


专栏:MySQL数据库成长记
个人主页:手握风云
目录
一、Update修改
1.1. 示例
-- 将王五的英语成绩加10分
update exam set English = English + 10 where `name` = '王五';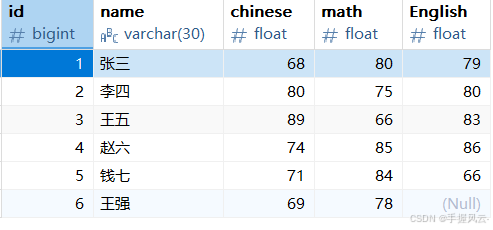
select *, chinese+math+English as total from exam order by total asc limit 3;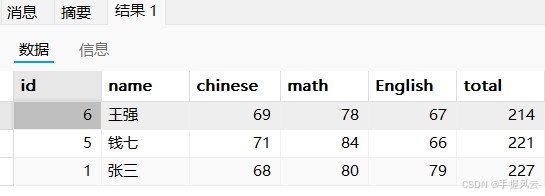
-- 总成绩倒数前三的同学的数学成绩加10
select *, chinese + math + English as total from exam order by total asc limit 3;
update exam set math = math + 10 order by chinese + math + English asc limit 3; 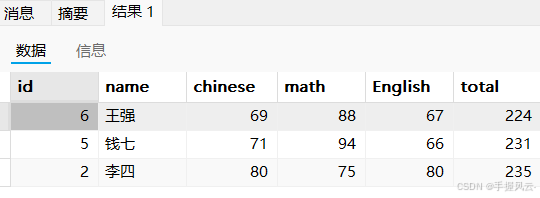
-- 所有人的语文成绩*2
update exam set chinese = chinese*2;
select * from exam;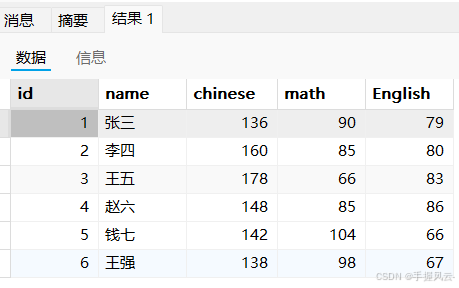
注意,基本运算不能像Java里面写成+=、-=或者*=。
二、Delete删除
2.1. 语法
DELETE FROM tbl_name [WHERE where_condition] [ORDER BY ...] [LIMIT row_count]2.2. 示例
-- 删除王强的成绩
delete from exam where `name` = '王强';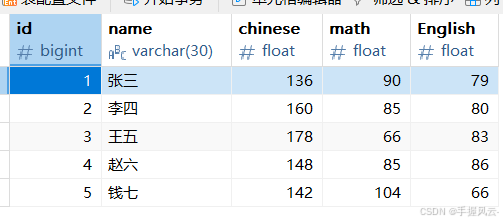
-- 删除整张表
create table t_delete(
id int,
`name` varchar(30)
);
insert into t_delete(id,`name`) values (1,'A'),(2,'B'),(3,'C');
delete from t_delete;
select * from t_delete;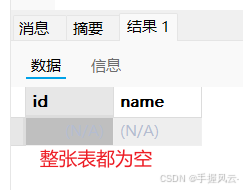
执行Delete时不加条件会删除整张表的数据,谨慎操作。insert、update、delete执行成功之后返回的都是受影响的行数,属于整型;select行成功之后返回的是结果集,属于set类型。
三、截断表
3.1. 语法
截断表是将表恢复到刚创建的状态。
TRUNCATE [TABLE] tbl_name3.2. 示例
create table t_truncate(
id int PRIMARY KEY AUTO_INCREMENT,
`name` varchar(30)
);
insert into t_truncate (`name`) values ('A'),('B'),('C');AUTO_INCREMENT是自增操作,当插入一条数据时,当前列的值加1,数据库会自动帮我们维护这个值,并且这个值会被记录在数据库内部。
查看创建表的语句:
mysql> show create table t_truncate;
+------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t_truncate | CREATE TABLE `t_truncate` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci |因为我们前面插入了3条数据,所以当我们查看创建表的语句时,下一行自增列的值AUTO_INCREMENT=4会被自动填充好。
truncate table t_truncate;
select * from t_truncate;
mysql> show create table t_truncate;
+------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t_truncate | CREATE TABLE `t_truncate` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci |通过上面的语句我们可以看到,AUTO_INCREMENT被重置了。truncate只能对整表操作,不能像delete⼀样针对部分数据,所以效率也比delete更高。
四、插入查询结果
4.1. 语法
INSERT INTO table_name [(column [, column ...])] SELECT ...4.2. 示例
- 删除表中的重复记录
实现思路:原始表中的数据⼀般不会主动删除,但是真正查询时不需要重复的数据,如果每次查询都使⽤distinct进⾏去重操作,会严重效率。可以创建⼀张与 t_recored 表结构相同的表,把去重的记录写⼊到新表中,以后查询都从新表中查,这样真实的数据不丢失,同时⼜能保证查询效率。
create table t_recored (
id int,
`name` varchar(30)
);
insert into t_recored values (100,'aaa'),(100,'aaa'),(200,'bbb'),(200,'bbb'),(300,'ccc');
-- 去重操作
select distinct * from t_recored;
--创建新表
create table t_newrecored like t_recored;
-- 去重的结果写入新表
insert into t_newrecored(id,`name`) select distinct id,`name` from t_recored;这种写法,如果查询出来的结果与写入的列类型一致也会写入成功,MySQL不会去校验列是否匹配。
-- 新表名称重命名为旧表
rename table t_recored to t_oldrecored,t_newrecored to t_recored;五、聚合函数
5.1. 常用函数
| 函数 | 说明 |
| COUNT([DISTINCT] expr) | 返回查询到的数据的数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的最小值,不是数字没有意义 |
后面4个函数只支持数值类型,如果是其它数据类型就会报错。
5.2. 示例
- count统计数量
-- 统计exam表中有多少条记录
select count(*) from exam;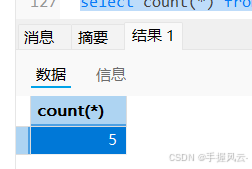
count(*)里面既可以传常量、列名、*,这里我们还是建议传*。因为*是SQL语言级别的,对于所有的数据库软件都通用,并且在MYISAM存储引擎中有一个变量记录了行数,count(*)就可以直接通过这个变量返回数据数量,效率相对来说更高。
-- 统计exam表中有多少条记录
select count(English) from exam;
insert into exam values (6,'王强',69,78,null);
insert into exam values (6,'李明',69,78,81);
当前列的值如果是null则不参与统计。
-- 统计英语成绩小于80的数量
select count(English) from exam where English < 80;
- sum求和
-- 统计所有学生的数学总分和语文总分
select sum(math) as 数学总分,sum(chinese) as 语文总分 from exam;
-- 非数值类型参与统计
select sum(name) from exam;
- avg求平均值
-- 求英语的平均分
select avg(English) from exam;
-- 求平均总分
select avg(chinese + math + English) 平均总分 from exam;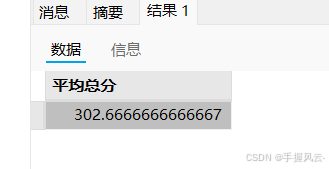
- max
-- 查询英语最高分
select max(English) from exam;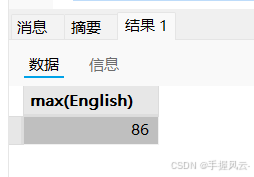
- min
-- 查询80分以上数学最低分
select min(math) from exam where math > 80;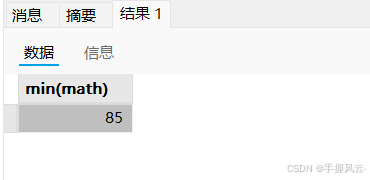
多个聚合函数可以出现在同一个select语句中。
-- 查询数学的最低分与英语的最高分
select min(math),max(English) from exam;
六、Group By分组查询
6.1. 语法
GROUP BY子句的作用是通过⼀定的规则将⼀个数据集划分成若干个小的分组,然后针对若干个分组进行数据处理,比如使用聚合函数对分组进行统计。
LECT {col_name | expr} ,... ,aggregate_function (aggregate_expr)
FROM table_references
GROUP BY {col_name | expr}, ...
[HAVING where_condition]
col_name | expr表示要查询的列或表达式,可以有多个,必须在 GROUP BY 子句中作为分组的依据;aggregate_function:聚合函数,⽐如COUNT(), SUM(), AVG(), MAX(), MIN(),比如统计一个班男女生个有多少人,就可以用到COUNT();aggregate_expr:聚合函数传⼊的列或表达式,如果列或表达式不在 GOURP BY 子句中,必须包含中聚合函数中。
6.2. 示例
create table emp(
id bigint primary key auto_increment,
`name` varchar(20) not null,
role varchar(20) not null,
salary decimal(10,2) not null
);
insert into emp values (1,'张一鸣','老板',35000000.00);
insert into emp values (2,'张三','工程师',280000.00);
insert into emp values (3,'李四','工程师',196000.00);
insert into emp values (4,'王五','工程师',325000.00);
insert into emp values (5,'赵四','产品经理',263000.00);
insert into emp values (6,'钱七','产品经理',237000.00);
insert into emp values (7,'王平','营销专员',224000.00);
insert into emp values (8,'李明','营销专员',215000.00);
insert into emp values (9,'刘永','内容创作者',188000.00);-- 统计每个职位的人数
select role, count(*) from emp group by role;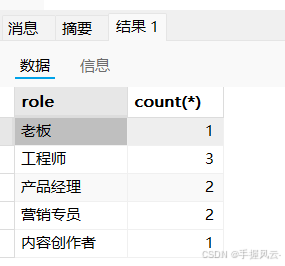
查询列表中如果要写列名,列必须是group by中。
6.3. having子句
使用GROUP BY 对结果进行分组处理之后,对分组的结果进行过滤时,不能使用 WHERE 子句,而要使用HAVING子句。