文章目录

Pre
分布式 - AT、TCC、SAGA、XA四种分布式事务模型的工作原理和应用场景
案例
微服务架构, 很多时候我们往往需要跨多个服务去更新多个数据库的数据,类似下图所示的架构。
图1
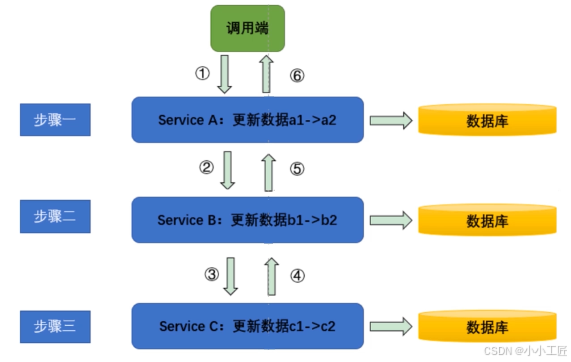
如图1 所示,如果业务正常运转,3 个服务的数据应该变为 a2、b2、c2,此时数据才一致。但是如果出现网络抖动、服务超负荷或者数据库超负荷等情况,整个处理链条有可能在步骤二失败,这时数据就会变成 a2、b1、c1,当然也有可能在步骤三失败,最终数据就会变成 a2、b2、c1,这样数据就对不上了,即数据不一致。
此时,我们不得不抽出时间针对数据一致性问题给出一个完美解决方案。
数据一致性问题的两种场景
第一种场景:实时数据不一致不要紧,保证数据最终一致性就行
因为一些服务出现错误,导致图 1 的步骤三失败,此时处理完请求后,数据就变成了 a2、 b2、c1,不过不要紧,我们只需保证最终数据是 a2、b2、 c2 就行。
第二种场景:必须保证实时一致性
如果图 1 中的步骤二和步骤三成功了,数据就会变成 b2、c2,但是如果步骤三失败,那么步骤一和步骤二会立即回滚,保证数据变回 a1、b1。
针对以上两种具体的场景,其具体解决方案是什么呢?
最终一致性方案
对于数据要求最终一致性的场景,实现思路是这样的:
-
每个步骤完成后,生产一条消息给 MQ,告知下一步处理接下来的数据;
-
消费者收到这条消息后,将数据处理完成后,与步骤一一样触发下一步;
-
消费者收到这条消息后,如果数据处理失败,这条消息应该保留,直到消费者下次重试。
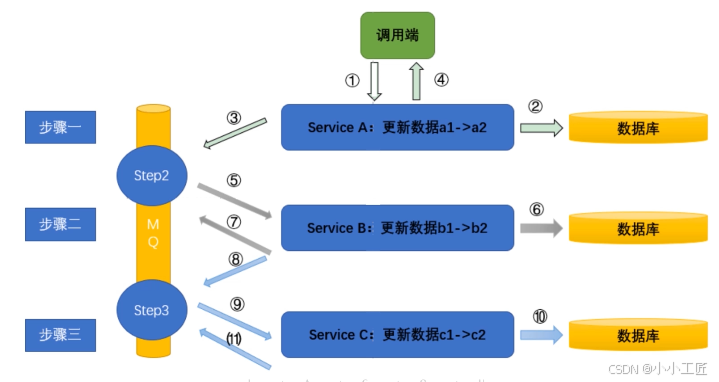
关于上图,详细的实现逻辑如下:
-
调用端调用 Service A;
-
Service A 将数据库中的 a1 改为 a2;
-
Service A 生成一条步骤 2(姑且命名为 Step2)的消息给到 MQ;
-
Service A 返回成功给调用端;
-
Service B 监听 Step2 的消息,拿到一条消息。
-
Service B 将数据库中的 b1 改为 b2;
-
Service B 生成一条步骤 3(姑且命名为 Step3)的消息给到 MQ;
-
Service B 将 Step2 的消息设置为已消费;
-
Service C 监听 Step3 的消息,拿到一条消息;
-
Service C 将数据库中的 c1 改为 c2;
-
Service C 将 Step3 的消息设置为已消费。
接下来我们考虑下,如果每个步骤失败了该怎么办?
- 调用端调用 Service A。
解决方案:如果这步失败,直接返回失败给用户,用户数据不受影响。
- Service A 将数据库中的 a1 改为 a2。
解决方案:如果这步失败,利用本地事务数据直接回滚就行,用户数据不受影响。
- Service A 生成一条步骤 2(姑且命名为 Step2)的消息给到 MQ。
解决方案:如果这步失败,利用本地事务数据将步骤 2 直接回滚就行,用户数据不受影响。
- Service A 返回成功给调用端。
解决方案:如果这步失败,不做处理。
- Service B 监听 Step2 的消息,拿到一条消息。
解决方案:如果这步失败,MQ 有对应机制,我们无须担心。
- Service B 将数据库中的 b1 改为 b2。
解决方案:如果这步失败,利用本地事务直接将数据回滚,再利用消息重试的特性重新回到步骤 5 。
- Service B 生成一条步骤 3(姑且命名为 Step3)的消息给到 MQ。
解决方案:如果这步失败,MQ 有生产消息失败重试机制。要是出现极端情况,服务器会直接挂掉,因为 Step2 的消息还没消费,MQ 会有重试机制,然后找另一个消费者重新从步骤 5 执行。
- Service B 将 Step2 的消息设置为已消费。
解决方案:如果这步失败,MQ 会有重试机制,找另一个消费者重新从步骤 5 执行。
- Service C 监听 Step3 的消息,拿到一条消息。
解决方案:如果这步失败,参考步骤 5 的解决方案。
- Service C 将数据库中的 c1 改为 c2。
解决方案:如果这步失败,参考步骤 6 的解决方案。
- Service C 将 Step3 的消息设置为已消费。
解决方案:如果这步失败,参考步骤 8 的解决方案。
以上就是最终一致性的解决方案.
如果仔细思考了该方案,可能會存在以下 2 点疑问。
-
因为我们利用了 MQ 的重试机制,就有可能出现步骤 6 跟步骤 10 重复执行的情况,此时该怎么办?比如上面流程中的步骤 8 失败了,需要从步骤 5 重新执行,这时就会出现步骤 6 执行 2 遍的情况。为此,在下游(步骤 6 和 步骤 10)更新数据时,我们需要保证业务代码的幂等性 。
-
如果每个业务流程都需要这样处理,岂不是需要额外写很多代码?那我们是否可以将类似处理流程的重复代码抽取出来?答案是可以的,这里使用的 MQ 相关逻辑在其他业务流程中也通用,最终就是将这些代码进行了抽取并封装。
实时一致性方案
实时一致性,其实就是我们常说的分布式事务。
MySQL 其实有一个两阶段提交的分布式事务方案(MySQL XA),但是该方案存在严重的性能问题。比如,一个数据库的事务与多个数据库间的 XA 事务性能可能相差 10 倍。另外,在 XA 的事务处理过程中它会长期占用锁资源,所以一开始并不考虑这个方案。
那时,市面上比较流行的方案是使用 TCC 模式,下面我们简单介绍一下。
TCC 模式
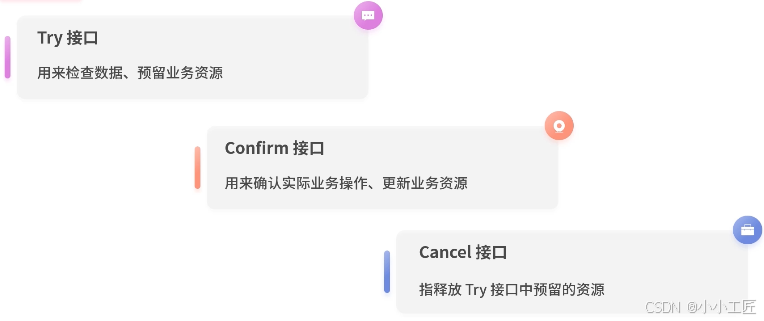
在 TCC 模式中,我们会把原来的一个接口分为 Try 接口、Confirm 接口、Cancel 接口。
-
Try 接口用来检查数据、预留业务资源。
-
Confirm 接口用来确认实际业务操作、更新业务资源。
-
Cancel 接口是指释放 Try 接口中预留的资源。
比如积分兑换折扣券的例子中需要调用账户服务减积分、营销服务加折扣券这两个服务,那么针对账户服务减积分这个接口,我们需要写 3 个方法,如下代码所示:
public boolean prepareMinus(BusinessActionContext businessActionContext, final String accountNo, final double amount) {
//校验账户积分余额
//冻结积分金额
}
public boolean Confirm(BusinessActionContext businessActionContext) {
//扣除账户积分余额
//释放账户 冻结积分金额
}
public boolean Cancel(BusinessActionContext businessActionContext) {
//回滚所有数据变更
}
同样,针对营销服务加折扣券这个接口,我们也需要写3个方法,而后调用的大体步骤如下:

图 3 中绿色代表成功的调用路径,如果中间出错,就会先调用相关服务的回退方法,再进行手工回退。原本我们只需要在每个服务中写一段业务代码就行,现在需要拆成 3 段来写,而且还涉及以下 5 点注意事项:
-
我们需要保证每个服务的 Try 方法执行成功后,Confirm 方法在业务逻辑上能够执行成功;
-
可能会出现 Try 方法执行失败而 Cancel 被触发的情况,此时我们需要保证正确回滚;
-
可能因为网络拥堵出现 Try 方法的调用被堵塞的情况,此时事务控制器判断 Try 失败并触发了 Cancel 方法,后来 Try 方法的调用请求到了服务这里,此时我们应该拒绝 Try 请求逻辑;
-
所有的 Try、Confirm、Cancel 都需要确保幂等性;
-
整个事务期间的数据库数据处于一个临时的状态,其他请求需要访问这些数据时,我们需要考虑如何正确被其他请求使用,而这种使用包括读取和并发的修改。
所以 TCC 模式是一个很麻烦的方案,除了每个业务代码的工作量 X3 之外,出错的概率也高,因为我们需要通过相应逻辑保证上面的注意事项都被处理。
后来,刚好看到了一篇介绍 Seata 的文章,了解到 AT 模式也能解决这个问题。
Seata 中 AT 模式的自动回滚
对于使用 Seata 的人来说操作比较简单,只需要在触发整个事务的业务发起方的方法中加入@GlobalTransactional 标注,且使用普通的 @Transactional 包装好分布式事务中相关服务的相关方法即可。
在 Seata 内在机制中,AT 模式的自动回滚往往需要执行以下步骤:
一阶段
-
解析每个服务方法执行的 SQL,记录 SQL 的类型(Update、Insert 或 Delete),修改表并更新 SQL 条件等信息;
-
根据前面的条件信息生成查询语句,并记录修改前的数据镜像;
-
执行业务的 SQL;
-
记录修改后的数据镜像;
-
插入回滚日志:把前后镜像数据及业务 SQL 相关的信息组成一条回滚日志记录,插入 UNDO_LOG 表中;
-
提交前,向 TC 注册分支,并申请相关修改数据行的全局锁 ;
-
本地事务提交:业务数据的更新与前面步骤生成的 UNDO LOG 一并提交;
-
将本地事务提交的结果上报给事务控制器。
二阶段-回滚
收到事务控制器的分支回滚请求后,我们会开启一个本地事务,并执行如下操作:
-
查找相应的 UNDO LOG 记录;
-
数据校验:拿 UNDO LOG 中的后镜像数据与当前数据进行对比,如果存在不同,说明数据被当前全局事务之外的动作做了修改,此时我们需要根据配置策略进行处理;
-
根据 UNDO LOG 中的前镜像和业务 SQL 的相关信息生成回滚语句并执行;
-
提交本地事务,并把本地事务的执行结果(即分支事务回滚的结果)上报事务控制器。
二阶段-提交
-
收到事务控制器的分支提交请求后,我们会将请求放入一个异步任务队列中,并马上返回提交成功的结果给事务控制器。
-
异步任务阶段的分支提交请求将异步地、批量地删除相应 UNDO LOG 记录。
以上就是 Seata 的 AT 模式的简单介绍。
