文章目录

Pre
引言
在高并发的系统中,读操作的性能优化往往可以通过缓存层实现,但当面临瞬时数十万级写请求时,传统的数据库直接写入方案将面临巨大挑战。
接下来我们将通过一个真实的预约活动案例,揭秘如何通过写缓存架构设计,实现数据库写压力的削峰填谷。
业务场景与挑战
某平台策划了一场预约活动,预计15分钟内涌入几十万预约请求。压测结果显示,当并发量超过8000时,系统响应速度急剧下降,而活动高峰期的瞬时并发预计超过10000,直接写入数据库将导致服务崩溃。
核心诉求:
- 不调整核心架构(避免分库分表等复杂改造)
- 低成本快速上线(无需大量服务器扩容)
- 用户体验零感知(页面不卡顿、数据不丢失)
解决方案:写缓存架构设计
核心思路
将用户请求先写入高性能缓冲层(如Redis),再通过异步批量落库将数据匀速写入数据库。通过缓冲层承受瞬时洪峰流量,避免直接冲击数据库。
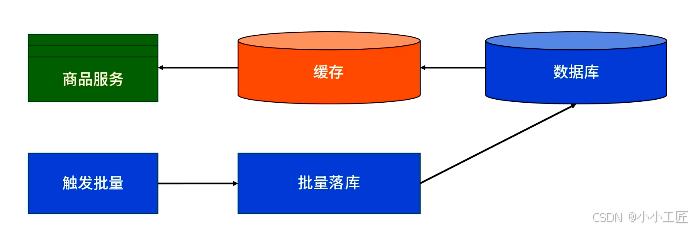
六大关键技术问题与解决方案
一、同步还是异步?
- 同步方案:请求线程等待数据落库完成再返回结果。
- 缺点:用户等待时间长,需处理超时与重试逻辑。
- 异步方案:请求写入缓冲层后立即返回成功。
- 优化体验:
- 提示“数据可能存在延迟”
- 跳转至详情页轮询落库状态(用户无感知)
- 优化体验:
最终选择异步方案,兼顾用户体验与实现复杂度。
同步与异步的区别
比如同步,写请求提交数据后,写操作的线程会等到批量落库完成后才开始启动。这种设计的好处是用户预约成功后,可在我的预约页面立即看到预约数据。坏处是用户提交预约后,还需要在界面上等待一段时间才能返回结果,且这个时间不定,有可能需要等待一个完整的时间窗。
比如异步,写请求提交数据后,会直接提示用户提交成功。这种设计的好处是用户能快速知道提交结果。坏处是用户提交完后,如果手痒前往我的预约页面查看,可能会出现没有数据的情况,这时用户就会蒙圈儿。
那我们到底应该使用哪种设计模式呢?先别急,先来讨论下这两种设计模式的复杂度。
同步与异步的复杂度
同步的实现原理是写请求提交数据时,写请求的线程被堵塞住或者等待,待批量落库完成后再发送信号给写请求的线程,这个线程获得落库完成的信号后,最后返回预约成功给用户。
不过,这个过程会引出一系列的问题,比如:

如果使用异步的话,上面的第二点、第四点基本不用考虑,从复杂度的角度上来说,异步会比同步简单很多,因此后面我们直接选用异步的方式,预约数据保存到缓冲层即可返回结果。
关于异步的用户体验设计,共有 2 种设计方案可供业务方选择。
-
在我的预约页面给用户提供一个提示:您的预约订单可能会有一定时间延迟。
-
用户预约成功后,直接进入预约完成详情页,此页面会定时发请求查询后台批量落库的状态,如果落库成功,则弹出成功提示,并跳转至下一个页面。
其实,第 1种方案在市面上也经常遇到,不过我们后面主要还是选择的第 2 种方案。因为在第 2 种方案中,用户也感受不到到延迟。
二、批量落库触发策略
- 按数量触发(如每10条触发一次)
- 优点:减少数据库访问次数
- 缺点:低流量时数据延迟落库
- 按时间窗口触发(如每秒触发一次)
- 优点:控制最大延迟时间
- 缺点:突发流量可能导致单次批量过大
混合策略:同时使用两种触发条件,确保既减少数据库压力,又控制数据延迟。
关于批量落库触发逻辑,目前市面上共分为 2 种触发方式。
- 写请求满足特定次数后就落库1次,比如 10个请求落1次。
按照次数批量落库的优点是访问数据库的次数变为 1/N,从数据库压力上来说会小很多。不过也存在不足,如果访问数据库的次数未凑齐 N 次,用户的预约就一直无法落库。
- 每隔一个时间窗口落库1次,比如每隔 1s 落库1 次。
按照时间窗口落库的优点是能保证用户等待的时间不会太久,其缺点是如果某个瞬时流量太大,在那个时间窗口落库的数据就会很多,多到在 1 次数据库访问中没法完成所有数据的插入(比如 1s 内堆积了 5 千条数据),它们只好通过分批次实现插入,这不就变回第 1 种逻辑了吗?
那到底哪种触发方式好呢? 这两种方式同时使用,具体实现逻辑如下:
-
每收集 1 次写请求,插入预约的数据到缓存中,再判断缓存中预约的总数是否达到一定数量,达到后直接触发批量落库;
-
开 1 个定时器,每隔 1s 触发 1 次批量落库。
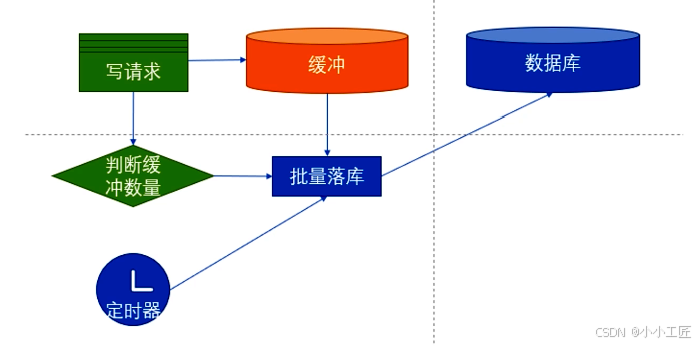
通过以上操作,我们既避免了触发方案 1 提到的数量不足无法落库的情况,也避免了方案2因为瞬时流量大,待插入数据堆积太多的情况。
三、缓冲层数据存储选型
缓冲数据不仅可以存放在本地内存中,也可以存放在分布式缓存中(比如 Redis),其中最简单的方式是存放本地内存中。
- 本地内存:实现简单,但存在宕机数据丢失风险。
- 分布式缓存(Redis):数据持久化+高可用,保障可靠性。
选择Redis,通过RDB快照与AOF日志实现数据持久化,结合主从模式提升可用性。
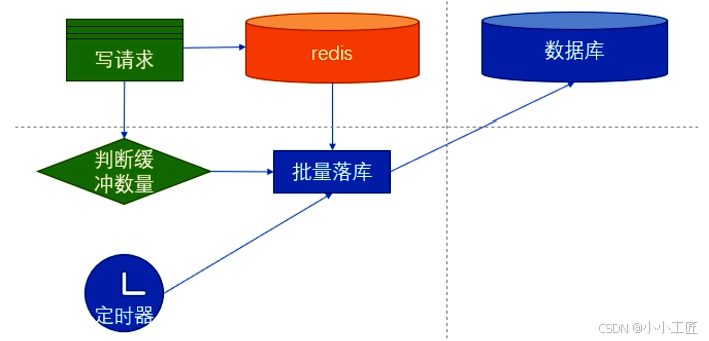
接下来,我们需要考虑批量落库的设计了,批量落库主要是把 Redis 中的预约数据移动到数据库中。那么问题又来了,当新的数据一直增加,批量落库可能会出现多个线程同时处理的情况,此时就要考虑并发性了。
四、并发控制设计
并不需要搬运海量数据,因为每隔 1 秒或数据量凑满 10 条,数据就会自动搬运一次,所以 1 次 batch insert 操作就能轻松搞定这个问题,我们只需要在并发性的设计方案中保证一次仅有一个线程批量落库就行。这个逻辑比较简单,就不赘述了。
五、批量落库失败处理
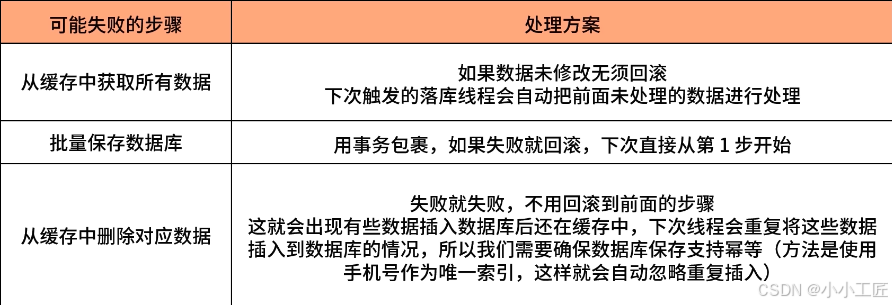
在考虑落库失败这个问题之前,我们先来看下批量落库的实现逻辑。
-
首先,当前线程从缓存中获取所有数据,因为每 10 条执行 1 次落库操作,不需要担心缓存数据量过多,也不用考虑将获得的数据分批次操作了;
-
其次,当前线程批量保存数据库;
-
最后,当前线程从缓存中删除对应数据。(注意:不能直接清空缓存的数据,因为新的预约数据可能插入到缓存中了。)
那在批量落库的过程中,如果这个操作失败了怎么办?
我们已经知道了批量落库每一步可能失败的处理的解决办法,接下来就是如何确保数据不丢失。
六、Redis高可用配置
在上面的业务场景里,我们是先把用户提交的数据保存到缓存中,因此必须保证缓存中的数据不丢失,这就要求我们实现 Redis的数据备份。
- 主从模式:Master负责写入,Slave实时同步数据。
- 持久化策略:
- RDB快照(每30秒) + AOF日志(每秒)
- 故障转移:哨兵(Sentinel)自动监测主节点状态并切换。
容灾预案:若Redis集群宕机,临时切换为直接写入数据库(牺牲性能保数据)。
方案价值与不足
核心价值
- 吞吐量提升:Redis单节点QPS可达10万级,远超数据库(通常<1万)。
- 成本优化:无需分库分表,节省服务器资源。
- 用户体验:活动期间零卡顿,预约成功率达100%。
局限性
- 短时高峰专用:不适合持续高写入场景(需结合分库分表)。
- 资源竞争场景不适用:如库存扣减需强一致性,需采用其他方案(如Redis原子操作+异步同步)。
总结
写缓存架构通过“缓冲削峰+异步落库”的设计,巧妙化解了瞬时高并发写入的难题。其核心在于权衡一致性、性能与成本,适用于营销活动、秒杀等短时高峰场景。后续我们将探讨如何结合消息队列(如Kafka)进一步优化异步处理流程,实现更高吞吐量的写场景支持。
