掌握Hadoop的案例操作,能够在Hadoop中运行MapReduce程序
接下来,通过一个词频统计案例体验Hadoop集群的使用,本案例要统计的是文本文件中每个单词出现的次数。
1.准备文本数据
创建一个名称为word.txt的文本文件。
hello world
hello hadoop
hello hdfs
hello yarn
2.创建目录
在HDFS创建/wordcount/input目录,用于存放文件word.txt。
hdfs dfs -mkdir -p /wordcount/input
3.上传文件
在虚拟机Hadoop1的/export/data/目录执行rz命令上传文件word.txt,将文件word.txt上传到HDFS的/wordcount/input目录。
hdfs dfs -put /export/data/word.txt /wordcount/input
4.查看文件是否上传成功
通过HDFS的Web UI查看文件word.txt是否上传到HDFS的/wordcount/input目录。

5.运行MapReduce程序
(1)进入虚拟机Hadoop1的/export/servers/hadoop-3.3.0/share/hadoop/mapreduce目录,在该目录下执行“ll”命令,查看Hadoop提供的MapReduce程序。
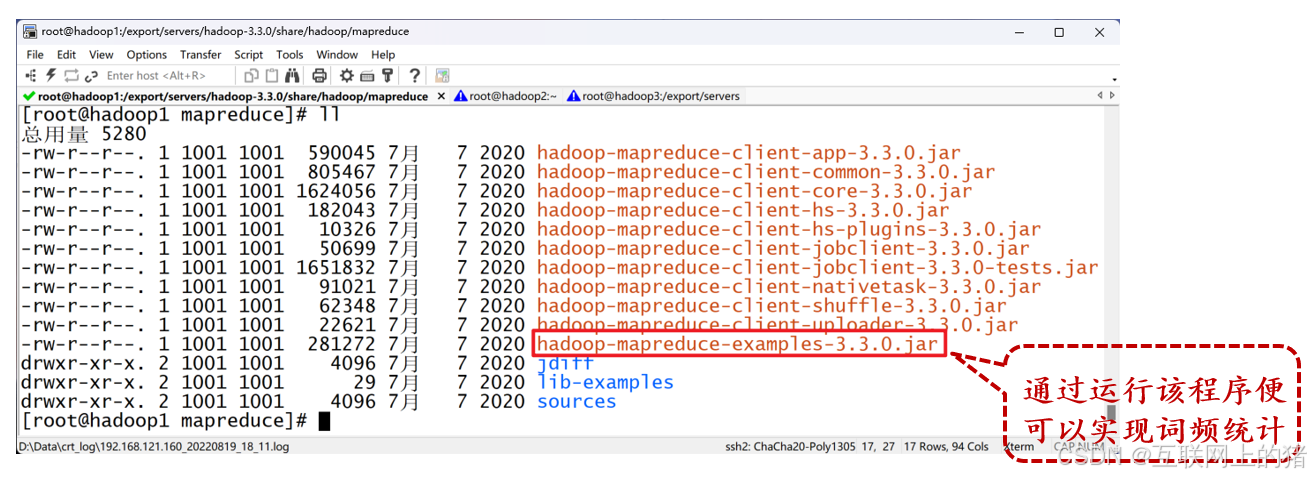
(2)在MapReduce程序所在的目录执行下列命令,统计word.txt中每个单词出现的次数。
hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount /wordcount/input /wordcount/output
- hadoop jar:用于指定运行的MapReduce程序;
- wordcount:表示程序名称;
- /wordcount/input:表示文件word.txt所在目录;
- /wordcount/output:表示统计结果输出的目录
(3)MapReduce程序部分运行效果。
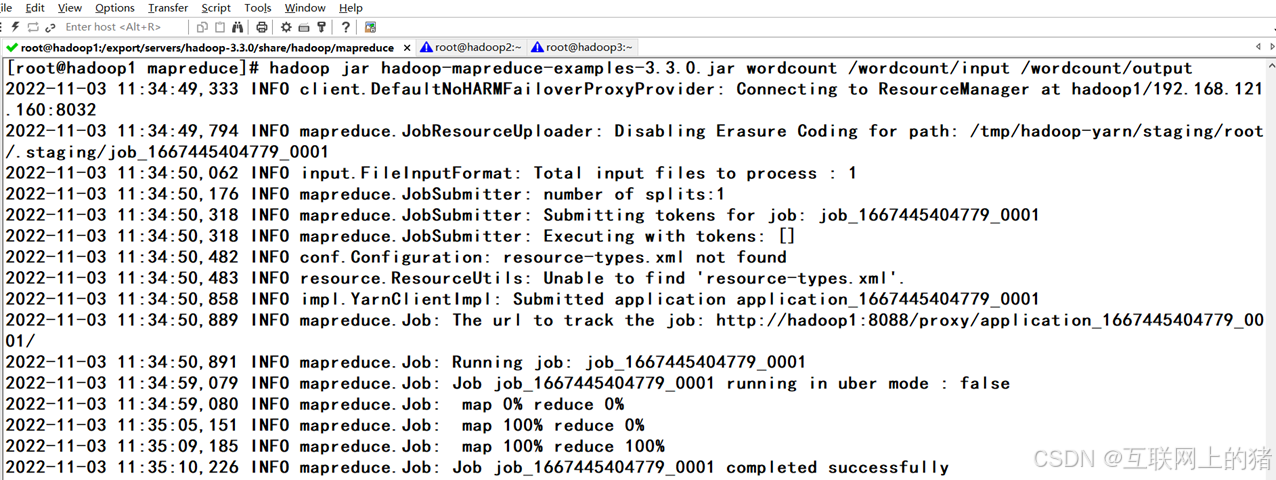
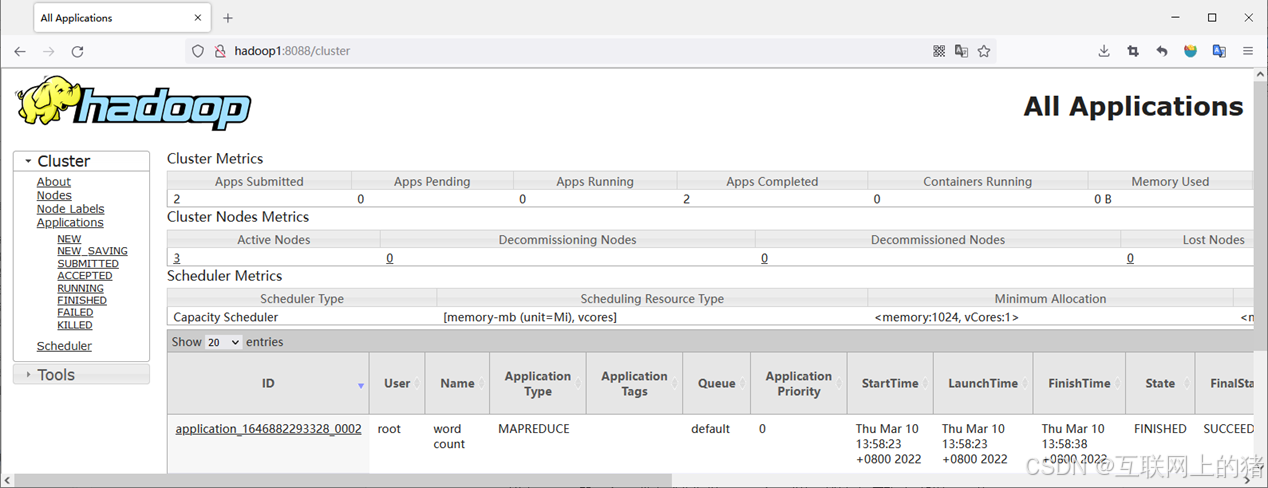
(3)MapReduce程序部分运行效果。
MapReduce程序运行过程中,使用浏览器访问YARN的Web UI查看MapReduce程序的运行状态。
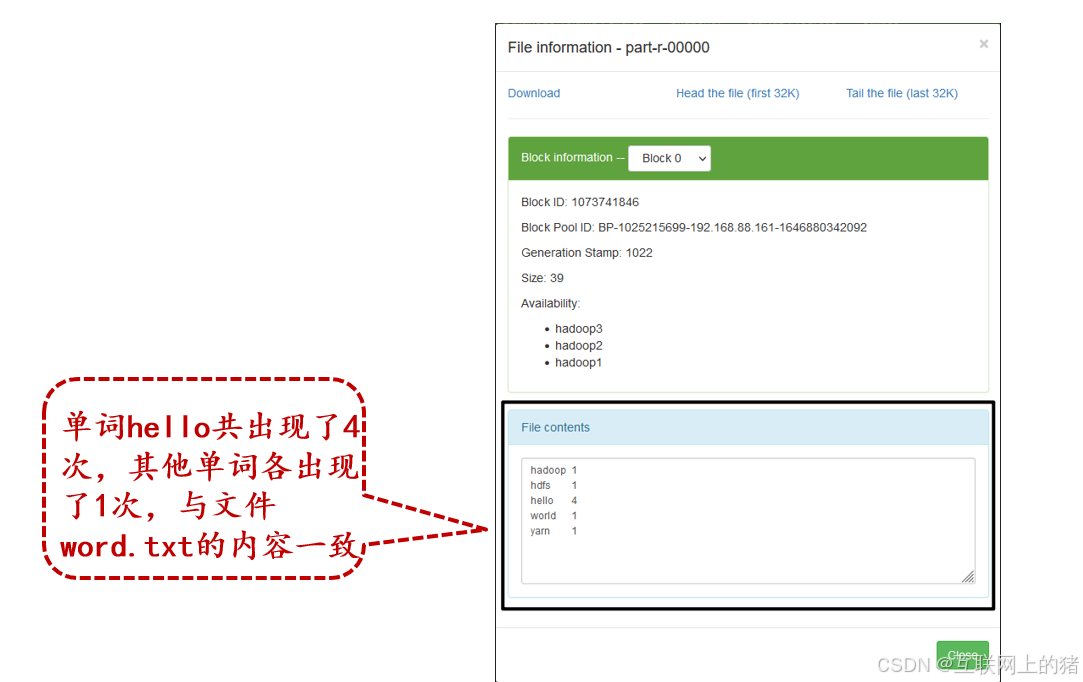
6.查看统计结果
(1)在HDFS的Web UI查看统计结果。
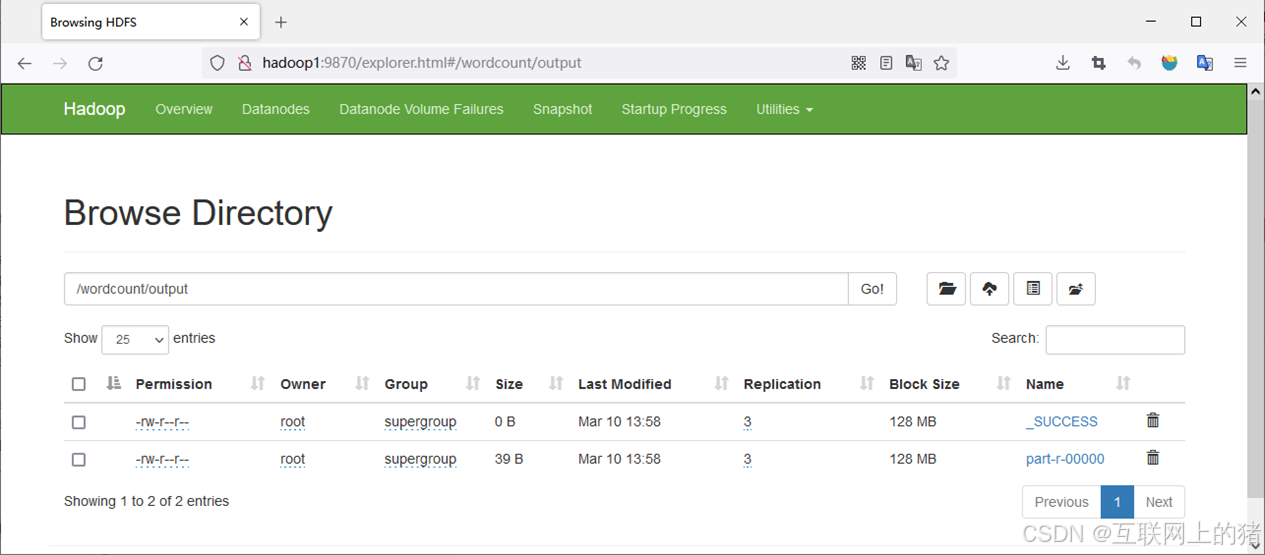
(2)查看文件part-r-00000的内容。