字节流解压方法源码如下:
/// <summary>
/// 解压缩字节流中的ZIP文件到指定路径。
/// </summary>
/// <param name="zipBytes">包含ZIP文件内容的字节数组。</param>
/// <param name="extractPath">解压后的文件保存路径。</param>
public static void ExtractZipFile(byte[] zipBytes, string extractPath)
{
try
{
// 检查目标目录是否存在,如果不存在则创建它
if (!Directory.Exists(extractPath))
{
Directory.CreateDirectory(extractPath); // 创建解压路径目录
}
// 使用MemoryStream将zipBytes加载到内存流中,以便读取ZIP文件内容
using (MemoryStream memoryStream = new MemoryStream(zipBytes))
// 使用ZipFile打开内存流中的ZIP文件
using (ZipFile zipFile = new ZipFile(memoryStream))
{
// 遍历ZIP文件中的每个条目(文件或目录)
foreach (ZipEntry entry in zipFile)
{
// 如果当前条目不是文件(例如目录),则跳过
if (!entry.IsFile)
continue; // 只处理文件,跳过目录
// 获取条目文件的文件名
string entryFileName = entry.Name;
// 创建一个4KB的缓冲区用于文件内容的复制
byte[] buffer = new byte[4096]; // 缓冲区大小为4KB
// 构造完整的解压路径(包括文件名)
string fullZipToPath = Path.Combine(extractPath, entryFileName);
// 获取解压路径中的目录部分
string directoryName = Path.GetDirectoryName(fullZipToPath);
// 如果目录不存在,则创建它
if (directoryName.Length > 0)
Directory.CreateDirectory(directoryName); // 创建目录
// 使用GetInputStream方法从ZIP文件中获取当前条目的输入流
using (Stream zipStream = zipFile.GetInputStream(entry))
// 创建文件流,用于写入解压后的文件内容
using (FileStream streamWriter = File.Create(fullZipToPath))
{
// 使用StreamUtils.Copy方法将ZIP流中的数据复制到文件流中
StreamUtils.Copy(zipStream, streamWriter, buffer);
// 这里的StreamUtils.Copy方法会从zipStream读取数据并写入到streamWriter(文件流)
}
}
}
// 解压缩成功后的调试信息(已被注释掉)
//Debug.Log("解压缩成功!");
}
catch (System.Exception ex)
{
// 如果出现任何异常,记录错误信息并输出到日志
Debug.LogError($"解压缩失败: {ex.Message}----" + extractPath);
}
}文件绝对路径解压方法源码如下:
/// <summary>
/// 解压指定路径的ZIP文件到目标路径。
/// </summary>
/// <param name="zipFilePath">待解压的ZIP文件路径。</param>
/// <param name="extractPath">解压后的文件保存路径。</param>
public static void ExtractZipFileFromPath(string zipFilePath, string extractPath)
{
try
{
// 检查目标目录是否存在,如果不存在则创建它
if (!Directory.Exists(extractPath))
{
Directory.CreateDirectory(extractPath); // 创建解压路径目录
}
// 使用FileStream打开指定的ZIP文件
using (FileStream zipFileStream = new FileStream(zipFilePath, FileMode.Open, FileAccess.Read))
{
// 使用ZipFile类来处理ZIP文件
using (ZipFile zipFile = new ZipFile(zipFileStream))
{
// 遍历ZIP文件中的每个条目(文件或目录)
foreach (ZipEntry entry in zipFile)
{
// 如果当前条目不是文件(例如目录),则跳过
if (!entry.IsFile)
continue; // 只处理文件,跳过目录
// 获取条目文件的文件名
string entryFileName = entry.Name;
// 创建一个4KB的缓冲区用于文件内容的复制
byte[] buffer = new byte[4096]; // 缓冲区大小为4KB
// 构造完整的解压路径(包括文件名)
string fullZipToPath = Path.Combine(extractPath, entryFileName);
// 获取解压路径中的目录部分
string directoryName = Path.GetDirectoryName(fullZipToPath);
// 如果目录不存在,则创建它
if (directoryName.Length > 0)
Directory.CreateDirectory(directoryName); // 创建目录
// 使用GetInputStream方法从ZIP文件中获取当前条目的输入流
using (Stream zipStream = zipFile.GetInputStream(entry))
// 创建文件流,用于写入解压后的文件内容
using (FileStream streamWriter = File.Create(fullZipToPath))
{
// 使用StreamUtils.Copy方法将ZIP流中的数据复制到文件流中
StreamUtils.Copy(zipStream, streamWriter, buffer);
// 这里的StreamUtils.Copy方法会从zipStream读取数据并写入到streamWriter(文件流)
}
}
}
}
// 解压缩成功后的调试信息(已被注释掉)
//Debug.Log("解压缩成功!");
}
catch (System.Exception ex)
{
// 如果出现任何异常,记录错误信息并输出到日志
Debug.LogError($"解压缩失败: {ex.Message}----" + zipFilePath);
}
}还可以传入多个文件路径,通过迭代器处理
/// <summary>
/// 解压多个文件路径的压缩包
/// </summary>
/// <param name="zipFilePaths">压缩文件的路径集合</param>
/// <param name="extractPath">解压后的文件保存路径</param>
public static void ExtractMultipleZipFiles(IEnumerable<string> zipFilePaths, string extractPath)
{
try
{
foreach (string zipFilePath in zipFilePaths)
{
if (!File.Exists(zipFilePath))
{
Debug.LogWarning($"文件不存在: {zipFilePath}");
continue;
}
// 对每个文件路径进行解压
ExtractZipFile(zipFilePath, extractPath); // 这是前面写的解压方法
}
}
catch (Exception ex)
{
Debug.LogError($"解压失败: {ex.Message}");
}
}
同样的,可以将Stream文件流和迭代器组合
public static void ExtractFromMultipleSources(IEnumerable<Stream> streams, IEnumerable<string> zipFilePaths, string extractPath)
{
try
{
// 解压来自文件流的文件
foreach (var stream in streams)
{
ExtractZipFromStream(stream, extractPath); // 处理Stream解压的ExtractZipFromStream方法
}
// 解压来自文件路径的文件
foreach (var filePath in zipFilePaths)
{
ExtractZipFileFromPath(filePath, extractPath); // 处理文件路径解压的ExtractZipFileFromPath方法
}
}
catch (Exception ex)
{
Debug.LogError($"解压失败: {ex.Message}");
}
}
字节流可以使用如下方法取得
System.IO.File.ReadAllBytes(modelPath + ".zip")读取压缩包时可能遇到如下报错
![]()
ArgumentException: Offset and length were out of bounds for the
array or count is greater than the number of elements from index to
the end of the source collection.排查后发现是因为压缩包是在Windows系统上手动打包的,会自动将压缩包内文件编码格式改为ANSI,即默认的GB2312编码格式,解决方法如下:
将压缩语言改为UTF-8
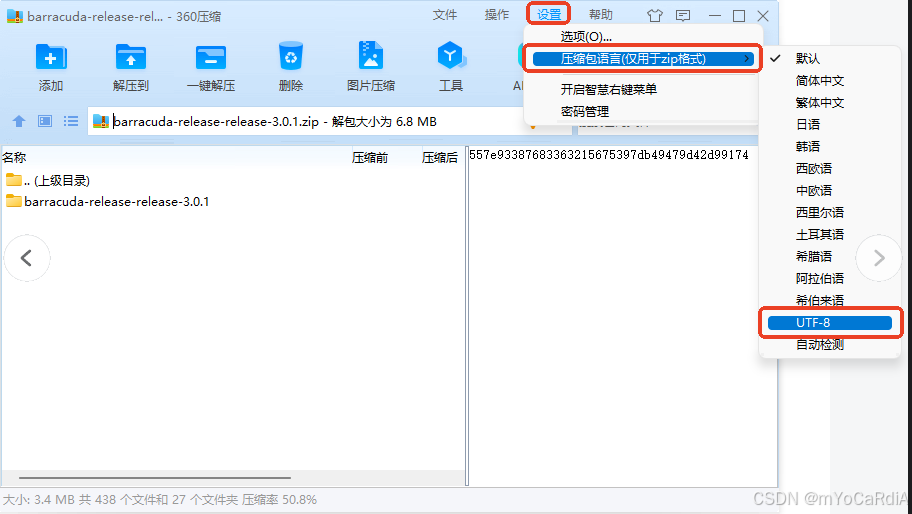
同理,Mac不支持Windows的ANSI默认中文编码GB2312,需手动改为UTF-8,IDE也要改。
扫描二维码关注公众号,回复:
17575511 查看本文章

