一种基于深度学习的VIT植物病害自动分类方法
A deep learning based approach for automated plant disease classification using vision transformer
摘要
-
植物病害可能会减少每个农场上相当一部分的农业产品。本研究的主要目标是为农民提供视觉信息,使他们能够采取必要的预防措施。
-
我们提出了一种基于视觉Transformer(ViT)的轻量级深度学习方法,用于实时自动化植物病害分类。除了ViT之外,还实施了经典的卷积神经网络(CNN)方法以及CNN与ViT的结合用于植物病害分类。这些模型已在多个数据集上进行了训练和评估。
-
根据获得结果的比较,得出的结论是,尽管注意力模块提高了准确率,但却减缓了预测速度。将注意力模块与CNN模块结合可以弥补速度上的不足。
-
小麦锈病分类数据集可在以下网址获取: https://www.kaggle.com/sinadunk23/behzad-safari-jalal。
-
本文的编码可在 https://github.com/yasaminborhani/PlantDiseaseClassification 获得。
1-引言
-
最近,Vision Transformer (ViT) 结构被引入以改善分类应用。
-
ResNet、ViT这些模型通常在像ImageNet这样的大型数据集上进行训练,然后将获得的权重用于迁移学习。当第二个数据集与第一个数据集具有相似领域时,通常能够获得高准确率。然而,当领域不同时,这些模型在小型数据集上往往难以达到可接受的准确率。
-
对于实时应用,预测需要尽可能快。由此提出一个论点,即迁移学习是否总是一个优秀的选择?
-
C-DenseNet结构、M-bCNN结构、番茄叶图像训练
-
本文介绍了基于ViT结构的轻量级模型,以实现实时作物疾病分类。
2-相关工作
-
卷积神经网络:在卷积神经网络(CNN)结构中,图像特征通过保持二维结构的方式提取,该结构由多个滤波器组成。通过在输入图像上滑动滤波器,进行特征提取的计算。
-
VIT:ViT受到了Bert和“注意力即一切”论文的启发。
-
首先从图像中提取二维补丁,然后将其重塑为一维数组,从而适用于ViT结构。
-
为了完成下一层的补丁嵌入准备,这些补丁会被添加到位置编码器中。位置编码器帮助网络记住补丁之间的相对位置。
-
在下一步中,输入通过规范化层进行规范化,然后进入Transformer模块。该模块中最重要的部分是多头注意力层。多头注意力层的目的是计算权重,为更重要的区域分配更高的值。
-
-
Dataset:小麦锈病分类数据集Wheat Rust Classification dataset、水稻叶病数据集Rice Leaf Disease dataset、Plant Village。
-
小麦锈病分类数据集(WRCD):小麦锈病分类数据集包括三个类别:健康小麦、黄锈和棕锈。
-
稻叶病数据集(RLDD)是一个小型数据库,仅包含120张感染稻叶的图像。
-
Plant Village大规模的数据集,包含54,306张农作物叶片的图像。
-
-
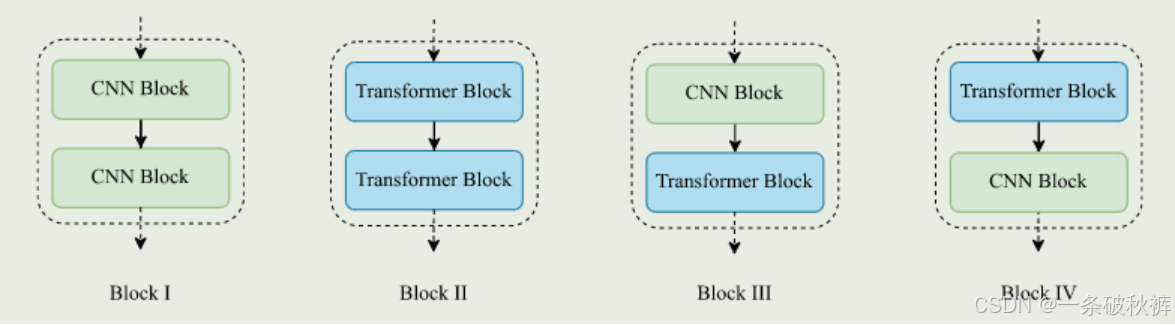
两个主要的构建块,分别为CNN和Transformer块:
-
CNN块:由两个具有3x3内核的卷积层组成。在这两个层中,不应用填充和活性值。第二个卷积层的输出进入一个leaky ReLU层。然后是一个具有2x2内核的最大汇聚层。
-
Transformer块:该块的输入被送入层规范化层。规范化层后接一个多头注意力层。

-
-
模型结构:模型的结构可以是纯卷积的(如模型1和模型2),也可以是纯变换的(如模型3和模型4),还可以是卷积块和变换块的组合。
3-实验
麦子锈病分类数据集实验:
-
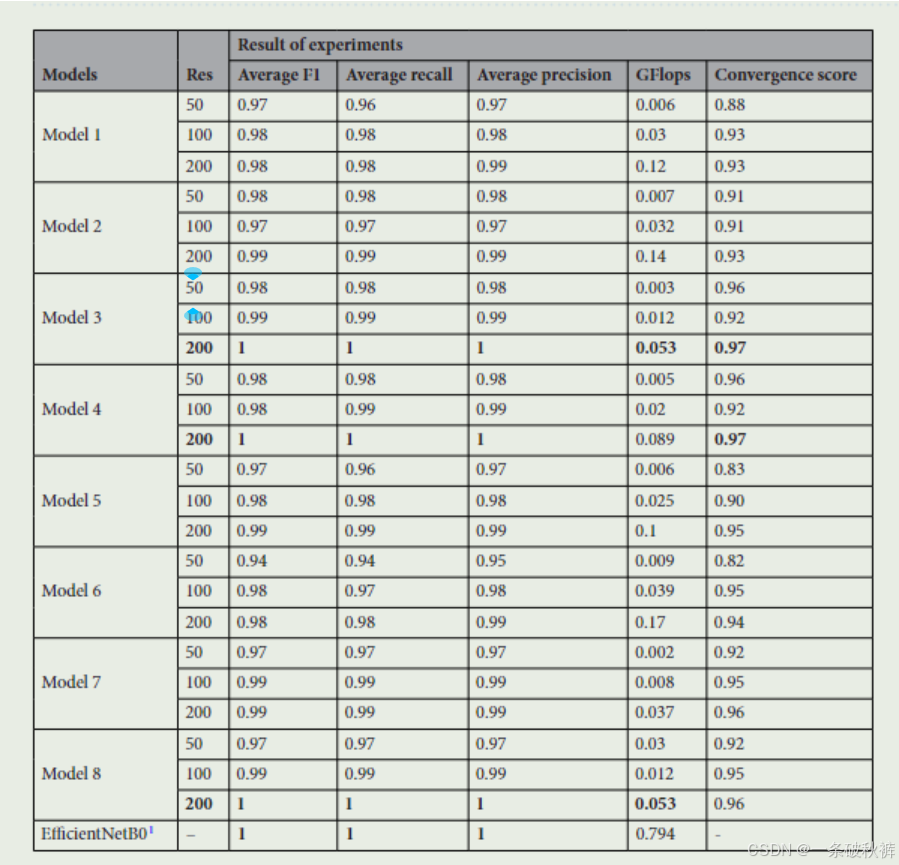
使用了八种模型结构,并选择了三种不同的图像分辨率(50x50、100x100和200x200)进行训练。较低的输入分辨率可以提高预测速度,但可能降低准确性。实验中,数据集被划分为80%的训练集和20%的验证集。
-
所有模型都经过100个epoch的训练,使用AdamW优化器,初始学习率设为0.001。实验结果显示,模型3在200x200分辨率下的表现优于其他模型,达到了与EfficientNet相似的F1分数、召回率和精确率,同时计算成本更低。
稻叶病数据集实验:
-
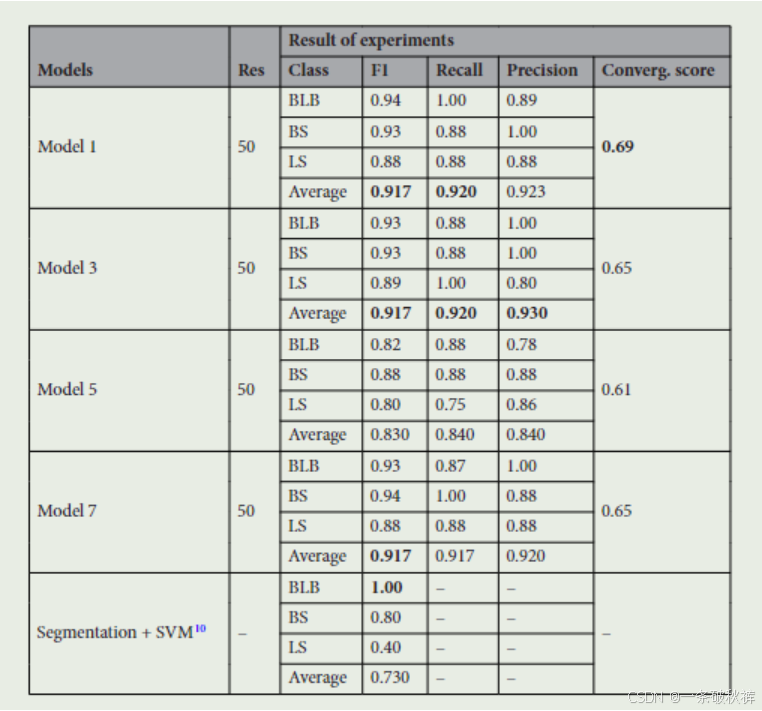
由于数据量有限,仅选择了模型1、3、5和7进行实验,这些模型各有两个特征提取块。实验中,初步选择50x50分辨率,后尝试了100x100分辨率。模型在BLB类别上表现出色,但在LS类别上的准确性较低。
-
所有模型在100x100分辨率下训练,未见显著改善,因此未进一步尝试200x200分辨率。
植物村数据集实验:
-
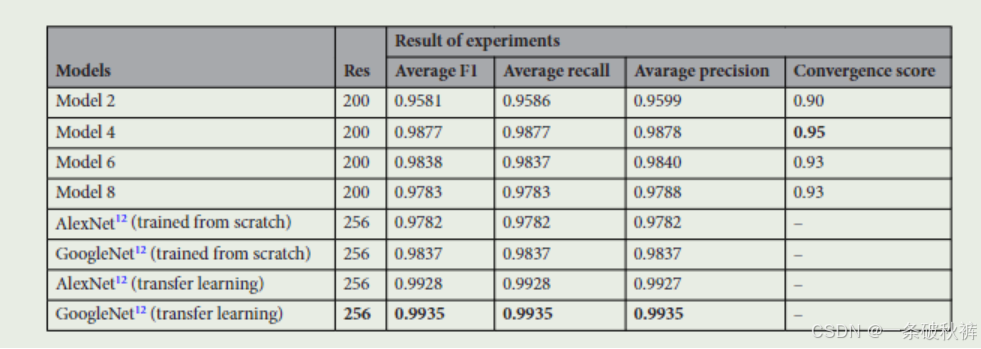
使用RGB图像版本进行实验,因其在准确性上表现更佳。选择了模型2、4、6和8进行实验,使用200x200分辨率。此数据集包含更多的图像和类别,因此选择了更复杂的模型。
-
实验结果显示,模型4的F1分数、召回率和精确率最高,超越了从头训练的AlexNet和GoogleNet。相比之下,模型4的可训练参数少于100万,而GoogleNet和AlexNet的参数数量分别为2300万和6200万。在使用迁移学习的情况下,AlexNet和GoogleNet的性能提升显著,超过了其他模型。
4-结论
研究了包含CNN和ViT组合的混合模型。
解决小型数据集RLDD(稻叶病数据集)、中型数据集WRCD(小麦锈病分类数据集)和大型数据集(Plant Village)上的分类任务。
本文中使用的注意力模块在所有设备上都比实现的卷积模块更慢。将注意力模块与卷积模块结合,有助于模型在预测速度上超过基于ViT的模型,同时在准确率上高于基于CNN的模型(植物村和WRCD实验)。
补充:
Leaky ReLU 激活函数
f(x) = max(αx, x)
Leaky ReLU(Leaky Rectified Linear Unit)是ReLU激活函数的一个改进版本,主要用于解决ReLU的"神经元死亡"问题。
-
解决神经元死亡问题:由于负值区域也有小的梯度,神经元不会被完全"关闭"
-
保留计算效率:仍然保持了ReLU计算简单的优点
-
缓解梯度消失:负值区域也有梯度流动