
7.2.2 深度强化学习在竞争中的应用
深度强化学习(Deep Reinforcement Learning, DRL)在多AI Agent竞争中的应用是一个充满活力和潜力的研究领域,它结合了深度学习的强大特征提取能力和强化学习的决策优化能力,使得智能体能够在复杂的、动态的环境中进行有效的学习和决策。以下将详细介绍深度强化学习在多AI Agent竞争中的应用。
1. 多智能体深度强化学习介绍
多智能体深度强化学习是强化学习和深度学习的交叉领域,涉及多个智能体在环境中同时学习和交互。与单智能体强化学习不同,多智能体系统中的智能体可能有不同的目标,且它们的行为会相互影响,导致环境变得非常复杂和动态。
2. DRL算法在多AI Agent竞争中的应用
(1)深度Q网络(DQN)及其扩展
- DQN通过深度神经网络近似Q值函数,解决了传统Q学习在高维状态空间中的应用难题。在多智能体竞争中,每个智能体可以独立运行DQN算法,根据环境反馈调整策略。
- 双DQN(Double DQN)和 prioritized DQN等改进算法进一步提升了学习效率和稳定性,适用于多智能体竞争场景。
(2)策略梯度方法
- 深度确定性策略梯度(DDPG):适用于连续动作空间的多智能体竞争任务,如机器人控制等。通过演员-评论家架构,智能体能够学习到更平滑和稳定的策略。
- 分布式策略梯度算法:在大规模多智能体系统中,分布式策略梯度算法允许智能体并行学习,加速了整个系统的收敛速度。
(3)基于注意力机制的算法
注意力机制使智能体能够关注环境中对其决策最关键的部分。在多智能体竞争中,智能体可以通过注意力机制选择性地共享信息或关注特定竞争对手的行为,从而优化决策。
3. DRL在多AI Agent竞争中的应用领域
(1)电子竞技
- AlphaGo Zero:通过自我对弈实现了围棋领域的重大突破,展示了深度强化学习在竞争环境中的强大能力。
- 多人在线战术游戏:如《星际争霸II》等游戏中,智能体通过深度强化学习算法进行训练,能够与人类玩家或其他AI智能体进行竞争,展现出高超的游戏技巧和策略。
(2)机器人技术
多机器人协作与竞争:在机器人足球比赛、救援任务等场景中,多个机器人通过深度强化学习进行策略学习,实现团队协作和与对手的竞争。
(3)智能交通
- 交通信号控制:多个智能体(如交通信号灯)通过深度强化学习优化交通流量,减少拥堵,提高通行效率。
- 自动驾驶车辆:在多车辆的交通环境中,自动驾驶车辆作为智能体,通过深度强化学习算法进行决策,与其他车辆竞争道路资源,同时确保安全和高效行驶。
(4)金融交易
多Agent交易系统:在金融市场中,多个交易智能体通过深度强化学习进行策略学习,进行股票、期货等金融产品的交易,通过竞争获取最大收益。
例如下面是一个基于深度强化学习实现的多AI Agent竞争系统,使用PyTorch框架和自定义竞技环境
实例7-2:基于DRL实现的多AI Agent竞争系统(源码路径:codes\7\Shen.py)
实例文件Shen.py的具体实现代码如下所示。
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from collections import deque
import random
import matplotlib.pyplot as plt
# 自定义竞技环境
class CompetitiveEnv:
def __init__(self, size=5):
self.size = size
self.agents = [{'pos': [0, 0]}, {'pos': [size-1, size-1]}]
self.resources = [[np.random.randint(1, size-1), np.random.randint(1, size-1)]]
self.step_count = 0
def reset(self):
self.agents[0]['pos'] = [0, 0]
self.agents[1]['pos'] = [self.size-1, self.size-1]
self.resources = [[np.random.randint(1, self.size-1), np.random.randint(1, self.size-1)]]
self.step_count = 0
return self.get_state()
def get_state(self):
state = []
for agent in self.agents:
state += agent['pos']
state += self.resources[0]
return np.array(state, dtype=np.float32)
def step(self, actions):
rewards = [0, 0]
done = False
# 更新智能体位置
for i, action in enumerate(actions):
dx, dy = [(0,0), (0,1), (0,-1), (1,0), (-1,0)][action]
new_x = self.agents[i]['pos'][0] + dx
new_y = self.agents[i]['pos'][1] + dy
if 0 <= new_x < self.size and 0 <= new_y < self.size:
self.agents[i]['pos'] = [new_x, new_y]
# 检查资源收集
for i, agent in enumerate(self.agents):
if agent['pos'] == self.resources[0]:
rewards[i] += 10
self.resources[0] = [np.random.randint(1, self.size-1), np.random.randint(1, self.size-1)]
# 竞争奖励
if self.agents[0]['pos'] == self.agents[1]['pos']:
rewards = [-5, -5]
self.step_count += 1
done = self.step_count >= 100
return self.get_state(), rewards, done, {}
# DQN智能体
class DQNAgent:
def __init__(self, state_size, action_size, agent_id):
self.state_size = state_size
self.action_size = action_size
self.memory = deque(maxlen=2000)
self.gamma = 0.95
self.epsilon = 1.0
self.epsilon_min = 0.01
self.epsilon_decay = 0.995
self.batch_size = 32
self.model = self._build_model()
self.target_model = self._build_model()
self.update_target_model()
def _build_model(self):
model = nn.Sequential(
nn.Linear(self.state_size, 24),
nn.ReLU(),
nn.Linear(24, 24),
nn.ReLU(),
nn.Linear(24, self.action_size)
return model
def update_target_model(self):
self.target_model.load_state_dict(self.model.state_dict())
def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
def act(self, state):
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_size)
state = torch.FloatTensor(state)
with torch.no_grad():
act_values = self.model(state)
return torch.argmax(act_values).item()
def replay(self):
if len(self.memory) < self.batch_size:
return
minibatch = random.sample(self.memory, self.batch_size)
states = torch.FloatTensor([t[0] for t in minibatch])
actions = torch.LongTensor([t[1] for t in minibatch])
rewards = torch.FloatTensor([t[2] for t in minibatch])
next_states = torch.FloatTensor([t[3] for t in minibatch])
dones = torch.FloatTensor([t[4] for t in minibatch])
targets = rewards + (1 - dones) * self.gamma * \
self.target_model(next_states).max(1)[0]
current_q = self.model(states).gather(1, actions.unsqueeze(1))
loss = nn.MSELoss()(current_q.squeeze(), targets.detach())
optimizer = optim.Adam(self.model.parameters())
optimizer.zero_grad()
loss.backward()
optimizer.step()
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
# 训练过程
env = CompetitiveEnv()
state_size = len(env.get_state())
action_size = 5 # 0:不动 1-4:四个方向移动
agents = [DQNAgent(state_size, action_size, 0),
DQNAgent(state_size, action_size, 1)]
episodes = 500
episode_rewards = []
for e in range(episodes):
state = env.reset()
total_rewards = [0, 0]
while True:
actions = [agents[i].act(state) for i in range(2)]
next_state, rewards, done, _ = env.step(actions)
for i in range(2):
agents[i].remember(state, actions[i], rewards[i], next_state, done)
total_rewards[i] += rewards[i]
state = next_state
for agent in agents:
agent.replay()
if done:
break
episode_rewards.append(total_rewards)
print(f"Episode: {e+1}, Agent1 Reward: {total_rewards[0]}, Agent2 Reward: {total_rewards[1]}")
# 定期更新目标网络
if e % 10 == 0:
for agent in agents:
agent.update_target_model()
# 可视化训练结果
plt.plot([r[0] for r in episode_rewards], label='Agent 1')
plt.plot([r[1] for r in episode_rewards], label='Agent 2')
plt.title('Training Progress')
plt.xlabel('Episode')
plt.ylabel('Total Reward')
plt.legend()
plt.show()对上述代码的具体说明如下所示:
1. 环境定义与初始化
(1)环境设计:定义一个二维网格环境CompetitiveEnv,包含两个智能体(A和B)和一个资源点。
- 初始状态:A位于左上角([0,0]),B位于右下角([size-1, size-1]),资源点随机生成在网格内部。
- 状态表示:每个状态包含两个智能体的位置坐标和资源点坐标(总长度为state_size=5)。
- 动作空间:每个智能体有5个动作选项(不动、上下左右移动)。
(2)奖励机制:
- 资源收集奖励:若智能体移动到资源点,获得+10奖励,并重置资源点位置。
- 竞争惩罚:若两个智能体在同一位置,双方均受-5惩罚。
- 终止条件:每回合最多执行100步,或手动终止。
2. 构建DQN智能体
(1)模型结构:每个智能体(A和B)独立拥有一个DQN网络:
- 神经网络:输入层(状态维度)、两个隐藏层(24神经元,ReLU激活)、输出层(动作数量5)。
- 目标网络:与主网络结构相同,定期同步参数以稳定训练。
(2)关键组件
- 经验回放:使用deque存储经验(状态、动作、奖励、下一状态、终止标志),批量采样用于训练。
- ε-贪心策略:以概率ε随机探索,逐步衰减ε(从1.0到0.01)平衡探索与利用。
- 优化器:使用Adam优化器,均方误差(MSE)作为损失函数。
3. 训练流程
(1)单个回合(Episode)流程
- 环境重置:初始化智能体位置和资源点,获取初始状态。
- 动作选择:每个智能体根据当前状态,通过DQN网络预测动作值,选择最大值对应的动作(或随机探索)。
- 环境交互:执行动作,更新智能体位置,检查资源收集和竞争冲突。获取下一状态、奖励和终止信号。
- 经验存储:将当前经验(状态、动作、奖励等)存入各自智能体的回放缓冲区。
- 经验回放与学习:首先,从经验池中随机采样批量数据,计算目标Q值(当前奖励 + 折扣后的未来最大Q值)。然后更新主网络参数以最小化预测Q值与目标Q值的误差。
- 终止条件判断:若回合结束(步数达到100或手动终止),退出循环。
(2)全局训练循环
- 多回合迭代:重复上述流程500个回合(episodes=500)。
- 目标网络更新:每10个回合同步主网络与目标网络的参数(agent.update_target_model())。
- 奖励记录:每回合结束后记录智能体的总奖励,用于后续可视化。
4. 可视化与结果分析
- 绘制两个智能体在每个回合的累积奖励变化曲线图(图7-2),观察训练收敛性。
- 若奖励逐渐上升,说明智能体学会了有效策略(如快速收集资源)。
- 若奖励波动或下降,可能需要调整超参数(如学习率、γ折扣因子)或优化网络结构。
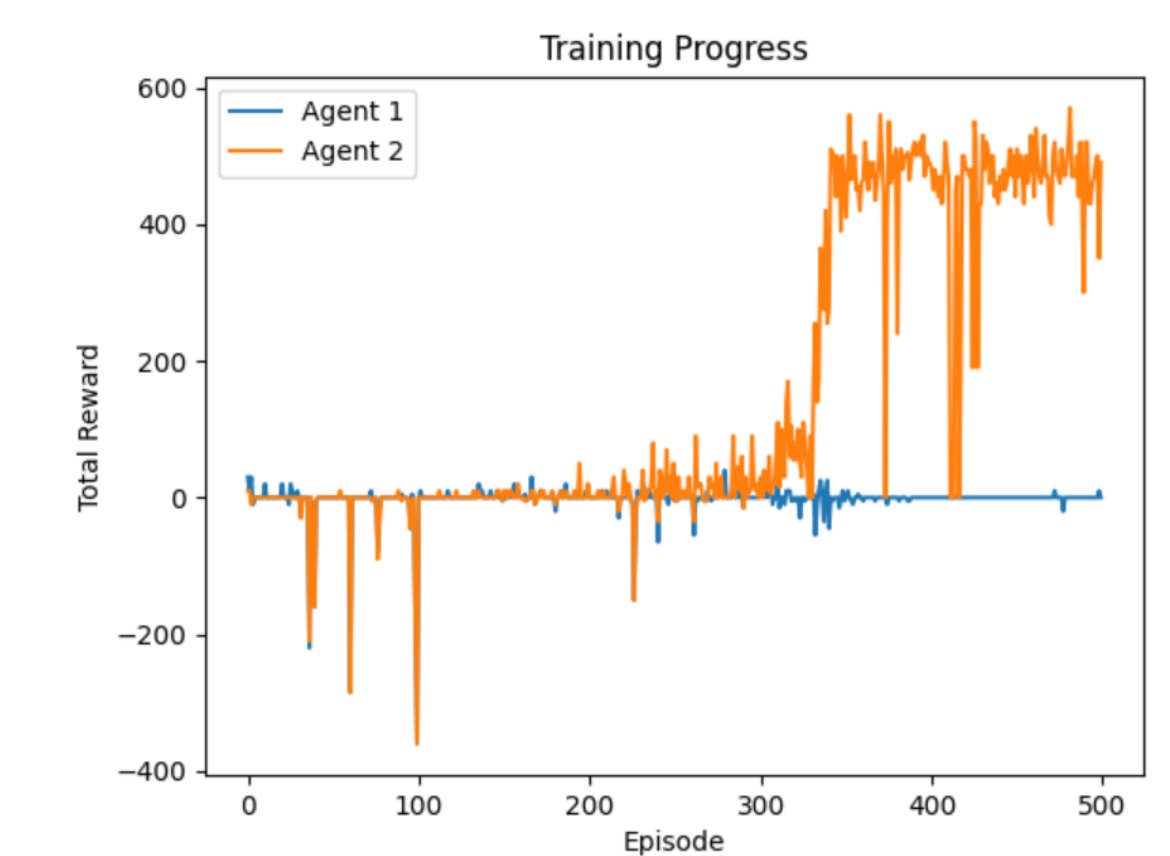
图7-2 累积奖励变化曲线图
总之,深度强化学习在多AI Agent竞争中的应用广泛且深入,通过各种先进的算法和策略,智能体能够在复杂的竞争环境中实现高效的决策和学习。随着技术的不断发展,深度强化学习将在更多领域展现出其巨大的潜力和价值。