参考:
https://research.google/blog/tx-llm-supporting-therapeutic-development-with-large-language-models/
https://developers.googleblog.com/en/introducing-txgemma-open-models-improving-therapeutics-development/
Tx-LLM,这是一种经过微调的语言模型,用于预测整个治疗开发管道中生物实体的属性,从早期目标发现到后期临床试验批准。
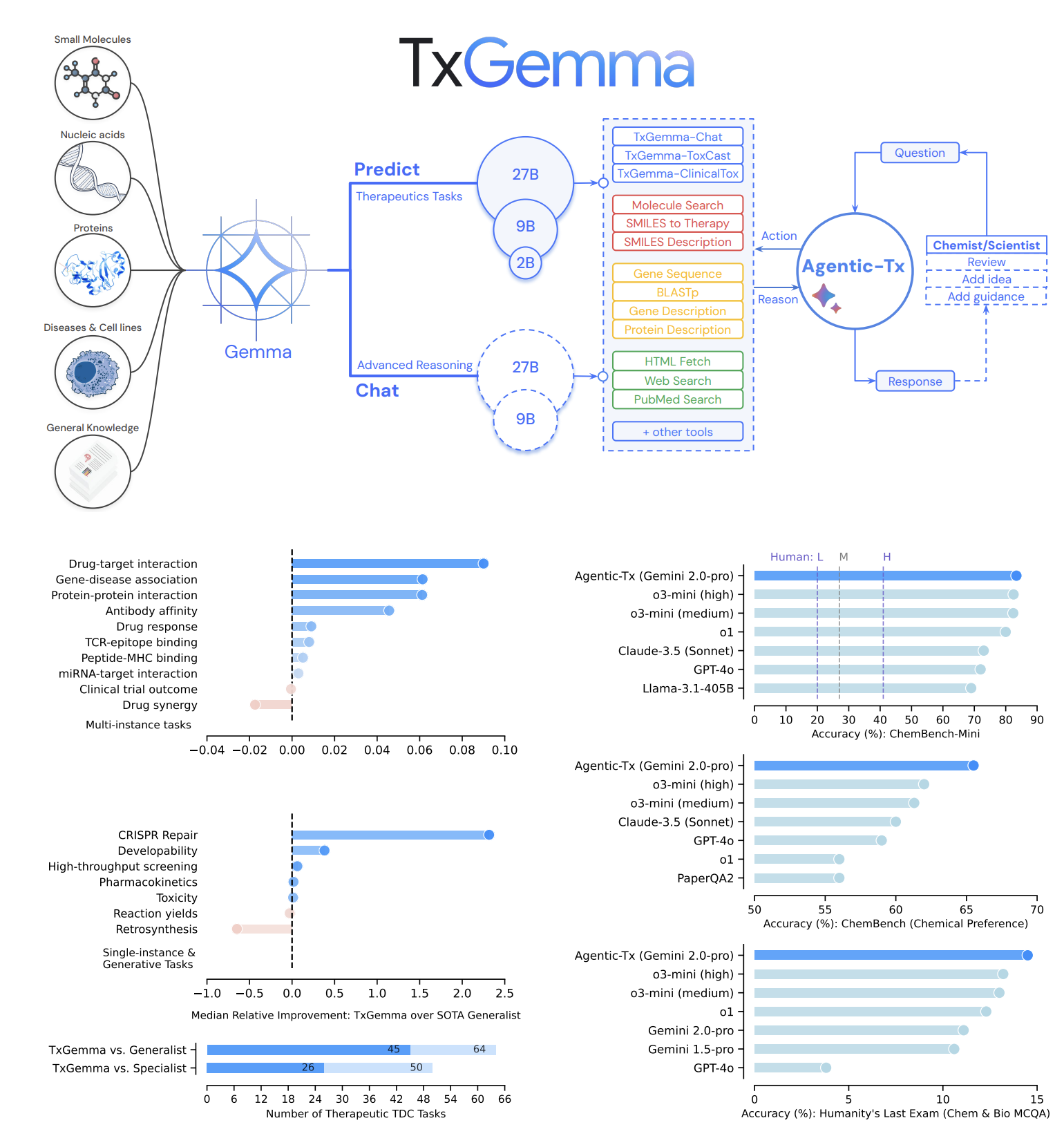


模型及代码
参考:https://huggingface.co/collections/google/txgemma-release-67dd92e931c857d15e4d1e87
https://github.com/google-gemini/gemma-cookbook/blob/main/TxGemma/%5BTxGemma%5DAgentic_Demo_with_Hugging_Face.ipynb
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
PREDICT_VARIANT = "2b-predict" # @param ["2b-predict", "9b-predict", "27b-predict"]
CHAT_VARIANT = "9b-chat" # @param ["9b-chat", "27b-chat"]
USE_CHAT = True # @param {
type: "boolean"}
if PREDICT_VARIANT == "2b-predict":
additional_args = {
}
else:
additional_args = {
"quantization_config": BitsAndBytesConfig(load_in_8bit=True)
}
predict_tokenizer = AutoTokenizer.from_pretrained(f"google/txgemma-{PREDICT_VARIANT}")
predict_model = AutoModelForCausalLM.from_pretrained(
f"google/txgemma-{PREDICT_VARIANT}",
device_map="auto",
**additional_args,
)
if USE_CHAT:
chat_tokenizer = AutoTokenizer.from_pretrained(f"google/txgemma-{CHAT_VARIANT}")
chat_model = AutoModelForCausalLM.from_pretrained(
f"google/txgemma-{CHAT_VARIANT}",
device_map="auto",
quantization_config=BitsAndBytesConfig(load_in_8bit=True)
)
Run inference on a sample binary classification task
## Example task and input
task_name = "BBB_Martins"
input_type = "{Drug SMILES}"
drug_smiles = "CN1C(=O)CN=C(C2=CCCCC2)c2cc(Cl)ccc21"
TDC_PROMPT = tdc_prompts_json[task_name].replace(input_type, drug_smiles)
def txgemma_predict(prompt):
input_ids = predict_tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = predict_model.generate(**input_ids, max_new_tokens=8)
return predict_tokenizer.decode(outputs[0], skip_special_tokens=True)
def txgemma_chat(prompt):
input_ids = chat_tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = chat_model.generate( **input_ids, max_new_tokens=32)
return chat_tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"Prediction model response: {txgemma_predict(TDC_PROMPT)}")
if USE_CHAT: print(f"Chat model response: {txgemma_chat(TDC_PROMPT)}")