本文来源公众号“Coggle数据科学”,仅用于学术分享,侵权删,干货满满。
在本篇博客中,我们将通过使用我们自己的强化学习(RL)奖励系统来改进我们最简单的检索增强生成(RAG)模型的实现,从而将事实性查询的检索质量从53%提升到84%。
我们将从头开始编写所有代码,包括强化学习算法,且不使用任何Python库。
在本篇博客中,我们将使用以下三个重要的部分:
-
用于响应生成:google/gemma-2–2b-it
-
用于嵌入生成:BAAI/bge-en-icl
-
用于强化学习奖励:贪心算法(寻找最大值)
原文地址:https://levelup.gitconnected.com/maximizing-simple-rag-performance-using-rl-in-python-d4c14cbadf59
开源地址:https://github.com/FareedKhan-dev/rag-with-rl
强化学习改进后的结果
我们的目标是改进一个简单的 RAG 模型,通过引入自定义的强化学习奖励系统,提升其在事实性查询任务中的表现。为了验证效果,我们选择了一个具体的查询问题:
What is the mathematical representation of a qubit in superposition?
在未引入强化学习之前,模型给出的响应是:
(Non RL Response): ψ α0 β1
经过 5 轮训练后,引入强化学习的 RAG 模型给出了更加准确和详细的响应:
The mathematical equation describing a qubit in superposition is:
|ψ⟩ = α|0⟩ + β|1⟩
Where:
* |ψ⟩ represents the superposition state of the qubit.
* α and β are complex coefficients representing the probabilities of finding the qubit in the |0⟩ and |1⟩ states, respectively.
* |0⟩ and |1⟩ are the basis states of the qubit.
Evaluation Results:
----------------------------------------
Simple RAG similarity to ground truth: 0.5326
RL-enhanced RAG similarity to ground truth: 0.8652
Improvement: 33.26%
为了量化改进效果,我们对两种模型的输出进行了与真实答案的相似度评估。以下是具体的评估结果:

-
简单 RAG 与真实答案的相似度:0.5326
-
强化学习增强的 RAG 与真实答案的相似度:0.8652
架构对比与原理解析
在自然语言处理领域,检索增强生成(RAG)模型是一种结合了检索和生成能力的强大工具。然而,不同的实现方式会对模型的性能产生显著影响。今天,我们将通过对比简单 RAG 和基于强化学习(RL)的 RAG 的架构,深入探讨它们的工作原理和差异。
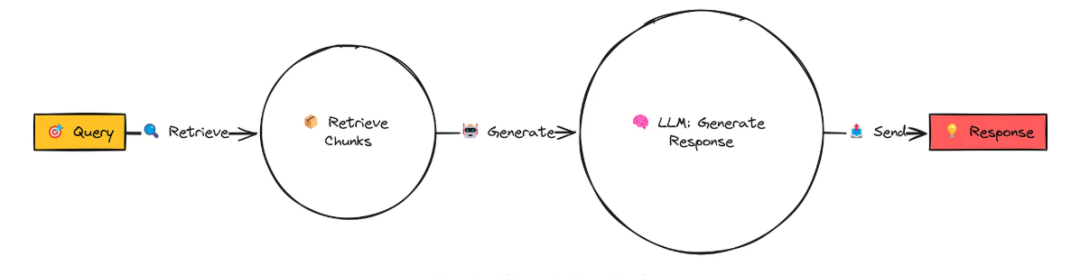
简单 RAG 的工作流程可以分为以下几个关键步骤:
-
输入查询与文档:用户输入一个查询,同时提供相关的文档集合。这些文档会被分割成多个小片段(chunk)。
-
检索相关片段:利用嵌入模型(embedding model)计算查询与每个片段的相似度,找出与查询最相关的片段。
-
生成响应:将检索到的顶部 K 个相关片段作为上下文,传递给语言模型(LLM),由其生成针对查询的响应。
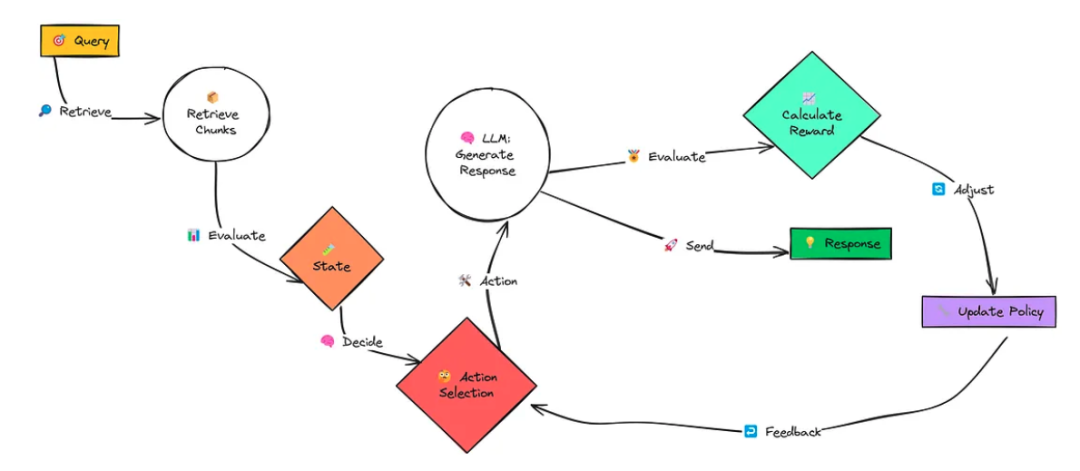
基于强化学习的 RAG 在简单 RAG 的基础上引入了强化学习机制,其工作流程如下:
-
初始化:同样从用户输入的查询和文档集合开始,文档被分割成片段。
-
强化学习代理介入:引入一个强化学习代理(agent),它根据语言模型生成的响应来采取行动。
-
动态调整:代理可以执行多种操作,例如:
-
重写查询:如果当前查询检索到的结果不理想,代理可以调整查询的表述,以获取更相关的内容。
-
检索更多片段:当需要更多上下文信息时,代理可以请求检索更多的文档片段。
-
移除无关片段:如果某些片段对生成响应没有帮助,代理可以将其从上下文中移除。
-
-
多步迭代:代理会重复上述过程,经过多个步骤(称为“episode”),直到生成的响应达到最佳效果。
数据预处理
我们将通过一个具体的例子,展示如何从头开始实现数据预处理流程,包括加载文档、分割文档为小片段(chunking)以及对文本进行预处理。
import os
from typing import List
# 函数:从目录加载文档
def load_documents(directory_path: str) -> List[str]:
"""
从指定目录加载所有文本文件。
参数:
directory_path (str): 包含文本文件的目录路径。
返回:
List[str]: 一个字符串列表,每个字符串是文本文件的内容。
"""
documents = [] # 初始化一个空列表来存储文档内容
for filename in os.listdir(directory_path): # 遍历目录中的所有文件
if filename.endswith(".txt"): # 检查文件是否以 .txt 结尾
# 以 UTF-8 编码打开文件并读取内容,然后将其添加到列表中
with open(os.path.join(directory_path, filename), 'r', encoding='utf-8') as file:
documents.append(file.read())
return documents # 返回文档内容列表
加载文档后,我们需要将每个文档分割成更小的片段(chunks)。这样做的目的是为了在后续步骤中更高效地处理数据,尤其是在检索和生成任务中。我们将使用一个固定的片段大小(例如 100 个字符,约 30 个单词),但你可以根据需求进行调整。
# 函数:将文档分割为片段
def split_into_chunks(documents: List[str], chunk_size: int = 100) -> List[str]:
"""
将文档分割为指定大小的片段。
参数:
documents (List[str]): 要分割的文档字符串列表。
chunk_size (int): 每个片段的最大字符数。默认为 100。
返回:
List[str]: 一个片段列表,每个片段是一个字符串,包含最多 `chunk_size` 个字符。
"""
chunks = [] # 初始化一个空列表来存储片段
for doc in documents: # 遍历每个文档
words = doc.split() # 将文档分割为单词
# 创建指定大小的片段
for i in range(0, len(words), chunk_size):
chunk = " ".join(words[i:i + chunk_size]) # 将单词重新组合成片段
chunks.append(chunk) # 将片段添加到列表中
return chunks # 返回片段列表
文档编码
在 RAG 模型中,知识库通常包含大量的文档片段。为了高效地检索与用户查询最相关的片段,我们需要将这些文本片段转换为嵌入向量。嵌入向量能够捕捉文本的语义信息,使得模型可以通过计算向量之间的相似度来快速找到最相关的片段。
由于知识库通常非常庞大,我们无法一次性为所有片段生成嵌入。因此,我们需要以批量的方式进行嵌入生成。我们将使用一个强大的嵌入模型 BAAI/bge-en-icl 来完成这项任务。
# 函数:为单个批次的文本片段生成嵌入
def generate_embeddings_batch(chunks_batch: List[str], model: str = "BAAI/bge-en-icl") -> List[List[float]]:
"""
使用 OpenAI 客户端为一批文本片段生成嵌入。
参数:
chunks_batch (List[str]): 要生成嵌入的文本片段批次。
model (str): 用于嵌入生成的模型。默认为 "BAAI/bge-en-icl"。
返回:
List[List[float]]: 嵌入列表,每个嵌入是一个浮点数列表。
"""
# 使用 OpenAI 客户端创建输入批次的嵌入
response = client.embeddings.create(
model=model, # 指定用于嵌入生成的模型
input=chunks_batch # 提供文本片段批次作为输入
)
# 从响应中提取嵌入并返回
embeddings = [item.embedding for item in response.data]
return embeddings
基于余弦相似度的检索
余弦相似度是一种衡量两个向量相似性的常用方法,它通过计算两个向量之间的夹角来判断它们的相似程度。余弦相似度的值范围在 -1 到 1 之间,值越接近 1,表示两个向量越相似。
import numpy as np
# 函数:计算两个向量之间的余弦相似度
def cosine_similarity(vec1: np.ndarray, vec2: np.ndarray) -> float:
"""
计算两个向量之间的余弦相似度。
参数:
vec1 (np.ndarray): 第一个向量。
vec2 (np.ndarray): 第二个向量。
返回:
float: 两个向量之间的余弦相似度,范围在 -1 到 1 之间。
"""
# 计算两个向量的点积
dot_product = np.dot(vec1, vec2)
# 计算第一个向量的模
norm_vec1 = np.linalg.norm(vec1)
# 计算第二个向量的模
norm_vec2 = np.linalg.norm(vec2)
# 返回余弦相似度
return dot_product / (norm_vec1 * norm_vec2)
基于余弦相似度,我们可以实现一个相似性检索函数。该函数将查询嵌入与向量存储中的所有文本片段嵌入进行比较,计算它们之间的相似度,并返回最相似的前 k 个文本片段。
现在我们已经实现了检索系统的所有功能,可以使用一个示例查询来测试其效果。
# 将生成的嵌入及其对应的预处理片段添加到向量存储中
add_to_vector_store(embeddings, preprocessed_chunks)
# 定义一个查询文本
query_text = "What is Quantum Computing?"
# 根据查询文本检索最相关的片段
relevant_chunks = retrieve_relevant_chunks(query_text)
# 打印每个检索到的片段的前 50 个字符
for idx, chunk in enumerate(relevant_chunks):
print(f"Chunk {idx + 1}: {chunk[:50]} ... ")
print("-" * 50) # 打印分隔线
LLM 响应生成
为了生成回答,我们需要构建一个输入提示(prompt),它包括查询文本和相关的文档片段作为上下文。我们将实现一个函数来完成这个任务。
# 函数:构建带有上下文的提示
def construct_prompt(query: str, context_chunks: List[str]) -> str:
"""
通过将查询与检索到的上下文片段结合,构建提示。
参数:
query (str): 要构建提示的查询文本。
context_chunks (List[str]): 要包含在提示中的相关上下文片段列表。
返回:
str: 用于作为 LLM 输入的构建好的提示。
"""
# 将所有上下文片段合并为一个字符串,用换行符分隔
context = "\n".join(context_chunks)
# 定义系统消息以指导 LLM 的行为
system_message = (
"You are a helpful assistant. Only use the provided context to answer the question. "
"If the context doesn't contain the information needed, say 'I don't have enough information to answer this question.'"
)
# 通过结合系统消息、上下文和查询,构建最终的提示
prompt = f"System: {system_message}\n\nContext:\n{context}\n\nQuestion:\n{query}\n\nAnswer:"
return prompt
基础 RAG:构建与评估
为了简化操作,我们将创建一个简单的 RAG 流水线函数,该函数仅接受一个参数——用户查询,并返回由 LLM 生成的回答。这个函数将依次完成以下步骤:
-
检索与查询最相关的文档片段。
-
构建包含查询和检索到的片段的提示。
-
使用 LLM 生成回答。
现在我们已经实现了基础 RAG 流水线,接下来需要对其进行评估。我们将使用一组评估查询,这些查询涵盖了不同的主题,包括事实性问题和复杂问题。首先,我们需要加载评估查询及其对应的期望答案。
# 函数:实现基础检索增强生成(RAG)流水线
def basic_rag_pipeline(query: str) -> str:
"""
实现基础检索增强生成(RAG)流水线:
检索相关片段,构建提示,并生成回答。
参数:
query (str): 输入查询,用于生成回答。
返回:
str: 基于查询和检索到的上下文,由 LLM 生成的回答。
"""
# 第一步:检索与给定查询最相关的片段
relevant_chunks: List[str] = retrieve_relevant_chunks(query)
# 第二步:使用查询和检索到的片段构建提示
prompt: str = construct_prompt(query, relevant_chunks)
# 第三步:使用构建好的提示从 LLM 生成回答
response: str = generate_response(prompt)
# 返回生成的回答
return response
强化学习在 RAG 系统
强化学习(Reinforcement Learning, RL)是一种机器学习范式,它通过让智能体(agent)在环境中采取行动来最大化累积奖励,从而学习做出决策。与监督学习不同,强化学习中的智能体不会被告知具体应该采取哪些行动,而是需要通过试错来发现哪些行动能够获得最多的奖励。
-
智能体(Agent)智能体是学习者或决策者,它在环境中采取行动以实现目标。
-
环境(Environment)环境是智能体与之交互的世界。环境会根据智能体的行动给出反馈。
-
状态(State, S)状态表示智能体在环境中的当前情境。状态可以是环境的直接观测,也可以是智能体对环境的内部表示。
-
行动(Action, A)行动是智能体可以采取的所有可能操作的集合。智能体根据当前状态选择行动。
-
奖励(Reward, R)奖励是环境在智能体采取行动后给出的反馈信号。奖励的目的是引导智能体朝着期望的方向发展。
-
策略(Policy, π)策略是智能体用来决定下一步行动的规则或策略。策略可以是确定性的,也可以是随机的。
强化学习的目标是学习一个最优策略 ( \pi^* ),使得智能体在长期运行过程中获得的累积奖励最大化。累积奖励通常通过以下公式计算:
在检索增强生成(RAG)系统中,强化学习可以用于以下几个方面:
-
优化检索过程通过强化学习,智能体可以学习哪些文档片段对回答查询最有帮助。智能体可以根据历史数据和用户反馈,动态调整检索策略,以提高检索到的相关性和准确性。
-
改进提示构建强化学习可以根据用户对生成回答的反馈,动态调整提示的构建方式。例如,智能体可以学习哪些上下文片段组合能够生成更高质量的回答。
-
优化生成过程通过强化学习,智能体可以从成功的回答中学习,优化生成过程。例如,智能体可以学习哪些生成策略能够获得更高的用户满意度。
在 RAG 系统中,我们可以将强化学习应用于以下几个关键环节:
-
检索优化智能体可以通过试错学习哪些文档片段对回答查询最有帮助。例如,智能体可以尝试不同的检索策略,根据生成回答的质量和用户反馈来调整策略。
-
提示构建优化智能体可以根据用户对生成回答的反馈,动态调整提示的构建方式。例如,智能体可以学习哪些上下文片段组合能够生成更高质量的回答。
-
生成优化智能体可以从成功的回答中学习,优化生成过程。例如,智能体可以学习哪些生成策略能够获得更高的用户满意度。
强化学习与RAG:状态、动作空间与奖励机制
在检索增强生成(RAG)系统中,我们可以通过强化学习优化检索和生成过程,从而提高回答的质量。接下来,我们将详细介绍如何在 RAG 系统中定义这些关键元素。
状态是智能体在环境中当前情境的描述。在 RAG 系统中,状态可以包括以下内容:
-
用户的原始查询(query)。
-
检索到的上下文片段(context chunks)。
-
可能经过重写的查询(rewritten query)。
-
之前生成的回答历史(previous responses)。
-
之前获得的奖励历史(previous rewards)。
动作空间是智能体在每个步骤中可以采取的所有可能行动的集合。在 RAG 系统中,我们定义了以下四种动作:
-
rewrite_query:重写原始查询以改进检索。
-
expand_context:检索额外的上下文片段。
-
filter_context:移除不相关的上下文片段。
-
generate_response:基于当前查询和上下文生成回答。
奖励是智能体采取行动后从环境中获得的反馈。在 RAG 系统中,奖励可以通过比较生成的回答与真实答案的相似度来计算。我们使用余弦相似度作为奖励函数,以衡量生成回答与真实答案的接近程度。
# 函数:根据回答质量计算奖励
def calculate_reward(response: str, ground_truth: str) -> float:
"""
通过比较生成的回答与真实答案来计算奖励值。
使用生成回答和真实答案的嵌入之间的余弦相似度来确定回答与预期答案的接近程度。
参数:
response (str):RAG 流水线生成的回答。
ground_truth (str):预期的正确答案。
返回:
float:奖励值在 -1 到 1 之间,值越高表示与真实答案的相似度越高。
"""
# 为回答和真实答案生成嵌入
response_embedding = generate_embeddings([response])[0]
ground_truth_embedding = generate_embeddings([ground_truth])[0]
# 计算嵌入之间的余弦相似度作为奖励
similarity = cosine_similarity(response_embedding, ground_truth_embedding)
return similarity
我们的目标是通过生成与真实答案相似的回答来最大化奖励。更高的奖励值表明生成的回答与预期答案更接近。
强化学习与RAG:动作函数逻辑
在定义了强化学习的状态、动作空间和奖励机制之后,我们需要进一步实现每个动作的具体逻辑。这些逻辑将决定智能体在 RAG 系统中采取行动时如何修改检索和生成过程。在本文中,我们将逐步实现每个动作的逻辑,以提升 RAG 系统的性能。
1. 动作逻辑:重写查询(Rewrite Query)
重写查询是提升检索效果的关键动作之一。通过优化原始查询,智能体可以更有效地检索到与问题相关的上下文片段,从而生成更准确的回答。
# 函数:重写查询以提升文档检索效果
def rewrite_query(
query: str,
context_chunks: List[str],
model: str = "google/gemma-2-2b-it",
max_tokens: int = 100,
temperature: float = 0.3
) -> str:
# 构建提示,让 LLM 重写查询
rewrite_prompt = f"""
你是一个查询优化助手。你的任务是重写给定的查询,使其更有效地检索相关信息。查询将用于文档检索。
原始查询:{query}
根据目前已检索到的上下文:
{' '.join(context_chunks[:2]) if context_chunks else '尚未检索到上下文'}
重写查询,使其更具体、更有针对性,以便检索到更好的信息。
重写后的查询:
"""
# 使用 LLM 生成重写后的查询
response = client.chat.completions.create(
model=model, # 指定用于生成响应的模型
max_tokens=max_tokens, # 响应中的最大标记数
temperature=temperature, # 响应多样性的采样温度
messages=[
{
"role": "user",
"content": rewrite_prompt
}
]
)
# 从响应中提取并返回重写后的查询
rewritten_query = response.choices[0].message.content.strip()
return rewritten_query
2. 动作逻辑:扩展上下文(Expand Context)
扩展上下文是通过检索额外的上下文片段来提供更多相关信息的动作。这有助于智能体探索更多与查询相关的知识,从而生成更全面的回答。
# 函数:通过检索额外的片段扩展上下文
def expand_context(query: str, current_chunks: List[str], top_k: int = 3) -> List[str]:
# 检索比当前可用片段更多的片段
additional_chunks = retrieve_relevant_chunks(query, top_k=top_k + len(current_chunks))
# 过滤掉当前上下文中已有的片段
new_chunks = []
for chunk in additional_chunks:
if chunk not in current_chunks:
new_chunks.append(chunk)
# 将新的唯一片段添加到当前上下文中,限制为 top_k
expanded_context = current_chunks + new_chunks[:top_k]
return expanded_context
3. 动作逻辑:过滤上下文(Filter Context)
过滤上下文是通过移除不相关的片段,保留最相关的片段来优化上下文的动作。这有助于确保提供给语言模型的上下文是简洁且聚焦于最相关信息的。
# 函数:过滤上下文以保留最相关的片段
def filter_context(query: str, context_chunks: List[str]) -> List[str]:
if not context_chunks:
return []
# 为查询和每个片段生成嵌入
query_embedding = generate_embeddings([query])[0]
chunk_embeddings = [generate_embeddings([chunk])[0] for chunk in context_chunks]
# 计算每个片段的相关性分数
relevance_scores = []
for chunk_embedding in chunk_embeddings:
score = cosine_similarity(query_embedding, chunk_embedding)
relevance_scores.append(score)
# 按相关性分数降序排序片段
sorted_chunks = [x for _, x in sorted(zip(relevance_scores, context_chunks), reverse=True)]
# 保留最多 5 个最相关的片段,或更少(如果不足 5 个)
filtered_chunks = sorted_chunks[:min(5, len(sorted_chunks))]
return filtered_chunks
强化学习与RAG:策略网络与单步训练
在之前的讨论中,我们已经定义了强化学习中的状态(State)、动作空间(Action Space)和奖励机制(Reward Methodology)。接下来,我们需要实现一个策略网络(Policy Network),它将根据当前状态选择一个动作。策略网络是强化学习中的核心组件,它决定了智能体在给定状态下如何行动。
策略网络是一个函数,它以当前状态和动作空间为输入,并根据状态选择一个动作。为了实现策略网络,我们可以使用一种简单的启发式方法,或者采用更复杂的策略,例如基于神经网络的策略。在本文中,我们将使用一种简单的启发式方法,并结合 epsilon-greedy 策略来平衡探索(exploration)和利用(exploitation)。
# 函数:定义策略网络以基于当前状态选择动作
def policy_network(
state: dict,
action_space: List[str],
epsilon: float = 0.2
) -> str:
# 使用 epsilon-greedy 策略:随机探索与利用
if np.random.random() < epsilon:
# 探索:从动作空间中随机选择一个动作
action = np.random.choice(action_space)
else:
# 利用:根据当前状态使用简单启发式方法选择最佳动作
# 如果没有之前的回答,优先重写查询
if len(state["previous_responses"]) == 0:
action = "rewrite_query"
# 如果有之前的回答但奖励较低,尝试扩展上下文
elif state["previous_rewards"] and max(state["previous_rewards"]) < 0.7:
action = "expand_context"
# 如果上下文片段过多,尝试过滤上下文
elif len(state["context"]) > 5:
action = "filter_context"
# 否则,生成回答
else:
action = "generate_response"
return action
在强化学习中,训练过程通常包含一个循环,每次循环称为一个步骤(step)。在每个步骤中,智能体根据当前状态选择一个动作,执行该动作,然后根据结果获得奖励,并更新状态。
# 函数:执行单步强化学习
def rl_step(
state: dict,
action_space: List[str],
ground_truth: str
) -> tuple[dict, str, float, str]:
# 使用策略网络选择一个动作
action: str = policy_network(state, action_space)
response: str = None # 初始化回答为 None
reward: float = 0 # 初始化奖励为 0
# 执行选择的动作
if action == "rewrite_query":
# 重写查询以提升检索效果
rewritten_query: str = rewrite_query(state["original_query"], state["context"])
state["current_query"] = rewritten_query # 更新状态中的当前查询
# 根据重写后的查询检索新的上下文
new_context: List[str] = retrieve_relevant_chunks(rewritten_query)
state["context"] = new_context # 更新状态中的上下文
elif action == "expand_context":
# 通过检索额外的片段扩展上下文
expanded_context: List[str] = expand_context(state["current_query"], state["context"])
state["context"] = expanded_context # 更新状态中的上下文
elif action == "filter_context":
# 过滤上下文以保留最相关的片段
filtered_context: List[str] = filter_context(state["current_query"], state["context"])
state["context"] = filtered_context # 更新状态中的上下文
elif action == "generate_response":
# 使用当前查询和上下文构建提示
prompt: str = construct_prompt(state["current_query"], state["context"])
# 使用 LLM 生成回答
response: str = generate_response(prompt)
# 根据生成的回答与真实答案之间的相似度计算奖励
reward: float = calculate_reward(response, ground_truth)
# 更新状态中的回答和奖励历史
state["previous_responses"].append(response)
state["previous_rewards"].append(reward)
# 返回更新后的状态、选择的动作、获得的奖励和生成的回答
return state, action, reward, response
强化学习与RAG:训练参数、策略更新与性能比较
在强化学习中,训练参数和策略更新是实现智能体学习和优化的关键环节。同时,为了评估强化学习增强的 RAG 系统(RL-enhanced RAG)的效果,我们需要设计一个性能比较逻辑,以对比简单 RAG 系统和强化学习增强的 RAG 系统。本文将详细介绍这些内容。
在强化学习中,智能体需要根据获得的奖励来更新其策略。策略更新的目的是让智能体在未来获得更高的累积奖励。虽然在复杂场景中通常会使用策略梯度或 Q 学习等方法,但为了简单起见,我们这里使用一个简单的更新逻辑。
# 函数:根据奖励更新策略
def update_policy(
policy: Dict[str, Dict[str, Union[float, str]]],
state: Dict[str, object],
action: str,
reward: float,
learning_rate: float
) -> Dict[str, Dict[str, Union[float, str]]]: # 示例:简单策略更新(应替换为适当的强化学习算法)
policy[state["query"]] = {
"action": action, # 存储采取的动作
"reward": reward # 存储获得的奖励
}
return policy
现在我们已经实现了训练过程的各个部分,可以将它们整合到一个函数中,实现强化学习增强的 RAG 系统的训练循环。
# 函数:实现训练循环
def training_loop(
query_text: str,
ground_truth: str,
params: Optional[Dict[str, Union[float, int]]] = None
) -> Tuple[Dict[str, Dict[str, Union[float, str]]], List[float], List[List[str]], Optional[str]]:
# 如果未提供训练参数,则初始化默认参数
if params is None:
params = initialize_training_params()
# 初始化变量以跟踪进度
rewards_history: List[float] = [] # 存储每个周期奖励的列表
actions_history: List[List[str]] = [] # 存储每个周期采取的动作的列表
policy: Dict[str, Dict[str, Union[float, str]]] = {} # 存储动作和奖励的策略字典
action_space: List[str] = define_action_space() # 定义动作空间
best_response: Optional[str] = None # 存储最佳回答的变量
best_reward: float = -1 # 将最佳奖励初始化为一个非常低的值
# 获取简单 RAG 流水线的初始性能以供比较
simple_response: str = basic_rag_pipeline(query_text)
simple_reward: float = calculate_reward(simple_response, ground_truth)
print(f"简单 RAG 奖励:{simple_reward:.4f}")
# 开始训练循环
for episode in range(params["num_episodes"]):
# 使用相同的查询重置环境
context_chunks: List[str] = retrieve_relevant_chunks(query_text)
state: Dict[str, object] = define_state(query_text, context_chunks)
episode_reward: float = 0 # 初始化当前周期的奖励
episode_actions: List[str] = [] # 初始化当前周期的动作列表
# 每个周期的最大步骤数,防止无限循环
for step in range(10):
# 执行单步强化学习
state, action, reward, response = rl_step(state, action_space, ground_truth)
episode_actions.append(action) # 记录采取的动作
# 如果生成了回答,则结束周期
if response:
episode_reward = reward # 更新周期奖励
# 跟踪最佳回答和奖励
if reward > best_reward:
best_reward = reward
best_response = response
break# 退出循环,周期结束
# 更新奖励和动作历史记录
rewards_history.append(episode_reward)
actions_history.append(episode_actions)
return policy, rewards_history, actions_history, best_responseTHE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。