✅ YOLO获取COCO指标(5): 解决Results do not correspond to current coco set报错 | AP=-1或很低
文章目录
一、 引言
在使用自定义数据集进行 COCO 评估时,开发者常常会遇到一些令人困惑的报错或得到异常的评估结果。本篇博客聚焦于两个最为常见的 COCO 评估拦路虎,和大家一起排查:
- AssertionError:
Results do not correspond to current coco set - 评估结果指标(AP、AR)非常低(接近0)或全部显示为
-1.000
二、 报错分析与解决方案
报错 1: AssertionError: Results do not correspond to current coco set
1. 问题定位
当您运行 COCO 评估脚本(无论是框架内置的还是自定义的),若终端或日志中出现类似以下的 AssertionError,则说明遇到了第一类常见问题。
Traceback (most recent call last):
# ... (省略部分调用栈) ...
File "path/to/pycocotools/coco.py", line 327, in loadRes # pycocotools 内部检查点
assert set(annsImgIds) == (set(annsImgIds) & set(self.getImgIds())), \
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
AssertionError: Results do not correspond to current coco set
2. 原因分析
这个断言错误的核心在于 pycocotools 在加载预测结果 (loadRes 函数) 时,会严格校验预测 JSON 文件中涉及到的所有 image_id 是否与当前 COCO格式的 Ground Truth 标注集中定义的 image_id 集合相符。
annsImgIds: 从 预测 JSON 文件(通常是predictions.json)的"annotations"列表中提取出的所有image_id组成的集合。self.getImgIds(): 从 Ground Truth JSON 文件(例如instances_val2017.json)的"images"列表中提取出的所有图像id组成的集合。
该 assert 语句实际上在检查:预测结果涉及的图像 ID 集合 (set(annsImgIds)) 是否完全等于它与 Ground Truth 图像 ID 集合 (set(self.getImgIds())) 的交集。换句话说,它要求预测结果中的所有 image_id 必须存在于 Ground Truth 的 image_id 集合中,且不允许预测结果包含 Ground Truth 中没有的 image_id。
根本原因 (如视频 [1:10-1:30] 所述): 预测 JSON 文件里的 image_id 与 Ground Truth JSON 文件里 "images" 列表下每个图像对象的 "id" 未能完全对应。
![* **[建议配图 1:并列展示 和 的片段。用红色框突出 中一个 annotation 的 字段,再用蓝色框突出 中对应 列表里一个 image 对象的 字段。用箭头连接两者,并标注“需要严格匹配”。]**](https://i-blog.csdnimg.cn/direct/4caae239231f44c18eaaaed20447c2fb.png)
报错 2: 评估结果指标很低 (例如接近 0) 或全部为 -1.000
1. 问题定位
模型训练过程看似收敛,损失下降正常,但在调用 COCO 评估后,得到的 mAP、AP50、AP75 等指标数值极低(如 0.00x),甚至所有 AP 和 AR 指标都显示为 -1.000。
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.000
2. 原因分析
pycocotools 报告 -1.000 的官方解释是 “-1 for the precision of absent categories”(对于缺失类别的精度为-1)。这意味着,对于某个特定的类别,Ground Truth 中无该类别的标注实例,或预测结果中完全没有检测到该类别的任何目标框。
因此,如果 所有类别 的指标都显示为 -1.000 或极低,这强烈暗示着 **预测结果与 Ground Truth 中的 category_id 之间存在系统性的不匹配,或者image_id之间存在系统性的不匹配。评估工具无法将预测框与任何真实标注框对应起来计算 TP/FP。
导致这种不匹配的常见原因如下:
-
image_id不对应:- 预测 JSON (
predictions.json内的"image_id") 与 Ground Truth JSON (instances_*.json内"annotations"列表中的"image_id")不一一对应。
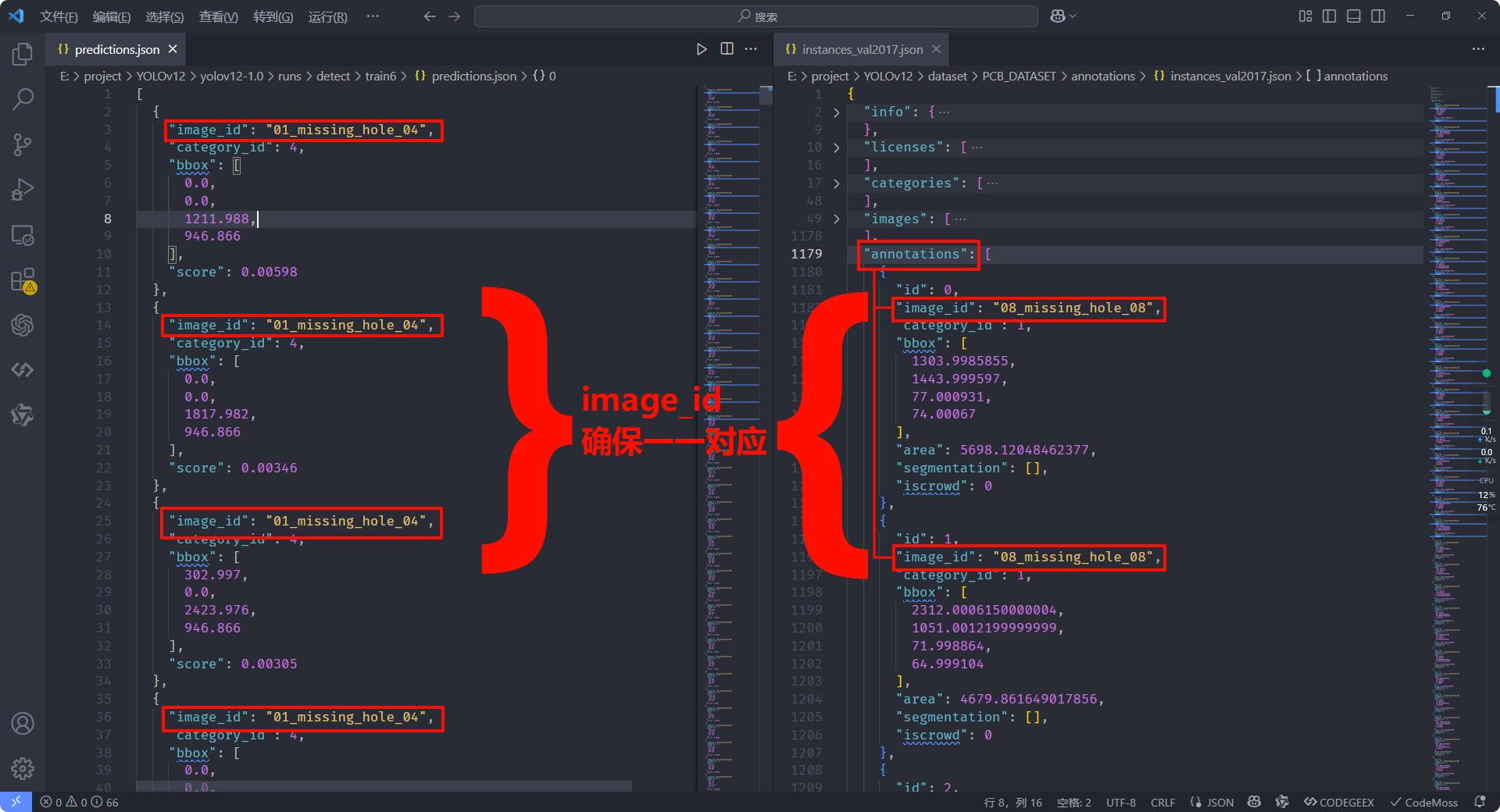
- 预测 JSON (
-
category_id值或范围不一致:-
预测 JSON (
predictions.json内的"category_id") 使用的 ID 集合与 Ground Truth JSON (instances_*.json内"annotations"列表中的"category_id") 使用的 ID 集合不匹配。
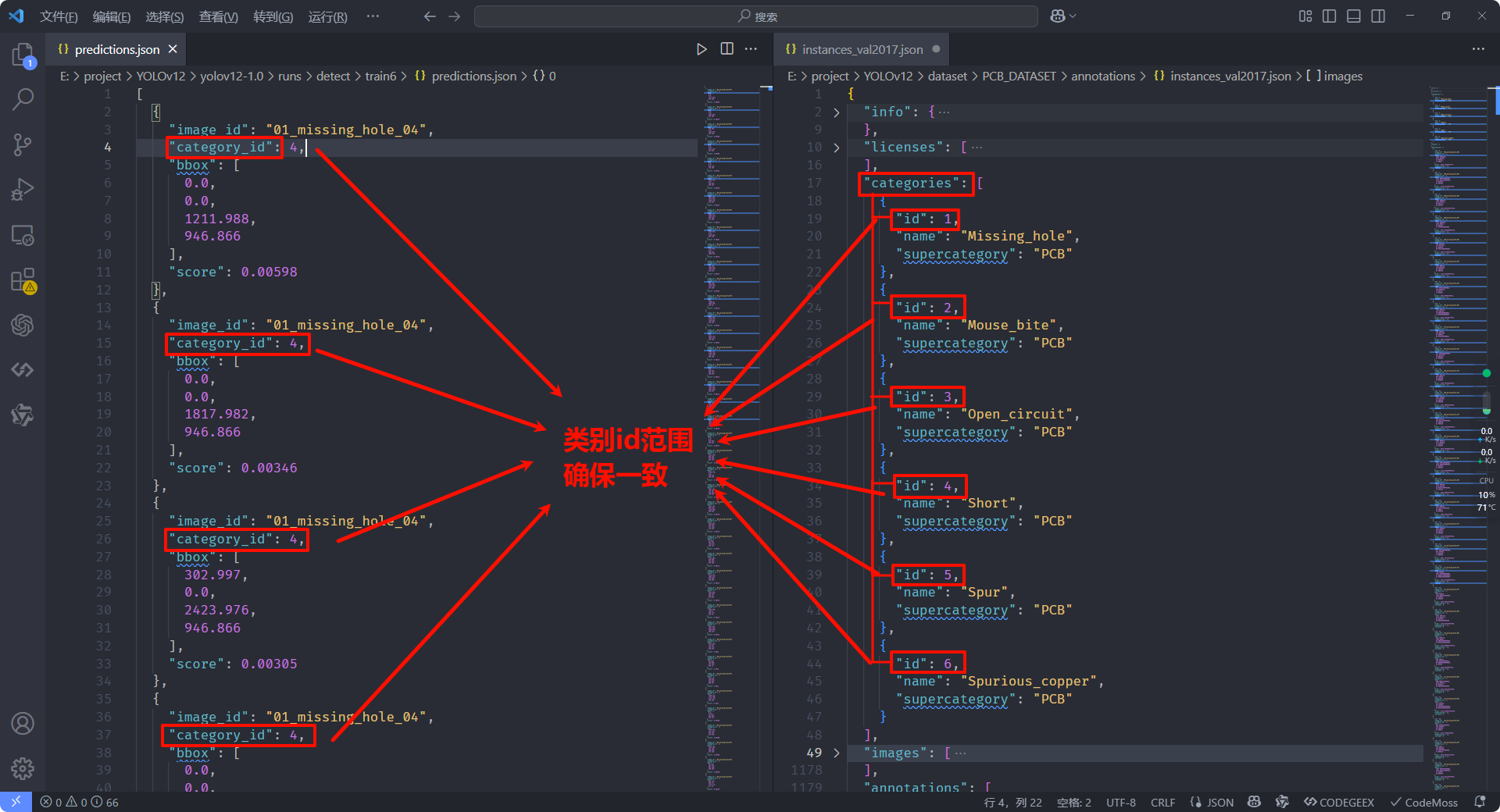
-
Ground Truth JSON 内部不一致:
"categories"列表定义的类别"id"与同文件内"annotations"中使用的"category_id"不一致。
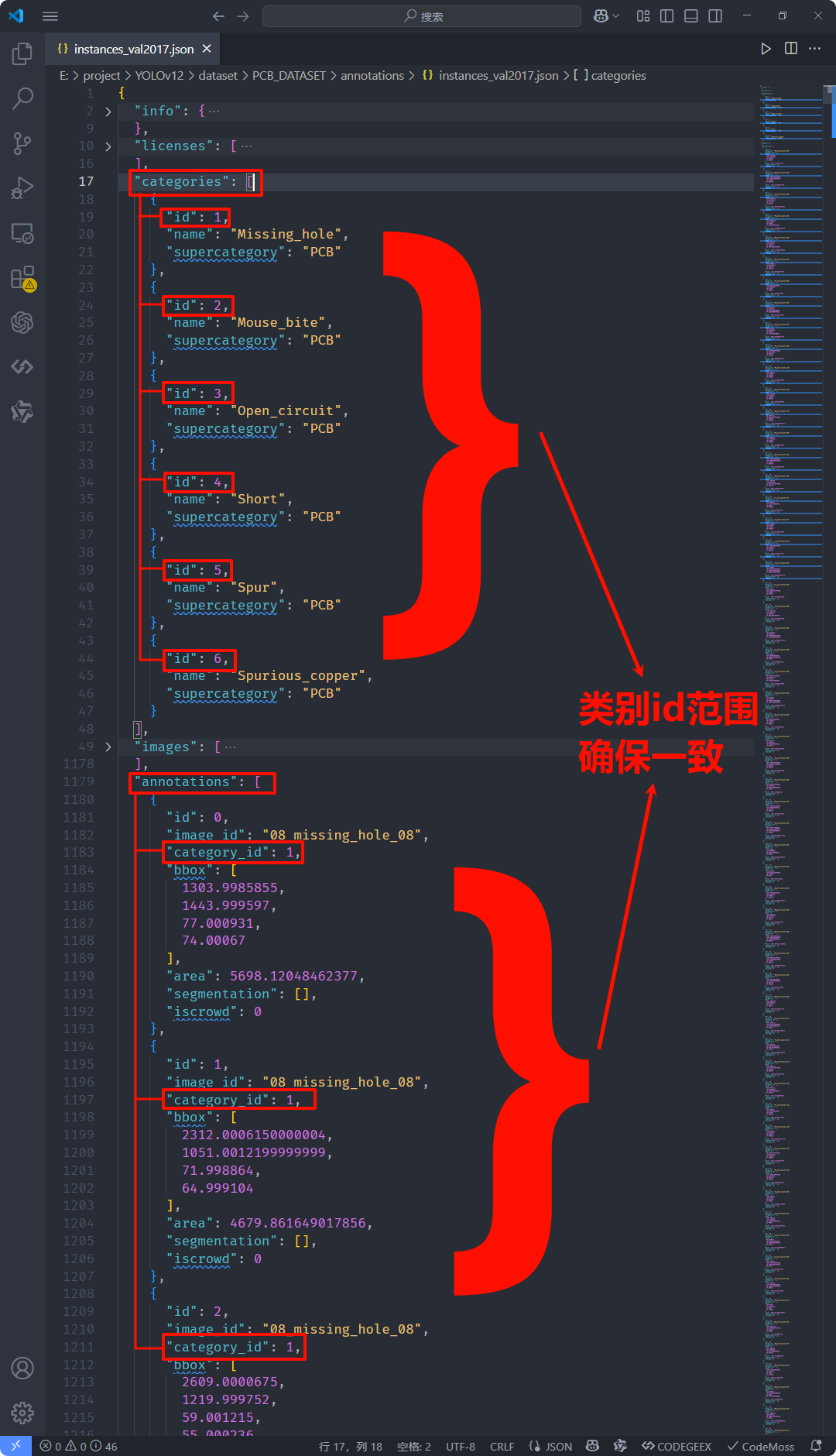
-
预测 JSON 与 GT 类别定义顺序不一致: 预测 JSON 中的
"category_id"(追溯到数据集yaml文件)与 Ground Truth JSON 中"categories"列表定义的类别"id"(追溯到转coco数据集的classes.txt文件)顺序不一致。
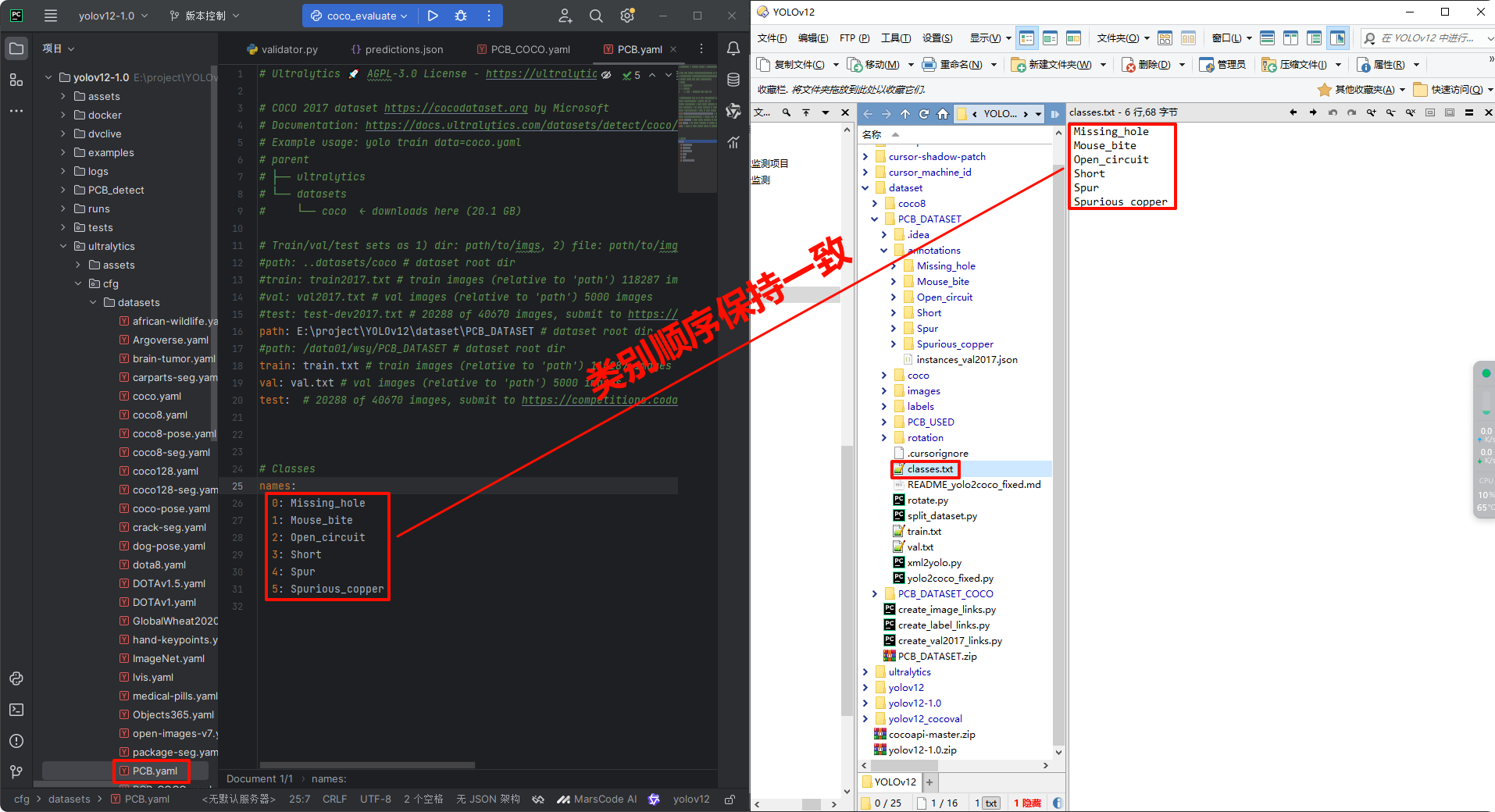
-
三、 排查建议
当你遇到 COCO 评估问题时,建议按照以下步骤系统排查:
- 从简入手: 使用一个仅包含几张图片和对应标注的最小验证集进行测试。手动检查这两个小型的 JSON 文件,确认
image_id和category_id是否完全按预期匹配。 - JSON 格式校验: 使用在线 JSON Linter 或 Python 的
json库加载文件,检查 Ground Truth JSON 和 Prediction JSON 是否为有效的 JSON 格式,且结构符合 COCO 要求。 - ID 逐个对比: 随机挑选几个图像样本,手动在
predictions.json和instances_val2017.json中找到对应的条目,仔细核对image_id和category_id的值和类型。 - 坐标系与格式: 确认
bbox坐标 ([x_min, y_min, width, height]) 的格式和在两个文件中一致且正确。不正确的坐标也会导致 IoU 计算错误,进而影响 AP。
四、 总结
COCO 评估过程中遇到的 AssertionError: Results do not correspond to current coco set 和 指标全为 -1.000 或极低的问题,绝大多数情况是由于 预测结果 JSON 与 Ground Truth JSON 之间的数据不一致造成的,尤其是 image_id 和 category_id 的匹配问题。
解决关键:
image_id一致性: 确保预测与 GT 使用相同的图像集,并且image_id在值、类型、集合上完全匹配。category_id一致性: 确保预测与 GT 使用相同的类别 ID,category_id的范围与顺序保持严格统一。
通过遵循本文提供的分析思路、解决方案和排查建议,细致地检查数据处理流程和评估代码配置,你将能有效地解决这些常见的 COCO 评估障碍,获取准确、可靠的模型性能指标。
参考文献:
- COCO Dataset 官方文档 (格式与评估):
pycocotoolsGitHub Repository: https://github.com/cocodataset/cocoapi (了解 API 源码和实现细节)- Ultralytics YOLO 文档:
- MMDetection 文档: