目录
Jetson AGX Orin Series Hardware Architecture
▲ 3rd Generation Tensor Cores and Sparsity
▲ Get the most out of the Ampere GPU using NVIDIA Software Libraries
■ Giant Leap Forward in Performance
Introduction
当今的自主机器和边缘计算系统是由日益增长的人工智能软件需求所定义的。运行简单卷积神经网络进行目标检测和分类等推理任务的固定功能设备无法跟上每天出现的新网络:转换器对于服务机器人的自然语言处理非常重要;强化学习可以用于制造与人类并肩作战的机器人;而各种应用都需要自动编码器、长短期记忆网络( LSTM )和生成对抗网络( GAN )。
NVIDIA ® Jetson平台是解决这些边缘复杂AI系统需求的理想解决方案。该平台包括Jetson模块,它们是小型的形状因子,高性能的计算机,用于端到端AI管道加速的JetPack SDK,以及具有传感器、SDK、服务和产品的生态系统,以加快开发。Jetson由相同的AI软件和在其他NVIDIA平台上使用的云原生工作流提供动力,并交付性能和能效客户需要在边缘构建软件定义的智能机器。对于制造、物流、零售、服务、农业、智慧城市和医疗保健等领域的高级机器人和其他自主机器,Jetson平台是理想的解决方案。
Jetson AGX Orin系列是Jetson家族的最新成员,为机器人和边缘AI提供了一个巨大的飞跃。借助Jetson AGX Orin模块,客户现在可以部署大型复杂的模型来解决诸如自然语言理解、3D感知和多传感器融合等问题。在本技术简报中,详细介绍了Jetson AGX Orin系列的新架构,以及客户可以采取的步骤,以充分利用Jetson平台的全部功能。
Jetson AGX Orin Series Hardware Architecture
NVIDIA ® Jetson AGX Orin系列提供服务器类性能,为自主系统供电的AI性能高达275 TOPS。Jetson AGX Orin系列包括Jetson AGX Orin 64GB和Jetson AGX Orin 32GB模块。这些功率高效的模块上系统( system-on-module,SOM )是采用Jetson AGX Xavier的形因子和管脚兼容,提供高达8倍的AI性能。Jetson AGX Orin模块以NVIDIA Orin SoC为基础,采用NVIDIA Ampere架构GPU,Arm & Cortex & A78AE CPU,新一代深度学习和视觉加速器,以及视频编码器和视频解码器。高速IO、204GB / s的内存带宽以及32GB或64GB的DRAM使这些模块能够为多个并发的AI应用流水线提供支持。通过SOM设计,NVIDIA围绕SoC做了大量的提升设计,不仅提供了计算和I/O,还提供了电源和存储器设计。详细信息参见Jetson AGX Orin系列数据表1,Jetson Download Center | NVIDIA Developer。
图1 Jetson AGX Orin传递8X Jetson AGX Xavier的AI性能。
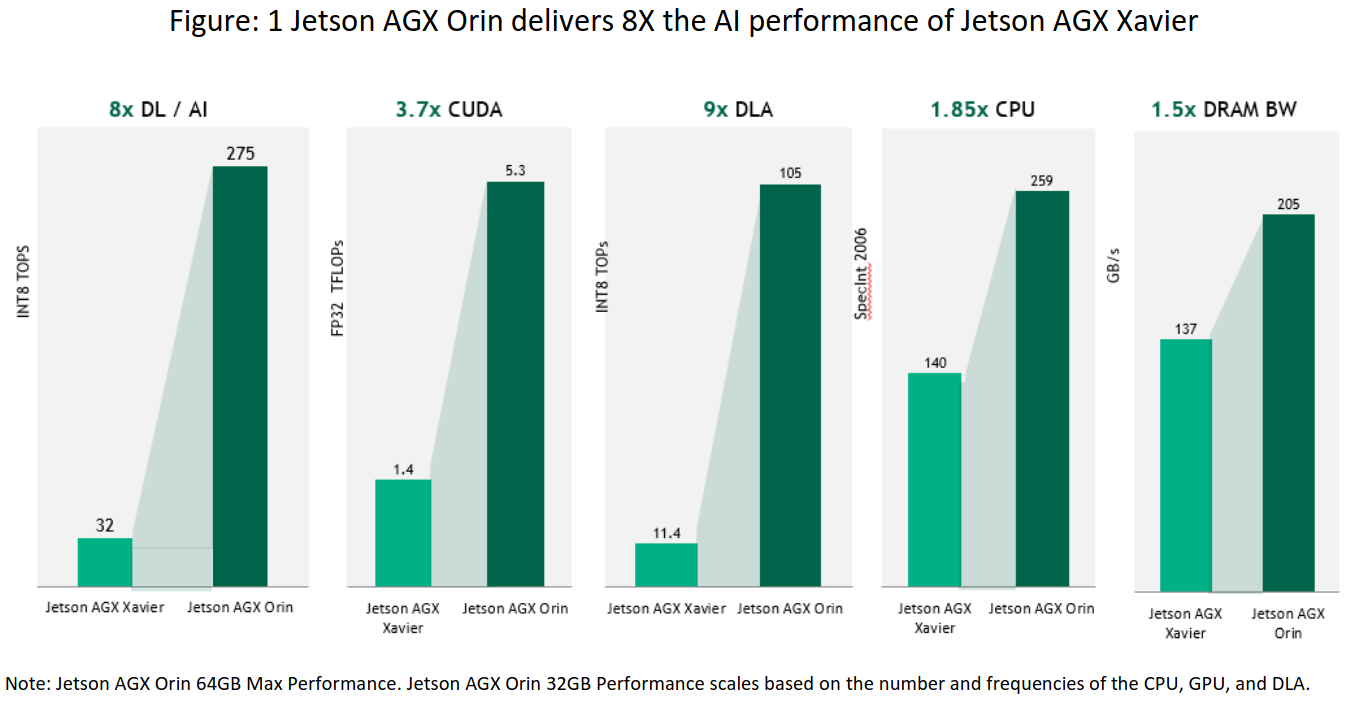
图2:Orin System-On-chip ( Soc )框图。
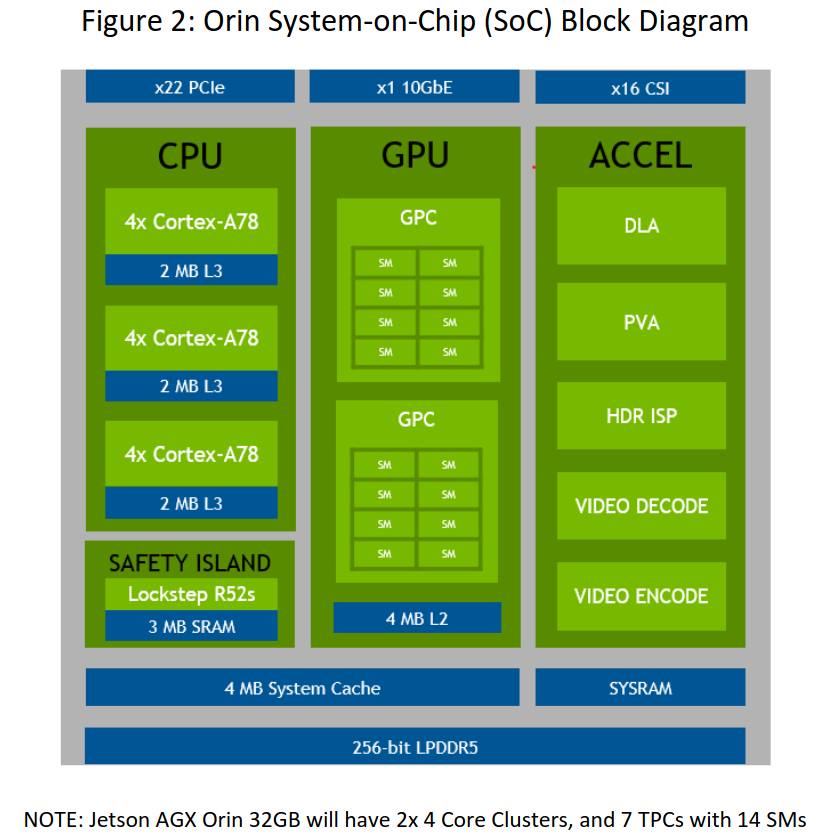
图3:Jetson Agx Orin系列System-On-Module。
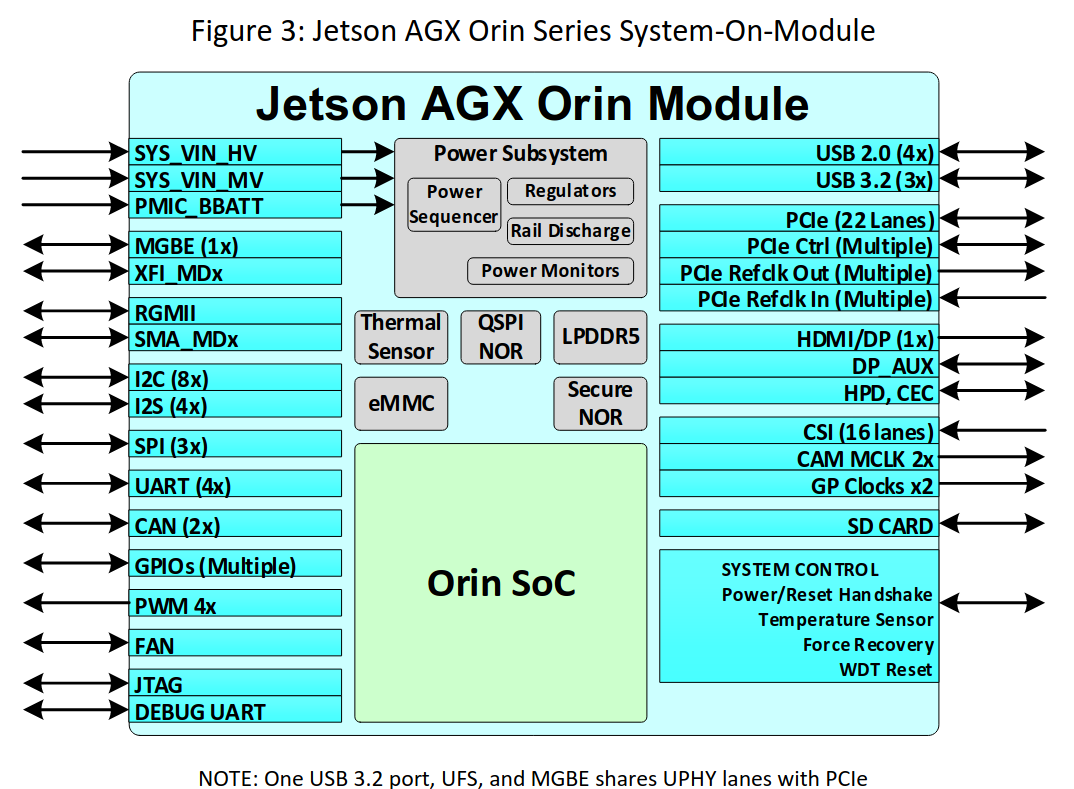
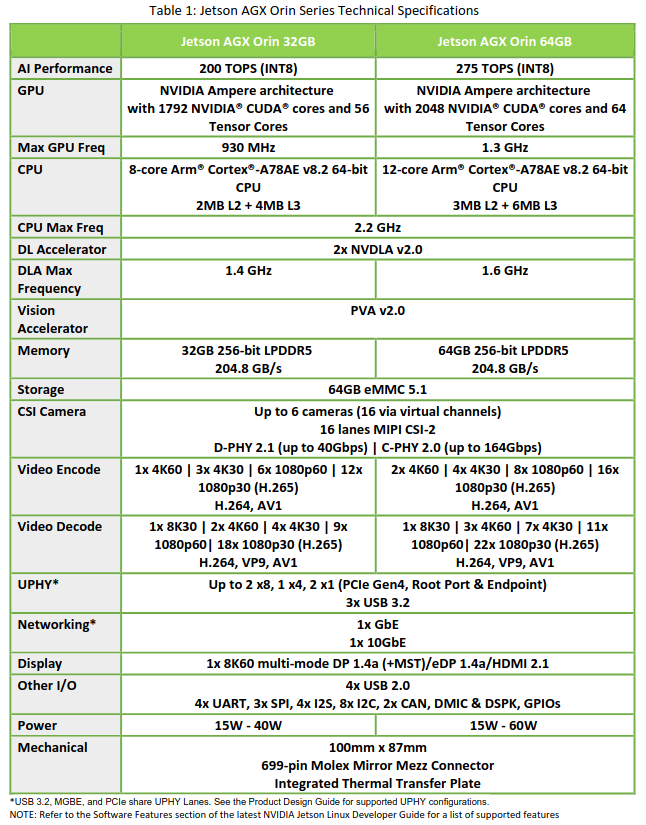
表1:Jetson Agx Orin系列技术规范。
■ GPU
Jetson AGX Orin模块包含一个集成的Ampere GPU,由2个图形处理集群( GPCs )、多达8个纹理处理集群( TPCs )、多达16个流式多处理器( SM的)、每个SM 192 KB的L1-cache和4 MB的L2 Cache组成。与Volta的64个CUDA核相比,Ampere每个SM有128个CUDA核,每个SM有4个第三代张量核。Jetson AGX Orin 64GB拥有2048个CUDA核心和64个Tensor核心,其中INT8 Tensor计算的Sparse TOP高达170个,高达5.3CUDA计算的FP32 TFLOPs。
对Tensor内核进行了增强,与上一代相比在性能上有了很大的飞跃。借助Ampere GPU,带来了对稀疏性的支持。稀疏性是一种细粒度的计算结构,可以成倍地提高吞吐量并减少内存使用。
图4:Orin Ampere GPU程序框图。

注:以上图示Jetson AGX Orin 64GB。Jetson Agx Orin 32Gb将有7个Tpcs和14个SMS。
▲ 3rd Generation Tensor Cores and Sparsity
NVIDIA Tensor内核提供了加速下一代人工智能应用所需的性能。张量核是可编程的融合矩阵乘累加单元,与CUDA核并行执行。张量核执行浮点HMMA (半精度矩阵相乘和累加)和IMMA (整数矩阵的倍数和累加)指令,用于加速稠密线性代数计算、信号处理和深度学习推理。
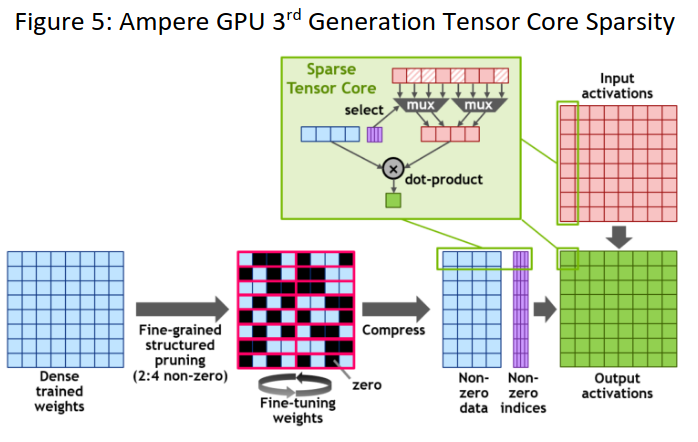
安培提供了对第三代Tensor核的支持,使其支持16x HMMA、32x IMMA和一种新的稀疏特性。通过稀疏特性,客户可以利用深度学习网络中的细粒度结构化稀疏性,将Tensor核操作的吞吐量提高一倍。稀疏度被限制在每4个权重中的2个非零。它可以使Tensor核跳过零值,成倍地提高吞吐量,并显著地减少内存存储。网络可以先在稠密权重上训练,然后剪枝,然后在稀疏权重上微调。
图5:安培GPU 3RD生成张量核稀疏度。
▲ Get the most out of the Ampere GPU using NVIDIA Software Libraries
客户可以使用NVIDIA TensorRT和cuDNN在GPU上加速他们的推断。NVIDIA TensorRT是深度学习推理的运行时库和优化器,可以在NVIDIA GPU产品中提供更低的延迟和更高的吞吐量。TensorRT通过将模型量化到INT8,通过融合内核中的节点来优化GPU内存和带宽的使用,并基于目标GPU选择最佳的数据层和算法,使客户能够解析训练好的模型并最大限度地提高吞吐量。
Cu DNN ( CUDA深度神经网络库)是一个GPU加速的深度神经网络图元库。它提供了在DNN应用中常见的例程的高度调整的实现,如卷积前向和后向,互相关,池化前向和后向,softmax前向和后向,张量转换函数等。借助Ampere GPU和NVIDIA软件栈,客户可以处理每天都在发明的新的、复杂的神经网络。
■ DLA
NVIDIA Deep Learning Accelerator,简称DLA,是一款针对深度学习操作而优化的固定函数加速器。旨在对卷积神经网络推理进行全硬件加速。Orin SoC以9倍于NVDLA 1.0的性能为下一代NVDLA 2.0提供了支持。
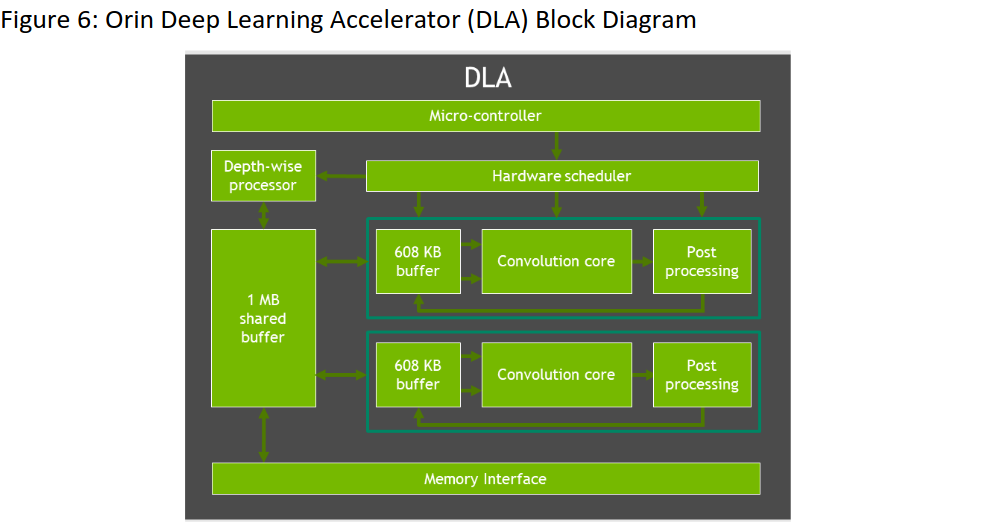
DLA 2.0提供了一种高能效的架构。通过这种新的设计,NVIDIA增加了本地缓冲以提高效率,并减少了DRAM带宽。DLA 2.0额外增加了一组新特性,包括结构化稀疏性、深度卷积和硬件调度器。这使得Jetson AGX Orin DLAs上的INT8 Sparse TOPs总数达到105个,而Jetson AGX Xavier DLAs上的INT8 Dense TOPS总数为11.4个。
图6:Orin深度学习加速器( Dla )框图。
▲ TensorRT supports DLA
客户可以像在GPU上一样使用TensorRT,在DLA上加速他们的模型。NVIDIA DLAs旨在从GPU上卸载深度学习推断,使GPU能够运行更复杂的网络和动态任务。TensorRT支持在DLA上的INT8或FP16中运行网络,并支持卷积、反卷积、全连接、激活、池化、批量归一化等各种层。关于TensorRT中DLA支持的更多信息可以在这里找到:Overview — NVIDIA TensorRT Documentation。NVIDIA DLAs能够支持多种模型和算法,以实现3D构建、路径规划、语义理解等。根据需要何种类型的计算,DLA和GPU都可以实现充分的应用加速。
■ Giant Leap Forward in Performance
随着GPU和DLA的增强,Jetson AGX Orin系列在性能上提供了巨大的飞跃。随着多传感器感知、地图构建与定位、路径规划与控制、态势感知和安全等功能的计算需求呈数量级增长,一个新的机器人时代正在到来。
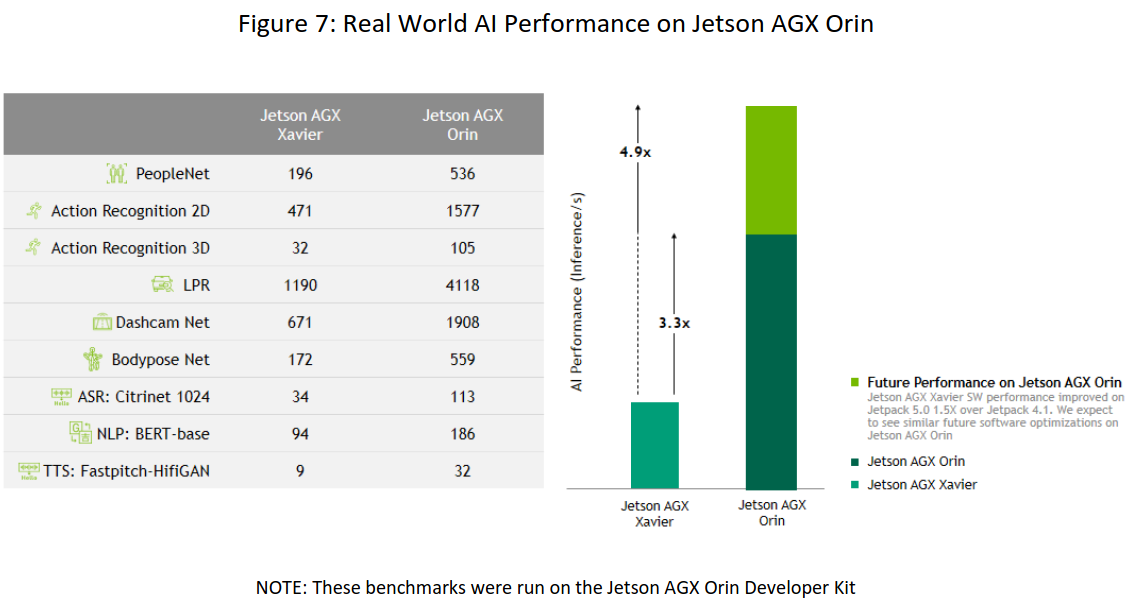
特别是,机器人技术和其他边缘AI应用对计算机视觉和对话式AI的需求越来越大。Jetson AGX Orin模块在真实世界AI应用上的性能是Jetson AGX Xavier的3.3倍,这可以从我们的预训练模型中看到。我们预计这将会随着未来的软件更新而增加近5倍的性能提升。( Jetson AGX Xavier从推出到现在,性能提升了1.5倍,采用了最新的Jetpack软件。)。
图7:真实世界ai在Jetson Agx Orin上的表现。
■ CPU
对于Jetson AGX Orin系列模块,我们从NVIDIA Carmel CPU迁移到Arm Cortex - A78AE。Orin CPU复合体拥有多达12个CPU核。每个核心包括64KB的指令L1 Cache和64KB的数据Cache,以及256KB的L2 Cache。与Jetson AGX Xavier一样,每个集群也有2MB的L3 Cache。最大支持CPU频率2.2 GHz。
图8:Orin Cpu框图。
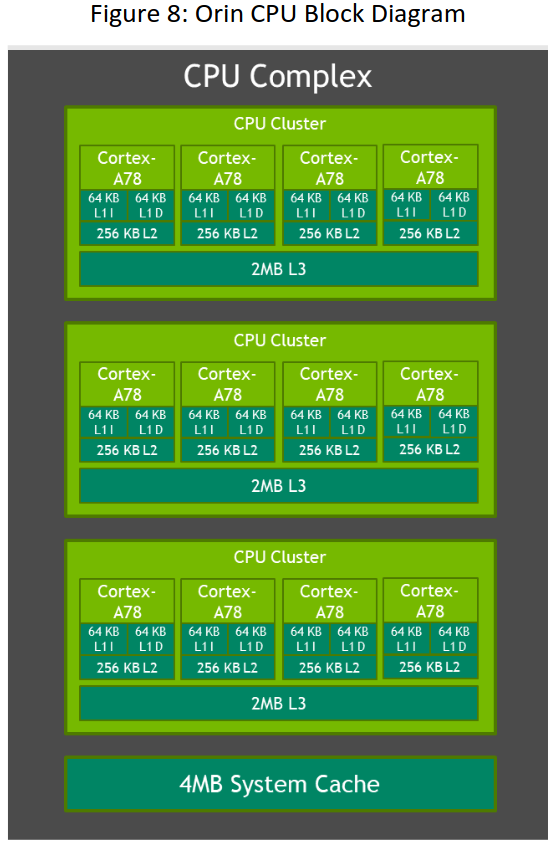
注:以上图示Jetson AGX Orin 64GB。Jetson Agx Orin 32Gb将拥有2 × 4的核心簇。
与Jetson AGX Xavier上的8核NVIDIA Carmel CPU相比,Jetson AGX Orin 64GB上的12核CPU能够提供近1.9倍的性能。客户可以使用Cortex - A78AE的增强功能,包括更高的性能和增强的缓存来优化他们的CPU实现。
■ Memory & Storage
Jetson AGX Orin模块支持1.4倍于Jetson AGX Xavier的存储带宽和2倍于Jetson AGX Xavier的存储容量,支持32GB或64GB的256位LPDDR5和64GB的eMMC。该DRAM支持最高3200 MHz的时钟速度,每引脚6400 Gbps,可支持204.8 GB / s的存储带宽。图8强调了各个组件如何与内存控制器Fabric和DRAM进行交互。
图9:Jetson Agx Orin系列功能块图。
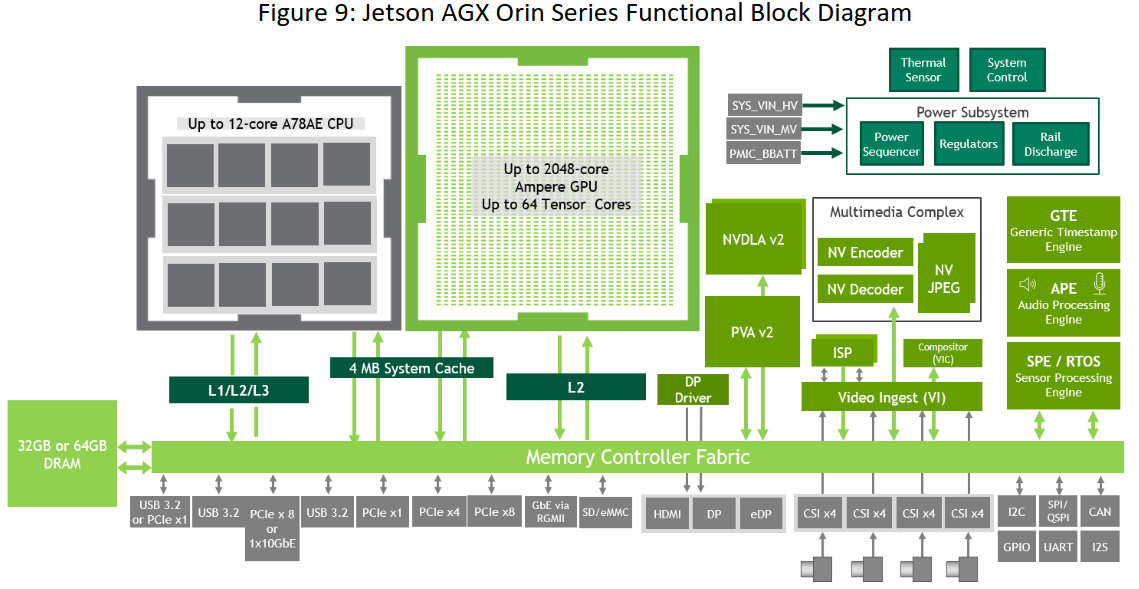
■ Video Codecs
Jetson AGX Orin模块包含多标准视频编码器( NVENC )、多标准视频解码器( NVDEC )和JPEG处理模块( NVJPEG )。NVENC实现了包括H.265、H.264和AV1在内的各种编码标准的全硬件加速。NVDEC可以对包括H.265,H.264,AV1,VP9在内的各种解码标准进行完全的硬件加速。NVJPG负责JPEG (de)压缩计算(基于JPEG静止图像标准)、图像缩放、解码( YUV420、YUV422H / V、YUV444、YUV400)和颜色空间转换( RGB到YUV)。完整的标准清单请参考Jetson AGX Orin Series Data Sheet:Jetson Download Center | NVIDIA Developer。客户可以利用NVIDIA Jetson的多媒体API为这些引擎提供动力。多媒体API:Jetson Linux API Reference: Main Page | NVIDIA Docs是底层API的集合,支持跨这些引擎的灵活应用开发。
■ PVA & VIC
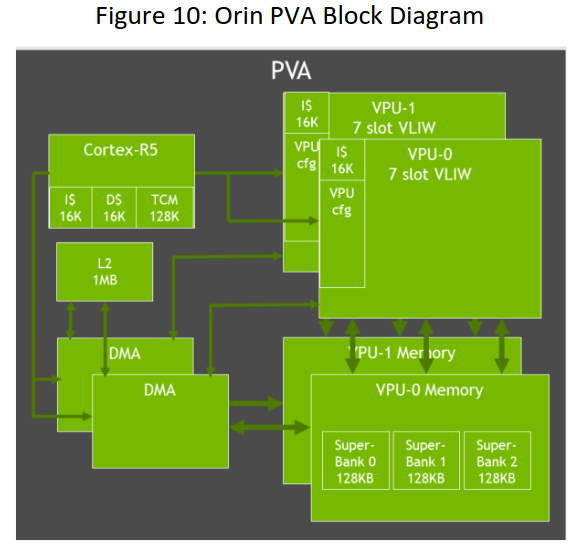
Jetson AGX Orin模块为我们的下一代可编程视觉加速器引擎PVA v2提供了支持。PVA引擎包括两个7路VLIW (超长指令字)向量处理单元、两个DMA引擎和一个Cortex - R5子系统。PVA支持各种计算机视觉内核,如滤波、变形、图像金字塔、特征检测和FFT。使用PVA的一些常见的计算机视觉应用包括特征检测器、特征跟踪器、目标跟踪器、立体视差和视觉感知。
图10:Orin Pva框图。
Orin SoC还包含一个Gen 4.2 Video Imaging Compositor( VIC ) 2D引擎。VIC支持各种图像处理功能,如镜头畸变校正和增强的时间噪声降低,视频功能,如清晰度增强,以及一般的像素处理功能,如颜色空间转换,缩放,混合和组合。
视觉编程接口( Vision Programming Interface,VPI )是在包括PVA、VIC、CPU和GPU在内的多个NVIDIA Jetson硬件组件上实现计算机视觉和图像处理算法的软件库。在PVA和VIC上支持VPI算法,可以将计算机视觉和图像处理任务卸载到它们上,并将CPU和GPU优先用于其他任务。
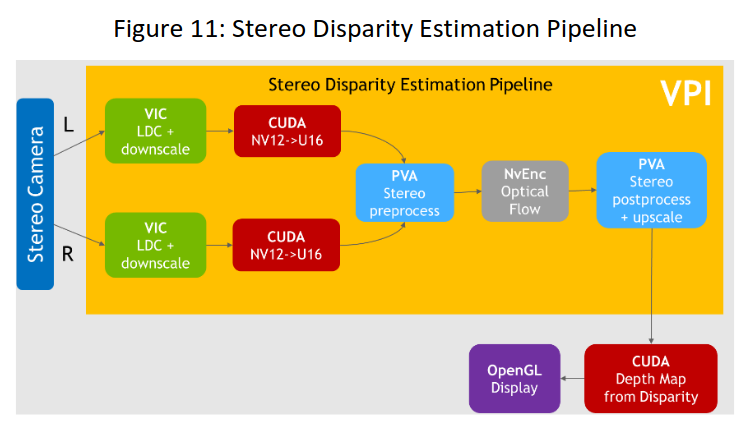
作为一个例子,使用VPI的完整立体视差估计流水线可以有效地使用包括VIC,PVA和NVENC在内的多个后端。管道接收来自立体相机的输入,这些图像是立体对的左图和右图。VIC在此输入上工作,校正镜头畸变,将图像向下缩放,得到校正后的立体像对。然后使用GPU将图像从颜色转换为灰度,并将结果输入到使用PVA和NVENC作为后端的一系列操作中。输出是对输入图像之间视差的估计,与场景深度有关。
图11:立体视差估计流水线。
VPI包含了许多算法,从图像处理的组成模块,如盒子滤波,卷积,图像缩放和重映射,到更复杂的计算机视觉算法,如Harris角点检测,KLT特征跟踪,光流,背景减除等。
■ I/O
Jetson AGX Orin系列模块包含丰富的高速I/O,包括22路PCIe Gen4、千兆以太网、1个用于10千兆以太网的XFI接口、1个Display Port、16路MIPI CSI - 2、USB3.2接口以及I2C、I2S、SPI、CAN、GPIO、USB 2.0、DMIC、DSPK等多种I / O。用户可以使用USB 3.2、UFS、PCIe和MGBE的UPHY通道,并且这些接口之间共享一些UPHY通道。PCIe的22个通道均支持根端口模式,部分通道还支持端点模式。在DP1.4上使用多流模式,Display Port可以支持2个显示器。Jetson被用于各种具有不同I / O需求的应用程序中。例如,自主地面车辆可以利用CSI摄像头观察机器人周围的环境景观,I2S用于语音命令,HDMI用于显示,PCIe用于Wi-Fi,GPIO & I2C等。像路口交通管理这样的视频分析应用可能需要许多GigE Camera和以太网用于联网。随着自治机器继续执行更高级的任务,需要更多的I / O来接口更多的传感器。
表2:Jetson Agx Orin I/O。

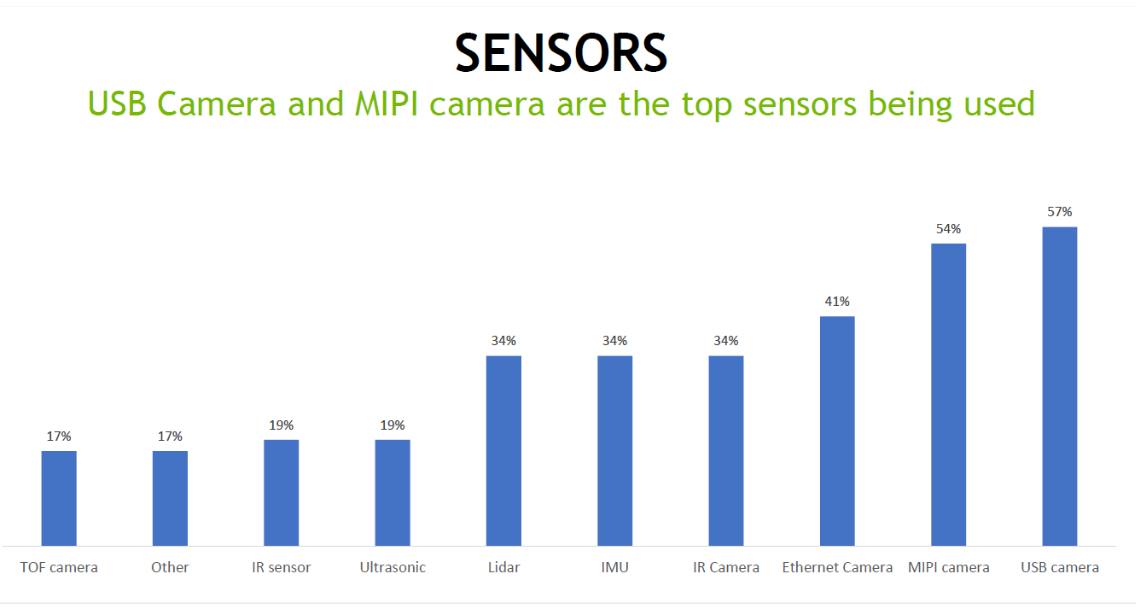
在2021年3月NVIDIA的一项调查中,当被问及您的项目正在使用哪些传感器和传感器接口时,大多数客户回答说,他们通过USB、MIPI和以太网使用相机。Jetson AGX Orin不仅支持所有这些接口,而且支持调查中列出的所有其他传感器。
图12:Jetson客户与开发者调查- -传感器使用情况。
■ Power Profiles
Jetson AGX Orin系列模块设计了高效的电源管理集成电路( PMIC )、稳压器和电源树,以优化电源效率。Jetson AGX Orin 64GB支持3种优化功率预算:15W、30W和50W。每个功率模式包含不同的组件频率,以及在线CPU、GPU TPC、DLA和PVA核的数量。Jetson AGX Orin 64GB还支持MAXN性能模式,可以实现高达60W的性能。Jetson AGX Orin 32GB支持15W ~ 40W之间的功率模式。客户可以利用Jetson Linux中的nvpmodel工具使用这些预先优化的电源模式之一,或者在我们的文档中提供的设计约束内自定义自己的电源模式。
Jetson Software
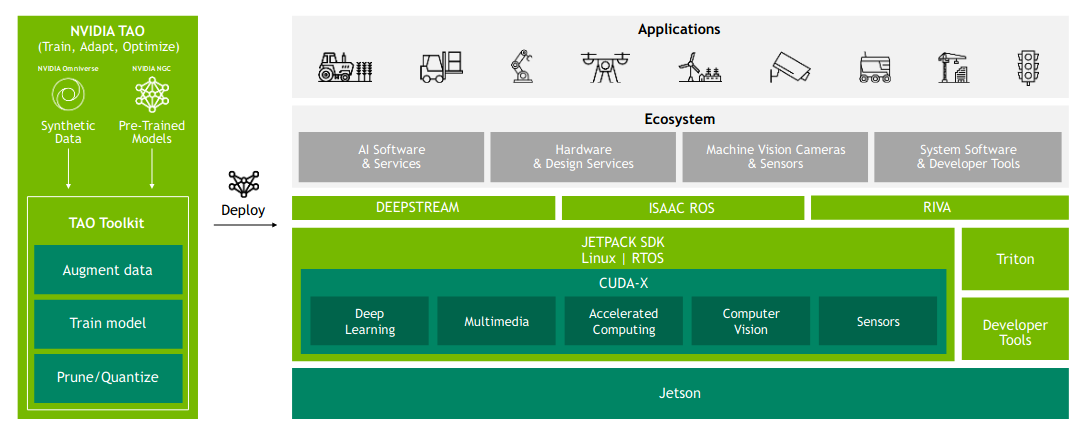
Jetson平台包含了所有必要的软件,以加速你的开发,并使你的产品快速推向市场。软件栈的基础是JetPack SDK。它包括板级支持包( BSP )、引导加载程序、Linux内核、驱动程序、工具链和基于Ubuntu的参考文件系统。BSP还支持多种安全功能,如安全引导、可信执行环境、磁盘和内存加密等。在BSP上,我们有几个用户级库,用于加速应用程序的各个部分。其中包括用于加速深度学习的库,如CUDA、CuDNN和Tensor RT;cu BLAS、cu FTT等加速计算库;加速的计算机视觉和图像处理库,如VPI;以及多媒体和相机库,如libArgus和v4l2。
在JetPack之上还有更高级别的、针对用例的SDK,包括面向智能视频分析应用的DeepStream、面向机器人应用的Isaac、面向自然语言处理应用的Riva等。围绕这个NVIDIA有一个不断增长的合作伙伴生态系统,可以为客户提供特殊的产品和服务,以加快发展。
边缘处的AI越来越大,边缘部署的复杂度也越来越高。我们看到在创造AI产品的过程中产生的各种挑战。准确的训练需要大量的数据,而推理则需要对模型进行优化。来自开源选项的高性能模型并没有提供理想的结果,也没有优化以获得最高的推理吞吐量。还需要各种框架的支持,以及对深度学习和数据科学的深入理解。NVIDIA的TAO Toolkit和预训练模型( PTM )可以帮助解决这一挑战。NVIDIA预训练模型为客户提供经过数百万张图像预训练的精确模型,以达到最先进的出箱精度。预训练的模型库可以在这里找到:TAO Toolkit | NVIDIA Developer,包括各种PTM,如人检测,车辆检测,自然语言处理,姿态估计,车牌检测和人脸检测。TAO工具包使客户具有使用自己的数据集轻松训练、微调和优化这些预训练模型的能力。客户可以很容易地使用我们的各种推理SDK在生产中部署这些模型。
边缘计算在历史上的特点是系统很少得到软件更新。随着新的云技术,你需要能够在你部署的产品上周期性地更新软件,并且具有灵活的适应性,并且容易在各种环境中扩展和部署。Jetson将Cloud - Native推向了边缘,并启用了容器和容器编排等技术。NVIDIA JetPack包含了NVIDIA Container Runtime与Docker的集成,实现了Jetson平台上GPU加速的容器化应用。JetPack还带来了对NVIDIA TritonTM Inference Server的支持,以简化AI模型在规模上的部署。Triton推理服务器是开源的,提供了一个单一的标准化推理平台,可以支持多个框架模型在数据中心、云和嵌入式设备等不同部署中的推理。它通过先进的批处理和调度算法支持不同类型的推理查询,以最大限度地提高AI应用程序的性能,并支持零推理停机的实时模型更新。
图13:Jetson云原生软件栈。
JetPack5.0提供了为Jetson AGX Orin和未来的Jetson模块以及基于NVIDIA Xavier SoC的现有Jetson模块供电的软件。JetPack5.0包括Linux内核为5.10的L4T和基于Ubuntu 20.04的参考文件系统。JetPack5.0使用CUDA 11 . x和新版本的cu DNN和Tensor RT实现了全计算堆栈更新。它将包括UEFI作为CPU引导程序,也将带来对OP-TEE作为可信执行环境的支持。最后,将对NVDLA 2.0的DLA支持进行更新,以及对下一代PVA v2的VPI支持进行更新。
Jetson AGX Orin Developer Kit
Jetson AGX Orin Developer Kit将包含开发人员快速上手和运行所需的一切。Jetson AGX Orin Developer Kit包括带散热器的Jetson AGX Orin模块、参考载板和电源。Jetson AGX Orin Developer开发包可以通过仿真模式对Jetson Orin的所有模块进行开发,以仿真其性能。在15 ~ 60 W之间,AI的性能和功率可配置高达275 TOPS,客户现在拥有超过8倍于Jetson AGX Xavier的性能,以开发先进的机器人和其他自主机器产品。Jetson AGX Orin Developer Kit现已上市。
图13:Jetson Agx Orin Developer Kit。

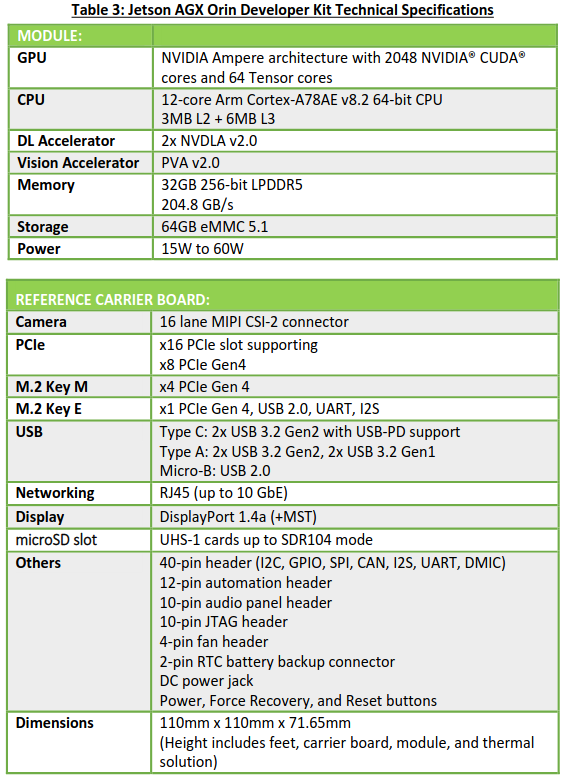
表3:Jetson Agx Orin Developer Kit技术规范。
至此,本文的内容就结束啦。