目录

1. 前言
生成对抗网络(GAN)自提出以来,因其在生成高质量数据方面的潜力而备受关注。然而,传统GAN在训练过程中常常面临不稳定、梯度消失和模式崩溃等问题。为了解决这些问题,Wasserstein GAN(WGAN)应运而生。WGAN通过引入Wasserstein距离(也称为Earth Mover's距离)作为损失函数,提供了更稳定的训练过程和更清晰的收敛信号。
本文将详细介绍WGAN的理论基础,并通过一个完整的PyTorch实现案例,帮助大家深入理解WGAN的工作原理和实际应用。
2. WGAN的理论基础
2.1 传统GAN的局限性
传统GAN通过最小化生成分布和真实分布之间的Jensen-Shannon(JS)散度进行训练。然而,JS散度在生成分布和真实分布不重叠时会变得不可微,导致梯度消失问题。此外,GAN的训练过程通常不稳定,容易出现模式崩溃。
2.2 Wasserstein距离
Wasserstein距离(也称为Earth Mover's距离)是衡量两个概率分布之间差异的一种度量。其核心思想是计算将一个分布的“土堆”移动到另一个分布所需的最小“工作量”。Wasserstein距离的一个重要特性是,即使两个分布不重叠,它也能提供有意义的梯度。
数学上,Wasserstein距离可以表示为:
![]()
其中,Π(pr,pg) 是所有可能的联合概率分布的集合。
通过Kantorovich-Rubinstein对偶性,Wasserstein距离可以重新表述为:
![]()
这里,h 是一个1-Lipschitz函数。
2.3 WGAN的改进与算法原理
WGAN的核心思想是用Wasserstein距离代替JS散度作为损失函数,并且满足1-Lipschitz约束,其余与GAN相差不多。
具体来说,WGAN引入了一个称为“Critic”的网络,用于估计真实数据和生成数据之间的Wasserstein距离。Critic的目标是最大化真实数据和生成数据之间的差异,而生成器的目标是最小化这个差异。
-
Critic的损失函数:
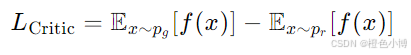
-
其中,f 是Critic网络的输出。
-
Wasserstein距离衡量的是生成分布和真实分布之间的差异。WGAN的目标是通过最小化这个距离来训练生成器和Critic。Critic网络的输出 f(x) 可以看作是对输入数据的评分,表示数据有多“真实”。
-
生成器的损失函数:
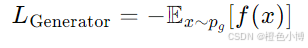
生成器的目标是生成的数据尽可能接近真实数据,从而欺骗Critic。为了实现这个目标,生成器希望最大化Critic对生成数据的评分。换句话说,生成器希望Critic认为生成的数据是真实的。
为了确保Critic满足1-Lipschitz约束,WGAN通过权重裁剪(weight clipping)来限制Critic的权重范围。这种方法虽然简单,但在实践中非常有效。
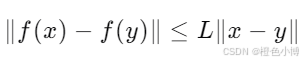
3. WGAN的PyTorch实现:生成以假乱真的数字图像
3.1 环境准备
确保安装了PyTorch、NumPy和Matplotlib等库:
pip install torch torchvision numpy matplotlib3.2 定义生成器和Critic
import torch
import torch.nn as nn
# 定义生成器
class Generator(nn.Module):
def __init__(self, input_dim, output_dim):
super(Generator, self).__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, 128),
nn.ReLU(),
nn.Linear(128, 256),
nn.ReLU(),
nn.Linear(256, output_dim),
nn.Tanh()
)
def forward(self, x):
return self.net(x)
# 定义Critic
class Critic(nn.Module):
def __init__(self, input_dim):
super(Critic, self).__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 128),
nn.LeakyReLU(0.2),
nn.Linear(128, 1)
)
def forward(self, x):
return self.net(x)3.3 训练过程
import itertools
# 超参数设置
latent_dim = 100 # 隐变量维度
output_dim = 784 # 输出维度(例如MNIST数据集的784像素)
epochs = 100000 # 训练轮数
n_critic = 5 # 每次生成器更新前Critic更新的次数
clip_value = 0.01 # 权重裁剪范围
# 初始化生成器和Critic
generator = Generator(latent_dim, output_dim)
critic = Critic(output_dim)
# 定义优化器
opt_gen = torch.optim.RMSprop(generator.parameters(), lr=0.00005)
opt_critic = torch.optim.RMSprop(critic.parameters(), lr=0.00005)
# 训练循环
for epoch in range(epochs):
for _ in range(n_critic):
# 训练Critic
opt_critic.zero_grad()
# 采样真实数据和生成数据
z = torch.randn(batch_size, latent_dim)
real_data = get_real_data(batch_size) # 实现此函数以加载真实数据
fake_data = generator(z)
# 计算Critic损失
loss_critic = torch.mean(critic(fake_data)) - torch.mean(critic(real_data))
loss_critic.backward()
opt_critic.step()
# 权重裁剪
for p in critic.parameters():
p.data.clamp_(-clip_value, clip_value)
# 训练生成器
opt_gen.zero_grad()
z = torch.randn(batch_size, latent_dim)
fake_data = generator(z)
loss_gen = -torch.mean(critic(fake_data))
loss_gen.backward()
opt_gen.step()
# 打印训练信息
if epoch % 100 == 0:
print(f'Epoch [{epoch}/{epochs}] Loss D: {loss_critic.item()}, Loss G: {loss_gen.item()}')-
critic.parameters():获取Critic网络的所有可训练参数。 -
p.data:访问参数的值(不涉及梯度计算)。 -
clamp_(-clip_value, clip_value):将参数值限制在[−clip_value,clip_value]范围内。clamp_是一个原地操作,直接修改参数值。
3.4 WGAN-GP(带梯度惩罚的WGAN)
为了进一步提高WGAN的稳定性,可以使用梯度惩罚(Gradient Penalty)代替权重裁剪。以下是梯度惩罚的实现代码:
# 定义梯度惩罚函数
def gradient_penalty(critic, real_data, fake_data):
alpha = torch.rand(real_data.size(0), 1).to(real_data.device)
interpolates = alpha * real_data + ((1 - alpha) * fake_data)
interpolates.requires_grad_(True)
critic_interpolates = critic(interpolates)
gradients = torch.autograd.grad(
outputs=critic_interpolates,
inputs=interpolates,
grad_outputs=torch.ones(critic_interpolates.size()).to(real_data.device),
create_graph=True, retain_graph=True, only_inputs=True
)[0]
gradient_penalty = ((gradients.norm(2, dim=1) - 1) ** 2).mean()
return gradient_penalty
# 计算Critic损失
loss_critic = torch.mean(critic(fake_data)) - torch.mean(critic(real_data))
# 计算梯度惩罚
gp = gradient_penalty(critic, real_data, fake_data)
# 总损失
loss_critic += lambda_gp * gp-
torch.autograd.grad:计算Critic对插值数据的梯度。-
outputs:Critic对插值数据的评分。 -
inputs:插值数据。 -
grad_outputs:梯度计算的初始值,通常设置为与outputs相同形状的全1张量。 -
create_graph和retain_graph:确保梯度计算过程中构建计算图,以便后续反向传播。 -
only_inputs:只对输入计算梯度。
-
-
gradients.norm(2, dim=1):计算梯度的L2范数。 -
gradient_penalty:计算梯度范数与1的差的平方的均值,作为梯度惩罚项。
梯度惩罚机制通过在真实数据和生成数据之间构造插值数据,并惩罚Critic在这些插值数据上的梯度偏离1的情况,从而确保Critic满足1-Lipschitz约束。这种方法比权重裁剪更有效,能够提高WGAN的训练稳定性和生成质量。
3.5 完整代码(权重裁剪)
完整代码如下方便调试:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import numpy as np
import matplotlib.pyplot as plt
# 超参数设置
latent_dim = 100 # 隐变量维度
output_dim = 784 # 输出维度(例如MNIST数据集的784像素)
epochs = 100000 # 训练轮数
n_critic = 5 # 每次生成器更新前Critic更新的次数
clip_value = 0.01 # 权重裁剪范围
batch_size = 64 # 批量大小
# 定义生成器
class Generator(nn.Module):
def __init__(self, input_dim, output_dim):
super(Generator, self).__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, 128),
nn.ReLU(),
nn.Linear(128, 256),
nn.ReLU(),
nn.Linear(256, output_dim),
nn.Tanh() # 输出范围在[-1, 1]
)
def forward(self, x):
return self.net(x)
# 定义Critic
class Critic(nn.Module):
def __init__(self, input_dim):
super(Critic, self).__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 128),
nn.LeakyReLU(0.2),
nn.Linear(128, 1)
)
def forward(self, x):
return self.net(x)
# 初始化生成器和Critic
generator = Generator(latent_dim, output_dim)
critic = Critic(output_dim)
# 定义优化器
opt_gen = optim.RMSprop(generator.parameters(), lr=0.00005)
opt_critic = optim.RMSprop(critic.parameters(), lr=0.00005)
# 数据加载
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]) # 将数据归一化到[-1, 1]
])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 定义get_real_data函数
def get_real_data(batch_size):
# 从数据加载器中获取一个批次的数据
for data in train_loader:
real_data, _ = data
real_data = real_data.view(real_data.size(0), -1) # 展平为784维
return real_data
# 训练循环
for epoch in range(epochs):
for _ in range(n_critic):
# 训练Critic
opt_critic.zero_grad()
# 采样真实数据和生成数据
real_data = get_real_data(batch_size)
z = torch.randn(batch_size, latent_dim)
fake_data = generator(z)
# 计算Critic损失
loss_critic = torch.mean(critic(fake_data)) - torch.mean(critic(real_data))
loss_critic.backward()
opt_critic.step()
# 权重裁剪
for p in critic.parameters():
p.data.clamp_(-clip_value, clip_value)
# 训练生成器
opt_gen.zero_grad()
z = torch.randn(batch_size, latent_dim)
fake_data = generator(z)
loss_gen = -torch.mean(critic(fake_data))
loss_gen.backward()
opt_gen.step()
# 打印训练信息
if epoch % 100 == 0:
print(f'Epoch [{epoch}/{epochs}] Loss D: {loss_critic.item()}, Loss G: {loss_gen.item()}')
# 生成样本并可视化
z = torch.randn(1, latent_dim)
generated_image = generator(z).view(28, 28).detach().numpy()
plt.imshow(generated_image, cmap='gray')
plt.show()3.6 完整代码(梯度惩罚)
完整代码如下方便调试;
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import numpy as np
import matplotlib.pyplot as plt
# 超参数设置
latent_dim = 100 # 隐变量维度
output_dim = 784 # 输出维度(例如MNIST数据集的784像素)
epochs = 100000 # 训练轮数
n_critic = 5 # 每次生成器更新前Critic更新的次数
lambda_gp = 10 # 梯度惩罚的权重系数
batch_size = 64 # 批量大小
# 定义生成器
class Generator(nn.Module):
def __init__(self, input_dim, output_dim):
super(Generator, self).__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, 128),
nn.ReLU(),
nn.Linear(128, 256),
nn.ReLU(),
nn.Linear(256, output_dim),
nn.Tanh() # 输出范围在[-1, 1]
)
def forward(self, x):
return self.net(x)
# 定义Critic
class Critic(nn.Module):
def __init__(self, input_dim):
super(Critic, self).__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 128),
nn.LeakyReLU(0.2),
nn.Linear(128, 1)
)
def forward(self, x):
return self.net(x)
# 初始化生成器和Critic
generator = Generator(latent_dim, output_dim)
critic = Critic(output_dim)
# 定义优化器
opt_gen = optim.RMSprop(generator.parameters(), lr=0.00005)
opt_critic = optim.RMSprop(critic.parameters(), lr=0.00005)
# 数据加载
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]) # 将数据归一化到[-1, 1]
])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 定义get_real_data函数
def get_real_data(batch_size):
# 从数据加载器中获取一个批次的数据
for data in train_loader:
real_data, _ = data
real_data = real_data.view(real_data.size(0), -1) # 展平为784维
return real_data
# 定义梯度惩罚函数
def gradient_penalty(critic, real_data, fake_data):
alpha = torch.rand(real_data.size(0), 1).to(real_data.device)
interpolates = alpha * real_data + ((1 - alpha) * fake_data)
interpolates.requires_grad_(True)
critic_interpolates = critic(interpolates)
gradients = torch.autograd.grad(
outputs=critic_interpolates,
inputs=interpolates,
grad_outputs=torch.ones(critic_interpolates.size()).to(real_data.device),
create_graph=True, retain_graph=True, only_inputs=True
)[0]
gradient_penalty = ((gradients.norm(2, dim=1) - 1) ** 2).mean()
return gradient_penalty
# 训练循环
for epoch in range(epochs):
for _ in range(n_critic):
# 训练Critic
opt_critic.zero_grad()
# 采样真实数据和生成数据
real_data = get_real_data(batch_size)
z = torch.randn(batch_size, latent_dim)
fake_data = generator(z)
# 计算Critic损失
loss_critic = torch.mean(critic(fake_data)) - torch.mean(critic(real_data))
# 计算梯度惩罚
gp = gradient_penalty(critic, real_data, fake_data)
# 总损失
loss_critic += lambda_gp * gp
loss_critic.backward()
opt_critic.step()
# 训练生成器
opt_gen.zero_grad()
z = torch.randn(batch_size, latent_dim)
fake_data = generator(z)
loss_gen = -torch.mean(critic(fake_data))
loss_gen.backward()
opt_gen.step()
# 打印训练信息
if epoch % 100 == 0:
print(f'Epoch [{epoch}/{epochs}] Loss D: {loss_critic.item()}, Loss G: {loss_gen.item()}')
# 生成样本并可视化
z = torch.randn(1, latent_dim)
generated_image = generator(z).view(28, 28).detach().numpy()
plt.imshow(generated_image, cmap='gray')
plt.show()4. 总结
Wasserstein GAN通过引入Wasserstein距离和Lipschitz约束,显著提高了GAN的训练稳定性。本文通过理论分析和代码实现,详细介绍了WGAN的工作原理和实际应用。对于更复杂的任务,可以进一步探索WGAN-GP等改进方法,以获得更好的生成效果。
希望本文能帮助大家深入理解WGAN,并在实际项目中灵活应用这一强大的生成模型。我是橙色小博,关注我,一起在人工智能领域学习进步。