0. 简介
自动驾驶汽车 (AV) 的最新进展利用大语言模型 (LLM) 在正常驾驶场景中表现良好。然而,确保动态、高风险环境中的安全并管理,对安全至关重要的长尾事件仍然是一项重大挑战。为了解决这些问题,本文《SafeDrive: Knowledge- and Data-Driven Risk-Sensitive Decision-Making for Autonomous Vehicles with Large》提出一个知识驱动和数据驱动的风险-敏感决策框架,提高 AV 的安全性和适应性。所提出的框架引入一个模块化系统,包括:(1) 一个风险模块,用于全面量化涉及驾驶员、车辆和道路相互作用的多因素耦合风险;(2) 一个记忆模块,用于存储和检索典型场景以提高适应性;(3) 一个由 LLM 驱动的推理模块,用于情境-觉察的安全决策;(4) 一个反思模块,用于通过迭代学习完善决策。
通过将知识驱动的洞察力与自适应学习机制相结合,该框架可确保在不确定条件下做出稳健的决策。对以动态和高风险场景为特征的真实交通数据集,包括高速公路(HighD)、交叉路口(InD)和环形交叉路口(RounD),进行广泛评估可验证该框架能够提高决策安全性(实现 100% 的安全率)、复制类似人类的驾驶行为(决策一致性超过 85%)并有效适应不可预测的场景。相关的代码可以在Github上找到
1. 主要贡献
尽管基于大型语言模型(LLM)的智能体展现出令人期待的能力,但它们有时会表现出过度自信,从而导致冒险行为[8]。虽然对LLM驱动的智能体的安全性能进行了广泛研究,但大多数研究集中在简单的模拟高速公路环境中,这些环境的风险源有限,交互也较少。然而,现实世界的交通复杂、动态且相互关联,潜在冲突频繁,使得基于LLM的智能体更难准确识别所有潜在风险并确保安全[6]。因此,以下研究问题对于推动更高级别的基于LLM的驾驶智能体至关重要:
1)RQ1:我们如何有效建模和量化安全关键环境中的耦合风险?
2)RQ2:我们如何引导基于LLM的智能体产生安全且类人化的驾驶行为?
为了解决这两个关键问题,本文提出了一种新颖的知识和数据驱动的风险敏感决策框架:SafeDrive。该框架引入了一个全面的风险量化模型,考虑来自人类、车辆和道路的多种风险源,提供精确且普遍适用的风险评估。此外,它利用真实世界的驾驶数据和场景风险知识,使基于LLM的安全决策成为可能。SafeDrive框架通过四个模块循环运行,以OpenAI的ChatGPT-4(GPT-4)作为驾驶智能体。这些模块如下:
1)风险模块:为各种场景输出全面且准确的风险评估。
2)记忆模块:根据风险模块输出的场景描述和风险水平存储和检索相关的过去经验。
3)推理模块:将先前的风险知识与动态上下文学习相结合,以进行自动驾驶车辆的推理。
4)反思模块:评估并纠正任何错误决策,促进更深层次的反思过程。
这些模块形成了一个强大且持续学习的系统,确保在复杂交通中安全导航。SafeDrive框架的有效性通过在多种真实世界数据集上的广泛实验得到了验证,包括HighD(高速公路)[9]、InD(交叉口)[10]和RounD(环形交叉口)[11]。
总之,我们的贡献如下:
1)我们提出了一个统一的风险量化模型,提供多因素耦合风险的全面和全方位评估,实现实时、持续的驾驶风险量化。
2)我们引入了一个知识和数据驱动的风险敏感决策框架,将风险评估与动态上下文学习相结合,提高了自动驾驶的安全性和不确定场景下的可解释性。
3)我们的框架实现了100%的安全率,并与人类决策的对齐率超过85%,在高风险场景中展现出强大的适应性,同时确保在多样化交通条件下的长期可靠性。
2. 框架
在本节中,我们提出了SafeDrive,一个基于大型语言模型(LLM)的知识和数据驱动的风险敏感决策框架,如图1所示。SafeDrive结合了自然驾驶数据和高风险场景,使自动驾驶车辆(AVs)能够在复杂动态环境中做出适应性、安全的决策。该框架以大量数据输入为起点(图1a),将所有道路用户、各种条件场景和全面覆盖的数据整合成一个典型和高风险驾驶场景的综合数据库。在耦合风险量化模块中(图1b),先进的风险建模,包括成本图和多维风险场,动态量化风险,为决策提供详细输入。LLM决策模块(图1c)利用数据驱动生成、风险先验知识和思维链(CoT)推理生成实时的风险敏感决策。此外,自适应记忆更新确保能够回忆起类似的经验,以优化决策过程。这些决策嵌入到一个风险敏感的驾驶智能体中(图1d),该智能体提供准确的风险警告,回忆过去的经验,并做出适应性决策。自我调整系统确保实时风险识别,并通过闭环反思机制实现驾驶策略的持续更新。总体而言,SafeDrive增强了实时响应能力、决策安全性和适应性,解决了高风险和不可预测场景中的挑战。
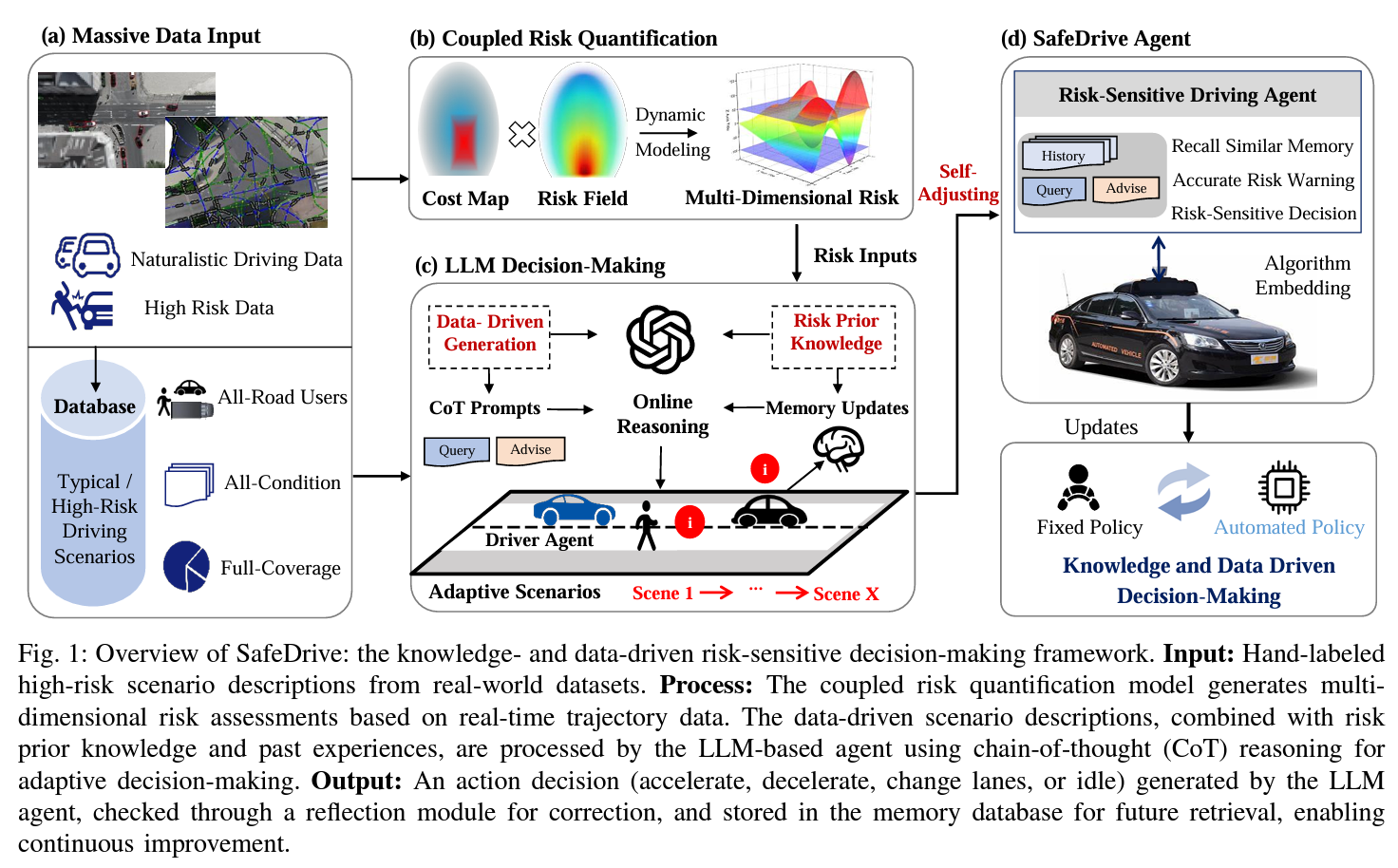
图1:SafeDrive概述:基于知识和数据的风险敏感决策框架。输入:来自真实世界数据集的手工标注高风险场景描述。过程:耦合风险量化模型基于实时轨迹数据生成多维风险评估。数据驱动的场景描述结合风险先验知识和过去经验,通过基于大型语言模型(LLM)的智能体使用思维链(CoT)推理进行处理,以实现自适应决策。输出:由LLM智能体生成的行动决策(加速、减速、变道或静止),经过反思模块进行校正,并存储在记忆数据库中以便未来检索,从而实现持续改进。
3. 方法论
在本节中,我们旨在解决实现更高级别自动驾驶车辆的两个关键研究问题。首先,我们介绍一个耦合风险量化模型。其次,我们提出一种风险敏感的决策方法,将LLM与风险模型相结合。
3.1 耦合风险量化
3.1.1 RQ1. 我们如何有效地建模和量化安全关键环境中的耦合风险?
感知风险的概念,如Naatanen和Summala等人所定义的[34],是事件发生的主观概率与该事件后果的乘积。在本文中,我们采用一种动态驾驶员风险场(DRF)模型,该模型根据车辆速度和转向动态进行调整,灵感来源于Kolekar等人的研究。DRF表示驾驶员对未来位置的主观信念,在自我车辆附近赋予更高的风险,并随着距离的增加而降低。事件后果通过根据物体的危险级别分配实验确定的成本来量化,这一过程独立于主观评估。总体量化感知风险(QPR)计算为所有网格点的事件成本和DRF之和。这种方法有效捕捉了驾驶员感知和行为中的不确定性,提供了驾驶风险的全面度量。
3.1.2 驾驶员风险场
该研究扩展了DRF,以考虑基于车辆速度和转向角的动态变化。DRF的计算使用运动学汽车模型,其中预测路径依赖于车辆的位置 ( x c a r , y c a r ) (x_{car}, y_{car}) (xcar,ycar)、航向角 ϕ c a r \phi_{car} ϕcar和转向角 δ \delta δ。假设转向角恒定,预测行驶弧的半径由以下公式给出:
R c a r = L tan ( δ ) (1) R_{car} = \frac{L}{\tan(\delta)} \tag{1} Rcar=tan(δ)L(1)
其中 L L L是汽车的轴距。利用车辆的位置和弧半径,可以找到转弯圆心 ( x c , y c ) (x_c, y_c) (xc,yc),并用于计算弧长 s s s,表示沿路径的距离。DRF被建模为具有高斯截面的环面,其表达式为:
z ( x , y ) = a exp ( − ( ( x − x c ) 2 + ( y − y c ) 2 − R c a r 2 ) 2 2 σ 2 ) (2) z(x,y) = a \exp\left(-\frac{((x-x_c)^2 + (y-y_c)^2 - R_{car}^2)^2}{2\sigma^2}\right) \tag{2} z(x,y)=aexp(−2σ2((x−xc)2+(y−yc)2−Rcar2)2)(2)
其中, a a a 是高度, σ \sigma σ 是高斯分布的宽度,二者均为弧长的函数。高度 a ( s ) a(s) a(s) 是关于 s s s 的抛物线函数,给定为:
a ( s ) = p − v t l a (3) a(s) = p - vt_{la} \tag{3} a(s)=p−vtla(3)
其中, t l a t_{la} tla 与车辆速度 v v v 成比例, p p p 决定了抛物线的陡峭程度。宽度 σ i \sigma_i σi 是弧长的线性函数,给定为:
σ i = ( m + k i ∣ δ ∣ ) s + c , i = { 1 (inner σ ) 2 (outer σ ) (4) \sigma_i = (m + k_i |\delta|) s + c, \quad i = \begin{cases} 1 & \text{(inner $\sigma$)} \\ 2 & \text{(outer $\sigma$)} \end{cases} \tag{4} σi=(m+ki∣δ∣)s+c,i={ 12(inner σ)(outer σ)(4)
这里, c c c 定义了车辆位置处的 DRF(驾驶风险场)的宽度,与车辆的宽度成正比,具体为 c = 车宽 4 c = \frac{\text{车宽}}{4} c=4车宽,其中 ± 2 σ \pm 2\sigma ±2σ 覆盖了 95% 的高斯分布。 m m m 控制直行时( δ = 0 \delta = 0 δ=0)的 DRF 宽度,而 k 1 k_1 k1 和 k 2 k_2 k2 则根据转向角 ∣ δ ∣ |\delta| ∣δ∣ 调整宽度。这反映了人类传感器运动系统中的噪声变异性。 k 1 k_1 k1 和 k 2 k_2 k2 的不对称性考虑了不同的驾驶行为,如切弯、跟随中心线或超出弯道,从而改善了在紧弯道中的风险管理。因此,DRF 由 p , t l a , m , c , k 1 p, t_{la}, m, c, k_1 p,tla,m,c,k1 和 k 2 k_2 k2 参数化,并完全依赖于驾驶员的状态。环境中的每个物体都被分配一个成本,从而创建一个成本图。该图通过逐元素相乘与 DRF 结合,沿网格求和以计算 QPR:
Q P R = ∑ grid points × ( Cost × DRF ) (5) QPR = \sum_\text{grid points} \times (\text{Cost} \times \text{DRF}) \tag{5} QPR=grid points∑×(Cost×DRF)(5)
该指标反映了驾驶员对潜在事件的感知可能性和严重性,将主观感知与客观风险量化相结合。
3.1.3 全向风险量化
传统的驾驶风险场(DRF)仅关注前方半圆。为了实现对自动驾驶的现实风险评估,我们的模型将其扩展到 360 度视角,涵盖来自前方和后方车辆的风险。通过包括后方车辆的 DRF 及其与自我车辆的碰撞成本,我们从各个角度创建了一个统一的风险景观,增强了情境意识和安全性。
Q P R total = Q P R front + Q P R rear (6) QPR_{\text{total}} = QPR_{\text{front}} + QPR_{\text{rear}} \tag{6} QPRtotal=QPRfront+QPRrear(6)
Q P R front = ∑ grid points × ( C o s t cars in front × D R F ego car ) (7) QPR_{\text{front}} = \sum_\text{grid points} \times (Cost_\text{ cars in front} \times DRF_\text{ego car}) \tag{7} QPRfront=grid points∑×(Cost cars in front×DRFego car)(7)
Q P R rear = ∑ grid points × ( C o s t ego car × D R F cars behind ) (8) QPR_{\text{rear}} = \sum_\text{grid points} \times (Cost_\text{ego car} \times DRF_\text{cars behind}) \tag{8} QPRrear=grid points∑×(Costego car×DRFcars behind)(8)
我们的方法不仅计算了所面临的总风险,还评估了每个参与者的具体风险属性。这使得能够识别出那些构成更大危险的参与者,从而实现更有针对性的风险识别和警告,如图 2 所示。

图 2:周围车辆的全向风险量化:QPR 属性包括与自我车辆相互影响的每辆车辆的风险成本,基于 DRF 分布。
3.2 风险敏感的基于大语言模型的决策制定
3.2.1 RQ2. 我们如何引导基于大语言模型的代理推导出安全且人性化的驾驶行为?
基于之前介绍的自主系统风险量化和先验知识驱动的范式,我们利用大模型的推理能力提出了SafeDrive,一个知识和数据驱动的框架,如图3所示。在本文中,GPT-4作为决策代理,推动推理过程并生成行动。我们使用手动标注的场景描述,并将其与来自真实世界数据集(包括HighD(高速公路)、InD(城市交叉口)和RounD(环形交叉口))的下一帧动作配对作为真实标签。这些描述提供了环境上下文,例如周围车辆的ID、位置和速度,使GPT-4能够解读环境并支持推理和决策。
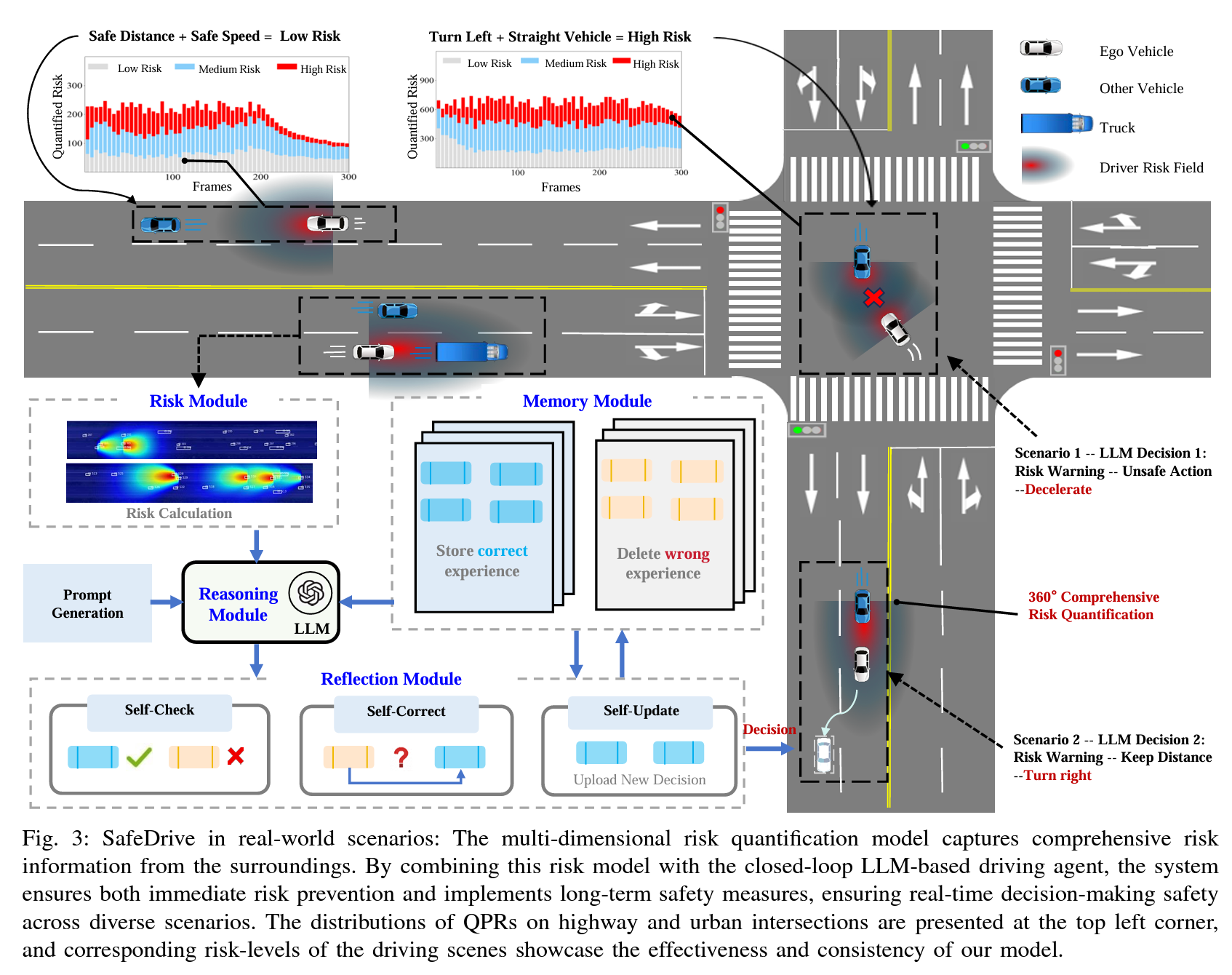
图3:SafeDrive在现实场景中的应用:多维风险量化模型捕捉来自周围环境的全面风险信息。通过将该风险模型与闭环基于大语言模型(LLM)的驾驶代理相结合,系统不仅确保了即时的风险预防,还实施了长期的安全措施,从而在多样化场景中确保实时决策的安全性。高速公路和城市交叉口的QPR分布展示在左上角,而相应的驾驶场景风险等级则展示了我们模型的有效性和一致性。
SafeDrive架构由四个核心模块组成:风险模块、推理模块、记忆模块和反思模块。该过程是迭代的:推理模块基于系统消息、场景描述、风险评估做出决策,并存储相似的记忆;反思模块评估决策并提供自我反思过程;记忆模块存储正确的决策以供未来检索。通过将三个真实世界数据集作为输入,这一自学习循环增强了在处理多样化复杂场景时的决策准确性和适应性。整体基于大语言模型的决策算法在算法1中展示。

算法 1:基于大语言模型的决策代理与风险评估器的自动驾驶
如图4所示,在动态场景中,SafeDrive接收用户导航指令和场景描述,实时评估周围车辆的风险属性(例如QPR值)、位置和速度。然后,利用大语言模型的推理和历史记忆,系统进行可行性检查、车道评估和决策制定,以确定最安全的行动,例如变道。总体而言,通过将多维风险量化与GPT-4的推理相结合,SafeDrive提供实时的风险敏感决策。在高速公路和交叉口等高风险场景中,它识别不安全行为并做出适应性决策(例如减速或转向)。闭环反思机制确保持续优化,增强响应能力、适应性和安全性。

图4:SafeDrive系统中系统提示和交互的示例。
3.2.2 风险模块
风险模块根据上述风险量化模型和定义的阈值为每个参与者生成详细的文本风险评估。这些阈值通过实验确定,考虑了风险分布和常见安全标准,涵盖纵向和横向风险。这一整合确保在决策中提高谨慎性,引导GPT-4驾驶代理有效避免或减轻不安全行为。
3.2.3 推理模块
推理模块通过三个关键组件促进系统的决策过程。它以系统消息开始,定义GPT-4驾驶代理的角色,概述预期的响应格式,并强调决策中的安全原则。在接收到由场景描述和风险评估组成的输入后,该模块与记忆模块互动,以检索相似的成功过去样本及其正确的推理过程。最后,动作解码器将输出的决策转化为自我车辆的具体行动,例如加速、减速、转向、变道或保持静止。这一结构化方法确保做出知情且注重安全的决策。
3.2.4 记忆模块
记忆模块是我们系统的核心组件,通过利用过去的驾驶经验增强决策制定。它使用GPT嵌入在向量数据库中存储向量化场景。数据库以一组手动创建的示例初始化,每个示例包括场景描述、风险评估、模板推理过程和正确行动。当遇到新场景时,系统通过使用相似度评分匹配向量化描述来检索相关经验。在决策过程之后,新样本被添加到数据库中。这一动态框架实现了持续学习,使系统能够适应多样化的驾驶条件。
3.2.5 反思模块
反思模块评估并纠正驾驶代理所做的错误决策,启动思考过程,探讨代理为何选择错误的行动。纠正后的决策及其推理随后存储在记忆模块中,作为防止未来类似错误的参考。该模块不仅使系统能够持续进化,还为开发者提供详细的日志信息,使他们能够分析和优化系统消息,以改善代理的决策逻辑。
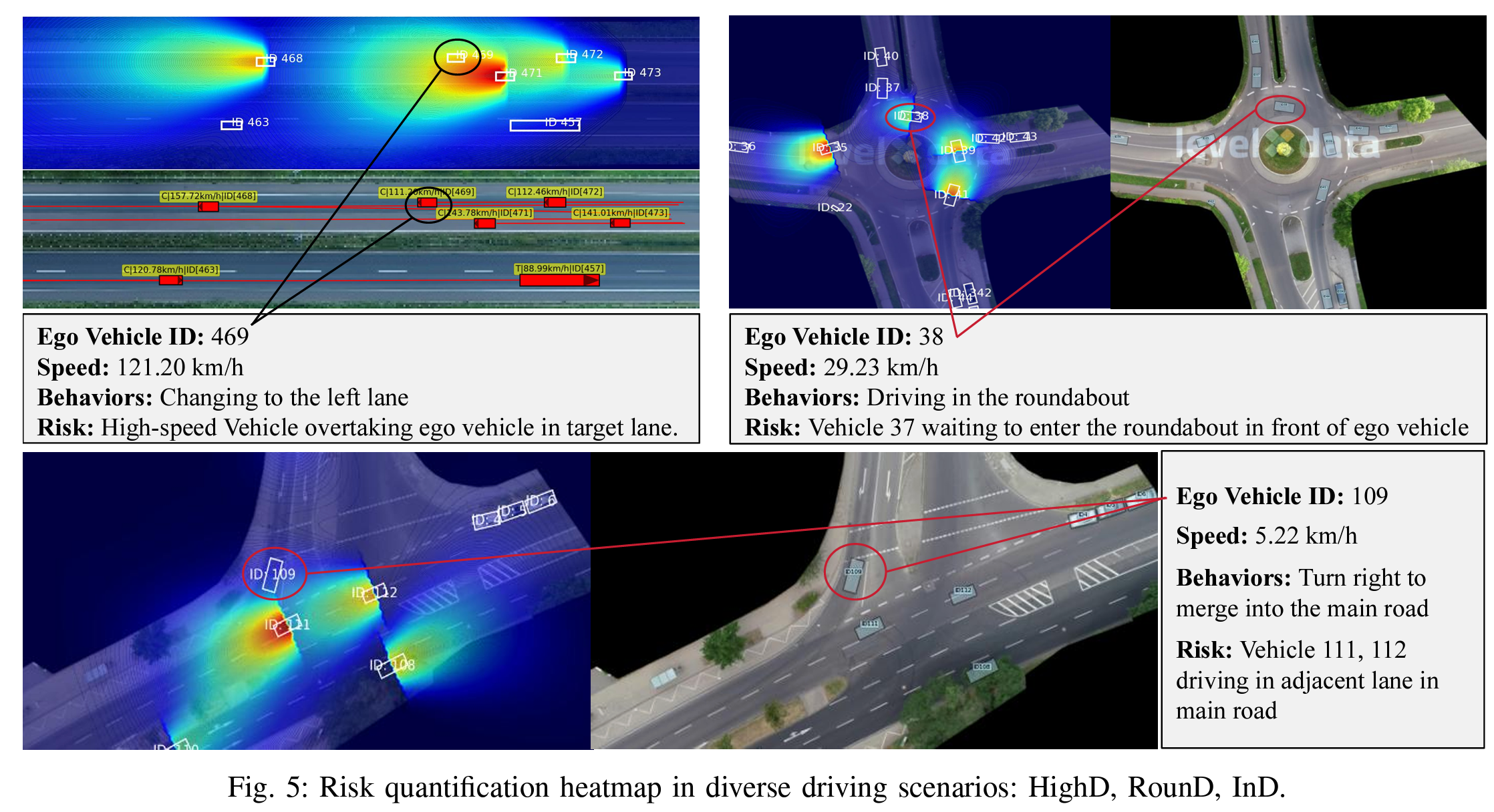
图5:在不同驾驶场景下的风险量化热图:HighD、RounD、InD。
4. 结论
在本文中,我们介绍了SafeDrive,一个基于知识和数据驱动的框架,用于自动驾驶汽车(AVs)的风险敏感决策,旨在解决在不可预测、高风险和长尾场景中安全性面临的关键挑战。通过提出一个统一的风险量化模型,该模型能够全方位评估多因素耦合风险,框架有效地模拟了随机城市环境的复杂性(RQ1)。将这一风险模型集成到由GPT-4驱动的基于大型语言模型(LLM)的决策框架中,使得在不确定的交通条件下能够实现安全、类人决策和持续适应性(RQ2)。使用真实世界数据集(HighD、InD和RounD)进行的广泛评估表明,该框架表现出色,达到了100%的安全率,并与人类驾驶行为的对齐度超过85%。这突显了该框架在复制类人策略方面的有效性,同时确保在多样且具有挑战性的场景中长期可靠性。未来,我们将通过纳入更详细的环境特征,如道路边界和障碍物,来增强风险量化模型。此外,过渡到具有更强推理能力的先进大型语言模型,如ChatGPT-01-preview[36],将使得决策更加细致入微。通过利用近期研究中强调的微调技术[37],我们旨在进一步提升系统在特定领域(如交通知识)中的专业能力,使其成为一个更成熟、更具能力的驾驶代理。