0. 简介
大模型技术论文不断,每个月总会新增上千篇。主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调重新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于构建生产级别架构则可以关注AI架构设计专栏。技术宅麻烦死磕LLM背后的基础模型。这个公众号的文章还是非常不错的,值得深入学习。关于机器人学习,标准做法是使用针对特定机器人和手头工作量身定制的数据集来训练策略。以这种方式从头开始需要为每项活动收集大量数据,并且生成的策略通常表现出很少的通用性。的确针对机器人和工作中收集的数据是最靠谱的解决方案,针对各种控制场景训练模型可以增强它们的泛化能力并在后续任务中表现更好。一些机构通过将机器人观察结果直接转化为动作来实现通用机器人模型,在通过zero-shot或者few-shot将模型扩展到新领域和新的机器人。由于这些模型在各种活动、环境和机器人系统中的低层次视动控制的多功能性,它们通常被称为‘通用机器人策略’(Generalist Robot Policies,简称 GRPs)。《Octo: An Open-Source Generalist Robot Policy》就是是为构建开源的、广泛适用的通用机器人操作策略所做的持续努力。它是基于Transformer的扩散策略,采用Open X-Embodiment数据集中的 80万个机器人操作片段来进行预训练。它支持灵活的任务和观察定义,并且可以快速微调到新的观察和动作空间。即将推出两个初始版本的 Octo,分别是Octo-Small(27M参数)和Octo-Base(93M参数)。相关的内容主页可以在Github上找到
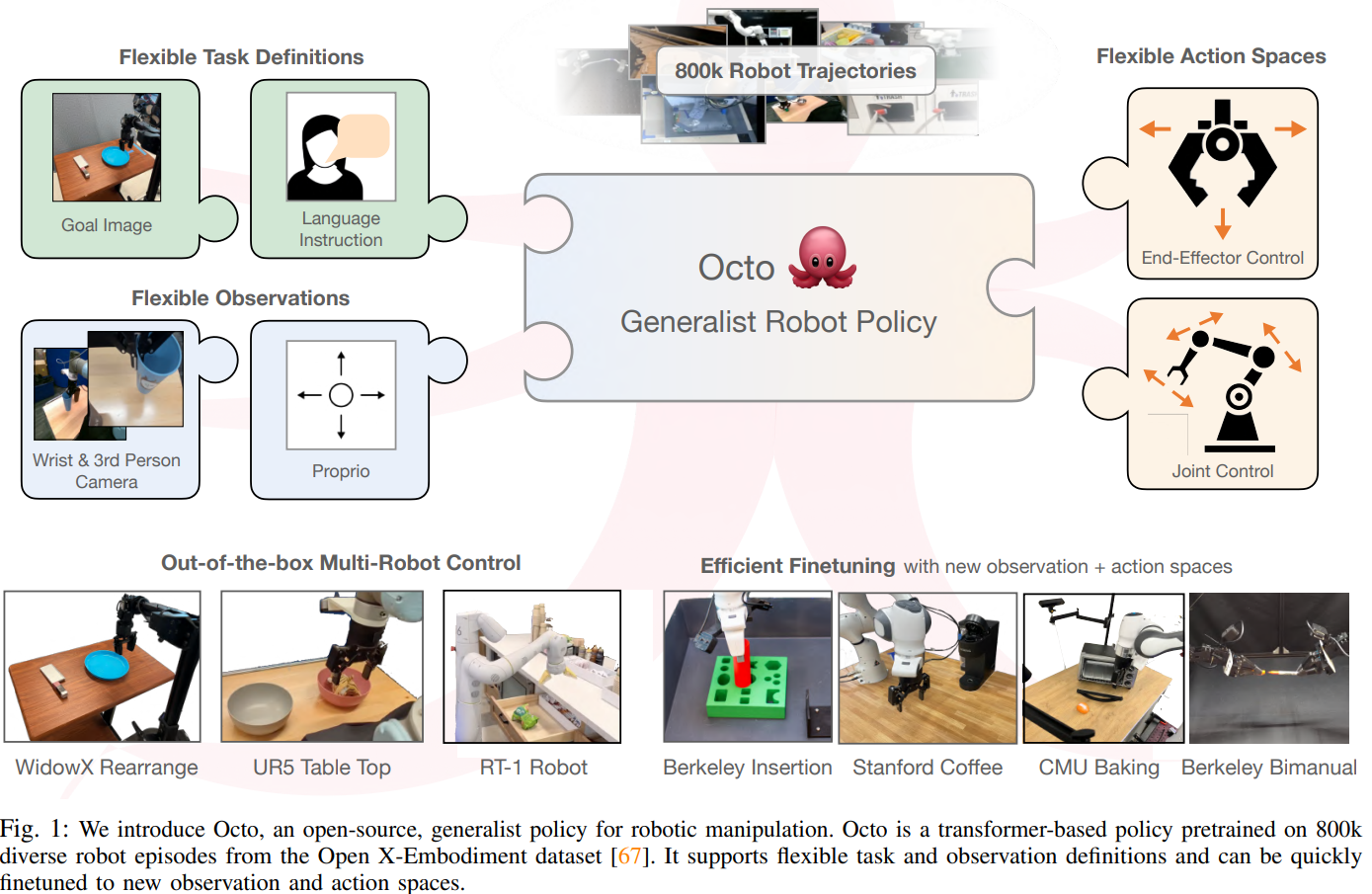
图1:我们介绍了Octo,一个开源的通用机器人操作策略。Octo是一个基于变换器的策略,经过在Open X-Embodiment数据集中800,000个多样化机器人实验的预训练。它支持灵活的任务和观察定义,并且可以快速微调以适应新的观察和动作空间。
Octo模型的设计强调灵活性和可扩展性,旨在支持各种常用的机器人、传感器配置和动作,同时提供一个通用且可扩展的训练方法,可以在大量数据上进行训练。Octo 支持自然语言指令和目标图像、观察历史以及通过扩散解码实现的多模态动作分布。此外还专门设计了Octo以支持对新机器人设置的高效微调,包括具有不同动作和不同摄像头与本体感觉信息组合的机器人。这种设计旨在使 Octo 成为一个灵活且广泛适用的通用机器人策略,能够用于各种下游机器人应用和研究项目。Open X-Embodiment 作为一个大规模、开放的机器人操作数据集,专门设计用于训练和评估机器人学习模型。它涵盖了广泛的机器人操作任务和环境,旨在为研究人员和开发人员提供丰富的训练数据,以推动通用机器人策略(Generalist Robot Policies, GRPs)的发展。
Octo其实是站在巨人的肩膀上,它的设计灵感来自于机器人模仿学习和可扩展的Transformer训练的最新研究,包括使用“denoising diffusion objectives” 进行动作解码和“动作块”(未来的行为)的预测,以及采用了可扩展ViT训练的模型结构和学习率调整计划。
1. 贡献与创新
Octo是一种基于transformer的机器人控制策略,具备通过语言命令和目标图像两种方式接受指令的能力。其设计特点使得它能够在标准消费级GPU上进行快速微调,以适应新传感器输入和动作空间,从而实现高效的机器人操控。
1. 指令接收方式
- 语言命令:Octo能够理解并响应口头指令,例如“拿起桌上的杯子”。这些指令被转化为机器可理解的形式,从而指导机器人执行相应的任务。
- 目标图像:除了语言命令,Octo还可以通过目标图像理解任务。例如,给机器人提供一个特定的目标图像(如桌子上的杯子),机器人将依据图像的指引去完成相应的任务,如抓取和移动该杯子。
2. 在标准消费级GPU上进行微调
- 标准消费级GPU:Octo的设计允许在普通个人电脑中使用的显卡(例如NVIDIA的A5000)上进行操作,而不依赖于昂贵的高性能计算硬件(如TPU或高端NVIDIA A100 GPU)。
- 微调:在经过初步预训练后,Octo能够通过少量的新数据(例如新的传感器输入、任务或动作空间)进行优化,以适应新的任务或环境。值得注意的是,这一微调过程能够在几小时内完成,使得Octo迅速掌握新的技能或适应环境变化。
3. 适应新的传感输入和动作空间
- 新的传感输入:Octo能够接受不同类型传感器的数据输入,包括新的视觉传感器(如深度摄像头和激光雷达)及触觉传感器。在微调过程中,Octo学习如何有效利用这些新传感器进行任务。
- 新的动作空间:Octo还具备适应新的机器人控制方式的能力。例如,从原有的操控机器人手臂的关节位置到现在的抓手动作(如开合抓手),Octo能够调整其控制策略以适应这些新的动作空间。
Octo的主要贡献在于基于Open X-Embodiment数据集的80万条机器人演示进行了预训练,成为第一个能够有效微调到新观测和动作空间的通用机器人操控策略,并且完全开源,提供了训练流程、模型检查点和数据。尽管Octo的组成部分(如transformer主干、支持语言和目标图像规范的模块,以及用于建模表达性动作分布的扩散头)在先前的研究中已有讨论,但将这些组件成功结合成为一个强大的通用机器人策略是其独特且新颖之处。
2. 代码使用
octo代码库包含了训练和微调Octo通用机器人策略(GRPs)的代码。Octo模型是基于变换器的扩散策略,训练于80万条多样化的机器人轨迹上。
我们安装说明进行操作,然后加载一个预训练的Octo模型!可以查看示例以获取零样本评估和微调的指南,以及在Colab中打开推理示例。
from octo.model.octo_model import OctoModel
model = OctoModel.load_pretrained("hf://rail-berkeley/octo-base-1.5")
print(model.get_pretty_spec())
Octo模型支持多种RGB摄像头输入,可以控制各种机器人手臂,并且可以通过语言命令或目标图像进行指令。Octo在其变换器主干中使用模块化注意力结构,使其能够针对新的传感器输入、动作空间和形态进行有效的微调,所需的目标领域数据集较小,并且计算预算也相对易于获取。
2.1安装步骤
首先创建并激活一个conda环境:
conda create -n octo python=3.10
conda activate octo
pip install -e .
pip install -r requirements.txt
对于GPU用户:
pip install --upgrade "jax[cuda11_pip]==0.4.20" -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html
对于TPU用户:
pip install --upgrade "jax[tpu]==0.4.20" -f https://storage.googleapis.com/jax-releases/libtpu_releases.html
有关Jax的更多详细信息,请参阅Jax的GitHub页面。
通过在调试数据集上微调来测试安装:
python scripts/finetune.py --config.pretrained_path=hf://rail-berkeley/octo-small-1.5 --debug
2.2 检查点
您可以在这里找到预训练的Octo检查点。目前我们提供以下模型版本:
| 模型 | 在1个NVIDIA 4090上推理速度 | 参数量 |
|---|---|---|
| Octo-Base | 13 it/sec | 93M |
| Octo-Small | 17 it/sec | 27M |
2.3 示例
我们提供了简单的示例脚本,演示如何使用和微调Octo模型,以及如何独立使用我们的数据加载器。示例包括:
- Octo推理:加载和运行预训练Octo模型的最小示例
- Octo微调:在新观察和动作空间上微调预训练Octo模型的最小示例
- Octo回滚:在Gym环境中运行预训练Octo策略的回滚
- Octo机器人评估:在真实的WidowX机器人上评估预训练Octo模型
- OpenX数据加载器介绍:Open X-Embodiment数据加载器功能的演示
- OpenX PyTorch数据加载器:独立的Open X-Embodiment数据加载器实现
2.4 Octo预训练
要重现我们在80万条机器人轨迹上的Octo预训练,请运行:
python scripts/train.py --config scripts/configs/octo_pretrain_config.py:<size> --name=octo --config.dataset_kwargs.oxe_kwargs.data_dir=... --config.dataset_kwargs.oxe_kwargs.data_mix=oxe_magic_soup ...
要从Open X-Embodiment数据集中下载预训练数据集,请安装rlds_dataset_mod包并运行prepare_open_x.sh脚本。预处理数据集的总大小约为1.2TB。
我们在TPUv4-128集群上进行预训练,Octo-S模型用时8小时,Octo-B模型用时14小时。
2.5 Octo微调
我们提供了一个微调新观察和动作空间的简化示例。
我们还提供了一个更高级的微调脚本,可以通过配置文件更改超参数并记录微调指标。要运行高级微调,请使用:
python scripts/finetune.py --config.pretrained_path=hf://rail-berkeley/octo-small-1.5
我们提供三种微调模式,具体取决于模型的冻结部分:head_only、head_mlp_only和full,可以微调整个模型。此外,可以指定微调的任务类型:image_conditioned、language_conditioned或multimodal(两者)。例如,要仅使用图像输入微调整个变换器,请使用:
--config=finetune_config.py:full,image_conditioned
2.6 Octo评估
加载和运行训练好的Octo模型非常简单:
from octo.model import OctoModel
model = OctoModel.load_pretrained("hf://rail-berkeley/octo-small-1.5")
task = model.create_tasks(texts=["pick up the spoon"])
action = model.sample_actions(observation, task, rng=jax.random.PRNGKey(0))
我们提供了在模拟Gym环境中评估Octo的示例,以及在真实的WidowX机器人上进行评估的示例。
要在您自己的环境中进行评估,只需将其包装在Gym接口中,并按照Eval Env README中的说明进行操作。
2.7 代码结构
| 文件 | 描述 |
|---|---|
| 超参数 | config.py 定义训练运行的所有超参数 |
| 预训练循环 | train.py 主要的预训练脚本 |
| 微调循环 | finetune.py 主要的微调脚本 |
| 数据集 | dataset.py 创建单个/交错数据集和数据增强的函数 |
| 分词器 | tokenizers.py 将图像/文本输入编码为标记的分词器 |
| Octo模型 | octo_model.py 与Octo模型交互的主要入口点:加载、保存和推理 |
| 模型架构 | octo_module.py 组合标记序列、变换器主干和读取头 |
| 可视化 | visualization_lib.py 用于离线定性和定量评估的工具 |
3. OCTO模型
在本节中,我们将描述Octo模型,这是我们开源的通用机器人策略,可以通过微调适应新的机器人和任务——包括新的传感器输入和动作空间。我们将讨论关键的设计决策、训练目标、训练数据集和基础设施。Octo模型的设计强调灵活性和可扩展性:它支持多种常用机器人、传感器配置和动作,同时提供一种通用且可扩展的方案,可以在大量数据上进行训练。它还支持自然语言指令、目标图像、观察历史以及通过扩散解码进行的多模态、分块动作预测[17]。此外,我们专门设计Octo以便于高效地微调到新的机器人设置,包括具有不同动作空间和不同组合的相机及本体感知信息的机器人。此设计旨在使Octo成为一种灵活且广泛适用的通用机器人策略,可用于多种下游机器人应用和研究项目。
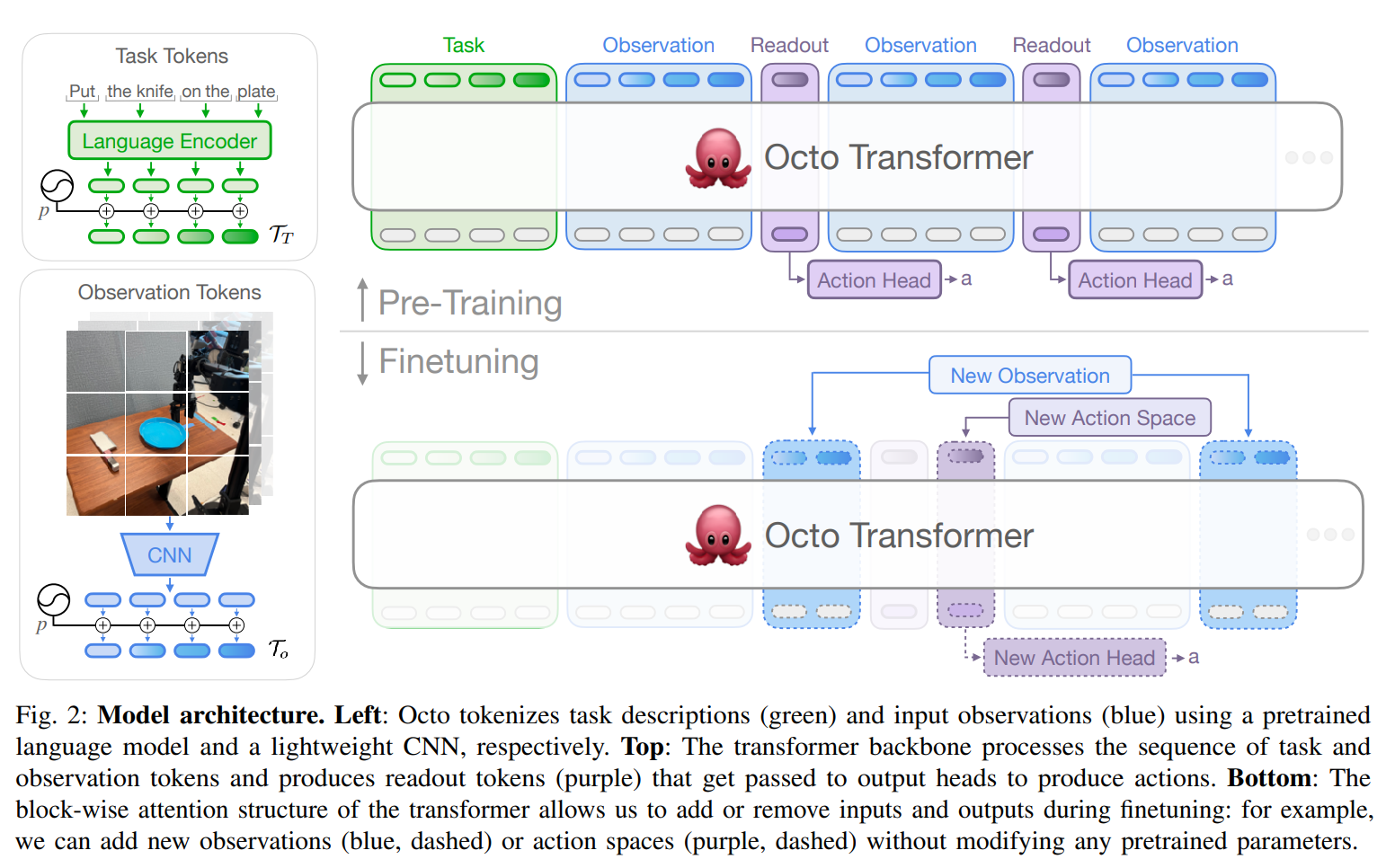
图2:模型架构。左侧:Octo使用预训练的语言模型和轻量级卷积神经网络分别对任务描述(绿色)和输入观察(蓝色)进行标记化。顶部:变换器骨干处理任务和观察标记的序列,并生成读出标记(紫色),这些标记被传递给输出头以生成动作。底部:变换器的块状注意力结构使我们能够在微调过程中添加或移除输入和输出:例如,我们可以添加新的观察(蓝色,虚线)或动作空间(紫色,虚线),而无需修改任何预训练参数。
4. 核心架构
Octo的核心是基于变换器的策略 π \pi π。它由三个关键部分组成:输入标记器,将语言指令 ℓ \ell ℓ、目标 g g g和观察序列 o 1 , … , o H o_1, \ldots, o_H o1,…,oH转换为标记 T l , T g , T o T_l, T_g, T_o Tl,Tg,To(见图2,左侧);一个处理这些标记并生成嵌入 e l , e g , e o = T ( T l , T g , T o ) e_l, e_g, e_o = T(T_l, T_g, T_o) el,eg,eo=T(Tl,Tg,To)的变换器骨干(见图2,顶部);以及生成所需输出(即动作 a a a)的读出头 R ( e ) R(e) R(e)。
任务和观察标记器:我们将任务定义(例如,语言指令 ℓ \ell ℓ和目标图像 g g g)以及观察 o o o(例如,手腕和第三人称相机流)转换为一种通用的“标记化”格式,使用特定模态的标记器(见图2,左侧):
- 语言输入被标记化,然后通过一个预训练的变换器,生成一系列语言嵌入标记。我们使用t5-base(111M)模型[74]。
- 图像观察和目标通过一个浅层卷积堆栈,然后分割成一系列扁平化的补丁[22]。
我们通过将可学习的位置嵌入 p p p添加到任务和观察标记中,并按顺序排列它们,来组装变换器的输入序列 T T , T o , 1 , T o , 2 , … T_T, T_{o,1}, T_{o,2}, \ldots TT,To,1,To,2,…。
4.1 变换器骨干和读出头
一旦输入被转换为统一的标记序列,它们就会被变换器处理(见图2,顶部)。这与之前的工作类似,后者在观察和动作序列上训练基于变换器的策略[92, 73]。Octo变换器的注意力模式是块状掩蔽的:观察标记只能因果地关注来自同一时间步或更早时间步的标记 T o , 0 : t T_{o,0:t} To,0:t以及任务标记 T T T_T TT(绿色)。对应于不存在的观察的标记会被完全掩蔽(例如,没有语言指令的数据集)。这种模块化设计使我们能够在微调过程中添加和移除观察或任务(见下文)。除了这些输入标记块外,我们还插入了学习的读出标记 T R , t T_{R,t} TR,t(紫色)。读出标记 T R , t T_{R,t} TR,t关注序列中之前的观察和任务标记,但不被任何观察或任务标记关注——因此,它们只能被动地读取和处理内部嵌入,而不影响它们。读出标记的作用类似于BERT中的[CLS]标记,作为到目前为止观察序列的紧凑向量嵌入。一个轻量级的“动作头”实现了扩散过程,应用于读出标记的嵌入。这个动作头预测一“块”多个连续的动作,类似于之前的工作[98, 17]。
我们的设计使我们能够在下游微调过程中灵活地向模型添加新的任务和观察输入或动作输出头。当在下游添加新任务、观察或损失函数时,我们可以完全保留变换器的预训练权重,仅添加新的位置嵌入、新的轻量级编码器或根据规范变化所需的新头的参数(见图2,底部)。这与之前的架构[10, 81]形成对比,后者在添加或移除图像输入或更改任务规范时需要重新初始化或重新训练预训练模型的大部分组件。
这种灵活性对于使Octo成为真正的“通用”模型至关重要:由于我们无法在预训练期间覆盖所有可能的机器人传感器和动作配置,因此能够在微调过程中适应Octo的输入和输出,使其成为机器人社区的多功能工具。之前的模型设计使用标准的变换器骨干或将视觉编码器与MLP输出头融合,锁定了模型所期望的输入类型和顺序。相比之下,切换Octo的观察或任务并不需要重新初始化模型的大部分部分。
5. 训练数据
我们在来自Open XEmbodiment Dataset [67]的25个数据集的混合上训练Octo,该数据集是一个多样化的机器人学习数据集集合。我们的训练混合包括来自多个机器人形态和场景的各种任务的演示数据。这些数据集在机器人类型、传感器(例如,是否包含腕部摄像头)和标签(例如,是否包含语言指令)等方面都是异质的。有关详细的混合信息,请参见图3和附录C。为了创建我们的训练混合D,我们首先去除所有不包含图像流的Open-X数据集,以及那些不使用增量末端执行器控制的数据集。我们还去除了过于重复、图像分辨率低或由过于小众的任务组成的数据集。对于剩余的数据集,我们根据任务和环境将其大致分类为“更多样化”和“较少样化”数据集,并在训练过程中将更多样化数据集的权重加倍。我们还降低了一些包含许多重复情节的数据集的权重,以避免其主导混合。最后,我们对任何缺失的摄像头通道进行零填充,并在数据集之间对夹持器的动作空间进行对齐,使得夹持器命令+1表示“夹持器打开”,而0表示“夹持器关闭”。虽然我们发现最终的训练混合效果良好,但未来的工作应对数据混合质量进行更全面的分析,以便为预训练通用机器人策略提供支持。
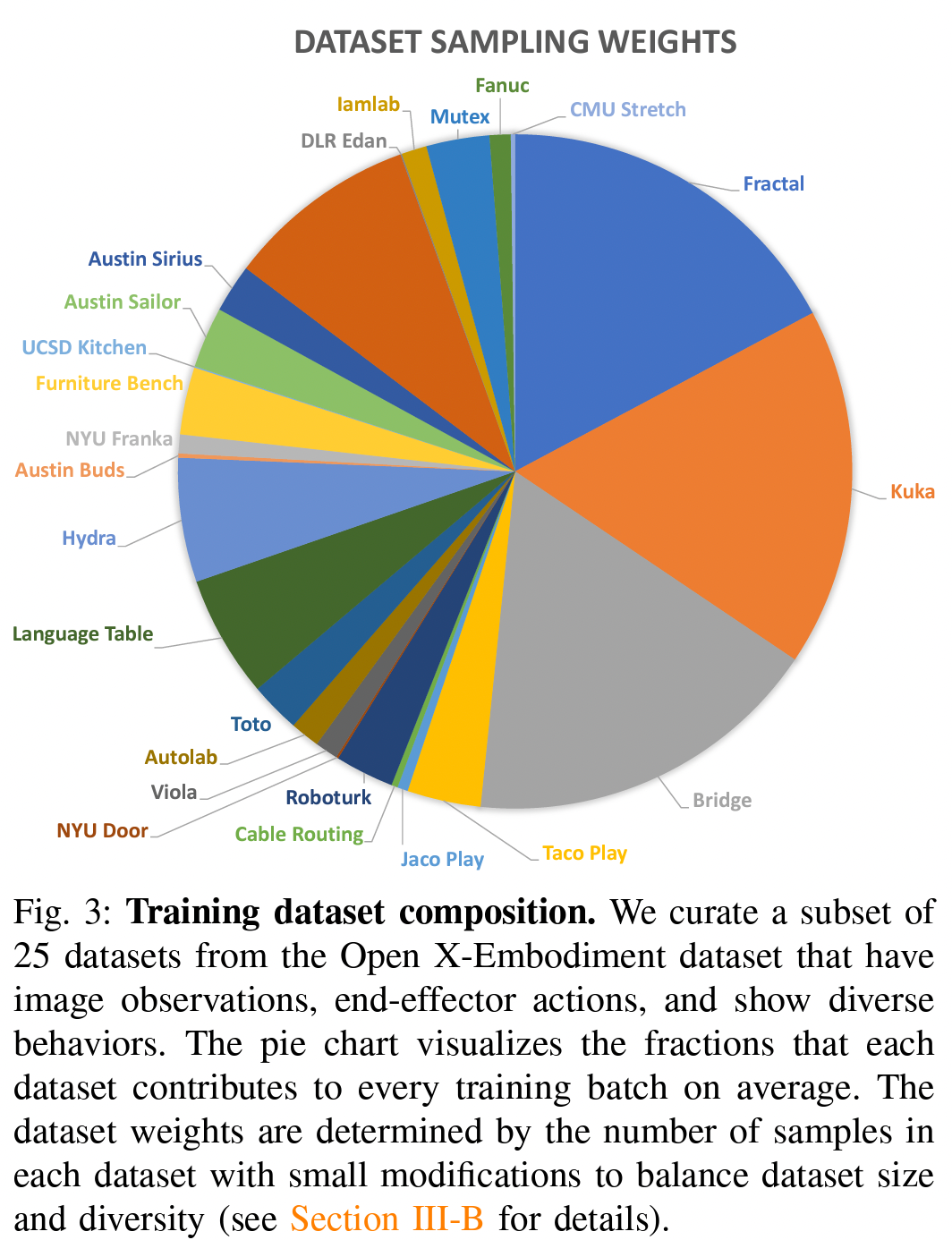
图3:训练数据集组成。我们从Open X-Embodiment数据集中精心挑选了25个具有图像观测、末端执行器动作并展现多样化行为的数据子集。饼图展示了每个数据集在每个训练批次中平均贡献的比例。数据集的权重是根据每个数据集中的样本数量确定的,并进行了小幅调整,以平衡数据集的大小和多样性(详见第III-B节)。
6. 训练目标
我们使用条件扩散解码头来预测连续的多模态动作分布 [34, 17]。重要的是,每次动作预测仅执行一次变换器主干的前向传播,之后的多步去噪过程完全在小型扩散头内进行。我们发现这种策略参数化在零-shot和微调评估中优于使用均方误差(MSE)动作头或离散化动作分布 [10] 训练的策略。为了生成一个动作,我们从高斯噪声向量 x K ∼ N ( 0 , I ) x^K \sim N(0, I) xK∼N(0,I) 中采样,并应用 K K K 步去噪,使用一个学习到的去噪网络 ϵ θ ( x k , e , k ) \epsilon_\theta(x^k, e, k) ϵθ(xk,e,k),该网络以前一步去噪的输出 x k x^k xk、步索引 k k k 和变换器动作读取的输出嵌入 e e e 为条件:
x k − 1 = α ( x k − γ ϵ θ ( x k , e , k ) + N ( 0 , σ 2 I ) . (1) x^{k-1} = \alpha(x^k - \gamma \epsilon_\theta(x^k, e, k) + N(0, \sigma^2 I). \tag{1} xk−1=α(xk−γϵθ(xk,e,k)+N(0,σ2I).(1)
超参数 α \alpha α、 γ \gamma γ 和 σ \sigma σ 对应于噪声调度:我们使用 [66] 中的标准余弦调度。我们使用在 [34] 中首次提出的标准 DDPM 目标训练扩散头,其中我们向数据集动作添加高斯噪声,并训练去噪网络 ϵ θ ( x k , e , k ) \epsilon_\theta(x_k, e, k) ϵθ(xk,e,k) 来重构原始动作。有关扩散策略训练的详细说明,请参见 Chi 等人 [17]。我们在附录 D 中列出了所有超参数。在微调过程中,我们使用相同的扩散训练目标并更新完整模型,这种方法优于冻结预训练参数的子集。在所有微调实验中,我们采用相同的方案:给定一个包含约 100 条轨迹的小目标领域数据集,我们使用余弦衰减学习率和线性预热进行 50,000 步的微调。

图 4:评估任务。我们在 4 个机构的 9 个真实机器人设置上评估 Octo。我们的评估涵盖了多样的物体交互(例如,“WidowX BridgeV2”)、较长的任务时间跨度(例如,“Stanford Coffee”)以及精确的操作(例如,“Berkeley Peg Insertion”)。我们评估了 Octo 在预训练数据环境中开箱即用地控制机器人以及如何高效地微调以适应新的任务和环境,使用小型目标领域数据集。我们还测试了在新观测(“Berkeley Peg Insertion”的力-扭矩输入)、动作空间(“Berkeley Pick-Up”和“Berkeley Bimanual”的关节位置控制)以及新的机器人实现(例如,“Berkeley Bimanual”和“Berkeley Coke”)下的微调效果。
7. 总结
Octo是一种基于大型变换器的策略模型,预训练于迄今为止最大的机器人操作数据集——80万条机器人轨迹。我们展示了 Octo 能够开箱即用地解决多种任务,并且展示了 Octo 的组合设计如何使其能够微调到新的输入和动作空间,从而使 Octo 成为广泛机器人控制问题的多功能初始化器。除了模型本身,我们还发布了完整的训练和微调代码,以及一些工具,使得在大型机器人数据集上进行训练变得更加容易。
8. 参考链接
https://blog.csdn.net/Janexjy/article/details/139220195
https://aitntnews.com/newDetail.html?newId=8834
https://github.com/octo-models/octo