@ 自注意力机制
1. 自注意力机制简单讲解
自注意力(Self-Attention)机制是现代深度学习模型中的核心组件,特别是在Transformer架构中。下面是一个简单但不失本质的解释:
基本思想
自注意力机制的核心思想是:让序列中的每个元素都能"看到"并与序列中的其他所有元素进行交互。
工作原理
-
查询、键、值转换:每个输入元素被转换为三个向量:
- 查询(Query):表示"我想要什么信息"
- 键(Key):表示"我包含什么信息"
- 值(Value):表示"我的实际内容是什么"
-
计算注意力分数:每个元素的查询向量与所有元素(包括自己)的键向量做点积,得到匹配程度
-
归一化与软化:对这些分数进行缩放并应用softmax函数,使它们变成和为1的权重
-
加权聚合:用这些权重对所有值向量进行加权求和,得到新表示
本质理解
- 自注意力本质上是在做加权信息聚合,权重由元素之间的相关性决定
- 它允许模型动态地决定应该关注哪些信息
- 每个元素得到的新表示包含了整个序列的上下文信息
- 这种机制使模型能够处理长距离依赖,捕捉序列中远距离元素之间的关系
为什么它如此强大
自注意力的强大之处在于它打破了序列处理的局部性限制。在传统模型中,元素主要与其邻近元素交互,而自注意力允许任意距离的元素直接交互,从而能够捕捉更复杂的模式和关系。
2. 图文结合讲解
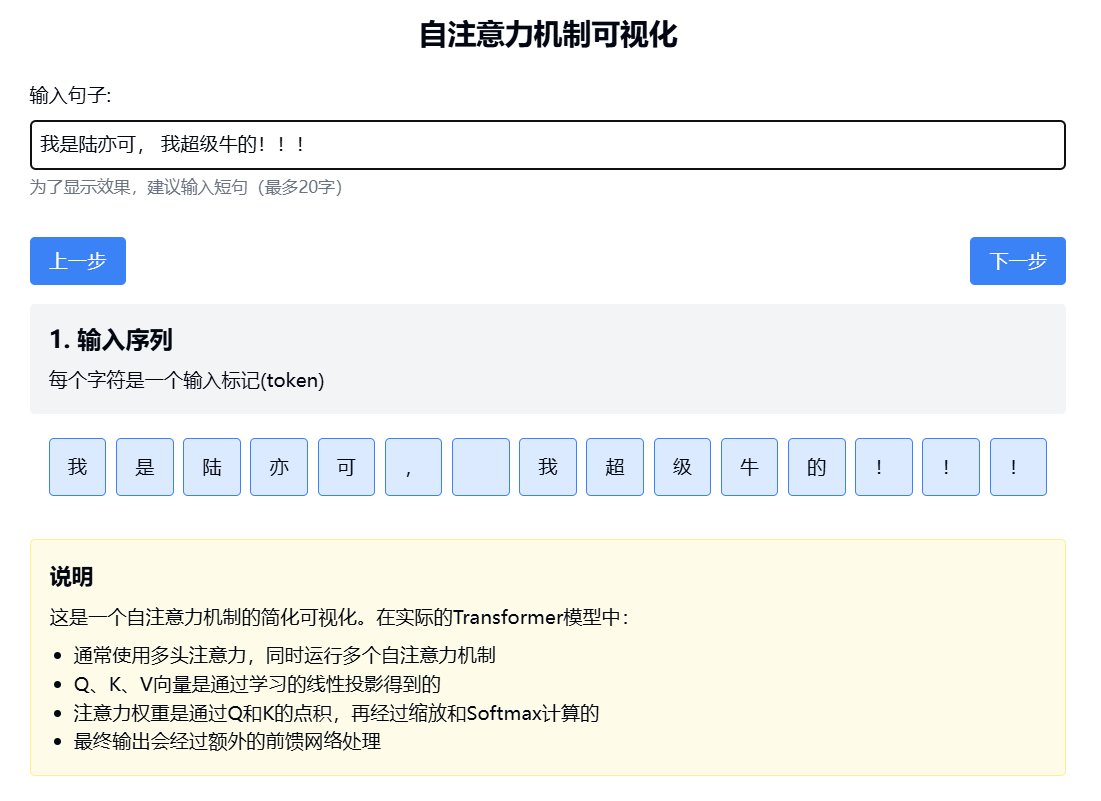
2.1. 输入序列 - 展示原始的文本输入
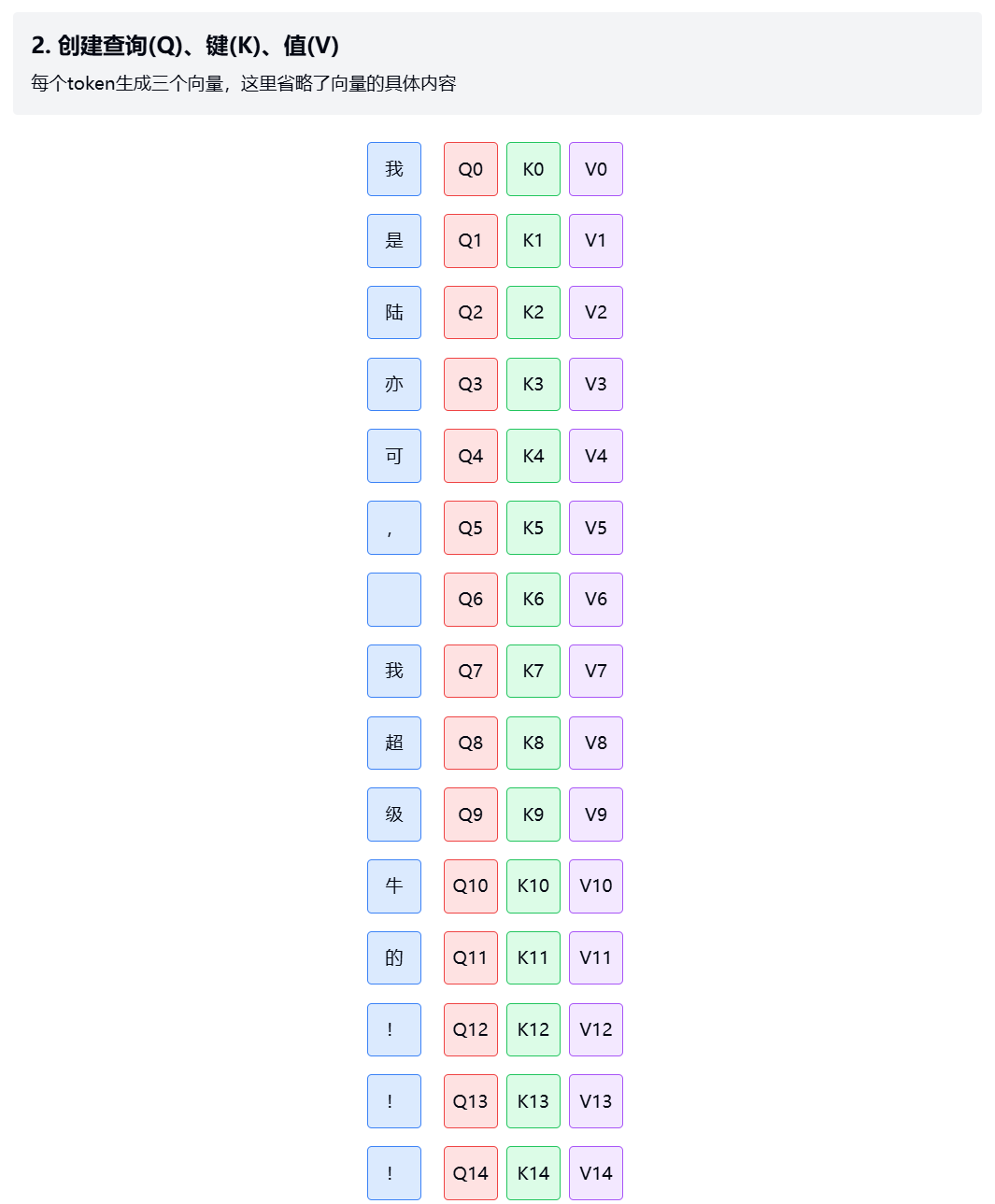
2.2. 创建查询(Q)、键(K)、值(V) - 每个token生成三个不同的向量表示
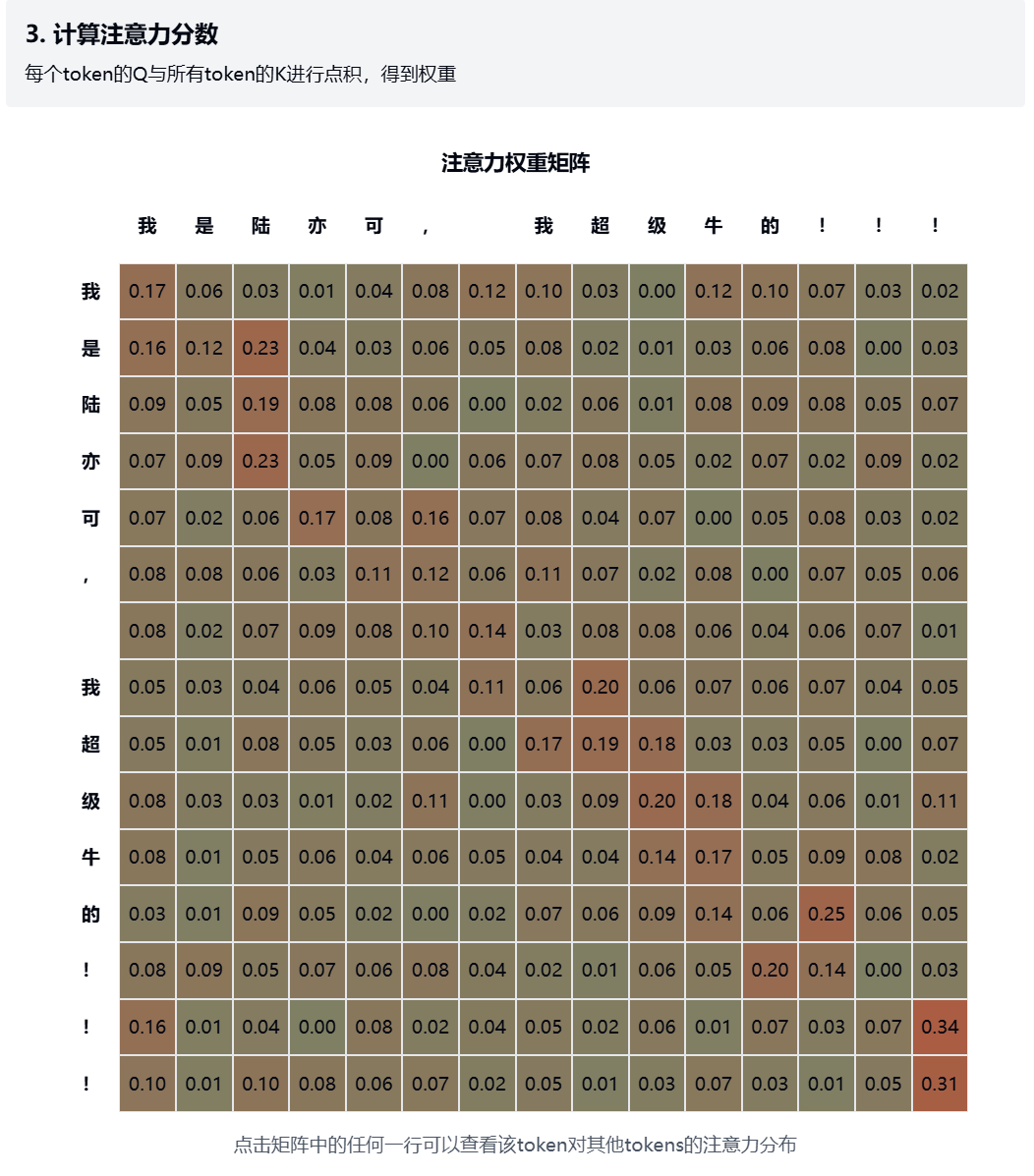
2.3. 计算注意力分数 - 可视化注意力矩阵,展示每个token对其他token的关注程度
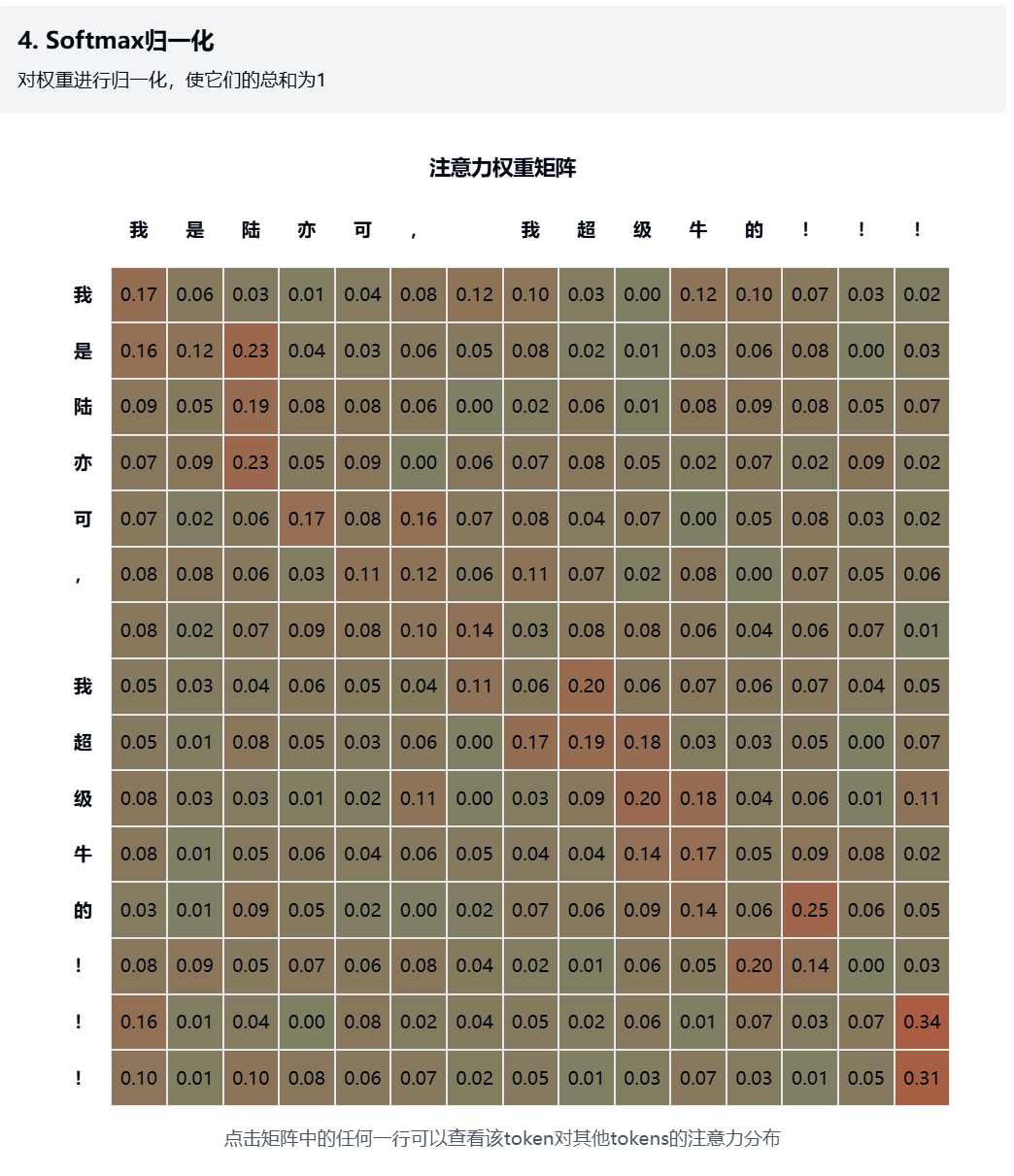
2.4. Softmax归一化 - 展示归一化后的权重分布
2.5. 加权聚合 - 展示最终如何根据权重汇总信息
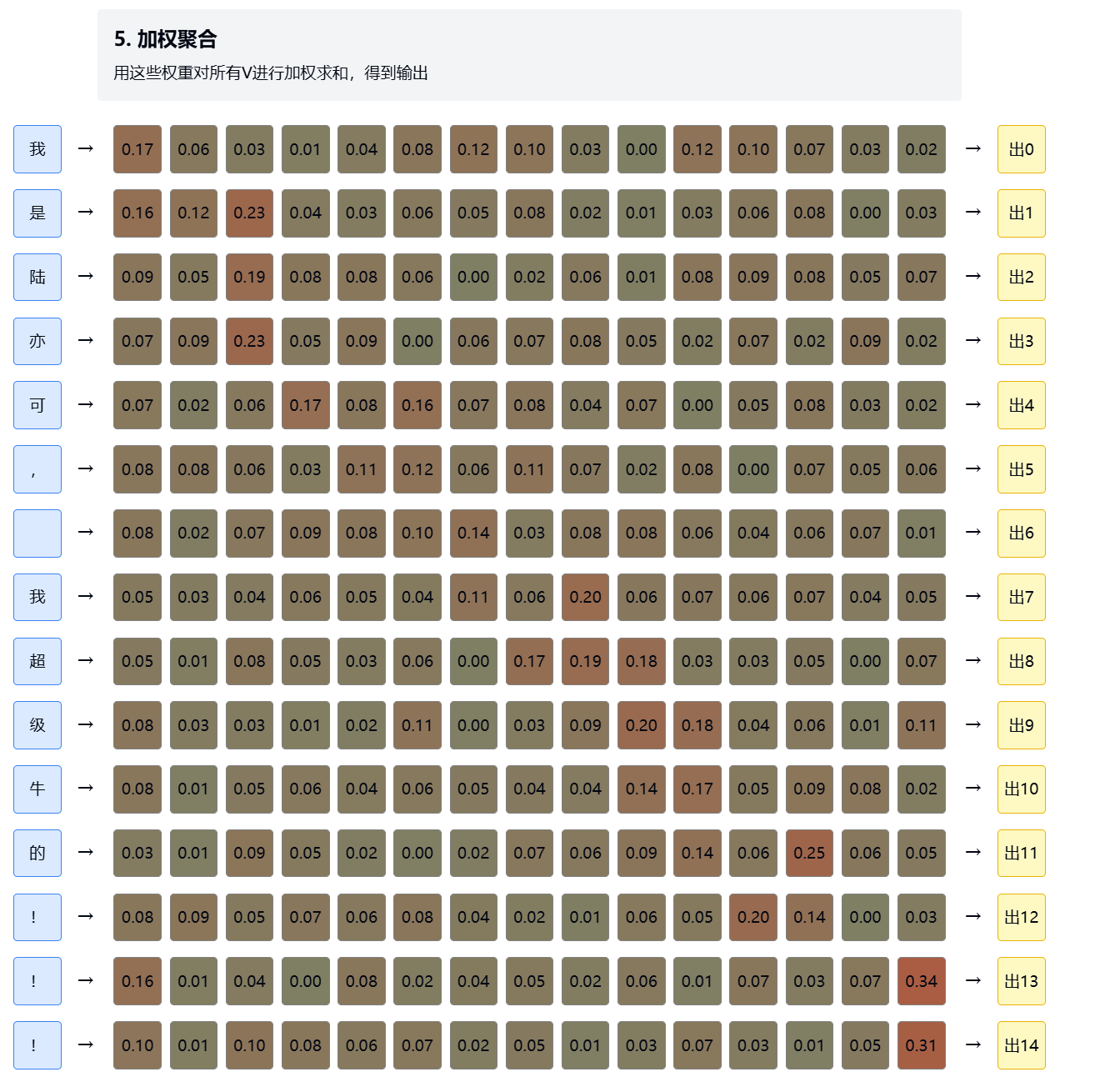
在自注意力机制中,加权聚合是指用计算出的注意力权重对所有值向量(V)进行加权求和,以生成每个位置的新表示。这是整个自注意力过程的最后一步,也是最核心的信息融合阶段。
具体步骤
假设我们有一个序列"自注意力很强大":
-
首先,每个字符都有自己的值向量(V),比如:
- "自"的值向量:V₁
- "注"的值向量:V₂
- "意"的值向量:V₃
- "力"的值向量:V₄
- "很"的值向量:V₅
- "强"的值向量:V₆
- "大"的值向量:V₇
-
然后,通过前面的步骤,我们为每个位置计算出了一组注意力权重。例如,对于"自"这个字,它对所有字的注意力权重可能是:
- 对"自"的权重:0.5 (自己关注自己最多)
- 对"注"的权重:0.2
- 对"意"的权重:0.1
- 对"力"的权重:0.1
- 对"很"的权重:0.05
- 对"强"的权重:0.03
- 对"大"的权重:0.02
(这些权重加起来等于1,因为它们经过了softmax归一化)
-
加权聚合步骤:对于"自"这个位置,它的新表示是所有字符的值向量按照上述权重加权求和:
新表示 = 0.5 × V 1 + 0.2 × V 2 + 0.1 × V 3 + 0.1 × V 4 + 0.05 × V 5 + 0.03 × V 6 + 0.02 × V 7 新表示 = 0.5×V₁ + 0.2×V₂ + 0.1×V₃ + 0.1×V₄ + 0.05×V₅ + 0.03×V₆ + 0.02×V₇