使用Python爬虫技术,通过Requests和lxml采集豆瓣Top250电影数据(含名称、评分、评价人数等),并利用Pandas进行数据清洗与分析。结合Matplotlib/Seaborn绘制评分分布、国家统计等可视化图表,WordCloud生成类型词云,完整实现从数据采集到分析的全流程,揭示高分电影特征与观众偏好。
1. 项目概述
1.1 背景与目的
在当今数字时代,电影作为重要的文化载体和娱乐方式,其艺术价值与市场表现一直备受关注。本研究旨在通过数据采集与分析技术,系统性地挖掘豆瓣Top250榜单中隐含的规律与洞见。通过可视化手段揭示高分电影的共同特征、年代分布趋势及地域分布特点;另一方面,分析观众评价行为背后反映的审美偏好,探讨电影艺术价值与大众接受度之间的关系。最终希望为电影创作提供数据支持,同时为观众选片提供客观参考,促进电影文化的传播与交流。
1.2 技术栈介绍
本项目采用Python技术栈,涵盖数据采集、清洗、分析与可视化全流程:
数据采集
-
Requests:发送HTTP请求,获取网页HTML
-
lxml:解析HTML结构,精准提取电影数据
-
随机延迟(
time.sleep + random):模拟人类操作,规避反爬 -
异常处理:应对封IP、验证码、重定向等反爬机制
数据分析与可视化
-
Pandas:数据清洗(年份/国家/类型字段拆分)、统计分析
-
Matplotlib + Seaborn:绘制评分分布、散点图、折线图等
-
WordCloud:生成电影类型词云,直观展示高频类型
-
Jieba(虽未直接使用,但常用于中文文本处理)
文件与持久化
-
CSV:存储结构化数据(
top250.csv)
2. 数据采集过程
2.1 数据介绍
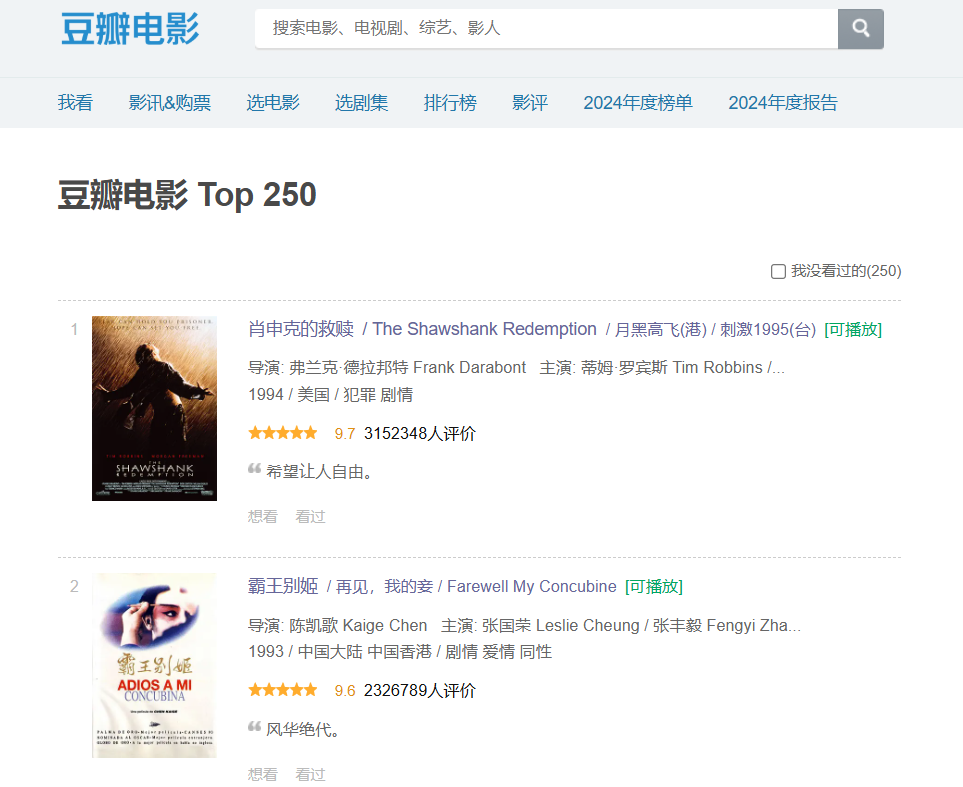
本次采集的目标数据是豆瓣电影Top250榜单,主要字段如下:
-
排名:电影在Top250中的序号(1~250)
-
电影名称:中文名(部分含原名)
-
导演和主演:第一行通常为导演,后续为主演
-
年份/国家/类型:混合字段(如"1994 / 美国 / 犯罪 剧情")
-
评分:豆瓣评分(10分制,如9.7)
-
评价人数:参与评分的人数(如"280万")
2.2 代码实战
1. 页面分析
打开豆瓣电影Top250页面(豆瓣电影 Top 250)
右击页面 → 检查(或按 F12),进入开发者工具(DevTools)
切换到 Network(网络) 选项卡,刷新页面,观察请求的URL和响应数据。
2. URL规律分析
翻页时,URL变化如下:
第1页:https://movie.douban.com/top250?start=0&filter=
第2页:https://movie.douban.com/top250?start=25&filter=
第3页:https://movie.douban.com/top250?start=50&filter=
...
第10页:https://movie.douban.com/top250?start=225&filter=3. 请求头(Headers)获取
在Headers部分,找到RequestHeaders下的User-Agent,复制其值
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}Cookie(可选):如果需要登录后才能访问的数据,需在headers 中添加 Cookie(同样在Request Headers中获取)。
4. 数据解析
分析HTML结构:
在Elements(元素) 选项卡,找到电影列表的HTML结构
每部电影的数据均包裹在 <li> 标签内,类名为item
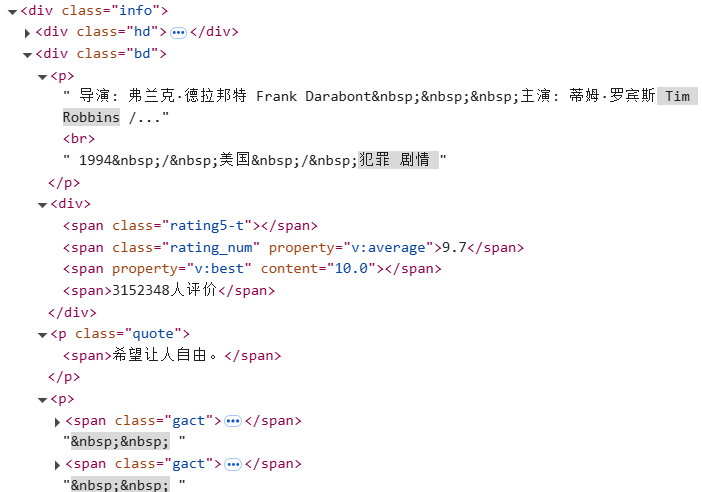
XPath提取关键数据:
电影名称://span[@class="title"]/text()
导演信息://div[@class="bd"]/p[1]/text()
年份/国家/类型://div[@class="bd"]/p[2]/text()
评分://span[@class="rating_num"]/text()
评价人数://span[contains(text(), "人评价")]/text()
def get_movie_info(movie):
name = movie.xpath('.//span[@class="title"]/text()')[0] # 电影名
director = movie.xpath('.//div[@class="bd"]/p[1]/text()')[0].strip() # 导演
year_info = movie.xpath('.//div[@class="bd"]/p[2]/text()')[0].strip() # 年份/国家/类型
rating = movie.xpath('.//span[@class="rating_num"]/text()')[0] # 评分
votes = movie.xpath('.//span[contains(text(), "人评价")]/text()')[0] # 评价人数
return name, director, year_info, rating, votes5. 存储数据
存储所有电影数据至CSV文件
with open("douban_top250.csv", "w", encoding="utf-8-sig", newline="") as f:
writer = csv.writer(f)
writer.writerow(["排名", "电影名称", "导演", "年份/国家/类型", "评分", "评价人数"])
for i, movie in enumerate(movies, 1):
name, director, year_info, rating, votes = get_movie_info(movie)
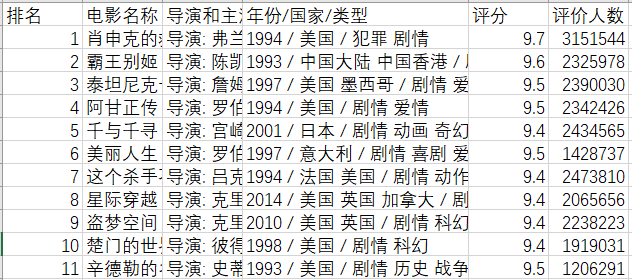
writer.writerow([i, name, director, year_info, rating, votes])2.3 结果展示
部分结果如下:
3. 可视化分析
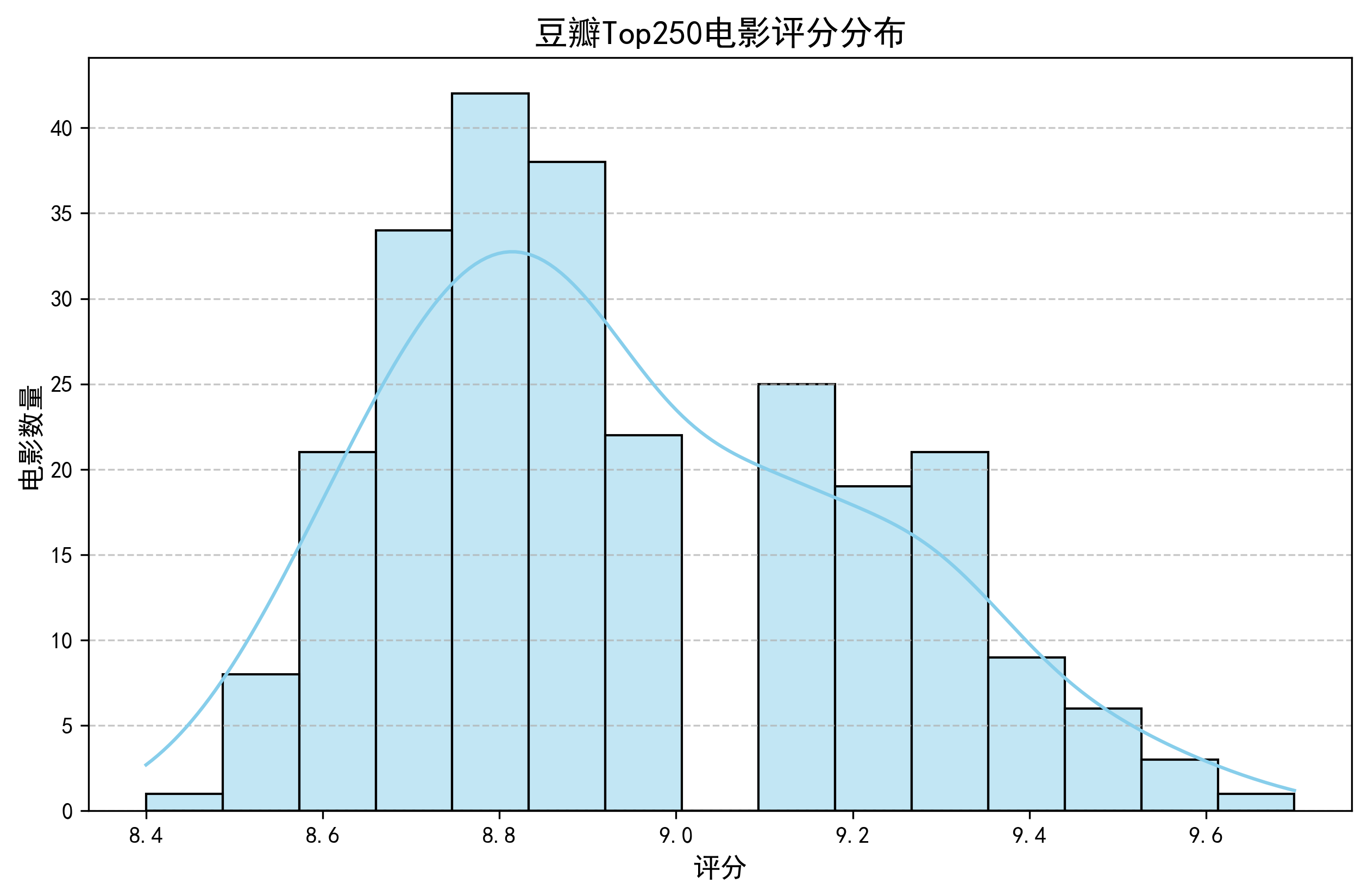
3.1 评分分布特征
本部分通过直方图分析豆瓣Top250电影的评分分布情况。使用Seaborn库绘制带核密度估计的直方图,设置15个分箱以展示评分数据的集中趋势和离散程度。图表添加了网格线和标签,确保可读性。通过观察评分分布形态,可以了解高分电影的整体质量水平以及评分的波动特征。
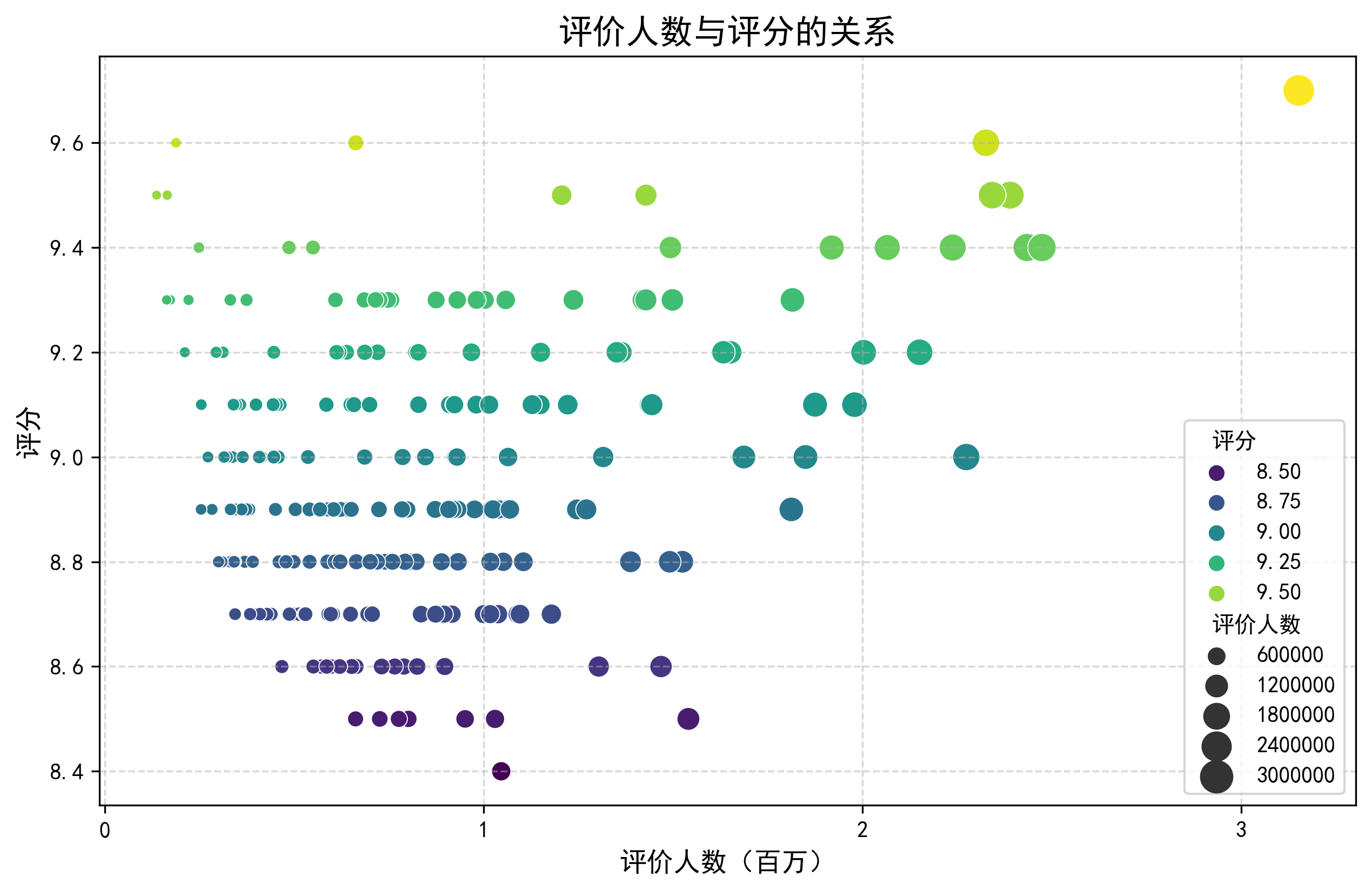
3.2 评价人数与评分关系
该分析采用散点图探索电影热度与质量的关系。将评价人数作为x轴,评分作为y轴,通过点的大小和颜色双重编码评价人数和评分数据。图表设置了合理的坐标轴刻度和网格线,并添加颜色图例。这种可视化方法可以直观展示电影受欢迎程度与艺术价值之间的潜在关联。
3.3 电影类型词云解析
本部分使用词云技术展示电影类型的分布特征。首先将各电影的类型字段合并,经过空格处理后生成连续的文本。采用WordCloud库创建词云图,设置中文字体以避免乱码。词云通过字体大小直观表现类型的出现频率,背景设为白色以提高可读性,适合展示文本型数据的分布模式。

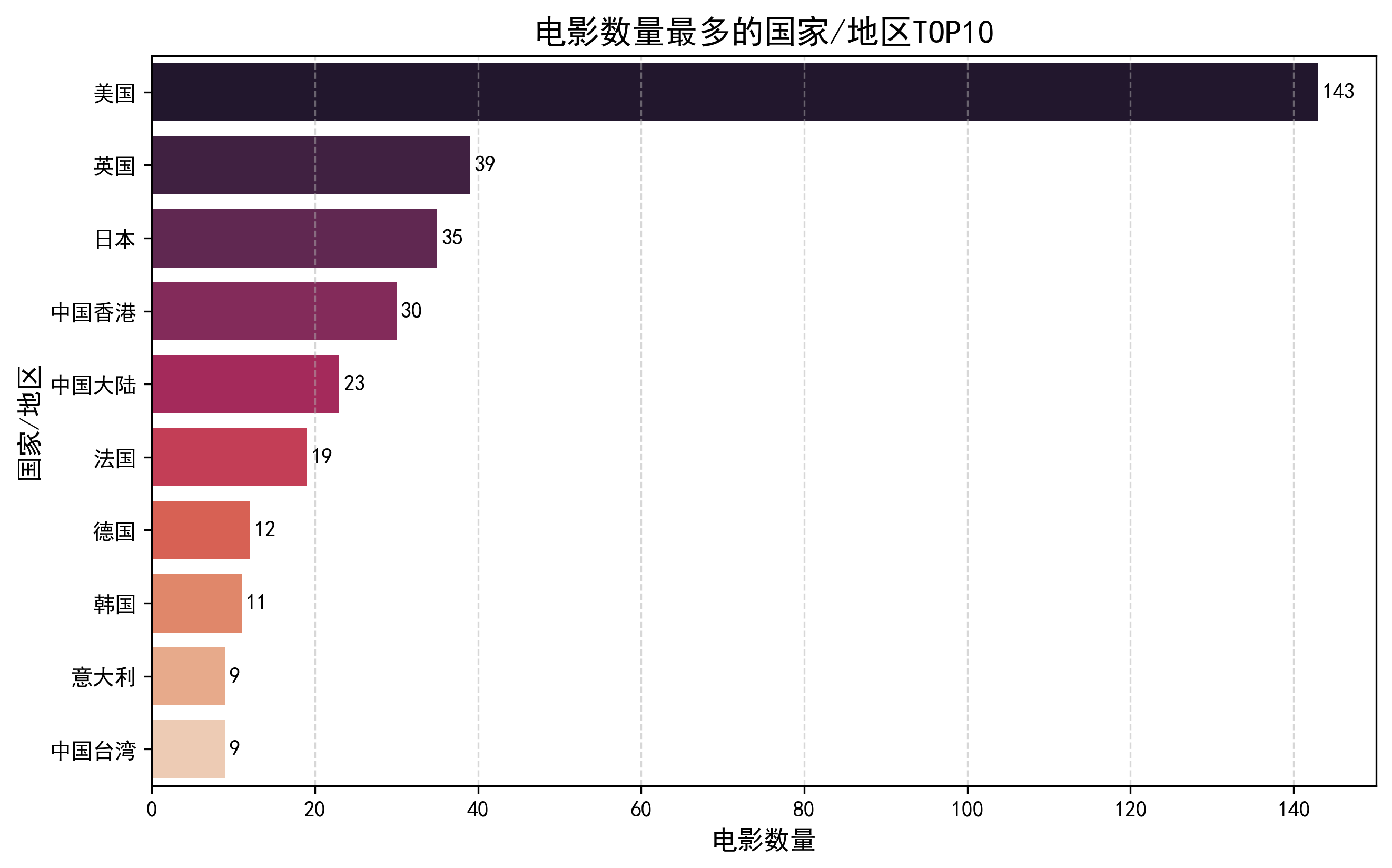
3.4 国家/地区分布TOP10
该分析使用条形图展示电影产地的分布情况。对国家字段进行拆分和计数后,选取出现频率最高的10个国家/地区。采用横向条形图设计,使用rocket配色方案,并在条形末端标注具体数值。图表添加了网格线和清晰的坐标轴标签,便于比较不同地区的电影产量差异。
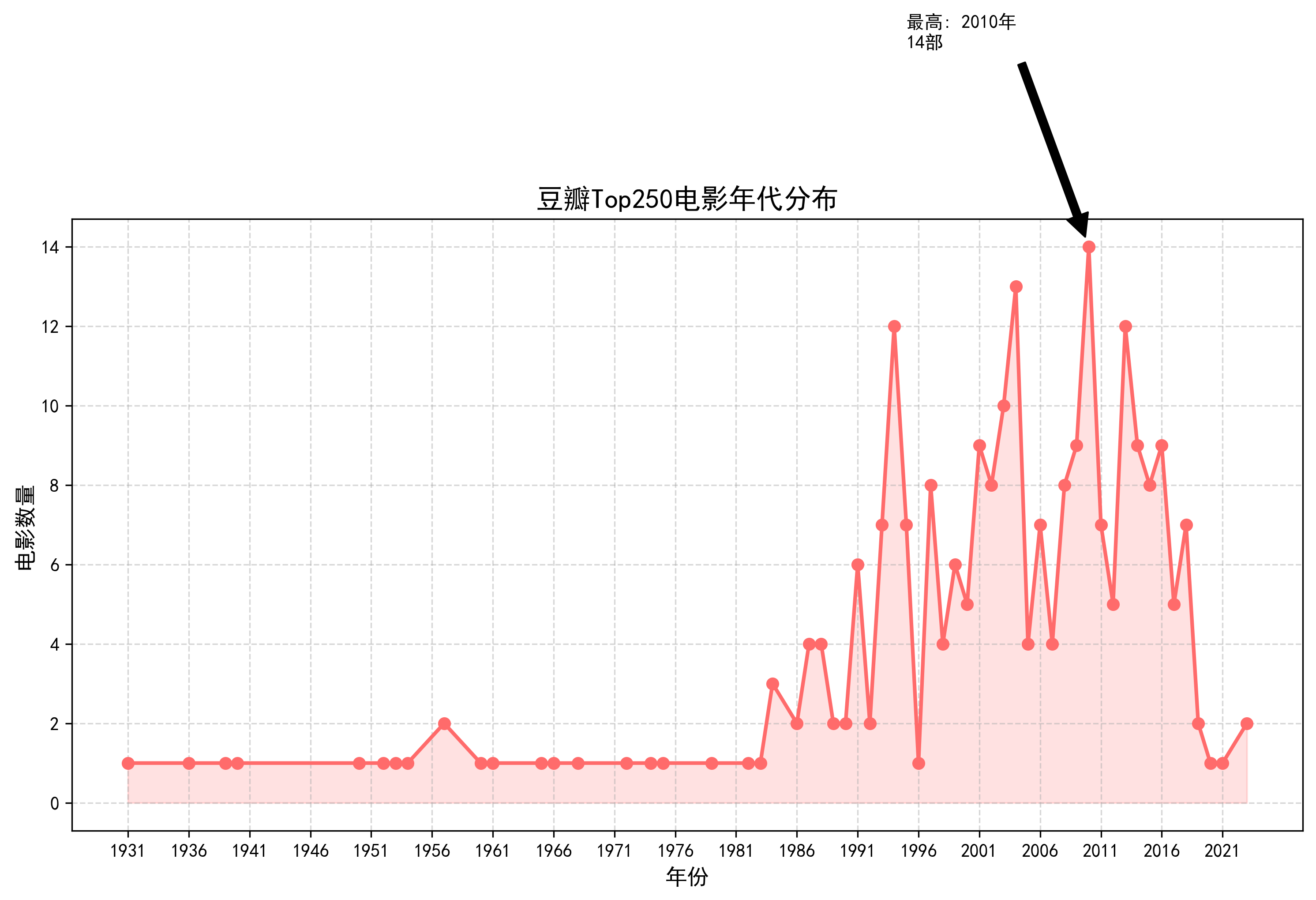
3.5 年代分布趋势
本部分通过折线图分析电影的时间分布特征。首先提取年份字段并进行频次统计,按年代排序后绘制带标记点的折线图。图表使用填充色增强视觉效果,设置5年为间隔的x轴刻度。特别标注了电影数量最多的年份,并添加箭头注释,突出显示重要时间节点。这种可视化方法能清晰展现电影艺术发展的历史轨迹。
4. 分析结果
4.1 豆瓣高分电影特征总结
通过对豆瓣Top250电影数据的综合分析,可以得出以下核心结论:首先,在电影特征方面,高分作品呈现出明显的集中分布规律,评分主要集中在8.5-9.5分区间,其中剧情类电影占据绝对优势,且常与犯罪、爱情等类型融合。这些优质电影在时间分布上呈现出显著的"黄金年代"特征,特别是1990-2000年间涌现了大量经典作品。从地域分布来看,美国电影在数量上占据主导,但欧洲和亚洲电影在艺术成就上表现更为突出,体现了不同地区电影产业的特色优势。
4.2 观众偏好分析
在观众偏好方面,数据显示口碑与热度呈现显著正相关,高评分电影往往能吸引更多观众参与评价。观众对具有深刻叙事和情感共鸣的剧情片表现出明显偏爱,同时对非英语文化背景的优秀作品也保持着较高接受度。值得注意的是,经得起时间检验的经典老片在榜单中占据主要地位,而近年新片的入选比例相对较低,这既反映了艺术价值需要时间沉淀的特点,也暗示当代电影创作可能存在某些局限性。
4.3 电影产业发展观察
从产业发展角度来看,数据分析揭示了电影艺术成就与产业生态之间的复杂关系。美国凭借成熟的工业体系在数量和质量上保持领先,欧洲则依靠作者电影的传统维持着较高的艺术水准,亚洲电影虽然在特定类型上有所突破,但整体多样性仍有提升空间。值得注意的是,商业大片在榜单中的稀缺性,以及英语电影的过度代表性,都反映出当前评价体系可能存在的文化偏向。随着流媒体平台的崛起和全球化进程的深入,未来电影评价标准和榜单构成或将面临新的变革,这为电影产业的多元化发展提供了新的可能性。