目录
一、启动neo4j
windows系统中,首先切换到 Neo4j bin目录,然后运行命令启动 Neo4j:neo4j.bat console。
cd /d D:\neo4j-community-3.5.5\bin
neo4j.bat console
二、Py2neo
Py2neo 是一个用于与 Neo4j 图数据库交互的 Python 客户端库和工具集。它为 Python 应用程序提供了与 Neo4j 图数据库交互的功能,支持 Bolt 和 HTTP 协议,并提供了一套高级 API、对象图映射(OGM)、管理工具、Cypher 词法分析器等。
基于Py2neo库可以对neo4j图数据库进行增删改查等操作,代码如下:
from typing import Union
from py2neo import Graph, Node, Relationship
class Neo4jDatabase:
def __init__(self, username, password, uri="bolt://localhost:7687"):
self.graph = Graph(uri, auth=(username, password))
def create_node(self, label: str, node_name: str, **properties) -> Node:
"""
创建一个节点,并可以输入节点的属性信息
"""
node = Node(label, name=node_name, **properties)
self.graph.create(node)
return node
def create_relationship(self,
start_node: Union[int, Node],
relationship_type: str,
end_node: Union[int, Node],
**properties) -> Relationship:
"""
创建两个节点之间的关系
输入节点ID或节点本身
"""
if isinstance(start_node, int):
start_node = self.graph.nodes.get(start_node)
if isinstance(end_node, int):
end_node = self.graph.nodes.get(end_node)
relationship = Relationship(start_node, relationship_type, end_node, **properties)
self.graph.create(relationship)
return relationship
def delete_node(self, node: Union[int, Node]):
"""
删除一个节点及其所有关系
"""
if isinstance(node, int):
node = self.graph.nodes.get(node)
self.graph.delete(node)
def delete_relationship(self, relationship: Union[int, Relationship]):
"""
删除一个关系
"""
if isinstance(relationship, int):
relationship = self.graph.relationships.get(relationship)
self.graph.separate(relationship)
def update_node(self, node: Union[int, Node], **properties):
"""
更新节点属性
"""
if isinstance(node, int):
node = self.graph.nodes.get(node)
for key, value in properties.items():
node[key] = value
self.graph.push(node)
def update_relationship(self, relationship: Union[int, Relationship], **properties):
"""
更新关系属性
"""
if isinstance(relationship, int):
relationship = self.graph.relationships.get(relationship)
for key, value in properties.items():
relationship[key] = value
self.graph.push(relationship)
def find_node(self, label: str, **properties) -> list:
"""
查询节点
"""
return list(self.graph.nodes.match(label, **properties))
def find_relationship(self, start_node: Union[int, Node], end_node: Union[int, Node]) -> list:
"""
查询两个节点之间的关系
输入节点ID或节点本身
"""
if isinstance(start_node, int):
start_node = self.graph.nodes.get(start_node)
if isinstance(end_node, int):
end_node = self.graph.nodes.get(end_node)
return list(self.graph.match((start_node, end_node)))
def delete_all(self):
"""
删除所有已有节点和关系
"""
self.graph.delete_all()
if __name__ == '__main__':
# 创建NEO4J实例
username = "neo4j" # Neo4j用户名
password = "" # Neo4j密码
neo4j_instance = Neo4jDatabase(username, password)
# 测试create_node
node1 = neo4j_instance.create_node("Person", "Alice")
assert node1["name"] == "Alice"
# 测试create_relationship
node2 = neo4j_instance.create_node("Person", "Bob")
relationship_knows = neo4j_instance.create_relationship(node1, "KNOWS", node2)
assert relationship_knows.start_node == node1
assert relationship_knows.end_node == node2
assert type(relationship_knows) == Relationship.type("KNOWS")
# 测试update_node
neo4j_instance.update_node(node1, age=30)
assert node1["age"] == 30
# 测试update_relationship
neo4j_instance.update_relationship(relationship_knows, since=2020)
assert relationship_knows["since"] == 2020
# 测试find_node
found_nodes = neo4j_instance.find_node("Person", name="Alice")
assert len(found_nodes) > 0
assert found_nodes[0]["name"] == "Alice"
# 测试find_relationship
found_relationships = neo4j_instance.find_relationship(node1, node2)
assert len(found_relationships) > 0
assert type(found_relationships[0]) == Relationship.type("KNOWS")
# 测试delete_relationship
neo4j_instance.delete_relationship(relationship_knows)
found_relationships_after_delete = neo4j_instance.find_relationship(node1, node2)
assert len(found_relationships_after_delete) == 0
# 测试delete_node
neo4j_instance.delete_node(node1)
found_nodes_after_delete = neo4j_instance.find_node("Person", name="Alice")
assert len(found_nodes_after_delete) == 0
# 测试delete_all
neo4j_instance.delete_all()三、创建豆瓣电影图数据库
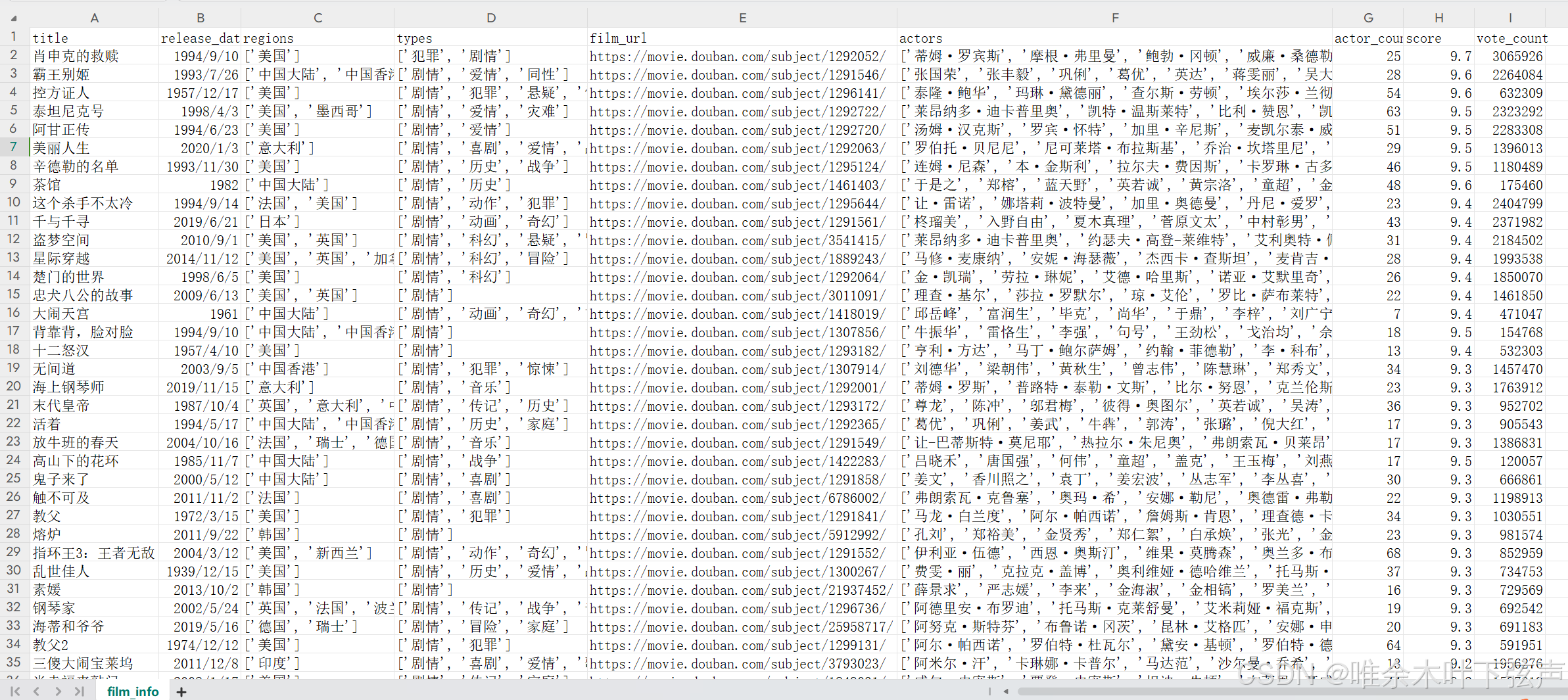
数据来自采集豆瓣网分类排行榜 (“https://movie.douban.com/chart”)中各分类类别所有电影的相关信息并存储为csv文件。
爬虫代码在我另一篇博客:豆瓣电影信息爬取与可视化分析
数据放在了百度云上:https://pan.baidu.com/s/1yewbSREZlCS_ZA3eszO3jw?pwd=pi8t
数据如下图所示,包含电影名、上映日期、上映地区、类型、豆瓣链接、参演演员、演员数、评分、打分人数,共有6300多部电影:
创建图数据库代码如下:
if __name__ == '__main__':
import pandas as pd
# 创建NEO4J实例
username = "neo4j" # Neo4j用户名
password = "" # Neo4j密码
neo4j_instance = Neo4jDatabase(username, password)
neo4j_instance.delete_all()
df = pd.read_csv("film_info.csv")
df.regions = df.regions.apply(eval)
df.types = df.types.apply(eval)
df.actors = df.actors.apply(eval)
actors_dict = {}
regions_dict = {}
types_dict = {}
# 创建演员节点
for actor in df.explode('actors').actors.unique():
node = neo4j_instance.create_node("Actor",actor)
actors_dict[actor] = node.identity
print(f"创建演员节点{len(actors_dict)}个")
# 创建地区节点
for region in df.explode('regions').regions.unique():
node = neo4j_instance.create_node("Region", region)
regions_dict[region] = node.identity
print(f"创建地区节点{len(regions_dict)}个")
# 创建类型节点
for type in df.explode('types').types.unique():
node = neo4j_instance.create_node("Type", type)
types_dict[type] = node.identity
print(f"创建电影类型节点{len(types_dict)}个")
# 创建电影节点及关系
for _, row in df.iterrows():
node = neo4j_instance.create_node("Film",
row["title"],
上映日期=row["release_date"],
豆瓣链接=row["film_url"],
演员个数=row["actor_count"],
评分=row["score"],
打分人数=row["vote_count"]
)
for type in row["types"]:
neo4j_instance.create_relationship(node, "TYPE_IS", types_dict[type])
for region in row["regions"]:
neo4j_instance.create_relationship(node, "REGION_IS", regions_dict[region])
for actor in row["actors"]:
neo4j_instance.create_relationship(actors_dict[actor], "ACT", node)
print("电影节点及关系创建完成")
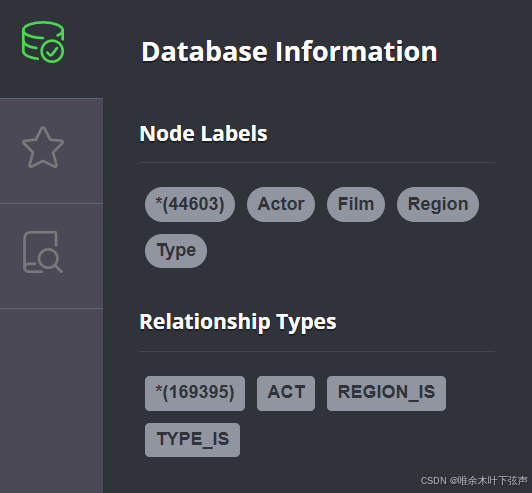
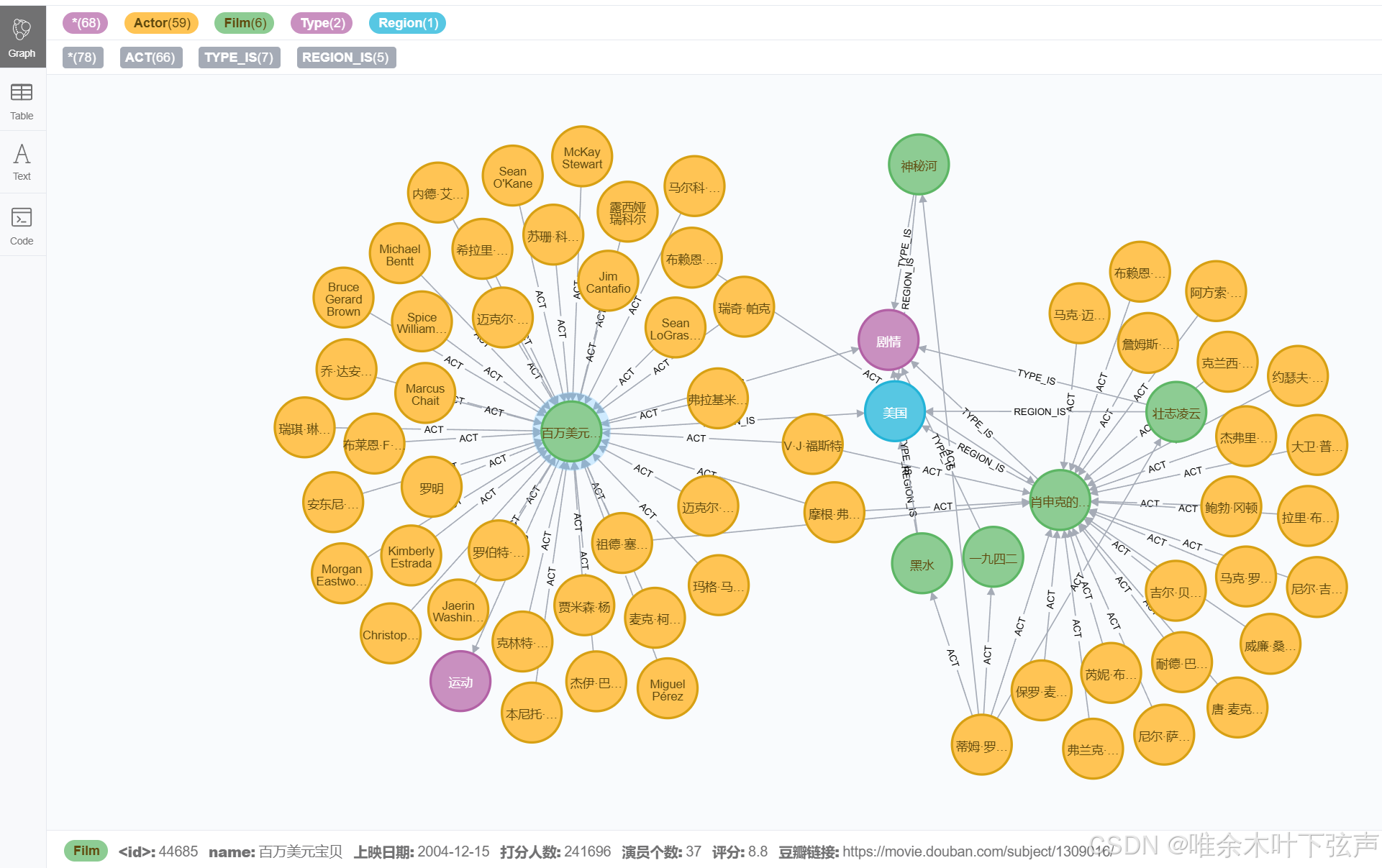
四、总结
本项目实现了一个Neo4jDatabase类,基于py2neo操作Neo4j图数据库。然后从豆瓣电影网爬取相关信息,在Neo4j数据库中创建相应的节点和关系,实现了电影数据的结构化存储。