目标
Trae 号称国内首个 AI IDE,且免费,看着就心动,试水一下,看看能不能替代vsCode+智能助手这种传统模式。
所以,实现和上一篇,一模一样的功能,就是用Ai翻译大藏经,上一篇的实现过程,参考文档:
准备
就是准备大模型的调用,也是必须的,参考下面文档中,api-key的获得部分:
【菜鸟飞】AI多模态:vsCode下python访问阿里云通义文生图API-CSDN博客
下载安装
下载安装程序,直接点击“立即获取Trae”,自己会识别当前系统信息,下载匹配版本,当然也可以自己点击“查看所有下载选项”,找对应的版本下载:
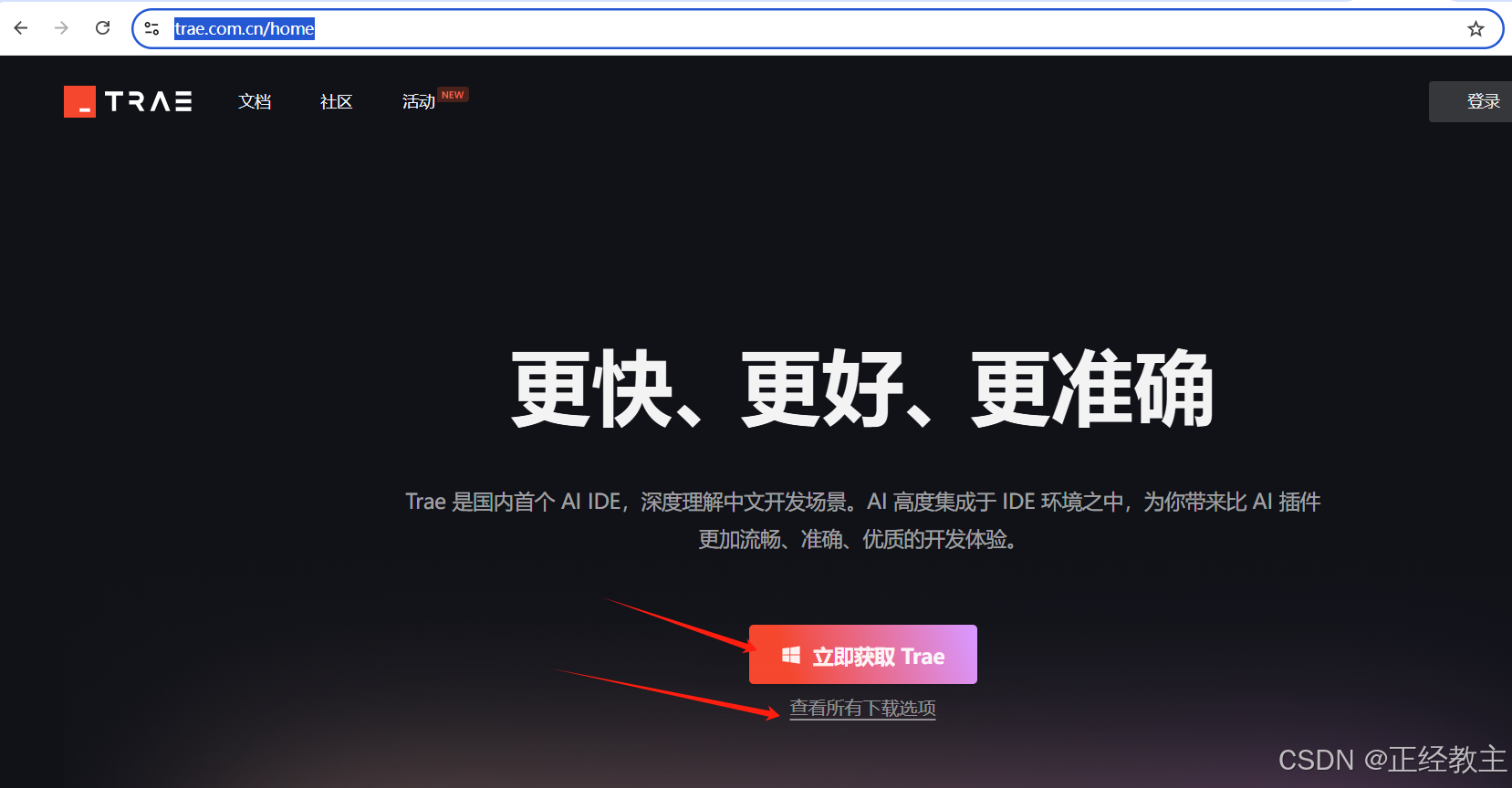
直接运行,“下一步”、“下一步”安装,其中安装目录可以换成空闲磁盘多的目录:
其他就一路“下一步”,就完成了
开始运行
有网络提示:允许
然后,“开始”:
选择样式主题,和语言:

可以从现有开发环境导入配置,我这里就从vsCode直接导入了:
为了日后用着方便,安装命令行:
然后,需要登录,才能有IA支持功能:
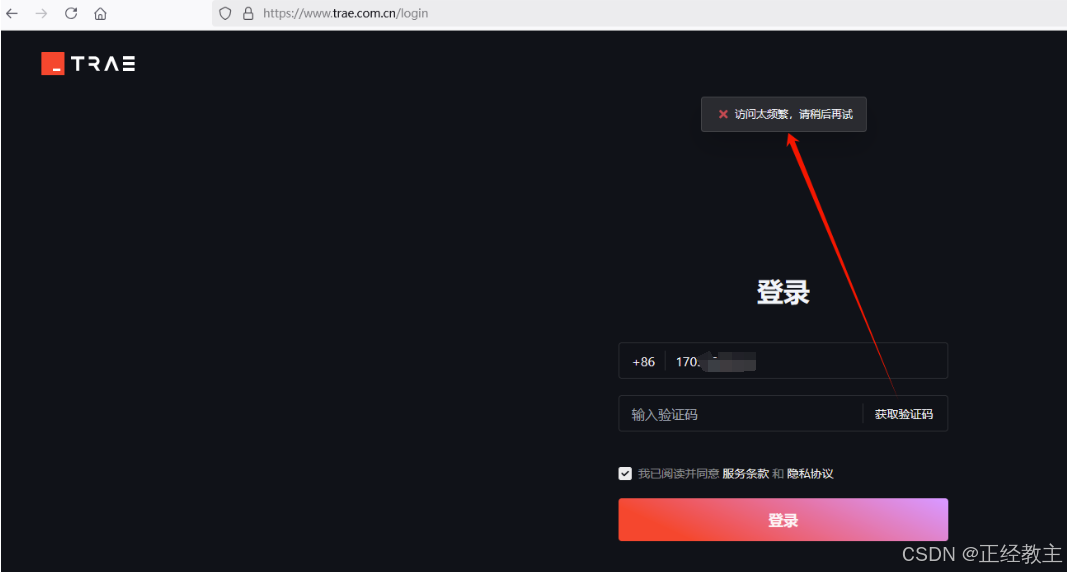
点击登录,会在浏览器,打开登录网址,不支持虚拟手机号,否则会提示“访问太频繁。。。”,正常手机号,能注册登录:
登录后,看起来和vdCode的界面差不多,打开一个空文件夹,作为工作空间,然后我就把上一篇AI实例的操作过程,搬过来,对比一下执行情况。
实践过程
1、在chat中,说出自己的要求,让其推荐大模型:
把文档中的佛经内容,翻译成白话文,尽量保持其原意和语境,用那个大模型好?
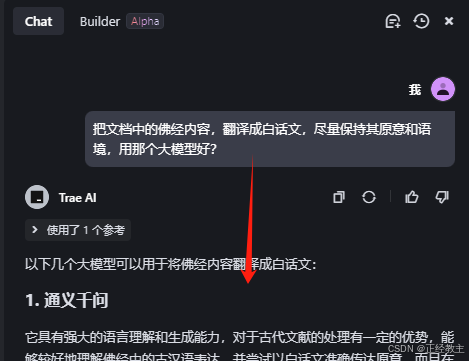
给出的模型里,有通义千问,还有其他的,我准备了通义中的访问API-key,就用这个模型了。
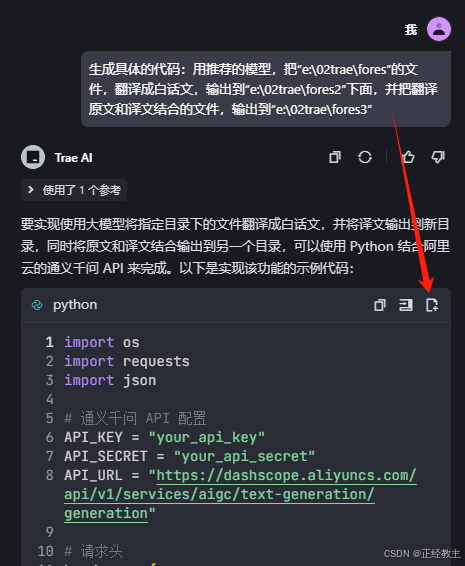
2、然后,进一步提出要求:
生成具体的代码:用推荐的模型,把“e:\02trae\fores”的文件,翻译成白话文,输出到“e:\02trae\fores2”下面,并把翻译原文和译文结合的文件,输出到“e:\02trae\fores3”
给出了代码,其中操作和vs+通义灵码中的操作,一样是三个:拷贝、插入、新建文件:
新建文件时,会在编程器创建一个文件,手动保存,选择保存目录,在vs中,是直接显示保存路径,我觉得这里要好一些,因为在保存之前,可以看代码,还能调整一下。
3、因为是代码用的是requests,我让它改了一下:
换成openai的访问方式
这时给出的代码,命令有运行按钮,代码旁边,有“应用”按钮,这是超过vs+通灵的
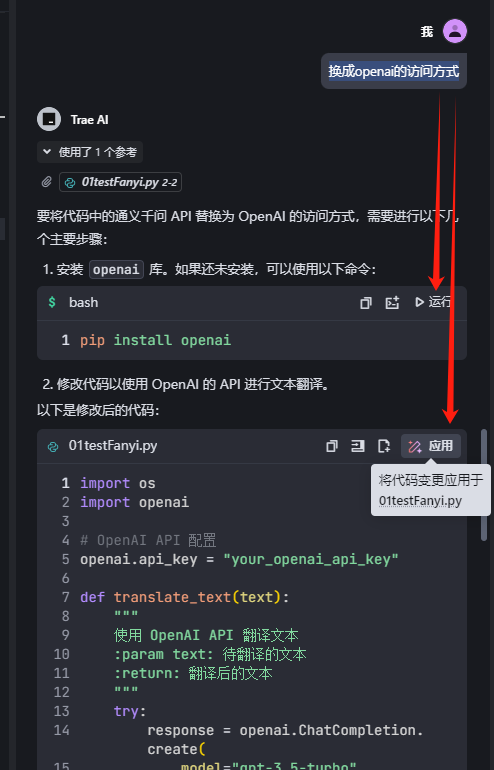
点击“将代码变更应用于。。。”,看到文件代码被替换,且有标识,并可以选择是否接受:
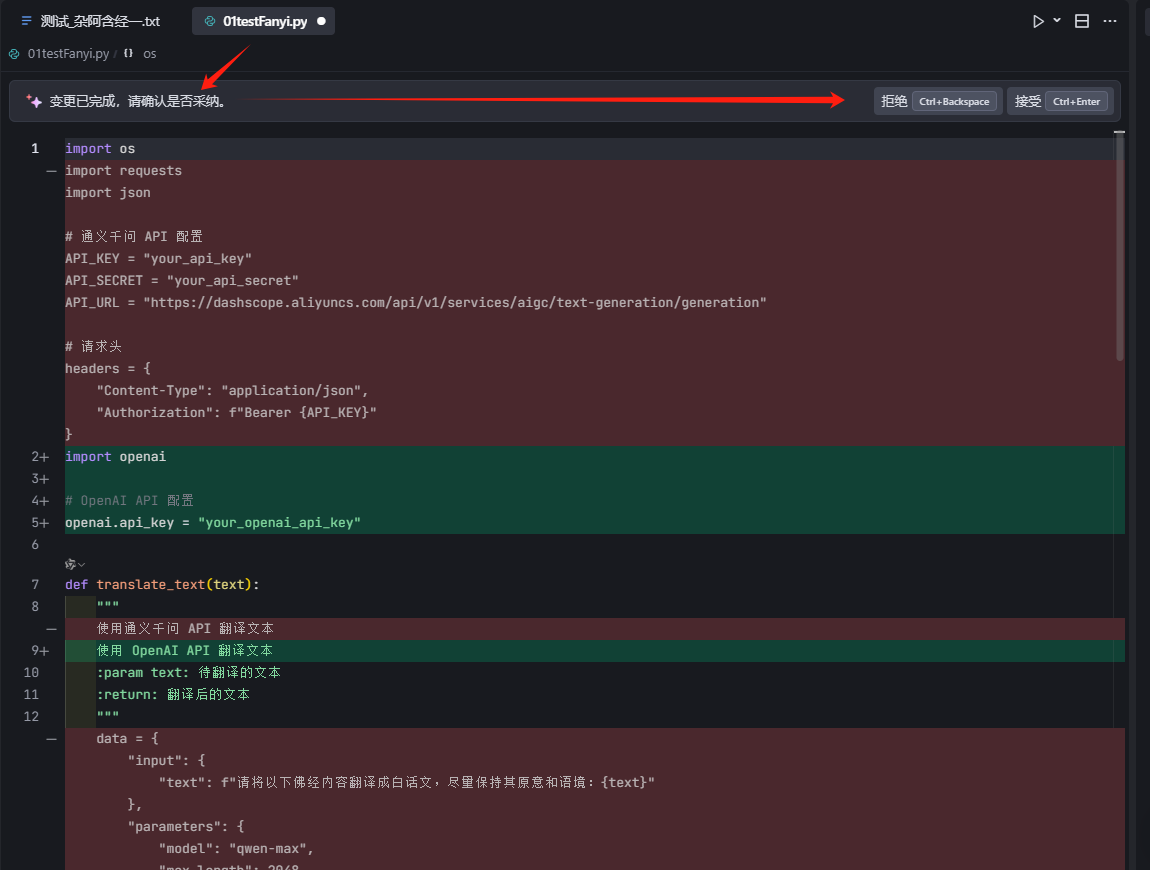
3、 看了一下代码,进一步优化:
优化:
1、通过系统环境变量DASHSCOPE_API_KEY获得api_key
2、调用通义千问 API(基于openai),调用通义云适合翻译大藏经的模型
优化后运行,运行按钮和vs差不多:

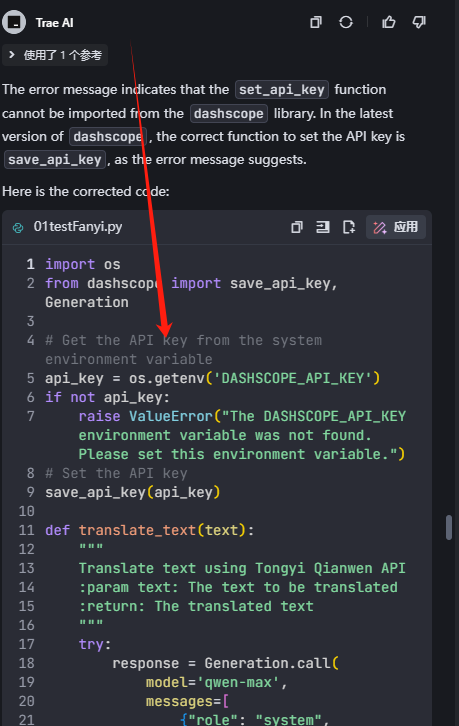
运行出错后,直接提问,可以识别错误,进行修改
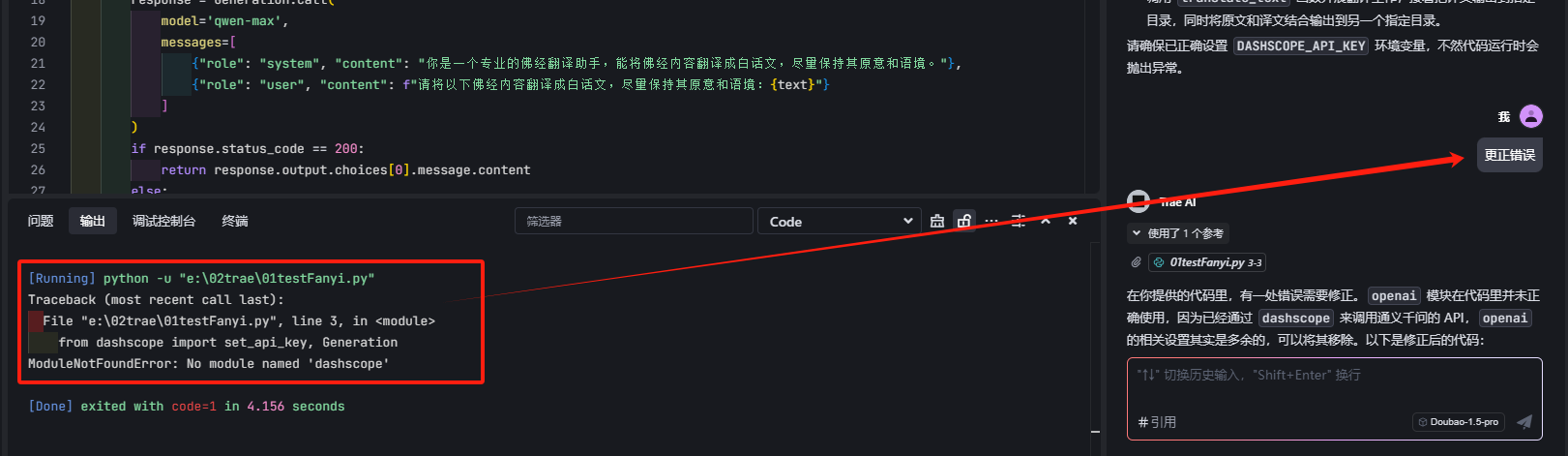 但很遗憾,它识别了错误,没有解决,我想念通灵了,好在trae从vscode中把插件信息也读过来了,所有我就有了两个程序助手,测试过程,发现还是需要把错误信息喂给AI,要不它就自己在那里猜来猜去:
但很遗憾,它识别了错误,没有解决,我想念通灵了,好在trae从vscode中把插件信息也读过来了,所有我就有了两个程序助手,测试过程,发现还是需要把错误信息喂给AI,要不它就自己在那里猜来猜去:
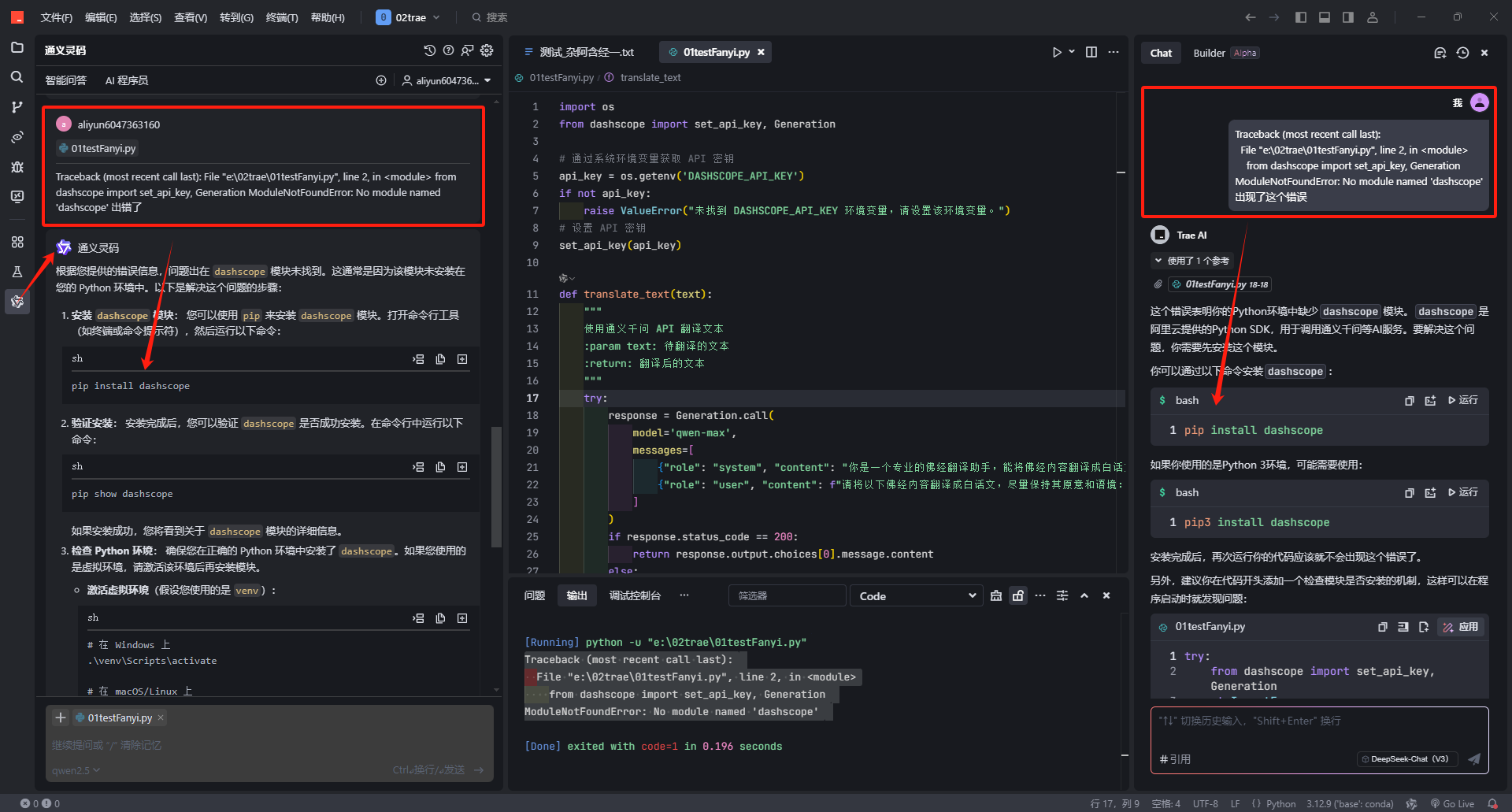 然后,有经过多轮沟通,然后我手动调整了错误,哎,心力憔悴,还是要总结一下。
然后,有经过多轮沟通,然后我手动调整了错误,哎,心力憔悴,还是要总结一下。
补充
启用Trae-builder方式,

启动后,可以添加选择支持的模型,使用界面和通灵和豆包差不多,但复杂问题,它是分层解决的,先解决一部分,你接受了,在解决一部分,分步骤的。
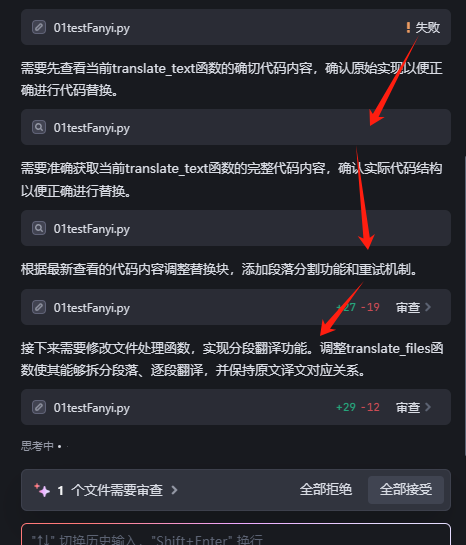
亮点
下面几点是Trae独有的,非常加分的功能:
*1、代码自动补全,根据上下文,AI自动判断推荐代码,按Tab键就表示采纳
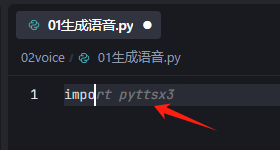
所以,你可以一直“Tab”,直到完成整个程序,中间,可以通过增加注释,调整AI生成代码的方向:
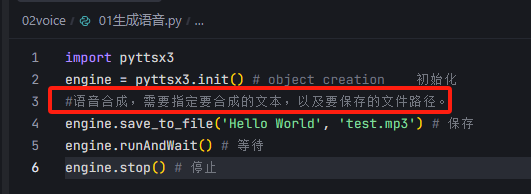
2、内嵌式交互:
在编辑区,输入ctr+i,可以内置聊天对话:
输入要求:
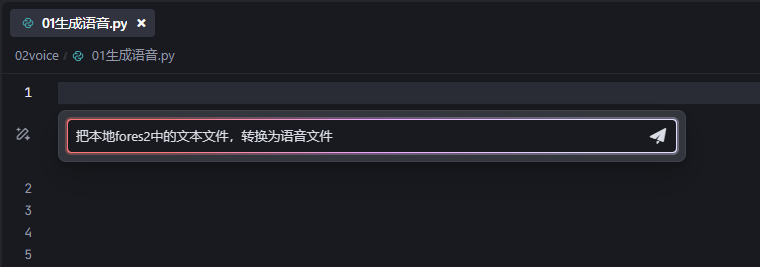
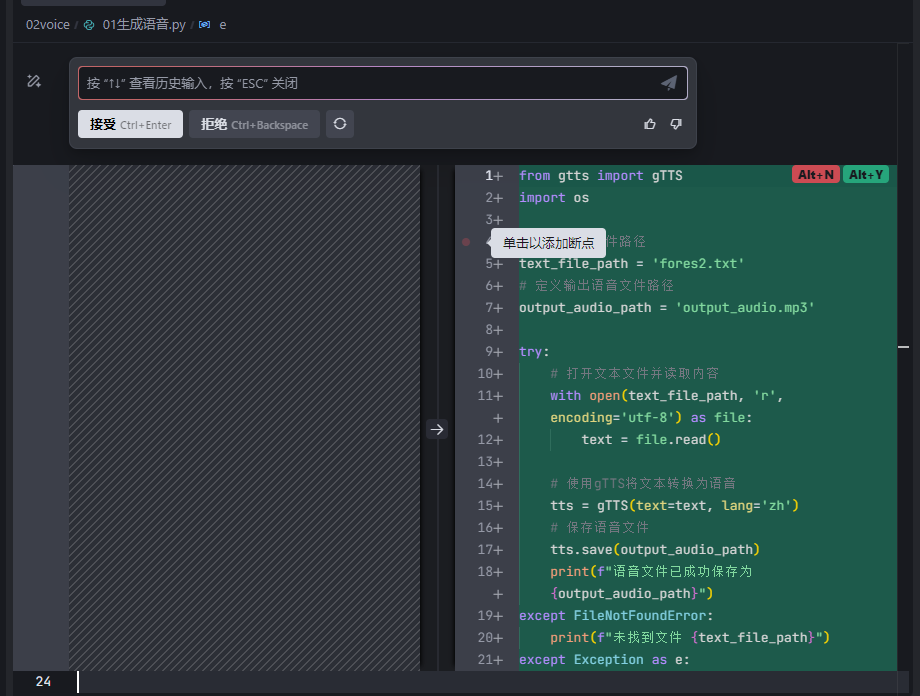
代码直接显示,我这里因为原文件有空行,所以显示为替换样式:
3、可以局部代码发送到对话中,选中需要优化的代码行,右键发送到对话,可以局部调整功能
结论
1、Trae提示的操作性更友好,直接可以运行,及代码替换等,特别特别是局部代码补全等。
2、Trae有分步骤处理问题的功能,但这就因人而异了,是逐步确认,还是一步到位,看使用者习惯。
3、Trae有时你问的内容全英文,它就切换到全英文环境了:
看似有点“不稳定”,看其他视频,可以通过配置来设置“AI会话语言”,但我当前的Trae CN V0.3.1中,没有找到,搜了帮助都没找到。抛开这个点,总体解决问题的水平,感觉差不多。
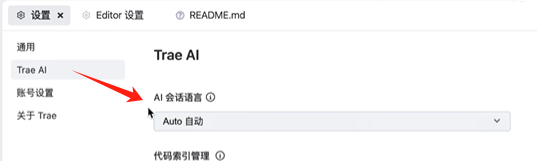
(上图为,别人家的设置界面,供参考)
4、解决问题主要是靠模型,初看差的不多,个人喜欢通灵多一些。
5、Trae的安装到使用,不得不说对小白很友好。
6、当问题解决不了,总是在打转的时候,就靠人破局了,所以人脑是问题的最后利器~
7、从前面测试看,硬性代码支持差不多,Trae胜出于跟优化的操作交互,所以结论是:Trae 可以平替传统vs+代码助手。
编者的话
因为还没有深度应用,以上评价仅供参考。
最后成果(可忽略)
翻译结果:
fores3的文件内容:
段落 1 原|文:
尔时,世尊告诸比丘:“当观色无常。如是观者,则为正观。正观者,则生厌离;厌离者,喜贪尽;喜贪尽者,说心解脱。段落 1 译文:
当时,佛陀对比丘们说:“你们应当观察身体(色)是无常的。如果这样去观察,就是正确的观法。通过正确的观法,就会产生厌离心;有了厌离心,对身体的贪爱和喜悦就会消失;当贪爱和喜悦都消失了,就可以说是心灵得到了解脱。”========================================
段落 2 原|文:
“如是观受、想、行、识无常。如是观者,则为正观。正观者,则生厌离;厌离者,喜贪尽;喜贪尽者,说心解脱。段落 2 译文:
这样观察感受、想象、行为、意识都是无常的。能够这样观察,就是正确的观察。通过正确的观察,就会产生厌离心;有了厌离心,对世间的喜爱和贪欲就会消失;当喜爱和贪欲都消失了,就可以说心灵得到了解脱。========================================
代码:
# -*- coding: utf-8 -*-
"""
佛经翻译自动化脚本
功能:
1. 使用通义千问API将指定目录中的佛经文本批量翻译为白话文
2. 生成纯译文文件和原文+译文对照文件
3. 自动处理目录创建和文件编码问题
使用方式:
1. 设置环境变量DASHSCOPE_API_KEY
2. 配置输入/输出目录路径
3. 直接运行脚本即可
"""
import os
from openai import OpenAI
# 通过系统环境变量获取 API 密钥
api_key = os.getenv('DASHSCOPE_API_KEY')
if not api_key:
raise ValueError("未找到 DASHSCOPE_API_KEY 环境变量,请设置该环境变量。")
# 设置 openai 的 API 密钥和 base_url
client = OpenAI(
api_key=api_key,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
def split_paragraphs(text):
"""将长文本按空行分割为段落"""
paragraphs = [p.strip() for p in text.split('\n\n') if p.strip()]
return paragraphs
def translate_text(text, max_retries=3):
"""
使用通义千问 API 翻译文本(带重试机制)
:param text: 待翻译文本(单段落)
:param max_retries: 最大重试次数
:return: 成功返回译文,失败返回None
"""
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model="qwen-max",
messages=[
{"role": "system", "content": "你是一个专业的佛经翻译助手,能将佛经内容翻译成白话文,尽量保持其原意和语境。"},
{"role": "user", "content": f"请将以下佛经内容翻译成白话文,尽量保持其原意和语境:{text}"}
]
)
return response.choices[0].message.content
except Exception as e:
print(f"第{attempt+1}次翻译失败: {e}")
if attempt == max_retries - 1:
return None
def translate_files(input_dir, output_dir, combined_dir):
"""
批量处理目录中的佛经文件
:param input_dir: 包含原始佛经文件的输入目录
:param output_dir: 只保存译文的输出目录(自动创建)
:param combined_dir: 保存原文译文对照文件的目录(自动创建)
:note: 支持嵌套目录结构,自动保持原始目录层级
"""
if not os.path.exists(output_dir):
os.makedirs(output_dir)
if not os.path.exists(combined_dir):
os.makedirs(combined_dir)
for root, dirs, files in os.walk(input_dir):
for file in files:
file_path = os.path.join(root, file)
try:
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
except UnicodeDecodeError:
print(f"无法以 UTF-8 编码读取文件: {file_path}")
continue
# 分割段落并翻译
paragraphs = split_paragraphs(text)
translated = []
error_count = 0
# 逐段翻译
for para in paragraphs:
t = translate_text(para)
if t:
translated.append(t)
else:
translated.append(f"[翻译失败段落: {para[:50]}...]")
error_count += 1
# 生成输出内容
output_content = '\n\n'.join(translated)
combined_content = []
# 构建对照内容
for i, (orig, trans) in enumerate(zip(paragraphs, translated)):
combined_content.append(f"段落 {i+1} 原|文:\n{orig}\n\n段落 {i+1} 译文:\n{trans}\n\n{'='*40}\n")
# 输出译文文件
output_file_path = os.path.join(output_dir, file)
with open(output_file_path, 'w', encoding='utf-8') as f:
f.write(output_content)
# 输出对照文件
combined_file_path = os.path.join(combined_dir, file)
with open(combined_file_path, 'w', encoding='utf-8') as f:
f.write(''.join(combined_content))
if error_count > 0:
print(f"警告: {file_path} 中有 {error_count} 个段落翻译失败")
if __name__ == "__main__":
# 配置路径(根据实际需求修改)
input_dir = r"e:\02trae\fores" # 原始佛经存放目录
output_dir = r"e:\02trae\fores2" # 纯译文输出目录
combined_dir = r"e:\02trae\fores3" # 对照文件输出目录
# 启动批量翻译流程
translate_files(input_dir, output_dir, combined_dir)