背景
目前从公众号、新闻媒体上获得的新闻信息,都是经过算法过滤推荐的,很多时候会感到内容的重复性和低质量,因为他们也要考虑到自己的利益,并非完全考虑用户想要的、对用户有价值的信息。这时,如果要获取自己认为重要的信息,定制化开发自己的筛选算法更好。
效果
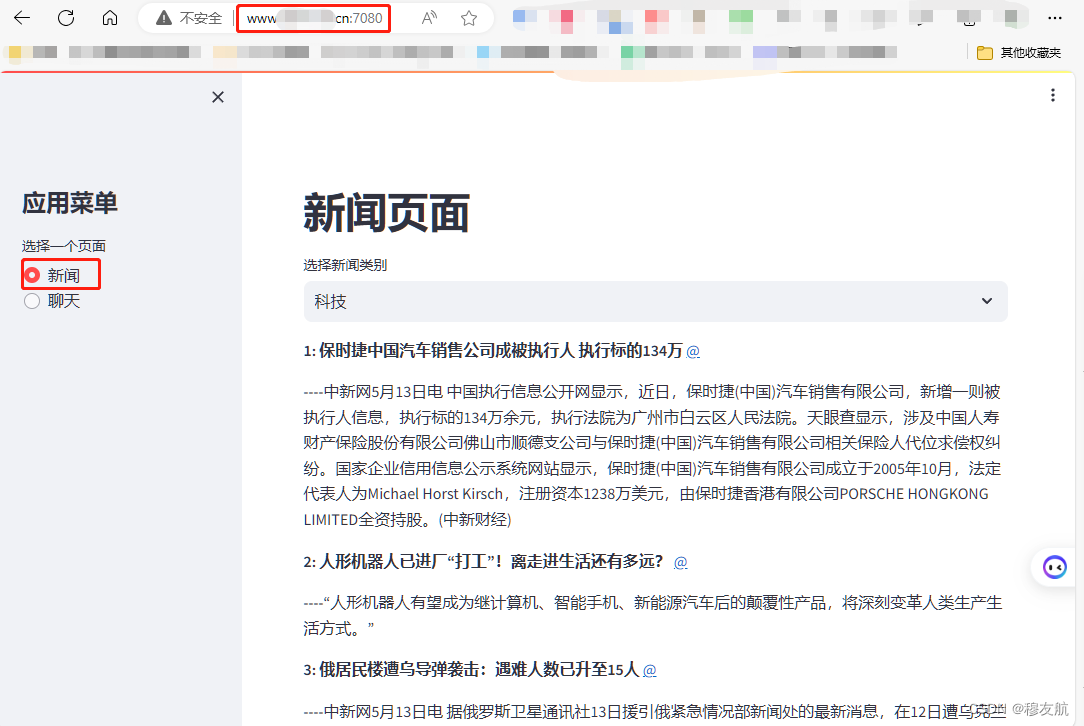
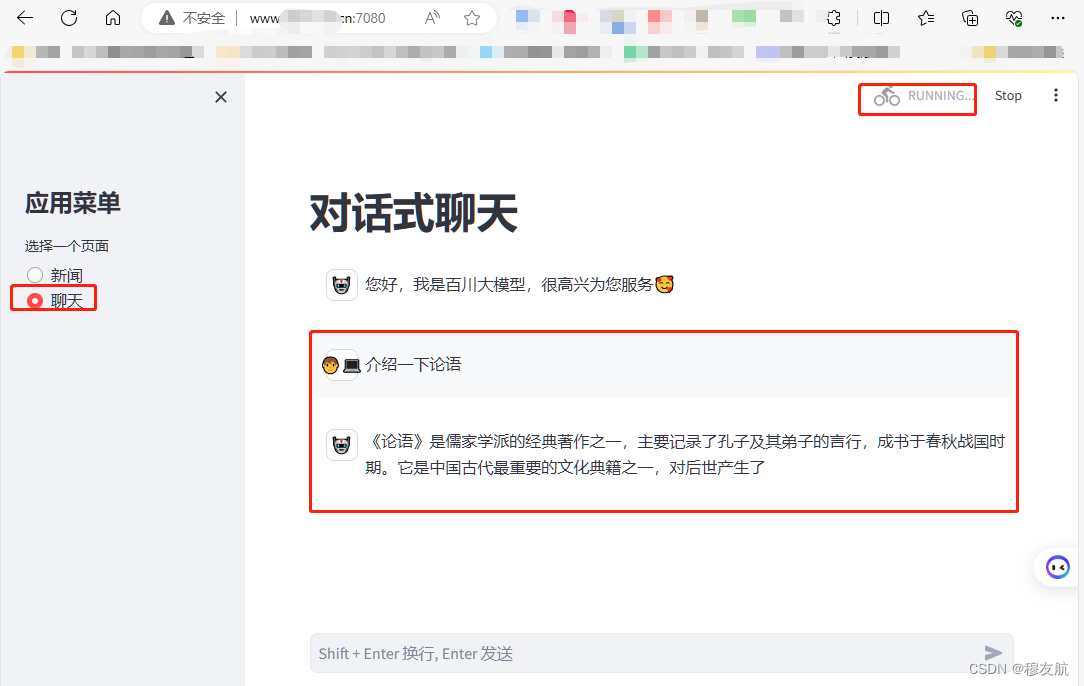
素材
软硬件资源
- GTX 4060 8GB显存,windows10,python3.7。
- frp用于本地机器与远程服务器通信,实现内网端口转发。
- 腾讯云服务器一台+个人域名一个,用于远程访问网页。
LLM大语言模型
本文使用的是Baichuan2,可用huggingface transformers库直接使用,各项评测集指标还不错,示例代码如下,后面会有更详细使用:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation.utils import GenerationConfig
tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan2-13B-Chat", use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-13B-Chat", device_map="auto", torch_dtype=torch.bfloat16, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-7B-Chat", torch_dtype=torch.float16, trust_remote_code=True)
model = model.quantize(4).cuda()
model.generation_config = GenerationConfig.from_pretrained("baichuan-inc/Baichuan2-13B-Chat")
messages = []
messages.append({
"role": "user", "content": "解释一下“温故而知新”"})
response = model.chat(tokenizer, messages)
print(response)
新闻数据获取RSS订阅
RSS订阅源不同,解析脚本不同,这里给出一个关于中国新闻网的订阅示例,
网页版内容如下:

使用feedparser库获取内容,使用BeautifulSoup获取新闻链接中的详细正文内容:
如果python提升ssl验证安全的问题,请记得使用科学上网方法,或者切换为python3.7。
# -*- coding: utf-8 -*-
import requests
import feedparser
from bs4 import BeautifulSoup
def get_new_info( url = "http://www.chinanews.com/gj/2024/04-12/10197213.shtml"):
# 发送 HTTP 请求并获取网页内容
response = requests.get(url)
print(response)
response.encoding = response.apparent_encoding
# response.encoding = "utf-8"
# 检查请求是否成功
if response.status_code == 200:
# 获取网页源代码
html_content = response.text
else:
print("Error:", response.status_code)
soup = BeautifulSoup(html_content, 'html.parser')
left_zw = soup.find_all(name='div',attrs={
"class":"left_zw"})
paragraphs_list = list(left_zw)
# print(paragraphs_list[0])
news=''
for p in paragraphs_list:
# print(p.get_text())
news+=p.get_text().strip()
return news
rss_url_follow=[
"https://www.chinanews.com.cn/rss/importnews.xml", # 要闻导读
"https://www.chinanews.com.cn/rss/world.xml", # 国际新闻
"https://www.chinanews.com.cn/rss/finance.xml",
"https://www.chinanews.com.cn/rss/china.xml",
]
fout=open('news.txt','w')
for rss_url in rss_url_follow:
feed = feedparser.parse(rss_url)
print(feed)
for entry in feed.entries:
print("url=%s=title=%s=summary=%s"%(entry.link,entry.title,entry.summary))
# break
# new = get_new_info(entry.link)
temp = "url=%s=title=%s=summary=%s"%(entry.link,entry.title,entry.summary)
fout.write("%s\n\n"%(temp))
fout.close()
基于LLM大语言模型的新闻数据类别分类
通过