
作者:WongSSH
引言
本系列文章将带领读者从零实现 Uniswap V3 核心功能,深入解析其设计与实现。 主要参考了 Constructor | Uniswap V3 Core Contract Explained 系列教程、 Uniswap V3 Development Book 和 Paco 博客中的相关内容。所有示例代码可在 clamm 代码库中找到,以便实践和探索。
BitMap
在上文内,我们介绍如何 swap 的基础原理,但我们没办法寻找到下一个区间。在本文内,我们将引入 BitMap 来进行流动性区间的搜索。一种朴素的搜索流动性区间的方案是遍历每一个 tick 来查询是否存在流动性。但我们的 tick 区间为 [−887272,887272],这是一个相当大的区间,即是小范围的检索也需要消耗大量 gas。所以,我们引入了 tickSpacing 参数来进行跳跃的 tick 检索。
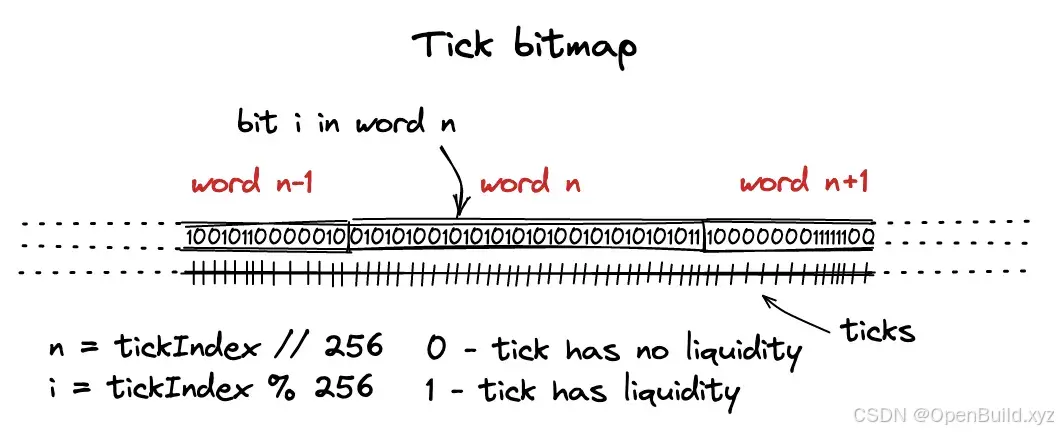
接下来,我们只需要将 [−887272,887272] 范围内的所有 tick 填充到一个位图内即可。如果将总计 1774545 个 tick 填充到位图内部,我们需要 1774545 bit 的长度。显然,solidity 原生无法一次存储如此大的空间。所以,我们使用了映射进行存储:
mapping(int24 => Tick.Info) public ticks;
mapping(int16 => uint256) public tickBitmap;我们将 int24 的 tick 分割为 int16 + uint8 ,其中 int16 被称为 word position,该参数也用作 tickBitmap 的键,而后 uint8 被称为 bit position,该参数被用作 tickBitmap 的值。我们可以认为 tickBitmap 就是一个如下的长位图:
对于 tick 的 int24 分割,我们可以使用以下代码处理(该代码位于 clamm/src/libraries/
TickBitmap.sol 内部):
function position(int24 tick) private pure returns (int16 wordPos, uint8 bitPos) {
wordPos = int16(tick >> 8);
bitPos = uint8(uint24(tick % 256));
}我们使用位移获得前 8 bit 作为 wordPos ,使用模除获得后 8 bit 作为 bitPos。接下来,我们讨论在已知 ticks 的情况下,如何将其存储到 tickBitmap 内部。
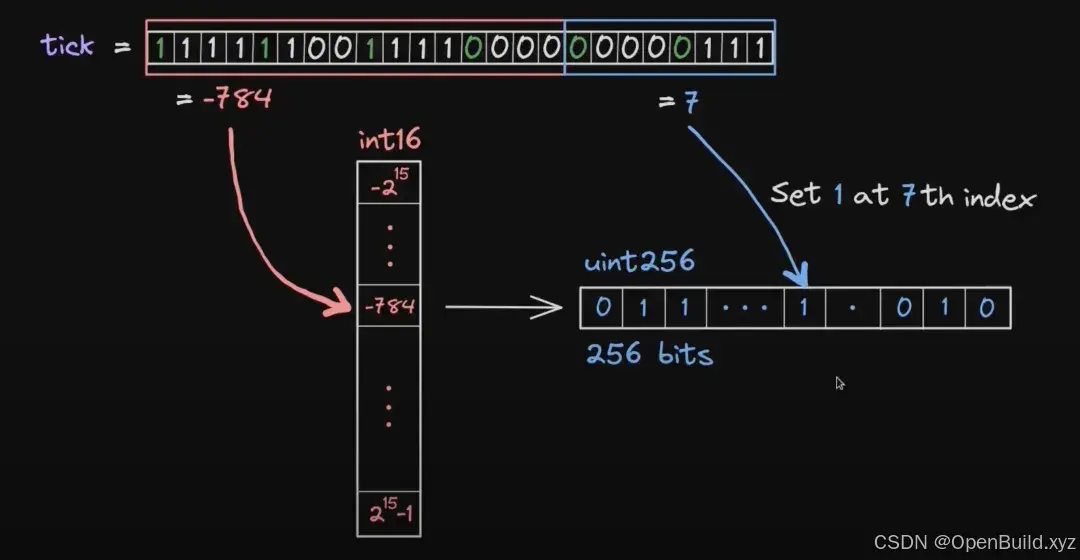
我们首先将一个 tick 划分为 int16 + uint8 ,其中 int16 部分作为 tickBitmap 的键,而 uint8 部分则转化为指定位置的位元写入 tickBitmap 的uint256 值内部。由于 uint8 最大数值为 255 ,所以 uint256 是有足够空间储存的。在具体的写入流程内,我们会使用 mask 掩码方案进行写入。
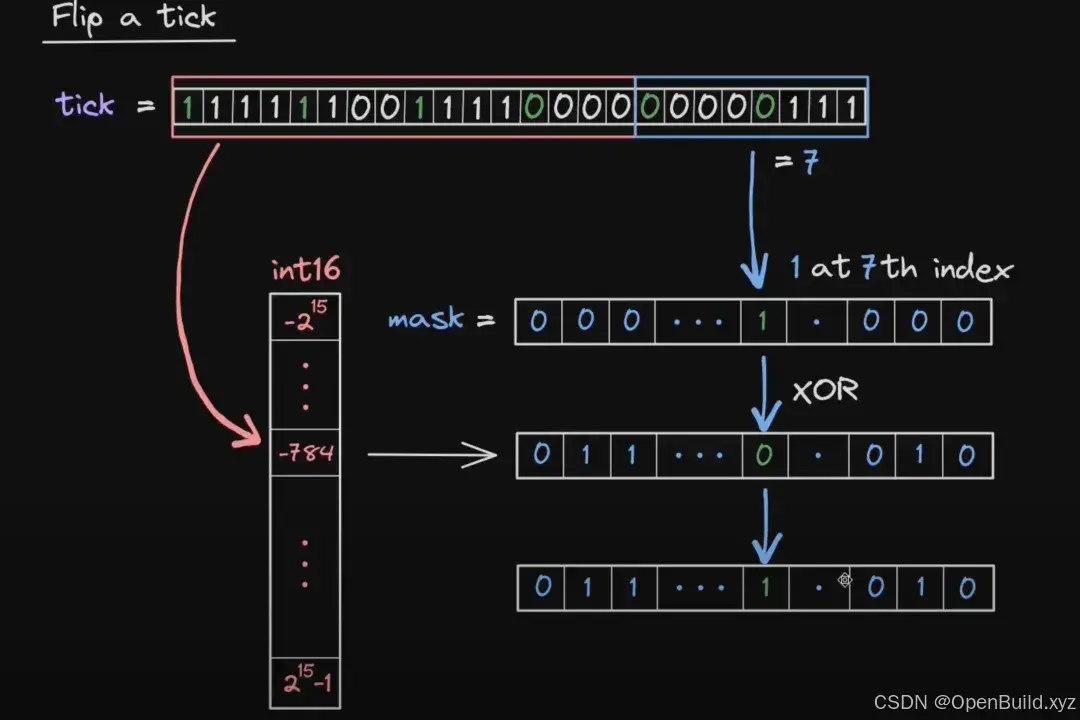
而读取数据的过程就是上述写入流程的逆过程,较为简单。
存储部分可以使用以下代码实现。但需要注意,存储需要考虑 tickSpacing 的影响。我们会将当前的 tick 放缩到 tickSpacing 内部成立的 tick。
function flipTick(
mapping(int16 => uint256) storage self,
int24 tick,
int24 tickSpacing
) internal {
require(tick % tickSpacing == 0);
(int16 wordPos, uint8 bitPos) = position(tick / tickSpacing);
uint256 mask = 1 << bitPos;
self[wordPos] ^= mask;
}介绍完 bitmap 内的读取和写入后,我们希望进一步探索如何寻找下一个被初始化的 tick。这个问题等同于寻找离当前 tick 对应的 Index 左侧或则右侧的非零位元。
我们先介绍如何寻找小于当前 tick 的 nextTick,等同于寻找当前 tick 的右侧位元。此过程可以使用下图展示:
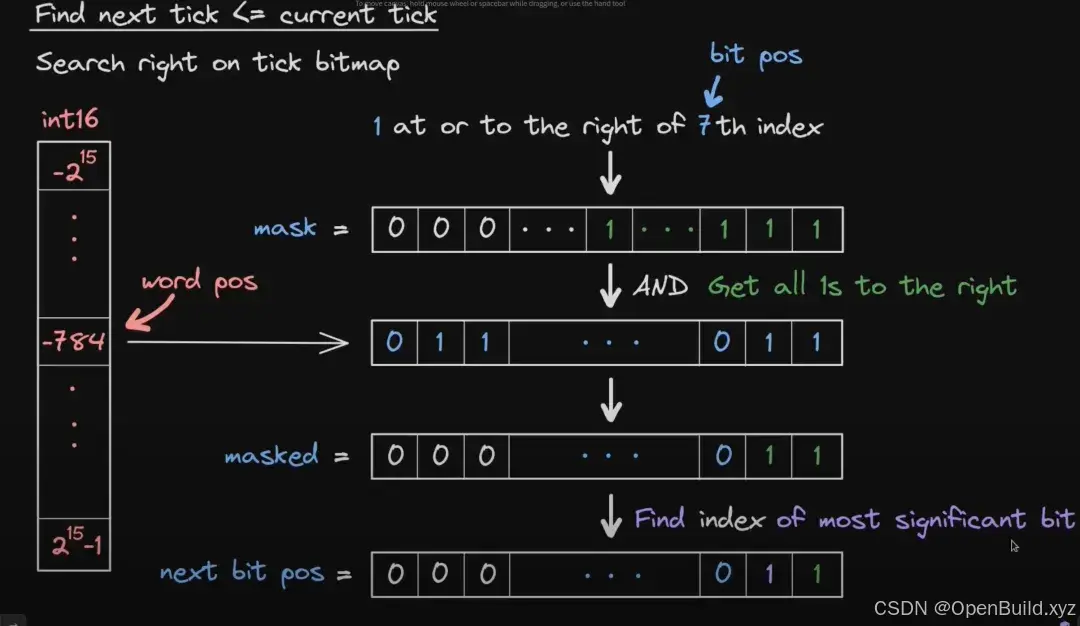
此处的 Find index of most significant bit 就是搜索当前位图内部最大的位元,该位元也是离当前 tick 最近的右侧位元。在代码内,该函数被命名为 mostSignificantBit 。具体实现上,一般使用二分法快速获得当前位图内最大的位元。在此处 next bit pos 等于当前位元距离零索引的距离。我们会发现由于寻找的是左侧位元,所以即使 masked 内包含当前 tick 依旧不会有任何问题。当我们找到当前位图内最大的位元后,我们使用以下算法计算新的的 tick 的位置:
next tick = tick - bit pos + next bit pos上述描述可以使用以下代码表示:
function nextInitializedTickWithinOneWord(
mapping(int16 => uint256) storageself,
int24 tick,
int24 tickSpacing,
bool lte
) internal view returns (int24 next, bool initialized) {
int24 compressed = tick / tickSpacing;
if (tick < 0 && tick % tickSpacing != 0) compressed--;
if (lte) {
(int16 wordPos, uint8 bitPos) = position(compressed);
uint256 mask = (1 << bitPos) - 1 + (1 << bitPos);
uint256 masked = self[wordPos] & mask;
initialized = masked != 0;
next = initialized
? (compressed - int24(uint24(bitPos - BitMath.mostSignificantBit(masked)))) * tickSpacing
: (compressed - int24(uint24(bitPos))) * tickSpacing;
} else {}
}此处的 lte 分支内的代码就是上述介绍的寻找当前 tick 左侧的 tick 的代码。这里需要注意,由于我们使用了基于 tickSpacing 压缩的 tick 索引,所以在函数最开始就需要计算压缩后的 tick 索引 compressed 。这里还需要注意我们都是选择向下取整来压缩 tick。但是对于负数而言,使用除法会出现向上取整的情况,所以此处使用了 if (tick < 0 && tick % tickSpacing != 0) compressed--; 来避免除法的向上取整。
为什么此处要保持向下取整,是因为对于 [-1, 1] 的区间而言,如果我们不保持向零取整,那么就会导致两侧的重叠。
此处,为了构造当前 tick 右侧均为 1 的的掩码,我们首先使用 (1 << bitPos) - 1 构造除了当前 tick 以外右侧均为 1 的掩码,然后使用 + (1 << bitPos) 的方法将当前 tick 也置为 1。所以上述代码是可以检索到当前 tick 自身的。关于为什么允许该函数返回当前 tick,读者可以在后文知晓原因。
然后,将 mask 与存储内的位图做 and 操作即可提取获得 masked 。最后,我们根据当前区间内是否可以找到此 tick 进行返回。假如当前位图内存在,那么就使用 next tick = tick - bit pos + next bit pos 方法计算, 即 (compressed - int24(bitPos - BitMath.
mostSignificantBit(masked))) * tickSpacing。而假如当前位图不存在,那么使用 (compressed - int24(bitPos)) * tickSpacing ,此方法等同于直接直接返回当前位图最左侧的索引以方便下一步检索。
接下来,我们分析如果寻找比当前 tick 更大的下一个被初始化的 tick,流程图如下图:
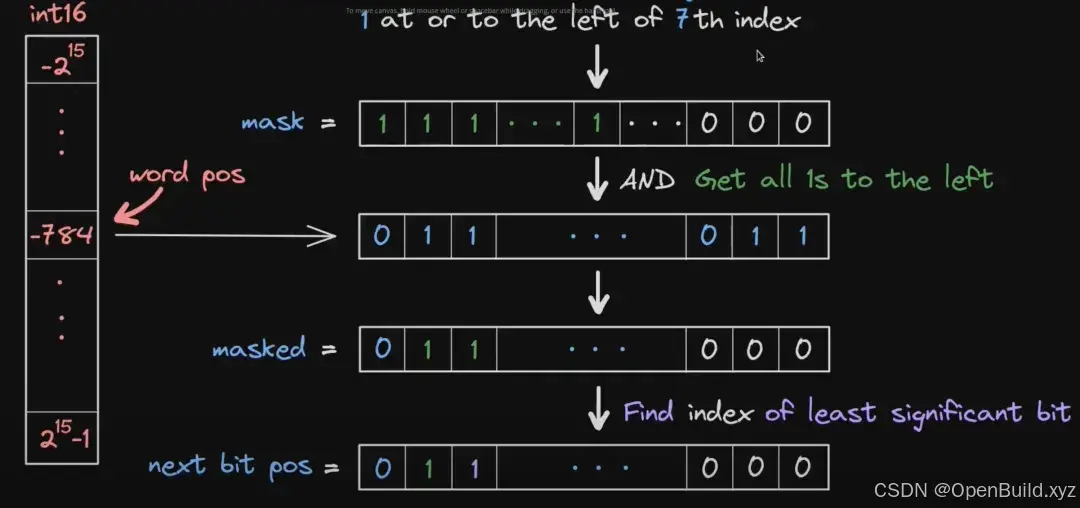
此处的 Find index of least significant bit 是寻找当前位图内最小的位元,该位元也是当前 tick 最近的左侧位元。注意,此处我们会发现由于寻找的 masked 内最小的位元,所以我们不能在最终产生的 masked 内包含当前 tick。具体来说在生成 mask 时,我们就需要去掉当前 tick。所以我们可以使用以下算法计算距离当前 tick 最新的左侧 tick 的位置,此处的 bit pos 实际上是 tick + 1 的 bit pos:
next tick = (tick + 1) - bit pos(tick + 1) + next bit pos此部分代码需要在 nextInitializedTickWithinOneWord 的 else 分支内进行实现。具体代码如下:
(int16 wordPos, uint8 bitPos) = position(compressed + 1);
uint256 mask = ~((1 << bitPos) - 1);
uint256 masked = self[wordPos] & mask;
initialized = masked != 0;
next = initialized
? (compressed + 1 + int24(uint24(BitMath.leastSignificantBit(masked) - bitPos))) * tickSpacing
: (compressed + 1 + int24(uint24(type(uint8).max - bitPos))) * tickSpacing;此处我们先获得了 position(compressed + 1) 的位置。正如上文所述,在求解距离当前 tick 最近的右侧 tick 时,我们需要排除掉当前 tick 的影响,所以此处使用了 position(compressed + 1) 进行相关计算。最后求解 next 时也使用了 compressed + 1 。假如没有在当前区间找到合适的 tick,那么会将 next 置为当前 word 的最大值。
我们已经完成了 TickBitmap 库的构建,我们将其导入到主合约内进行一些其他工作。在 _updatePosition函数内,我们之前定义了 flippedLower 和 flippedUpper 用来表示 tick 是否会被翻转。但我们之前并没有完成此工作。在上文内,我们已经构造了 flipTick 函数,我们可以直接在此处使用:
if (flippedLower) {
tickBitmap.flipTick(tickLower, tickSpacing);
}
if (flippedUpper) {
tickBitmap.flipTick(tickUpper, tickSpacing);
}上述代码还有一个特殊作用,由于我们在 flipTick 内进行了 tickSpacing 的校验,所以此处当用户不按照 tickSpacing 添加流动性时会出现报错。
在上文介绍 swap 时,我们并没有完成 tickNext 的真正检索。由于我们此处已经实现了 nextInitializedTickWithinOneWord 函数,所以此处也可以引入真实函数进行操作。在 swap 函数内部,我们可以增加以下代码:
(step.tickNext, step.initialized) =
tickBitmap.nextInitializedTickWithinOneWord(state.tick, tickSpacing, zeroForOne);此处最为麻烦的就是 nextInitializedTickWithinOneWord 中的 lte 参数,当该参数为 true时,意味着向左寻找 tick,即向较小价格搜索。而在上文内,我们已经推导过 zeroForOne 实际上就是向较小价格移动,所以此处我们直接将 zeroForOne 置为 lte 参数。
这里涉及一个非常有意思的问题,在循环内,每次调用 nextInitializedTickWithinOneWord 都会进行搜索,而且如果当前调用没有获得合适的 tick,那么下一次调用会进入下一个 word 进行检索。在具体机制实现内,对于 lte = true 的情况,我们会在核心的循环最后,使用了 step.tickNext - 1直接将 step.tickNext 向下移动,手动进入下一个 word 进行搜索。
而当 lte = false 时,假如第一次没有搜索到合适的 tick,那么 step.tickNext 会被置为当前 word 的最大值,当第二次调用此函数时,我们可以看到 (int16 wordPos, uint8 bitPos) = position(compressed + 1); 代码,直接将当前 tick 通过加 1 的方法推入了下一个 word 区间。