R1-Searcher,这是一种使用 RL 增强 LLM 的 RAG 能力的新框架,通过两阶段强化学习(RL)实现LLM在推理过程中自主调用外部检索系统,突破模型固有知识限制。
为了通过探索外部检索环境来激励大语言模型的搜索能力,设计了一种基于结果的两阶段强化学习方法,通过定制的奖励设计,使模型能够在推理过程中自由探索如何调用外部检索系统以获取相关知识。具体来说,在第一阶段,我们采用检索奖励来激励模型进行检索操作,而不考虑最终答案的准确性。这样,大语言模型可以快速学习正确的检索调用格式。在第二阶段,我们进一步引入答案奖励,以鼓励模型学习有效地利用外部检索系统正确解决问题。我们的方法仅依赖于基于结果的强化学习,使模型能够通过探索和学习自主学习,而无需任何知识蒸馏或使用有监督微调(SFT)进行冷启动。为了支持大语言模型与外部检索环境在训练过程中的探索,我们进一步提出了一种基于 Reinforce++的改进强化学习训练方法,该方法具有基于检索增强生成的展开和基于检索掩码的损失计算。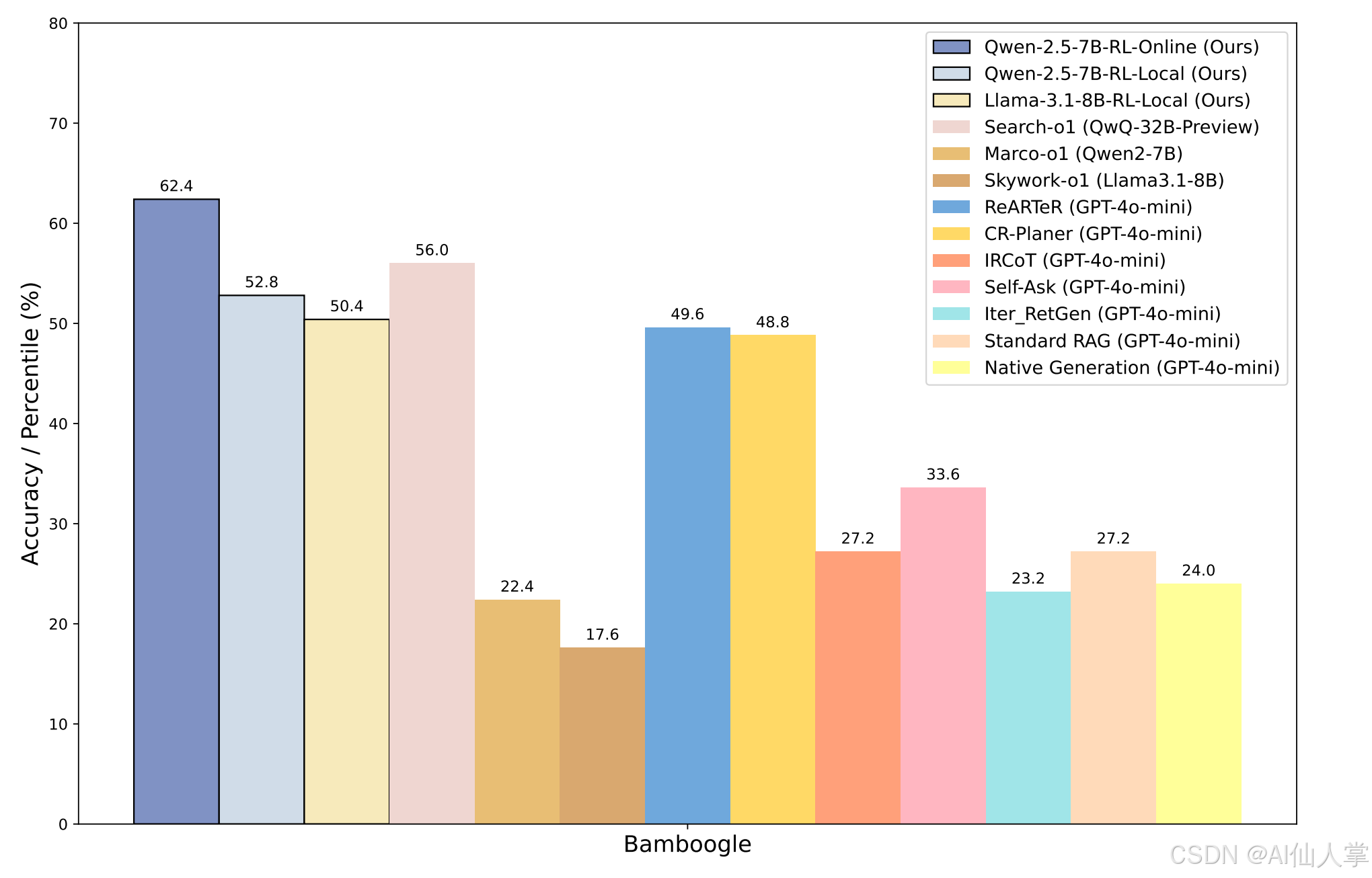
方法框架

1两阶段强化学习设计
- 第一阶段(检索激励):
- 目标:训练模型主动发起检索请求。
- 奖励机制:检索奖励(+0.5/次) + 格式奖励(0.5)。
R r e t r i e v a l = { 0.5 , if n ≥ 1 0 , if n = 0 R_{retrieval} = \begin{cases} 0.5, & \text{if } n \geq 1 \\ 0, & \text{if } n = 0 \end{cases} Rretrieval={ 0.5,0,if n≥1if n=0其中, n n n 表示检索调用的次数。 - 不关注答案准确性。
1.模型的思考过程和最终答案应分别放在…和…标签内。此外,…标签内只允许有最终的简短答案。
2.生成的输出必须没有任何乱码或不可读的内容。
3.在进行检索时,模型应提出一个查询,并将查询封装<begin_of_query>…</end_of_query > 标签中。此外,模型在不进行检索的情况下无法直接生成文档。
- 第二阶段(答案优化):
-
目标:整合检索信息提升答案正确率。
-
奖励机制:取消检索奖励,并加入答案奖励,答案F1分数 + 格式奖励(错误格式扣2分),公式如下:
Precision(精确率)和Recall(召回率):
Precision = P N I N , Recall = R N I N \text{Precision} = \frac{PN}{IN}, \quad \text{Recall} = \frac{RN}{IN} Precision=INPN,Recall=INRN
F1分数:
F 1 = 2 × Precision × Recall Precision + Recall F1 = \frac{2 \times \text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}} F1=Precision+Recall2×Precision×Recall
-
2 关键技术细节
-
奖励设计创新:
-
格式奖励:
- 1.模型的思考过程和最终答案应分别放在…和…标签内。此外,…标签内只允许有最终的简短答案。
- 2.生成的输出必须没有任何乱码或不可读的内容。
- 3.在进行检索时,模型应提出一个查询,并将查询封装<begin_of_query>…</end_of_query > 标签中。此外,模型在不进行检索的情况下无法直接生成文档。

-
检索掩码:过滤外部文档对模型推理的干扰。
-
-
训练算法选择:
在推理过程中,模型使用外部检索系统解决问题,并因正确解决方案而获得奖励。通过最大化此奖励来增强模型在推理过程中利用检索的能力。目标是使模型在面临不确定性时能够自主访问外部知识,有效地整合推理和检索。为了无缝整合检索到的文档并确保合理的模型优化,对Reinforce++算法,进行了两项修改:基于 RAG 的展开和基于检索掩码的损失计算:- 基于Reinforce++算法进行修改,采用RAG-based Rollout和检索掩码基于损失计算。
- RAG-based Rollout确保检索在生成过程中无缝集成,检索掩码基于损失计算防止外部标记影响损失计算。
实验结果
1 性能对比
| 数据集 | 最佳基线(ReARTeR) | R1-Searcher提升幅度 |
|---|---|---|
| HotpotQA | 50.6% (CEM) | 48.2% |
| 2Wiki | 53.4% (CEM) | 21.7% |
| Bamboogle | 54.4% (CEM) | 11.4%(在线搜索) |
-
多跳问答任务上的显著性能提升:R1-Searcher在HotpotQA和2WikiMultiHopQA数据集上分别取得了48.2%和21.7%的LLM-as-Judge指标提升,显著优于现有的RAG方法和闭源的GPT-4o-mini。
-
无需冷启动的RL学习:从强大的基模型Qwen-2.5-7B-Base开始进行RL学习,R1-Searcher在大多数域内和域外数据集上取得了更好的结果,甚至超过了闭源的LLM。
-
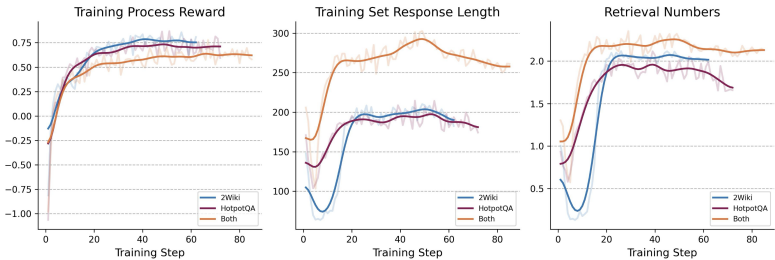
保持泛化能力:R1-Searcher在HotpotQA和2WikiMultiHopQA的8148个训练样本上进行了RL训练,不仅在域内数据集上表现出色,还在域外数据集如Musique和Bamboogle上展示了强大的泛化能力。在线搜索场景下的性能提升了11.4%。
2 关键发现
-
模型泛化:在未训练的Bamboogle数据集(在线搜索场景)仍保持11.4%提升。
-
模型适配性:
- Qwen-2.5-7B-Base模型表现最佳(平均CEM 60.6%)。
- 超越闭源模型GPT-4o-mini。
-
训练方式对比:
- RL训练显著优于监督微调(SFT)(平均CEM提升10.5%)。
-
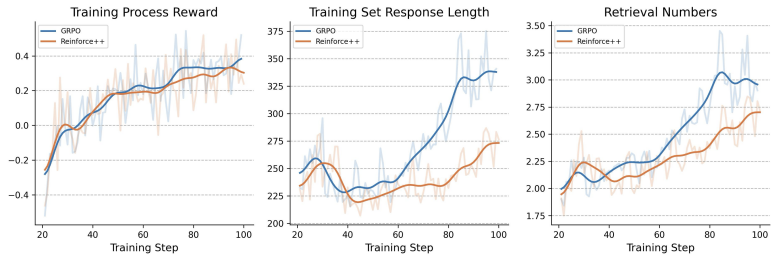
RL算法对比:
- GRPO:生成文本更长、检索更频繁,泛化能力更强(Bamboogle表现优)。
- Reinforce++:在领域内数据集(HotpotQA/2Wiki)上学习效率更高。
-
奖励机制对比:
- F1奖励机制比严格匹配(EM/CEM)更有效(平均提升52.6%)。
通过完全依靠结果监督强化学习,可以仅使用查询-回答对激活模型的内在搜索能力,而不管面对的是基础LLM还是聊天LLM。
最近的强化学习算法,如GRPO和Reinforce++都可以有效地激活LLM的内部搜索能力。
训练期间不要求进行复杂的快速工程或过程监督。
基础LLM的能力在很大程度上影响着模型是否可以直接从零开始训练。
与现有的基于树搜索的方法(如蒙特卡洛树搜索)相比,RL后的Longcot推理是一种更有效、更高效的测试时间缩放方法。
通过使用本地检索进行RL训练,该模型可以很好地推广到其他数据集和在线搜索场景。
代码解读
下面将结合仓库中的核心代码文件和 README.md 的内容,对核心代码进行解读并添加中文注释。
1. R1-Searcher/wiki_corpus_index_bulid/build_corpus_embedding.py
此文件的主要功能是加载语料库并生成其嵌入向量,然后保存到文件中。
import faiss
import pickle
from FlagEmbedding import FlagModel
import os
import argparse
import pickle
import torch
def load_corpus(file_path):
"""
加载语料库文件,将每行文本处理后添加到新的语料库列表中。
:param file_path: 语料库文件路径
:return: 处理后的语料库列表
"""
with open(file_path, 'r', encoding='utf-8') as file:
corpus = file