一 、存储引擎
02. 进阶-存储引擎-MySQL体系结构_哔哩哔哩_bilibili
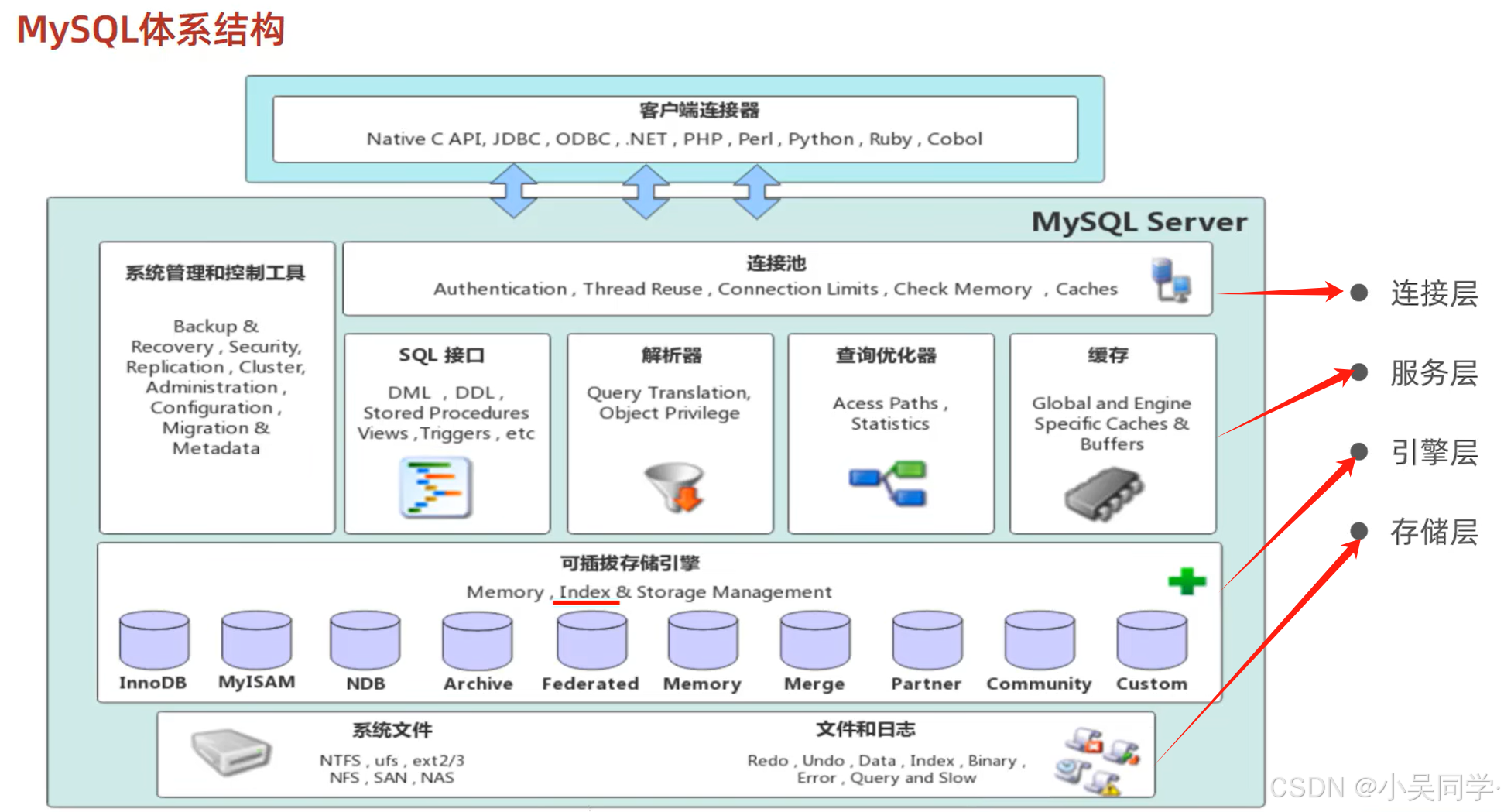
1、MySQL体系结构——连接层、服务层、引擎层、存储层
1>注意:索引是在存储引擎层实现的,意味着不同的存储引擎对应的索引结果不一样
如下图,具体见3、

2>存储层:最后具体的存储都是落在磁盘文件中的

2、存储引擎简介
1>存储引擎 = 表类型
如下图,“存储引擎是基于表的”:每张表可以选择不同的存储引擎

2>存储引擎在建表时若没有指定,默认为InnoDB
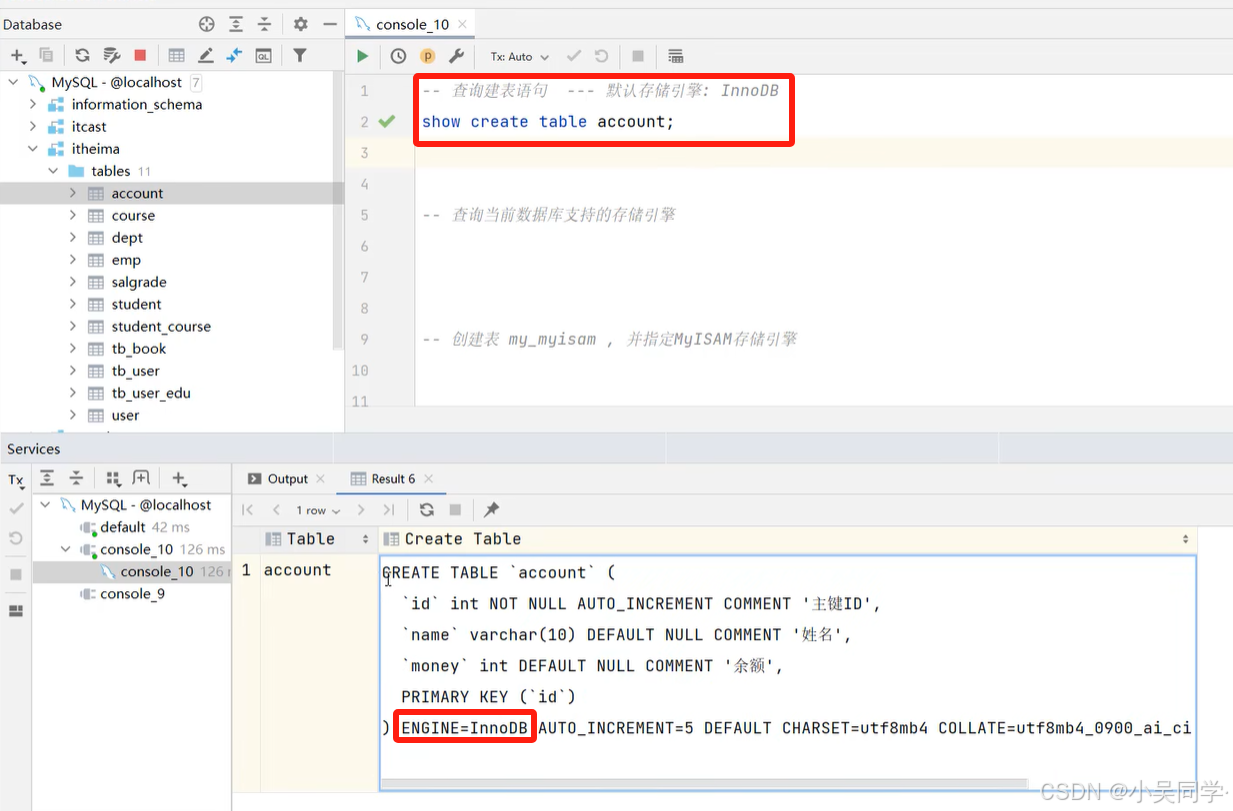
1》如何指定存储引擎?

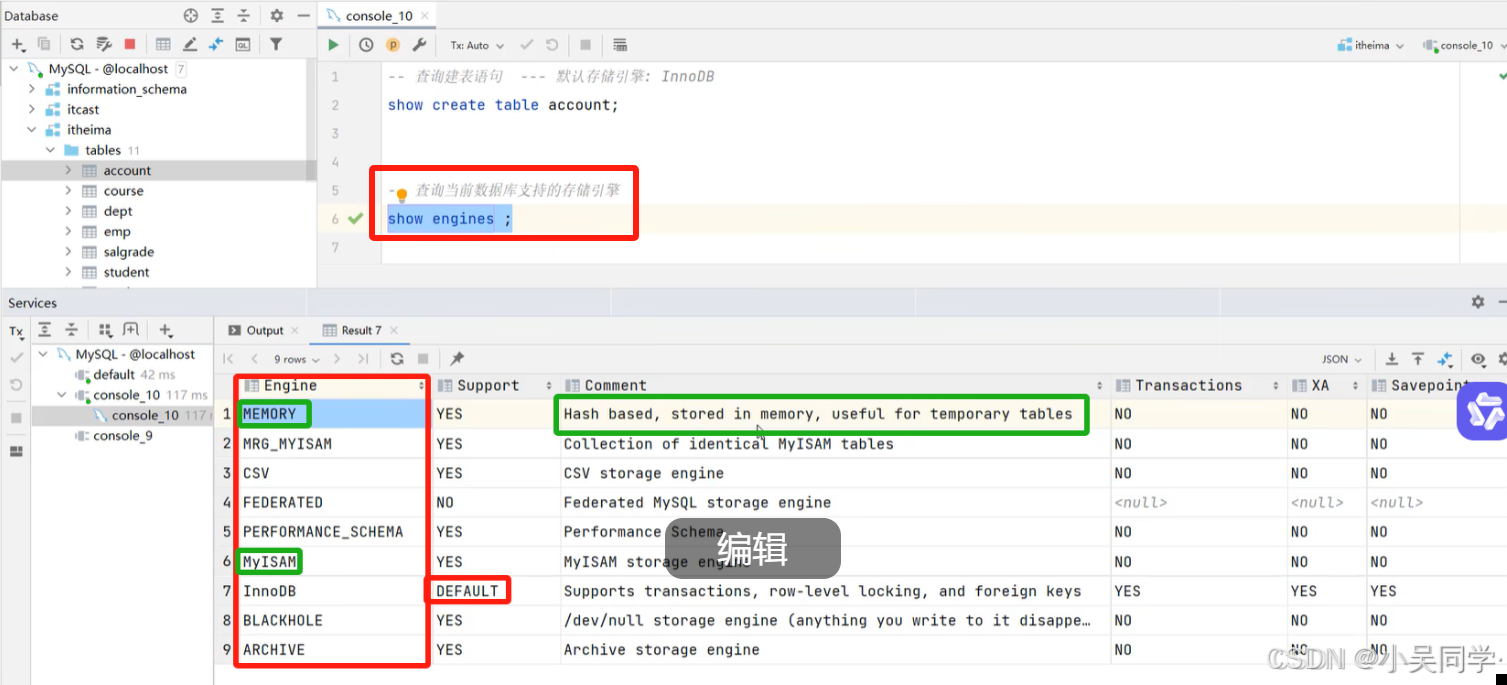
3>各个存储引擎的介绍

在下图中,
MEMORY:是存储在内存中,通常用来做临时表存储
MyISAM:MySQL早期版本默认的存储引擎
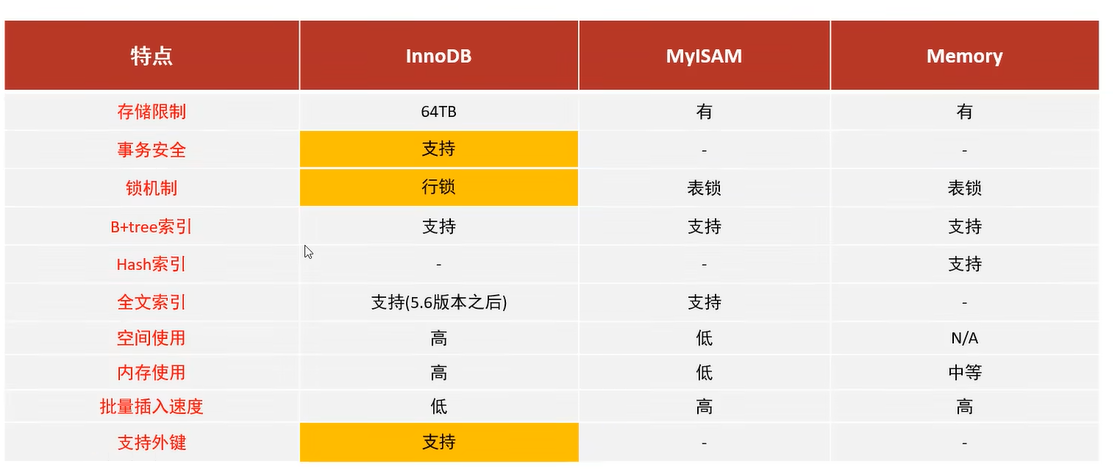
3、各个主要存储引擎特点
1>InnoDB

上图中,
1》DML:对表中数据的增删改
2》ACID模型:事务的四大特性,原子性(A)、一致性(C)、隔离性(I)、持久性(D)。是数据库事务处理的基础,它确保了事务的可靠性与数据的一致性。
3》参数innodb_file_per _table:打开意味着每张表都对应一个表空间文件(.ibd)
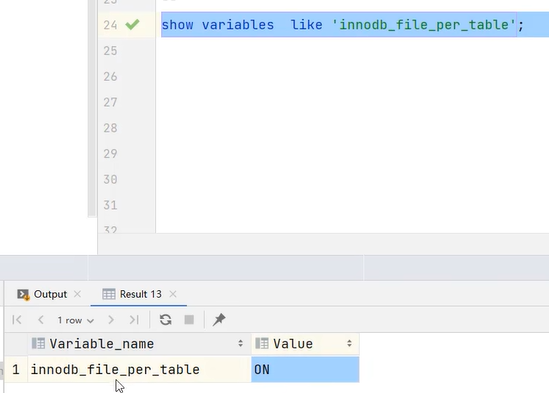
通过上图可以看到innodb_file_per _table = 'ON',所以每张表都对应一个表空间文件。如下图

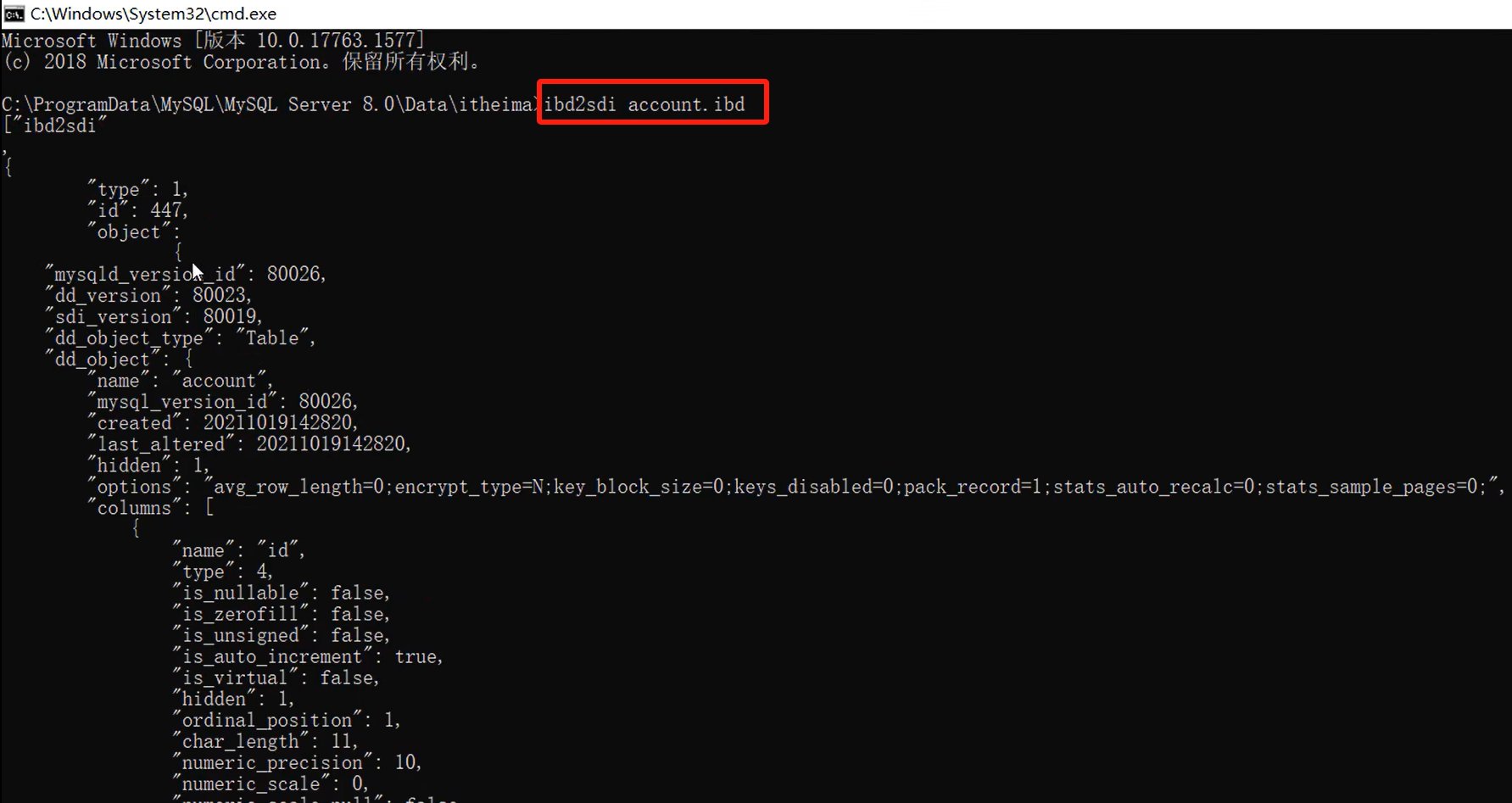
如何查看ibd文件里的内容?——二进制文件,不能直接用记事本打开。需要通过终端命令行打开。
ibd2sdi:从ibd这个文件中提取sdi表结构数据
2>InnoDB逻辑存储结构
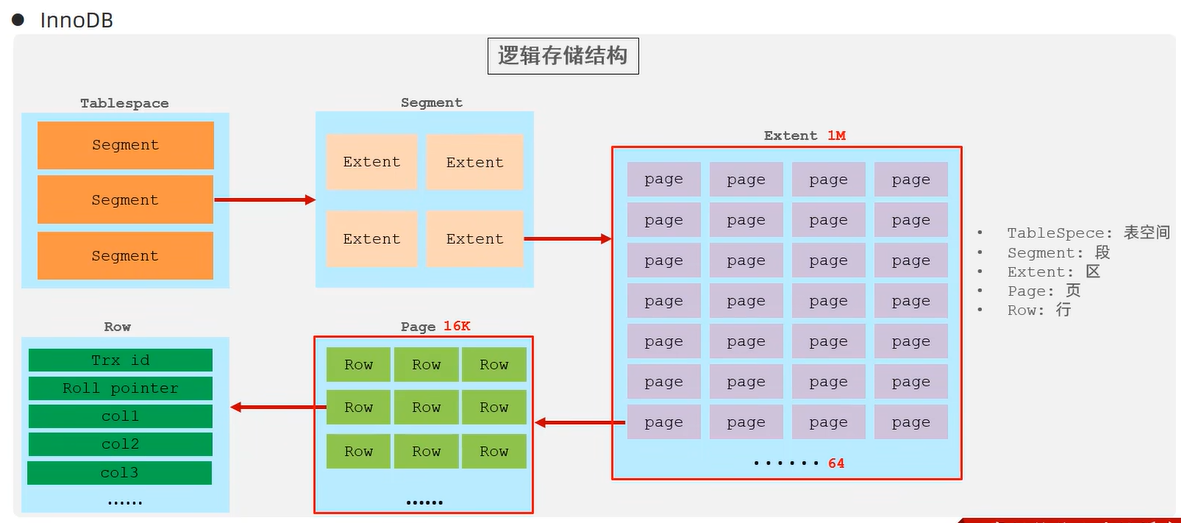
1》InnoDB中,Page(页)是磁盘操作的最小单元,固定大小16K。
Extent(区)的固定大小是1M(= 1024K)。所以一个区里有64(1024K/16K )个页。
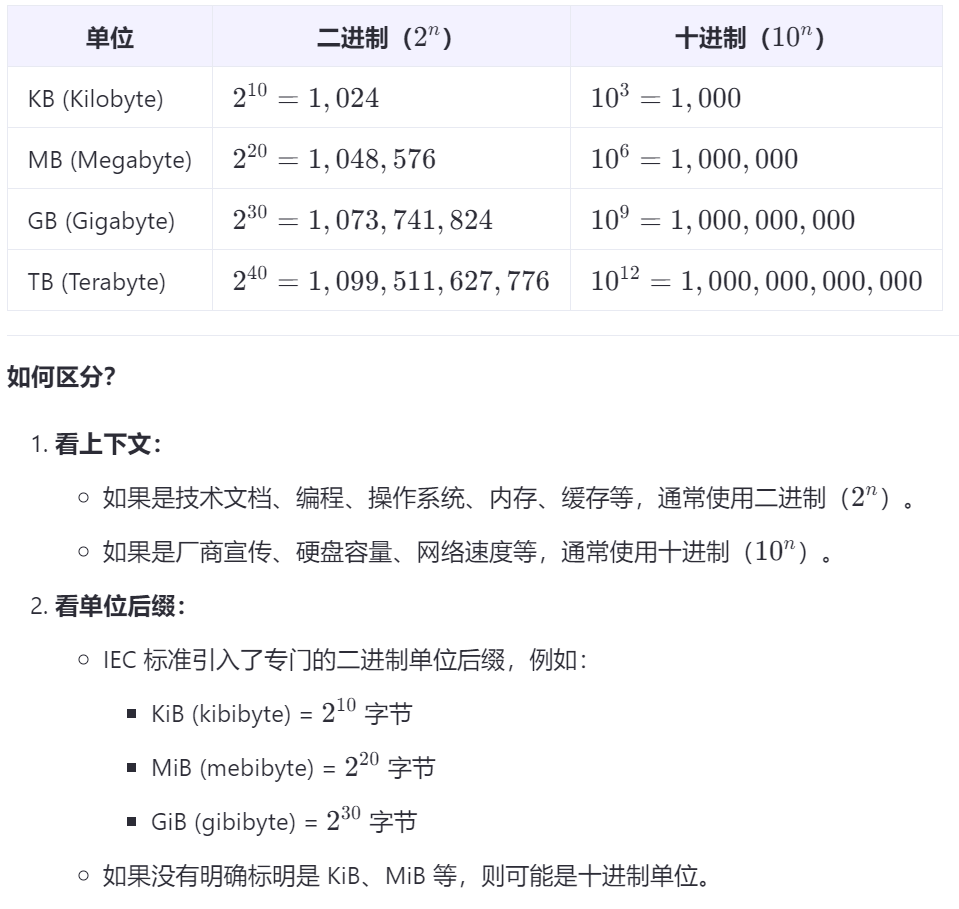
《1》注意:什么时候M的进制是2^10,什么时候是10^3,简要说明
涉及到与计算机内部二进制相关的存储容量(内存大小、磁盘容量、文件系统等)时,进制是2^10。
- 计算机以二进制为基础工作,因此使用基于 2 的幂次方更方便计算和分配资源。
网络带宽、数据传输速率;市场营销中的存储设备容量(如硬盘、U盘、SD卡等)时,进制是10^3。
- 厂商为了简化计算并让数字显得更大,通常会按照十进制来标注容量。
- 消费者更容易理解 1GB=10^9字节,而不是 1GB=2^30 字节。
2》上上图中的Row
Trx id:最后一次操作事务的id
Roll pointer:指针
col1...:各个字段的数据
3》如下图,在表结构中存储的数据,对应上上图的Page。
下图中每一行数据对应上上图的Row。

3>MyISAM:MySQL早期的默认存储引擎

sdi文件可以直接打开,里面的内容是JSON格式,在网站上转换一下格式就行了。如下图
4>Memory:访问速度快(因为它的数据都是存放在内存中的),存临时表

Memory只有sdi文件。因为它的数据都是存放在内存中的。【其它两个引擎的数据都是存放在硬盘中的,在文件夹中显示出来】
- 内存和硬盘的区别?
CPU经常会通过硬盘获取数据,但是CPU和硬盘之间又有一定的距离,而且硬盘的速度比较慢,数据延迟会变得很大。所以需要内存来转运数据。在开机或者打开软件的时候,硬盘会把数据存入内存,等到CPU需要这些的时候,内存与CPU就会开始超快的数据传输,从而减小数据延迟。

下图就是硬盘,硬盘是电脑的仓库,存储着各个文件。
- 硬盘(Hard Disk Drive, HDD):这是一种具体的硬件设备,用于长期存储数据。它由一个或多个快速旋转的磁盘片(也称为“盘片”)和移动读/写头组成,这些盘片涂覆有磁性材料,可以通过改变磁场来记录数据。
- 磁盘(Disk):这个术语更广泛,可以指任何圆形的平面介质,用于存储数据。除了硬盘中的磁盘片外,还包括软盘、光盘(如CD、DVD)、以及固态硬盘(SSD)中的闪存芯片等

4、存储引擎的选择:大部分情况下选择InnoDB
MyISAM:被另一个NoSQL数据库取代了,叫MangoDB
MEMORY:也被另一个NoSQL数据库取代了,叫Redis

二、索引
1、索引概述


2>优缺点

上图中的两个劣势,解释如下
1》索引列也是要占用空间的
索引是一种数据结构,要去维护这个数据结构得先把这个结构存储在磁盘中。使用不同的存储引擎对应的索引结构/文件都不同,如下图。
2》会降低更新表的速度
当对表进行INSERT、UPDATE、DELETE时,会去维护索引结构,删除/增加结点。所以会影响表的更新效率。
2、索引结构(BTree;B+Tree;Hash...)

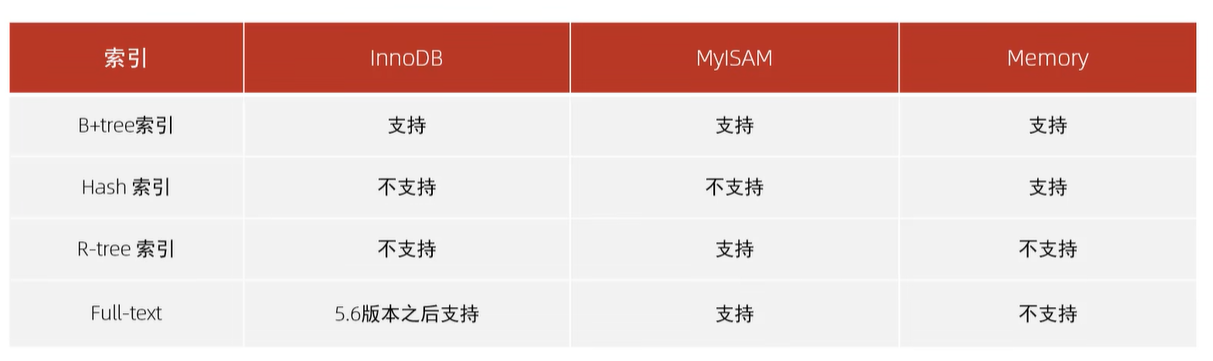
1>BTree
1》二叉树
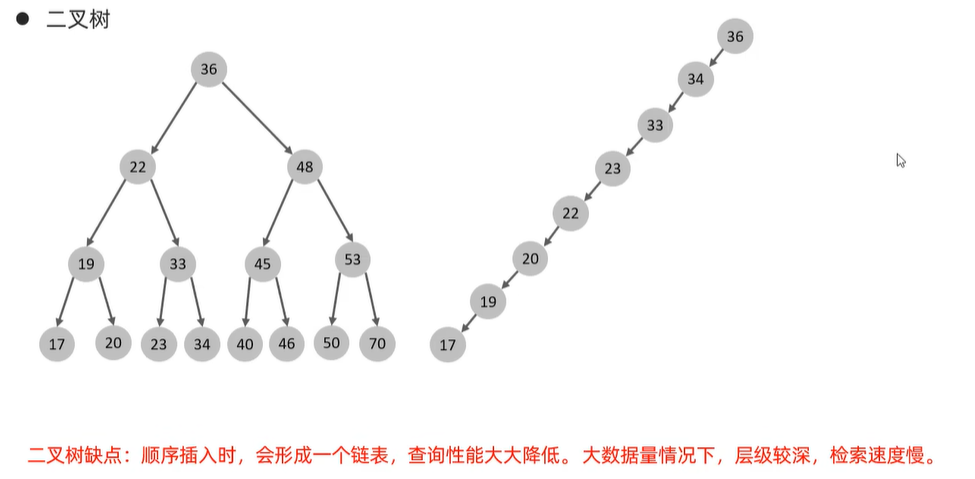
从上图可知,顺序插入时有很明显的缺点,所以引入红黑树
2》红黑树:自平衡的二叉树
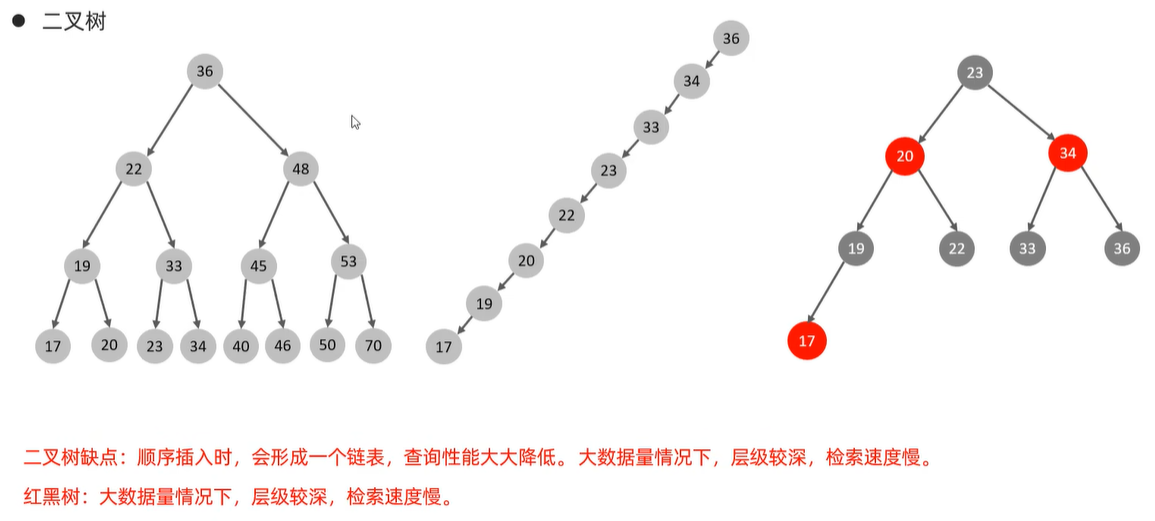
但是红黑树的本质也是二叉树,所以在大数据量时也会有二叉树存在的问题
3》B-Tree(多路平衡查找树)

动态构建出B-Tree的构建过程。视频从下述链接7:30开始(当“第i个插入的数字=度数i”时,树发生裂变:中间元素向上分裂,分出两个子节点)
11. 进阶-索引-结构-Btree_哔哩哔哩_bilibili
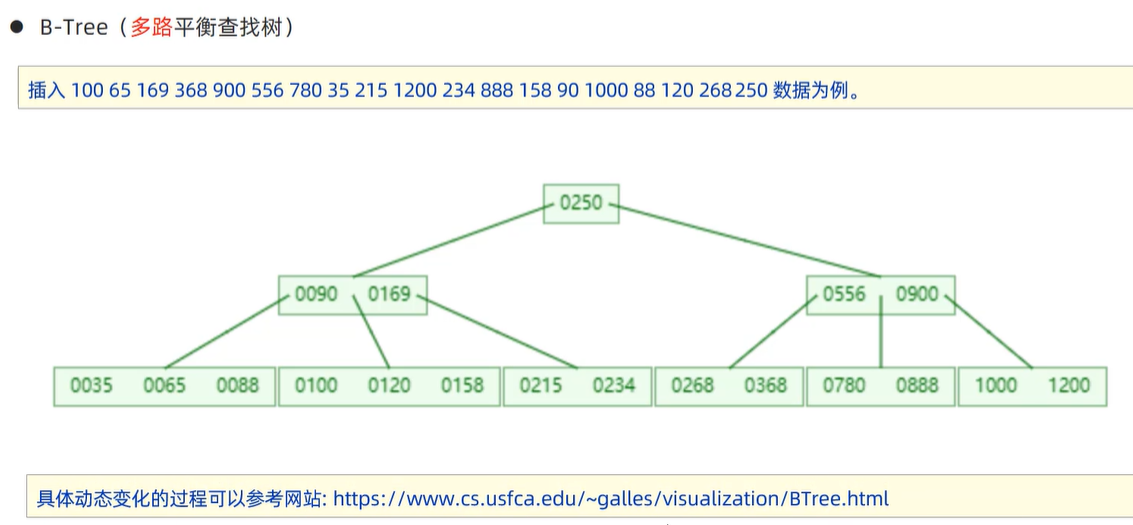
数据结构可视化网站如下:

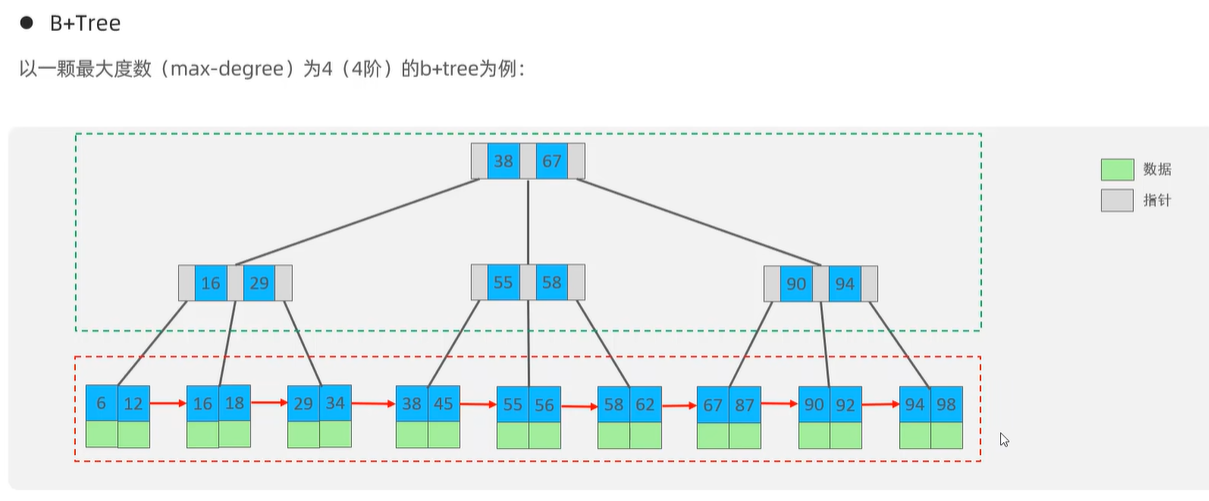
2>B+Tree
1》区别BTree
《1》在B+Tree中,所有元素都会出现在叶子节点上,如下图的红框中。
下图上面绿框:非叶子节点起到索引的作用
下图下面红框:存放数据,所有元素都会出现在叶子节点上
《2》在B+Tree中,所有叶子节点都会形成一个单向链表。每个节点都会通过指针指向下一个元素
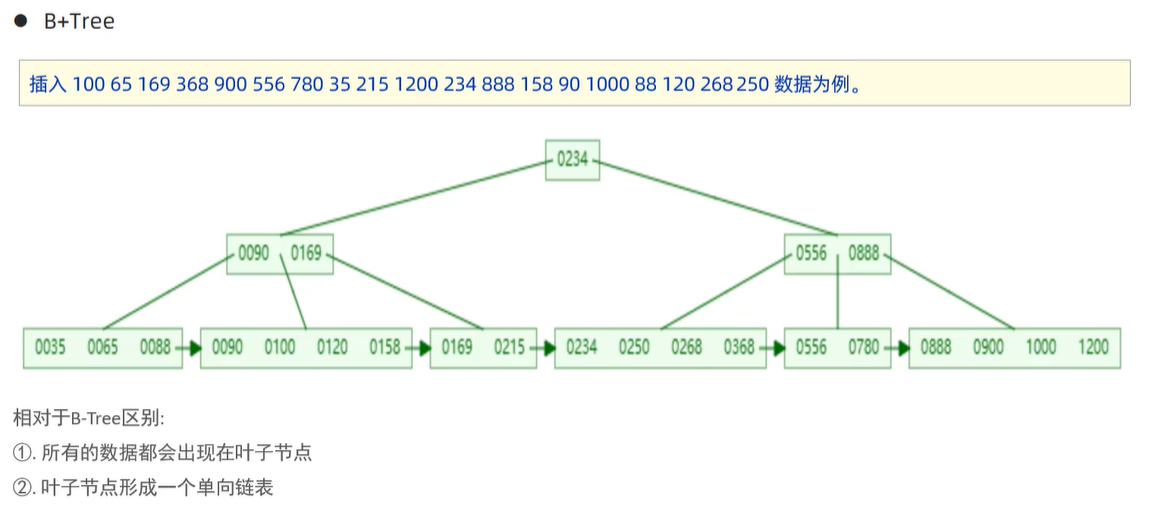
2》动态构建出B+Tree的构建过程
视频从下述链接2:28开始
12. 进阶-索引-结构-B+tree_哔哩哔哩_bilibili
与BTree相同的地方:当“第i个插入的数字=度数i”时,树发生裂变:中间元素向上分裂,分出两个子节点。
不同的是,分裂出去的元素还会落在叶子节点上。并且会有指针把叶子节点连起来,形成链表。
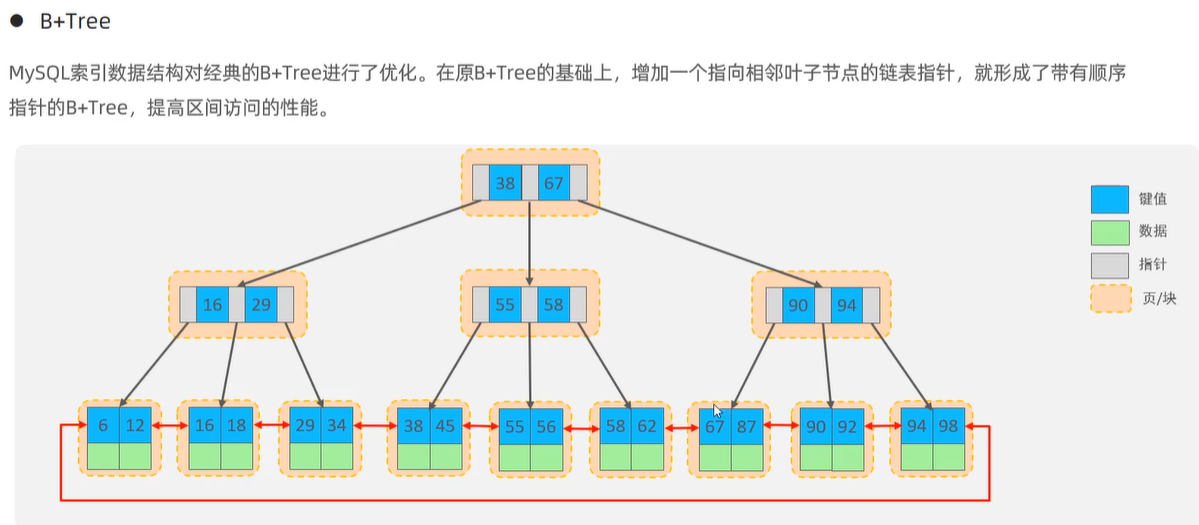
3》MySQL索引数据结构对经典的B+Tree进行了优化
3>Hash
3、索引分类
1>主键索引、唯一索引、常规索引、全文索引

2>在InnoDB存储引擎中,根据索引的存储形式,索引被分为:聚集索引、二级索引

1》聚集索引
《1》上图中的”含义“:叶子节点下面挂的数据,就是那一行的行数据
《2》聚集索引必须有,而且在一个表中只有一个
因为聚集索引决定了表中数据行的物理存储顺序。由于数据行只能按照一种方式物理存储,因此只能有一个聚集索引。
2》二级索引
《1》上图中的”含义“:叶子节点下面挂的数据,是那行数据所对应的主键
《2》”聚集索引必须有,而且在一个表中只有一个“。所以剩下的想要创建的索引都是二级索引。
3》举例
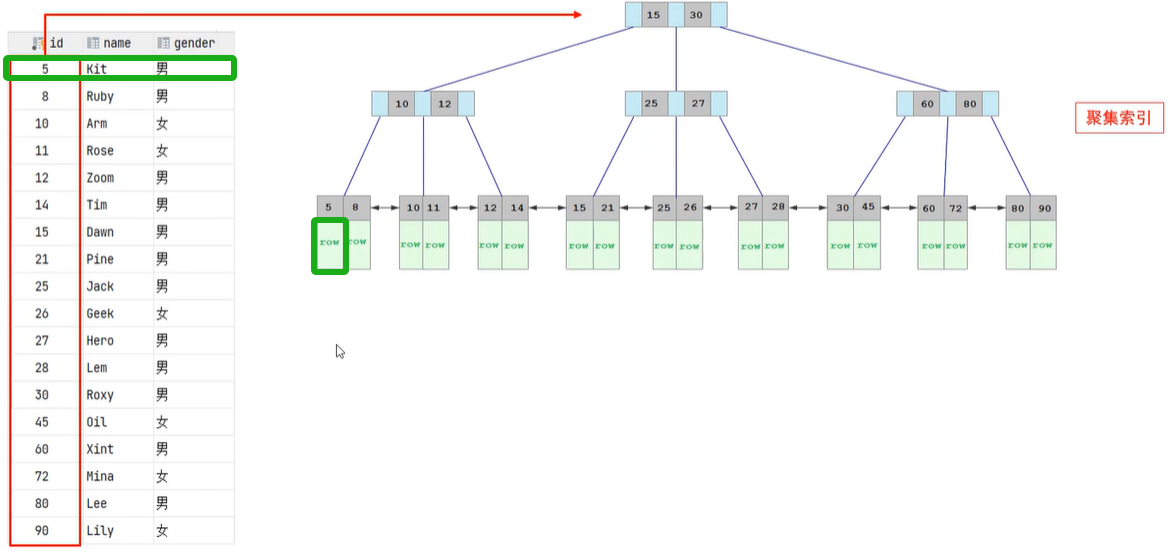
《1》如果存在主键,主键索引就是聚集索引
聚集索引 叶子节点下面挂的数据,就是那一行的行数据
如下图的两个绿框,“5”下面挂的“row”,就是指id为5的那一行数据。
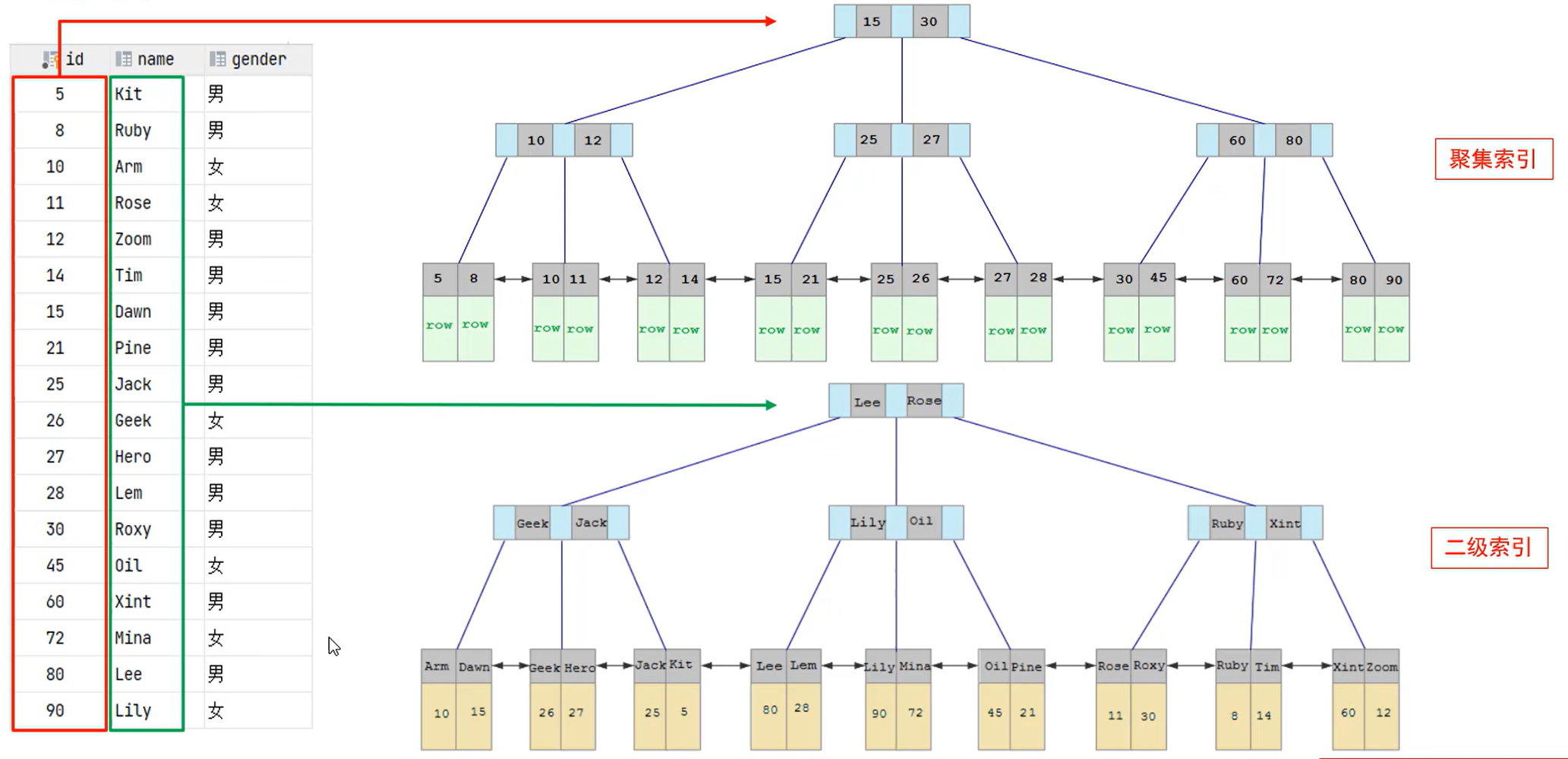
《2》如果想再根据name字段建立索引
由于已经有聚集索引了,那么后面建立的索引都只能是二级索引。
二级索引 叶子节点下面挂的数据,是那行数据所对应的主键
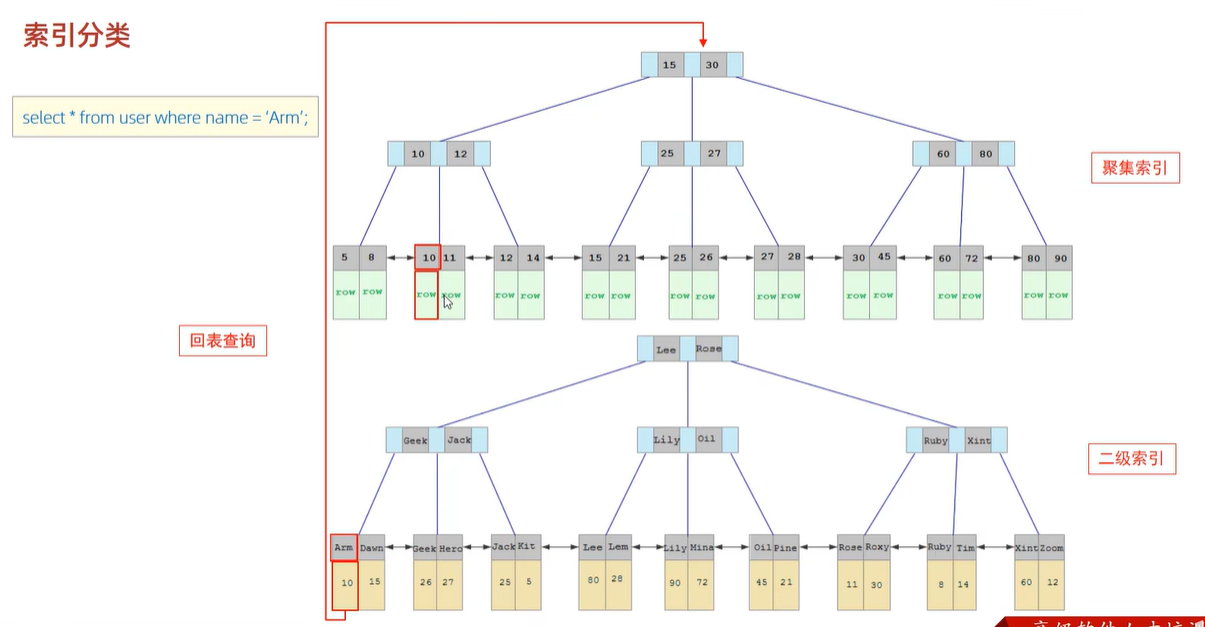
4》在上述两个索引的基础上,执行查询语句
回表查询:先走二级索引拿到对应的主键值,再走聚集索引拿到对应的行数据
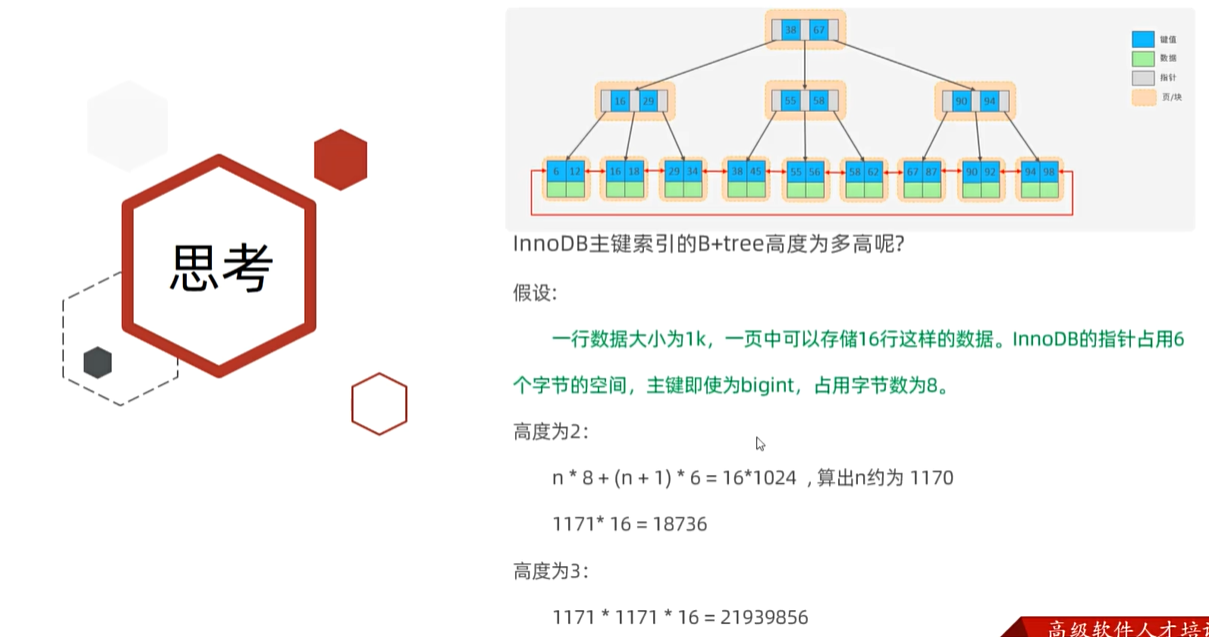
5》思考:InnoDB主键索引的B+tree总共能存储多少数据?
4、索引语法
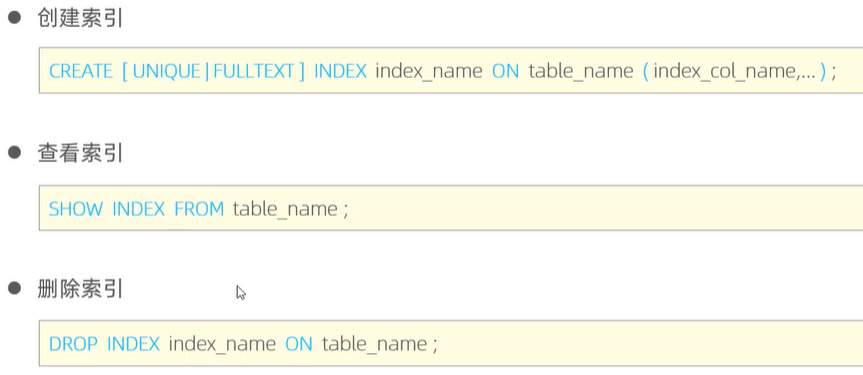
举例:
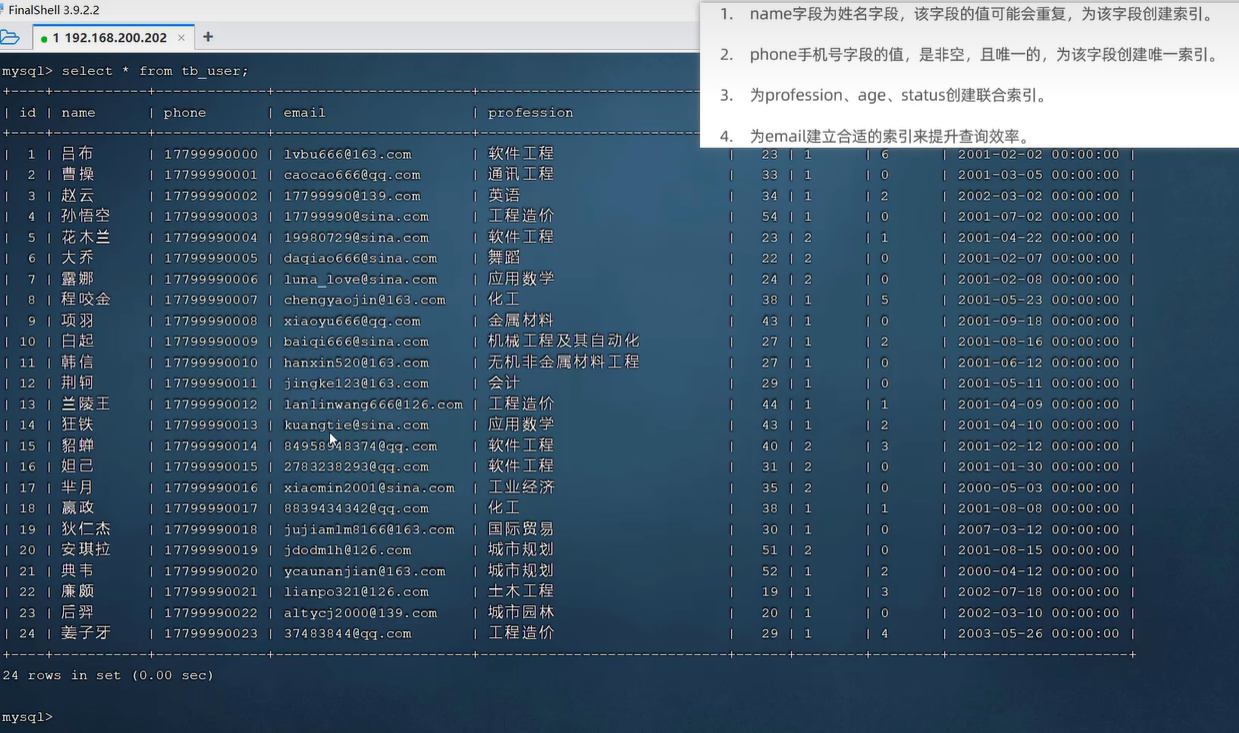
按照上图右上角需求创建索引,如下图

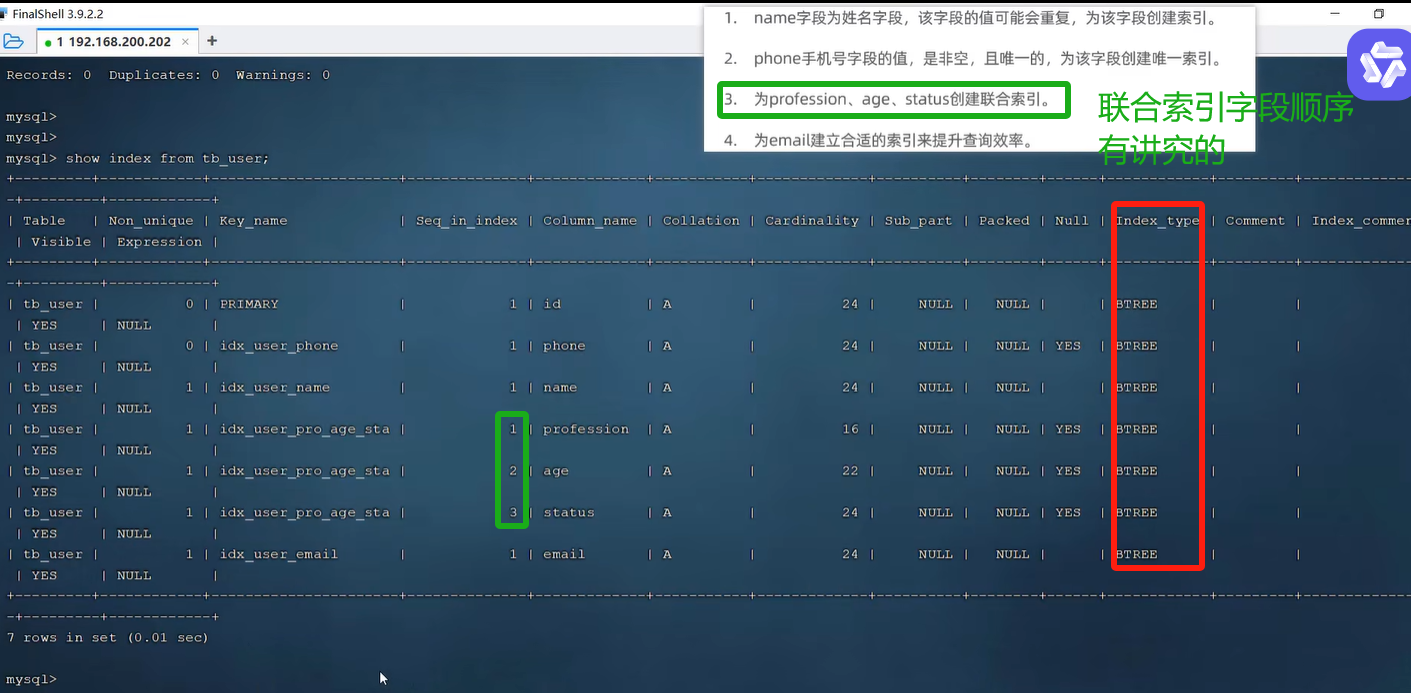
创建完所有索引,在下图中展示出来。因为默认用的是InnoDB存储引擎,所以索引类型都是BTree(B+Tree是BTree的升级)
5、SOL性能分析
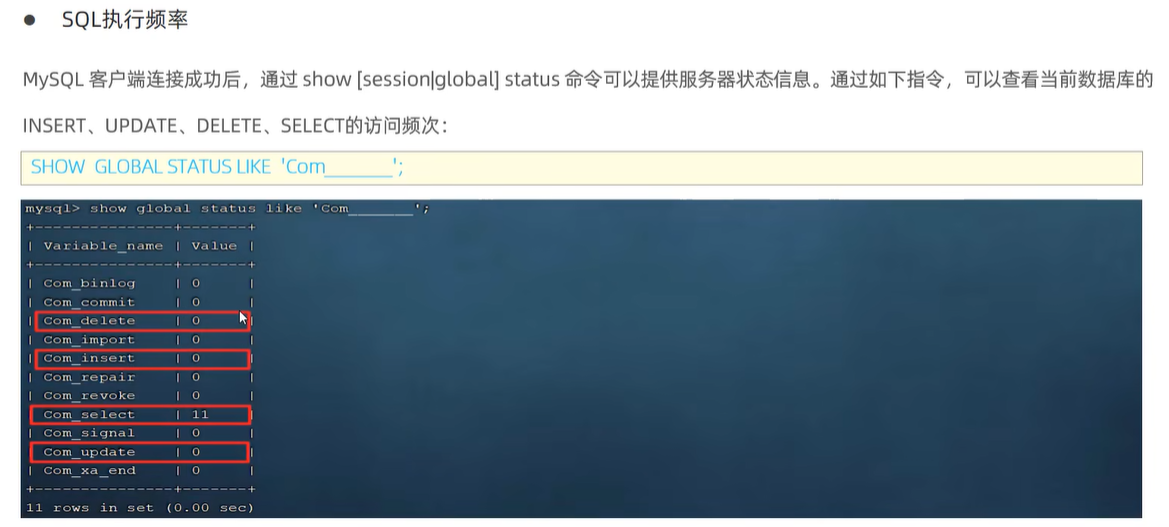
1>SQL执行频率:如何看“增删改查”各个语句的执行频率?
如果数据库以增删改为主,就没必要做索引优化;如果以查找Select为主,就有必要使用索引。
下图中,show [session/global] status
session是指看当前会话的;global是全局的。
like 'Com_ _ _ _ _ _ _'后面的_有七个
2>慢查询日志:找出对当前数据库的哪些Select语句进行优化
使用set global slow_query_log=1开启慢查询日志指对当前数据库生效,如果MySQL重启后则会失效。如果需要永久生效,就必须修改配置文件my.cnf。

Windows MySQL开启慢查询日志方法 - 微笑着写代码 - 博客园
3>profile详情:查看每条语句的耗时、每条语句各个阶段的耗时

2》举例
上图中的query_id是 show profiles;里的query_id,如下图。

4>explain:查看SELECT语句的执行计划

解释EXPLAIN 执行计划各字段含义??????
21. 进阶-索引-性能分析-explain_哔哩哔哩_bilibili
6、索引使用
7、索引设计原则
