黑马程序员 MySQL数据库入门到精通,从mysql安装到mysql高级、mysql优化全囊括_哔哩哔哩_bilibili
一、数据库相关概念
1、主流的关系型数据库都支持SQL语言——SQL语言可以操作所有的关系型数据库
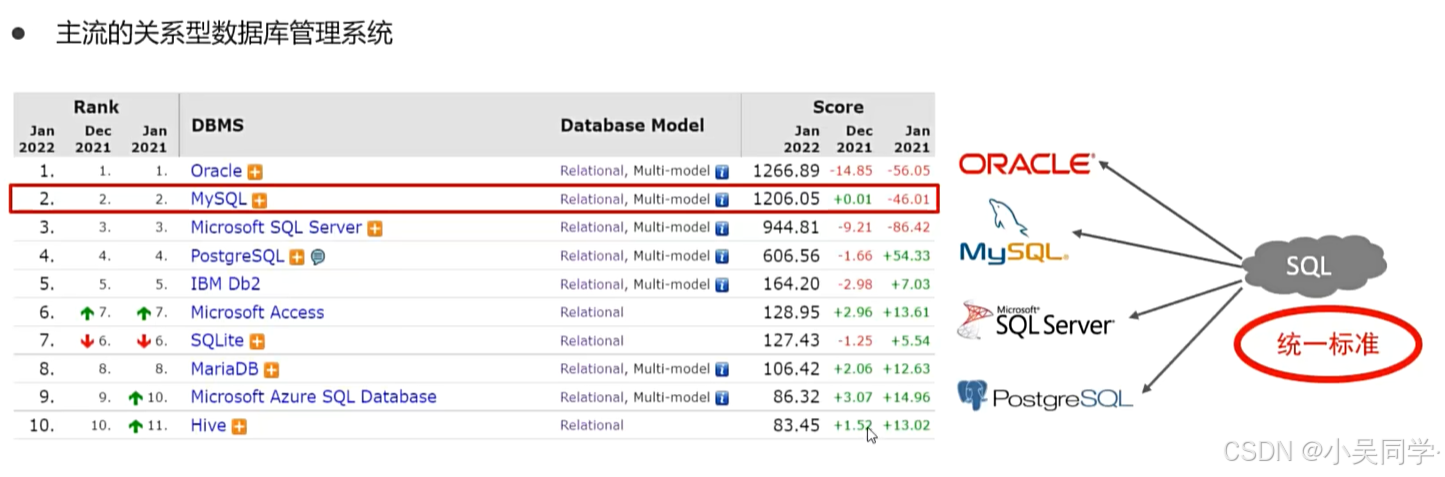
像MySQL、Oracle Database、Microsoft SQL Server、IBM Db2等主流的关系型数据库系统都支持SQL,并将其作为主要的查询和数据操作语言。这些系统实现了SQL标准的大部分功能,但也添加了各自的扩展和特性。
基础的SELECT、INSERT、UPDATE、DELETE等操作在大多数情况下是兼容的,但在涉及更复杂的查询或需要利用特定数据库特性的场合时,就需要针对具体数据库调整SQL代码了。【比如二、3、6>分页查询,不同关系型数据库用的不一样】

2、什么是 关系型数据库(RDBMS)?

反之,则称之为“非关系型数据库”。
二、SQL语句的分类——DDL、DML、DQL、DCL
下图中,注意SQL语句不区分大小写,关键字建议使用大写
当使用引号时,使用单引号。


1、DDL
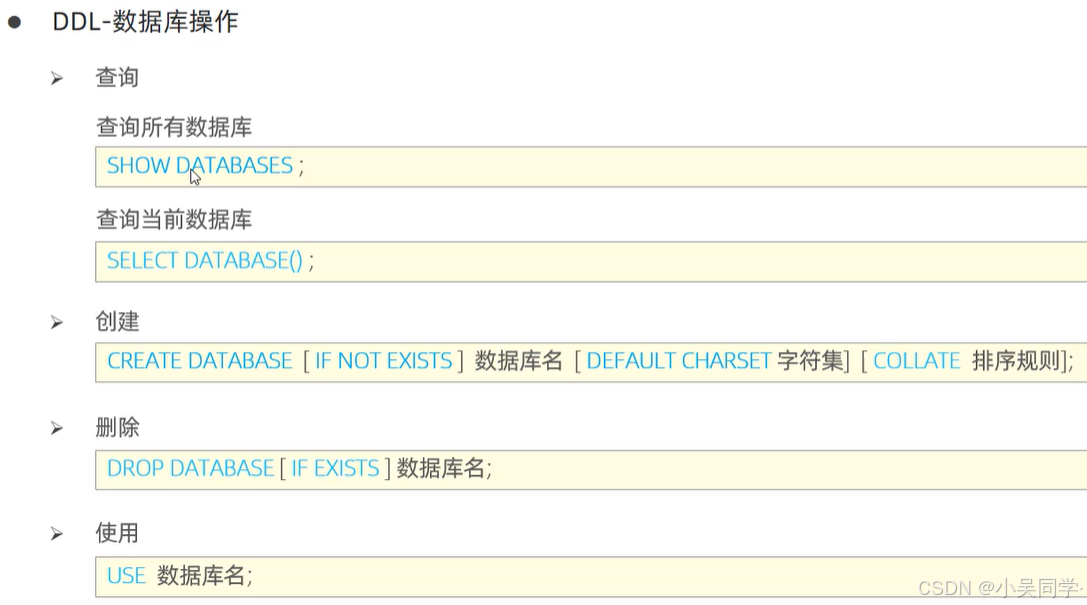
1>数据库操作
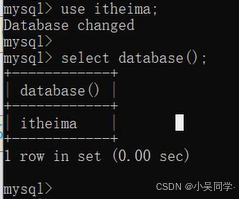
上图中,“查询当前数据库”是结合“使用”的。“查询当前数据库”——就是看当前处于哪个数据库。
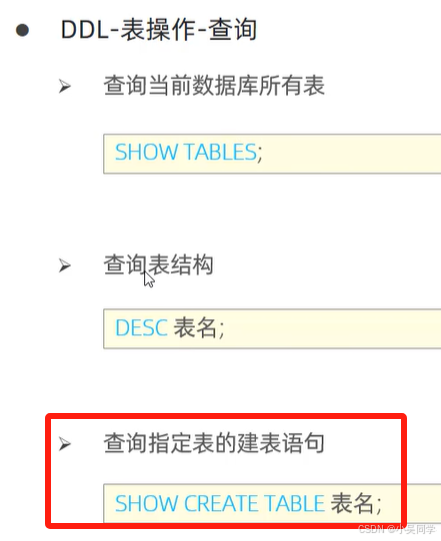
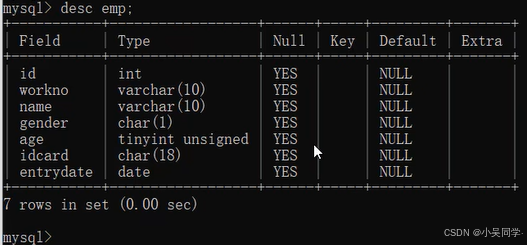
2>表操作——针对表+字段(即列名)
下图中,在对某个数据库进行操作时,要先通过上图的“使用”命令进入该数据库。
1》数据类型【略】:数值类型、字符串类型、日期时间类型
2》针对表——添加&修改&删除


下图中,TRUNCATE是只留下了表的结构,里面的数据都没有了

3》针对每个字段——添加&修改&删除



2、DML:对表中内容的增(INSERT)删(DELETE)改(UPDATE)
1>选择MySQL图形化界面
下载DataGrip,其功能比前两种都要强大。

DataGrip的基本操作,见下述链接:
11. 基础-SQL-图形化界面工具DataGrip_哔哩哔哩_bilibili
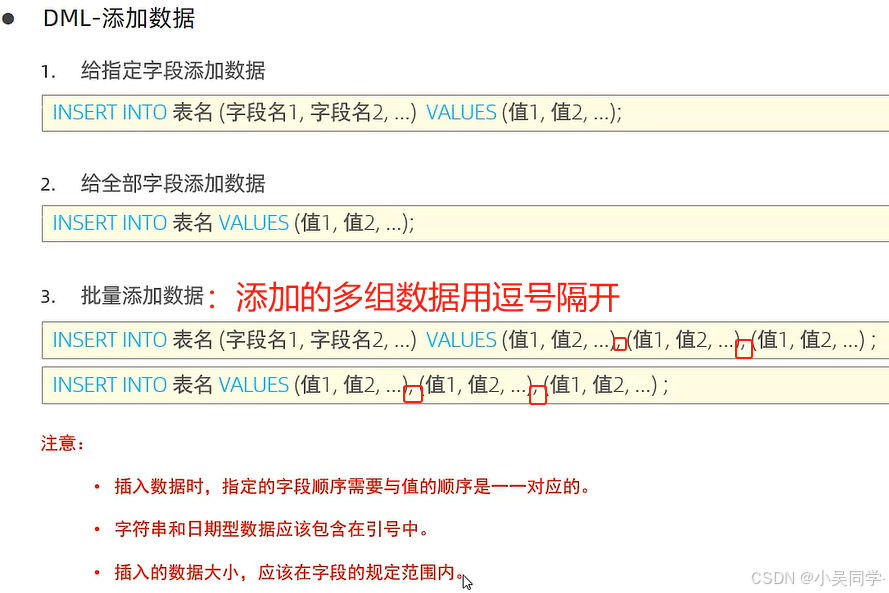
2>增(INSERT)——插入指定字段/全部字段;批量添加数据
下图中,引号是单引号。
3>改(UPDATE)

4>删(DELETE)

3、DQL:查询表中内容(SELECT);及其执行顺序!
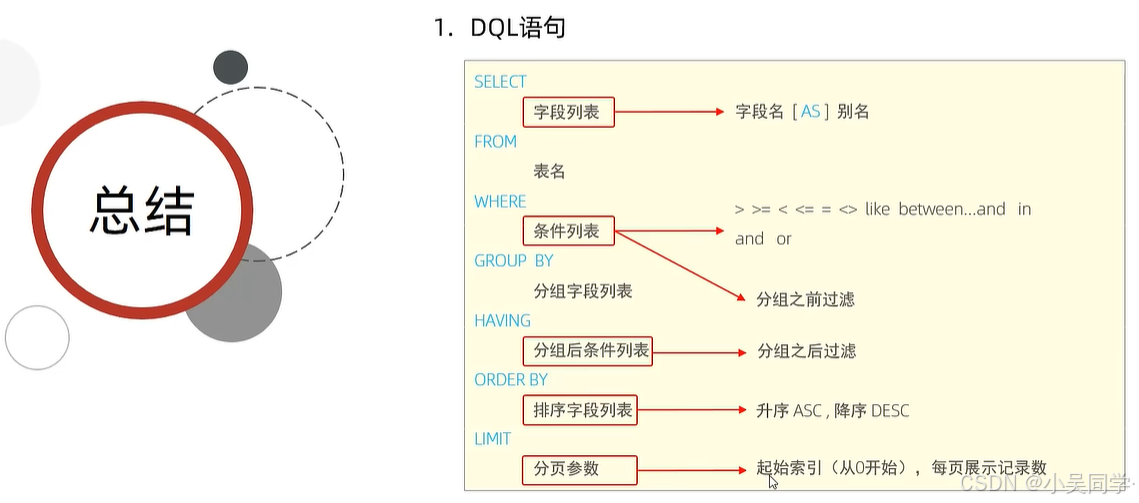
下图中,讲解分组查询前需要先讲聚合函数

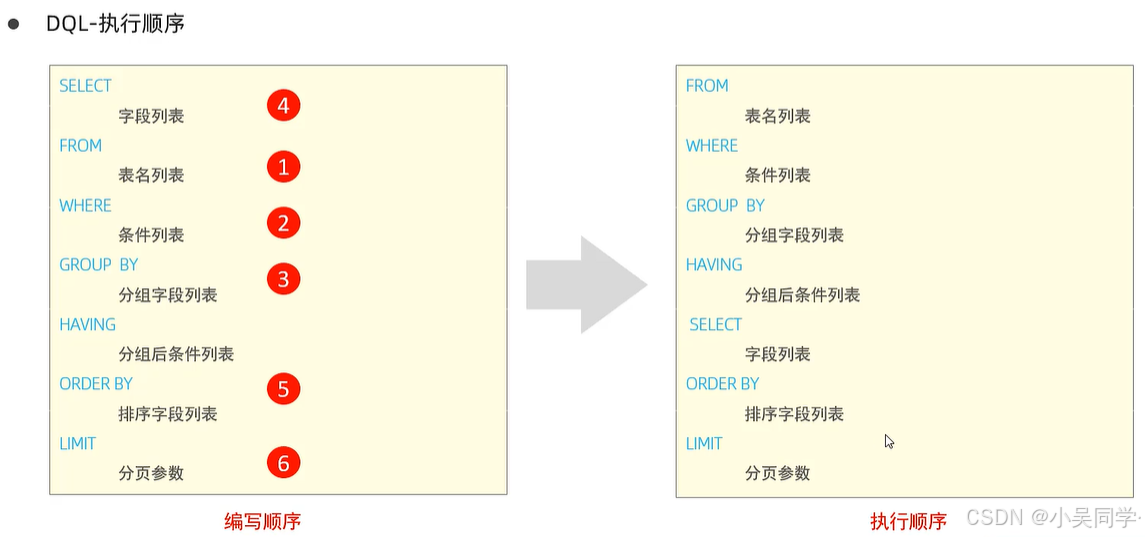
验证上图右边的执行顺序:
先执行FROM:如下图,在FROM后给表加别名,发现其它地方都可以用

WHERE在SELECT之前:如下图,在SELECT后面给e.age取别名eage,想在WHERE后面使用eage却报错。证明WHERE的执行顺序在SELECT之前!

SELECT在ORDER BY之前:如下图,在SELECT后面给e.age取别名eage,可以在ORDER BY后面使用eage。

1>基本查询

2>条件查询(WHERE)


注意区别OR和IN,如下图:
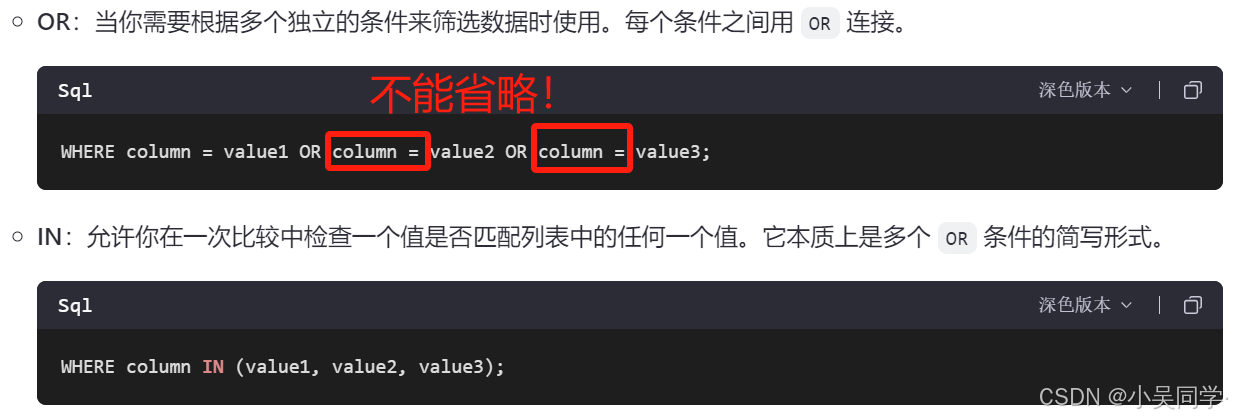
上图中红色字体部分“不能省略!”,解释如下图:

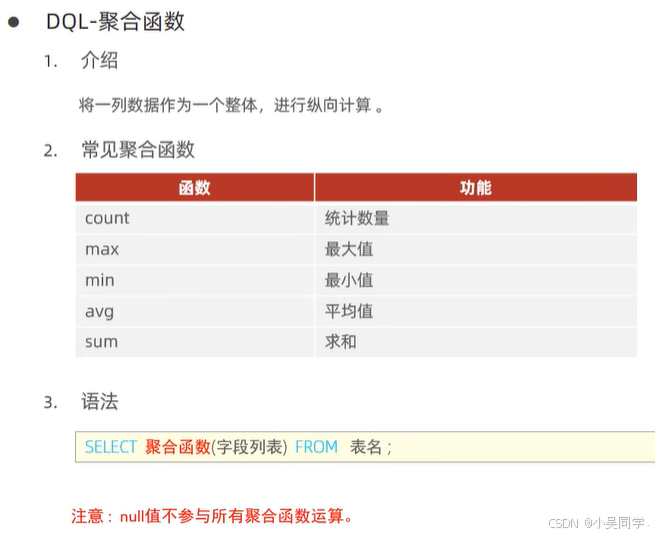
3>聚合函数【讲“分组查询”前得先讲聚合函数】:是作用于某一列的,注意NULL值不参与所有聚合函数运算
比如select count(*) from emp; 答案=16,即一共有16行数据。
然而,如果select count(idcard) from emp; 如果idcard有一行的数据为null,那么答案=15。【NULL值不参与所有聚合函数运算】
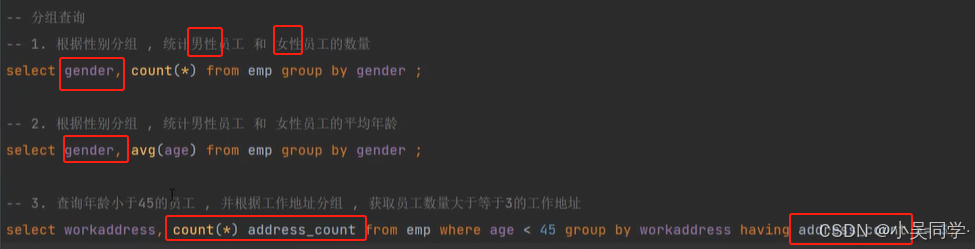
4>分组查询(GROUP BY)

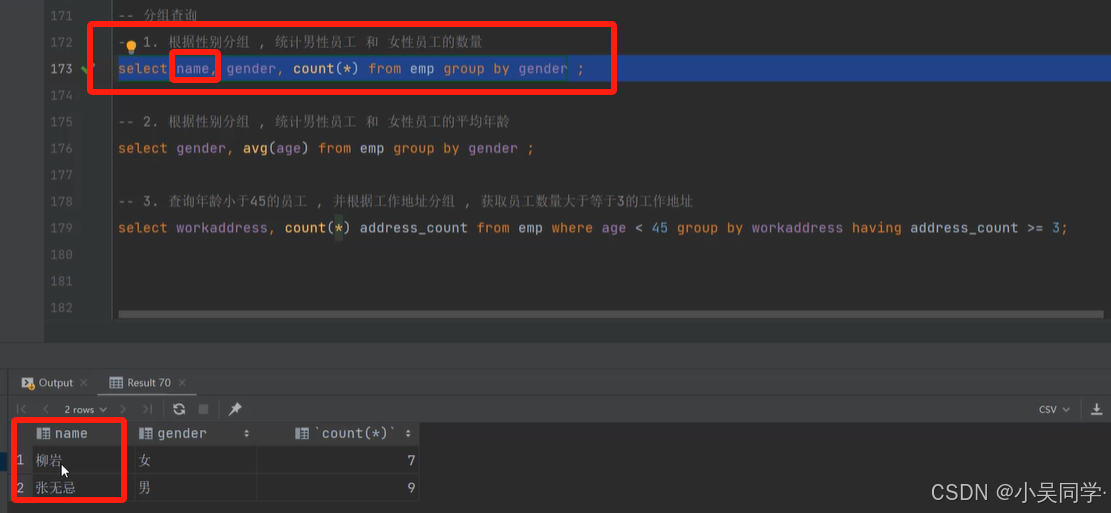
上图中,“分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义。”
比如下图的1.,如果加个name字段,是没有任何意义的。只是显示了性别是"女"的第一行数据的女生姓名。如下下图。
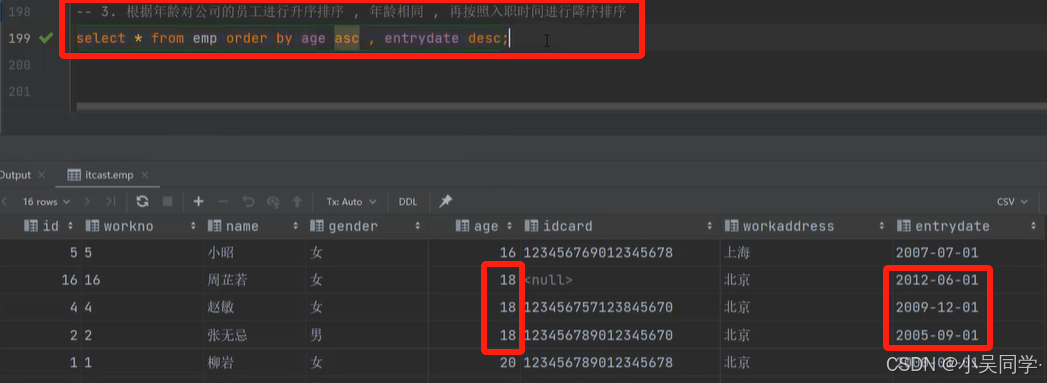
5>排序查询(ORDER BY)

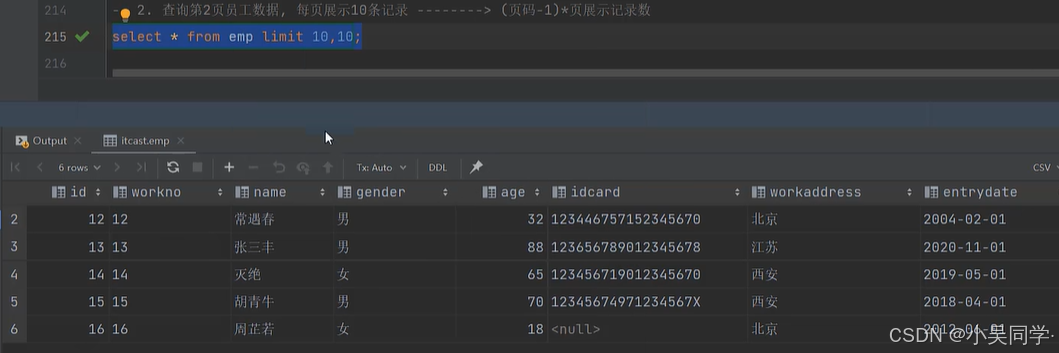
6>分页查询(数据库方言,MySQL中是LIMIT)
下图中,“查询记录数”就是“每页显示记录数”
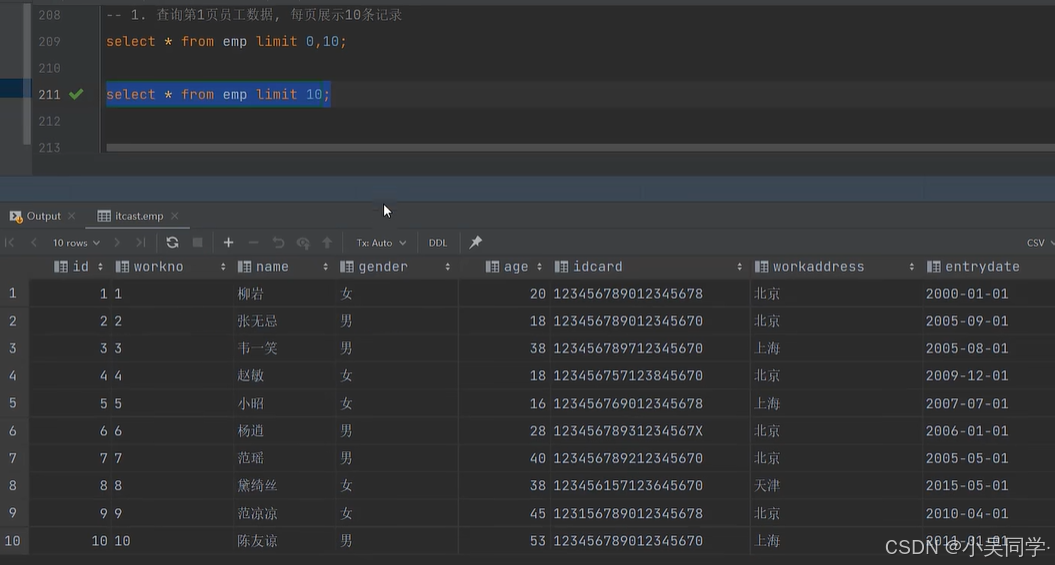
下图中,起始索引=(2-1)*10=10;“查询记录数”就是“每页显示记录数”=10.
emp表里一共16行数据,所以第二页只显示6行数据。
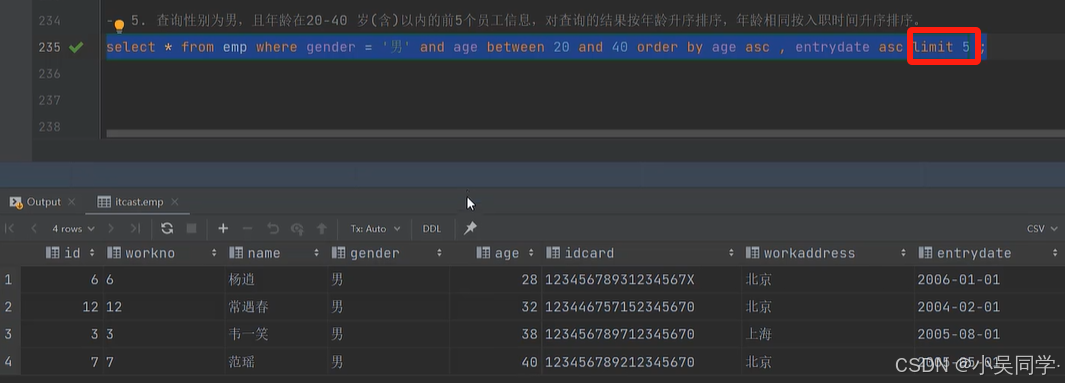
举例:查询前5个员工
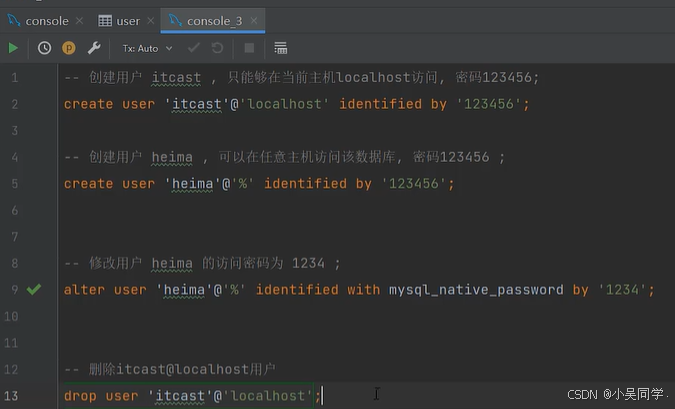
4、DCL:管理数据库 用户、控制数据库的访问 权限
1>管理用户
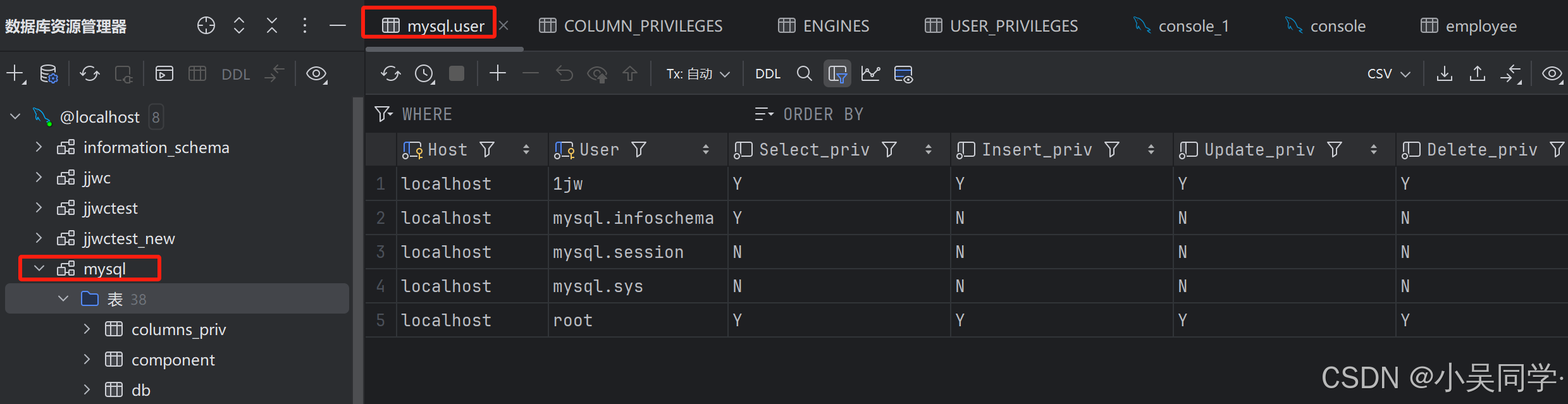
mysql数据库如下,里面有个user表存储着使用的用户。
举例:
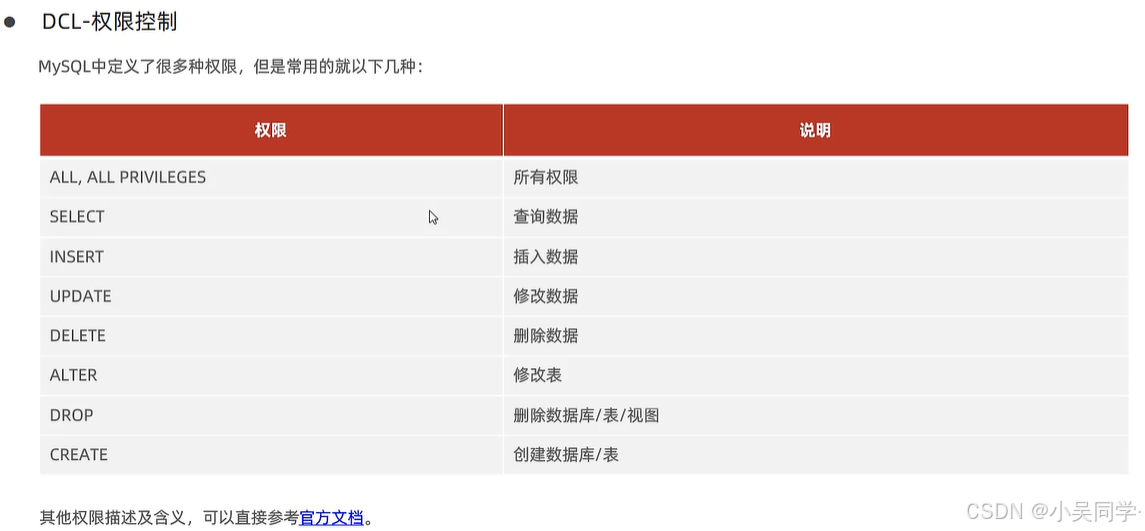
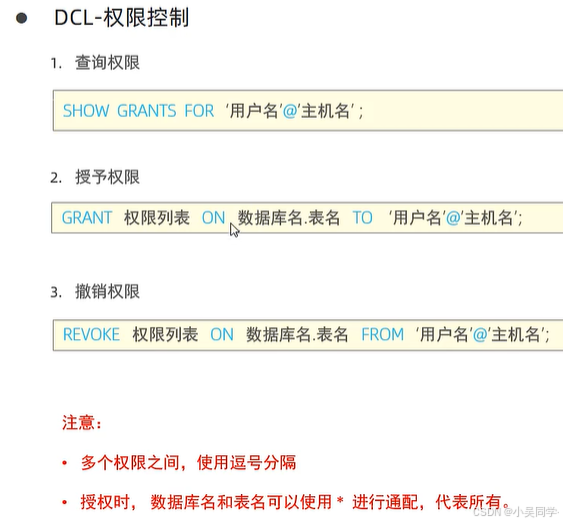
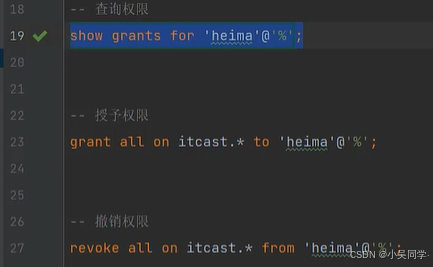
2>权限控制
三、函数
1、聚合函数【见二、3、3>】
2、字符串函数
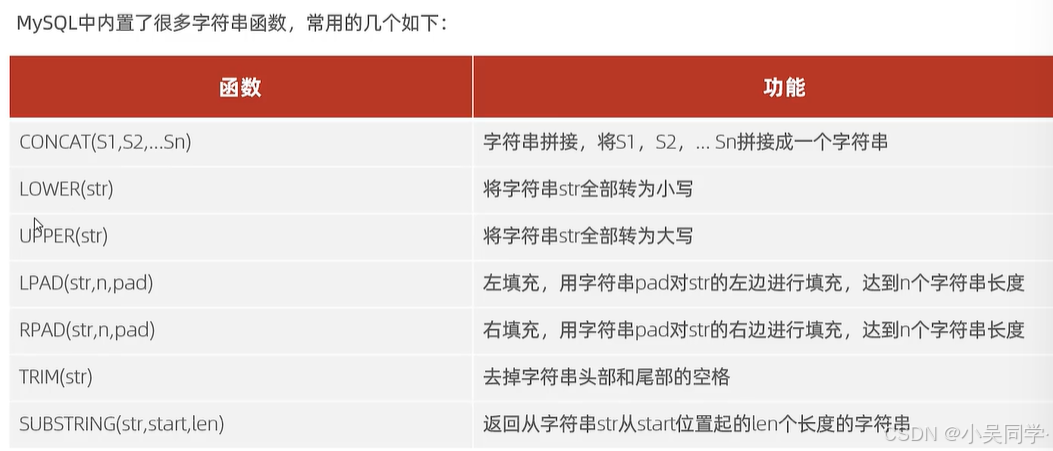
3、数值函数
4、日期函数
5、流程函数
四、约束:作用于表中字段上的规则,在创建/修改表的时候添加约束
1、概述

2、举例

在上图创建完表后,插入下图的两条数据,不用指定id字段

如下图所示,id字段会自增
3、外键约束:外键用来让两张表的数据之间建立连接,从而保证数据的一致性和完整性
1>外键关联到另一个表中的字段,被引用的列需要保证其值的 唯一性和非空性
这意味着,被引用的列是 主键(Primary Key) 或 唯一约束(Unique Constraint)+ 非空。
唯一约束允许列包含空值(除非在定义约束时明确指定了不允许空值)。因此,在确保非空性的前提下,具有唯一约束的列也可以被外键引用。
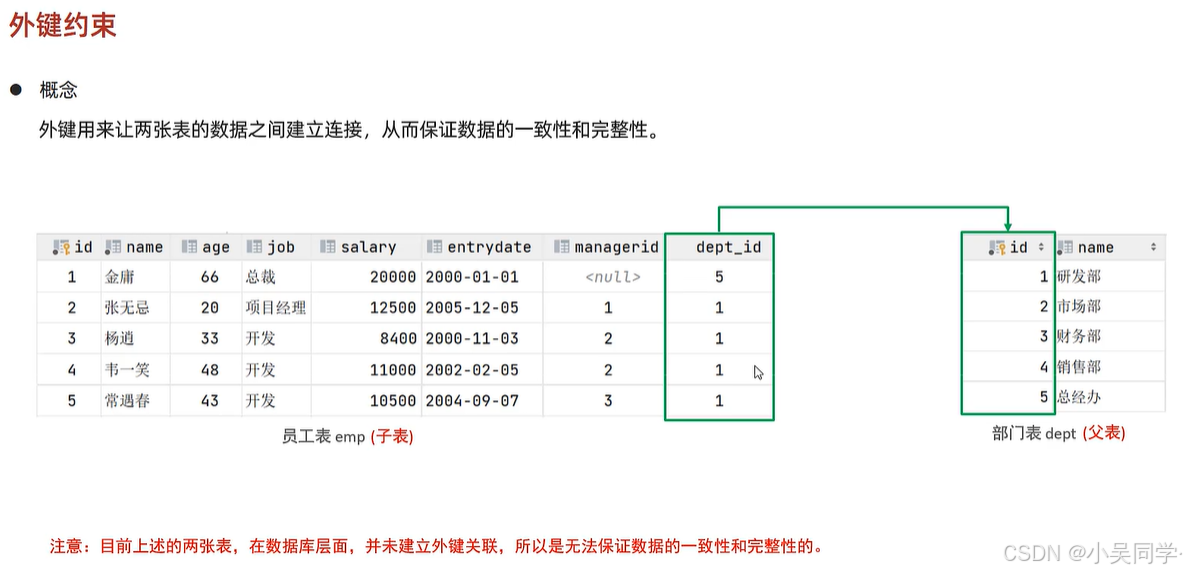
在上图中,如果在父表dept中删除了id=1的部门,对子表emp没有任何影响。这违背了数据的一致性和完整性。

创建表后添加外键


现在如果要在父表dept中删除了id=1的部门,那么会报错
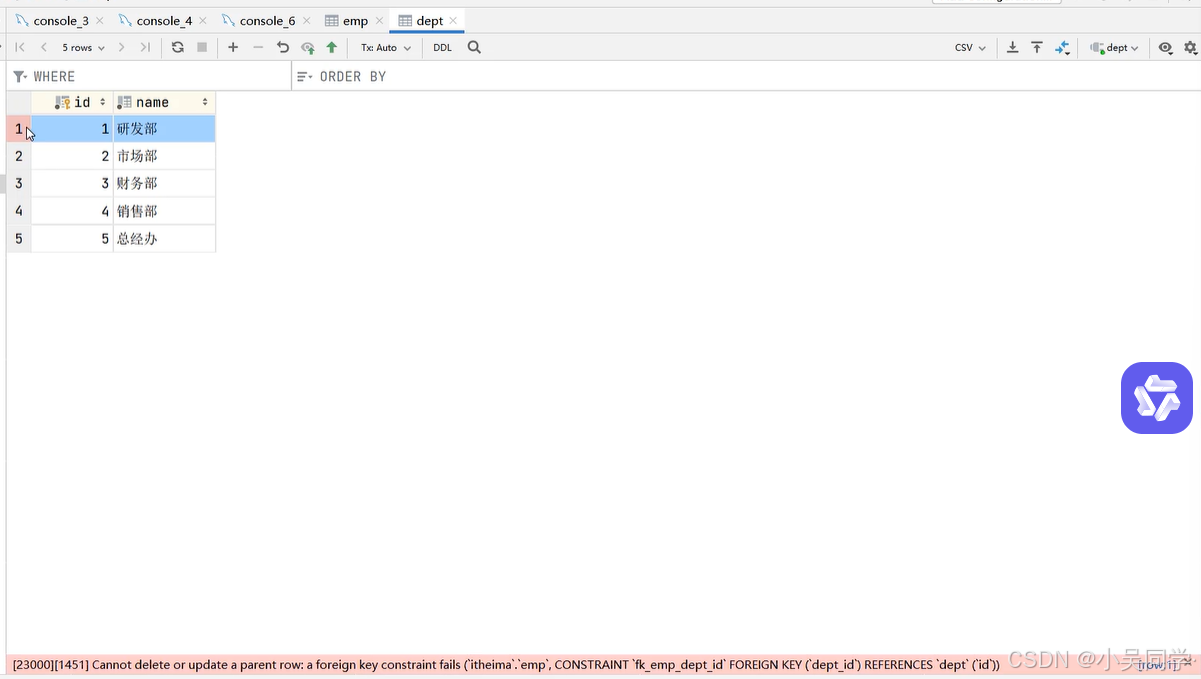
2>外键删除更新行为【级联操作等】

1》举例CASCADE

2》举例SET NULL

五、多表查询
1、多表关系:一对多(多对一)、多对多、一对一

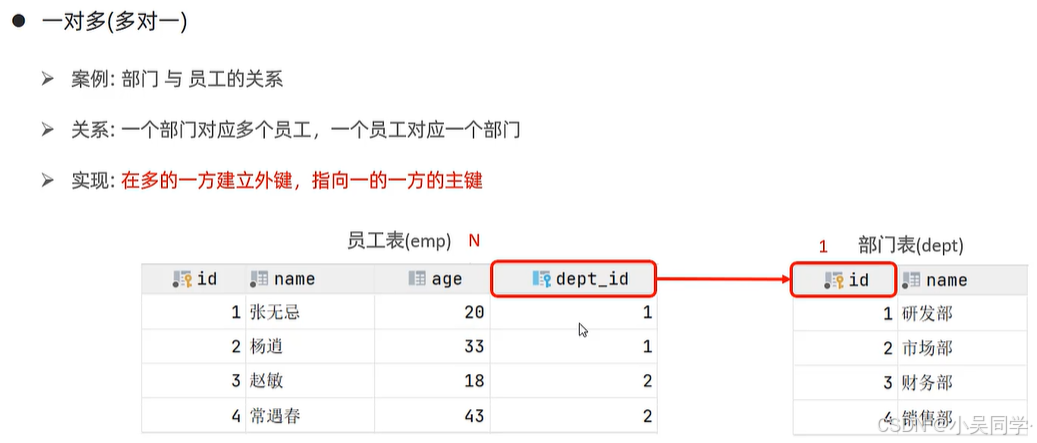

3>一对一:多用于单表拆分
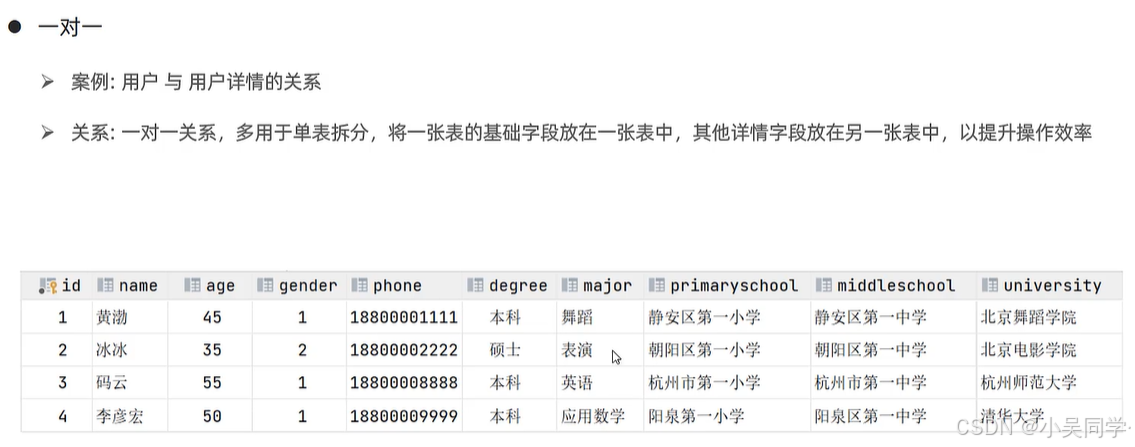
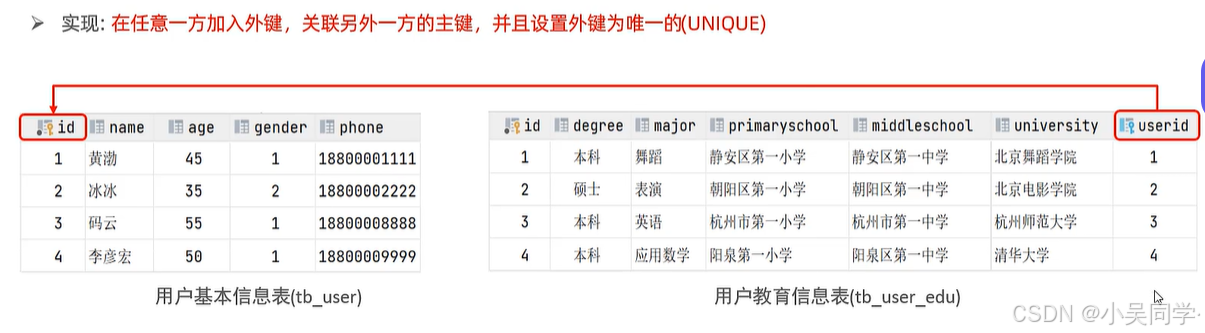
拆分上图中的表为两张表,如下图

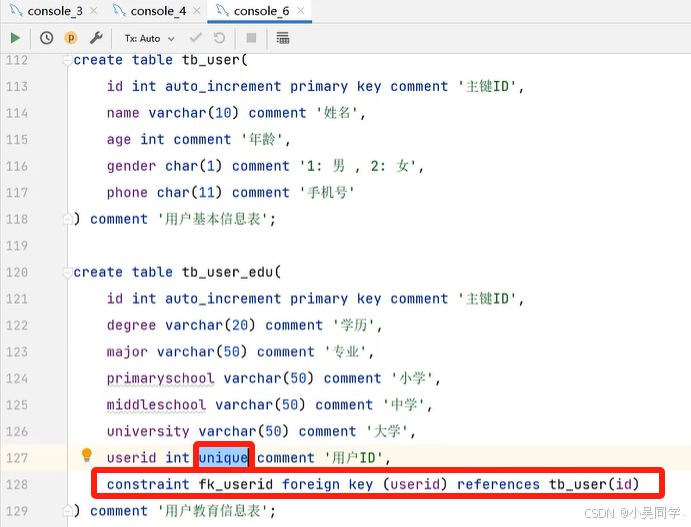
增加外键,关联两张表。如下图
注意要设置外键为唯一的。如下下图。
2、多表查询概述:需要消除掉无效的笛卡尔积【常为表取别名:在FROM后面取(因为执行DQL顺序是先执行FROM)】

需要消除掉无效的笛卡尔积,只显示有用的数据

3、多表查询分类:连接查询【内、外(左/右)、自连接】、子查询
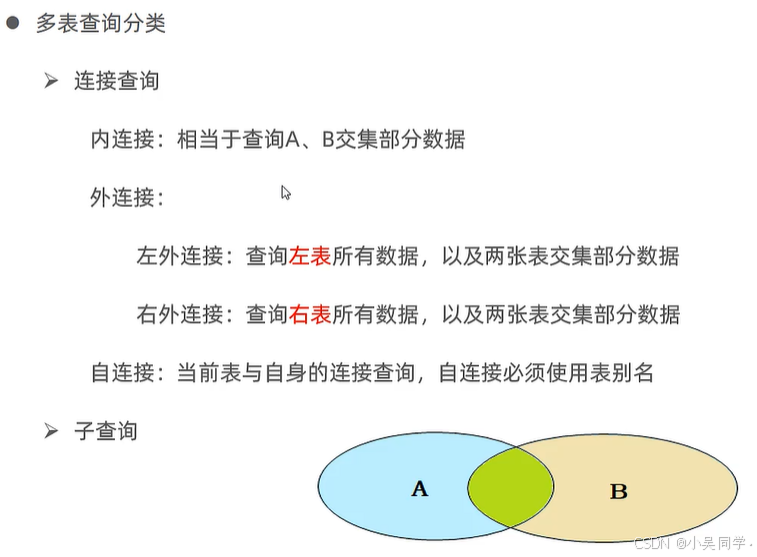
1>内连接(隐式、显式):查询两张表交集的部分


2>外连接(左外、右外):谁取名就以谁为主


3>自连接:自己连接自己
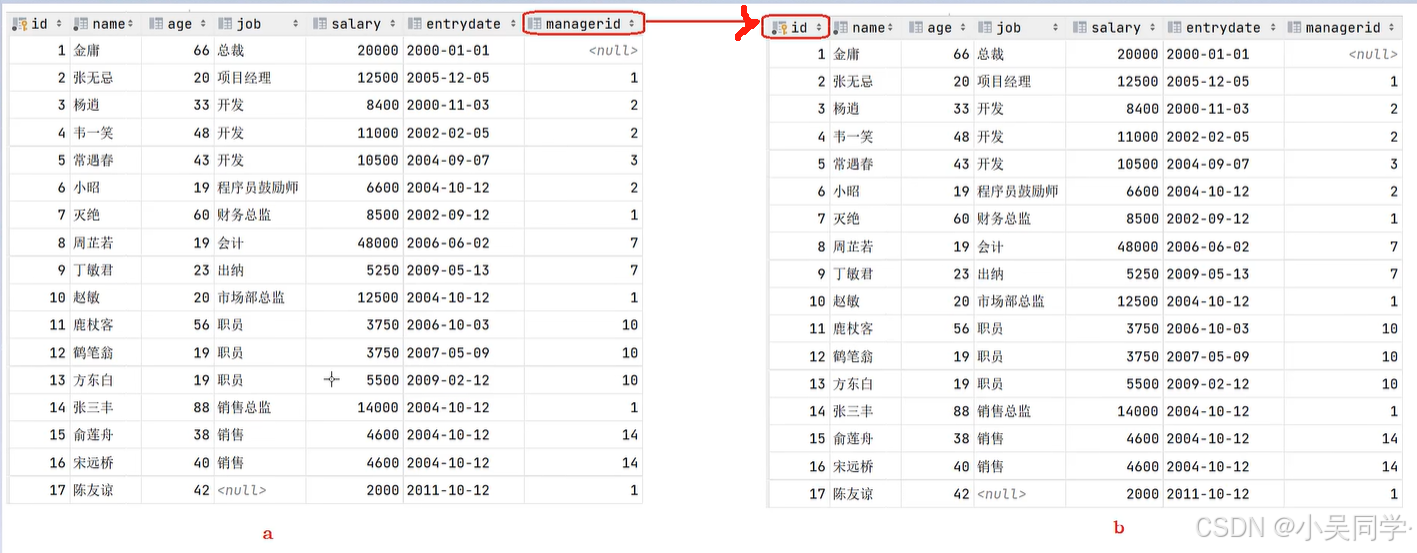
举例:
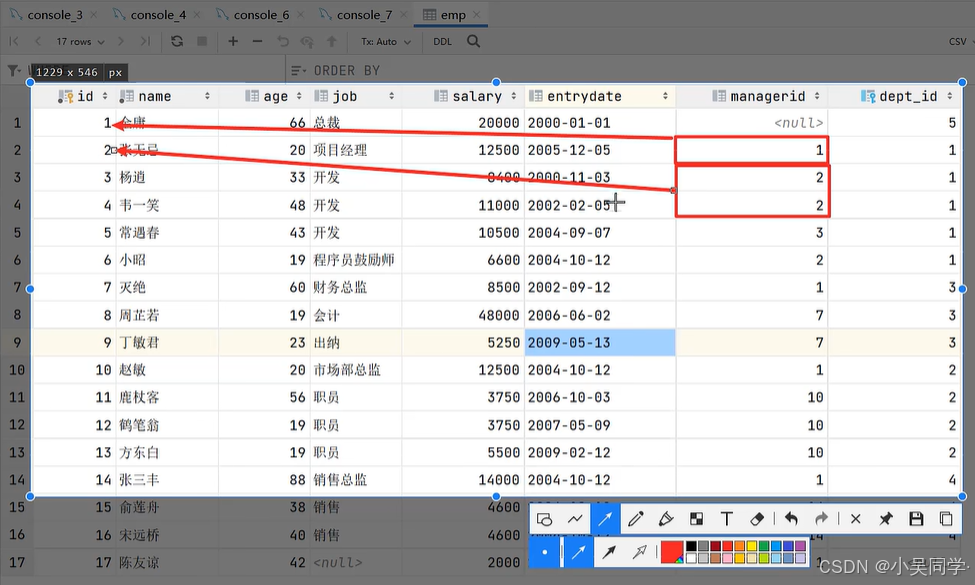
把上图看作下图两张表

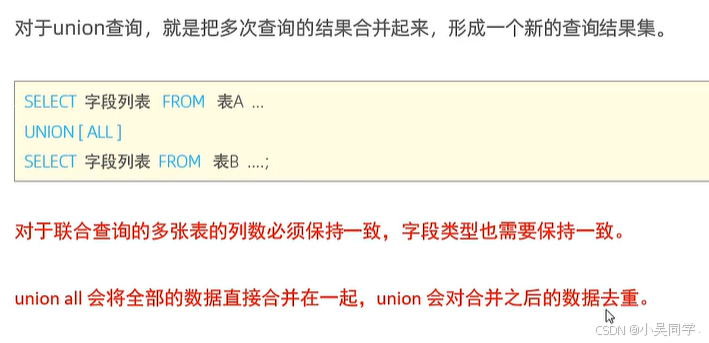
4、联合查询(union , union all):把多次查询的结果合并起来,形成一个新的查询结果集

5、子查询(嵌套查询):SQL语句中嵌套SELECT语句

1>标量子查询
2>列子查询
3>行子态询
4>表子查询
六、事务
1、事务:一组操作的集合,它是一个不可分割的工作单位(这些操作要么同时成功,要么同时失败)
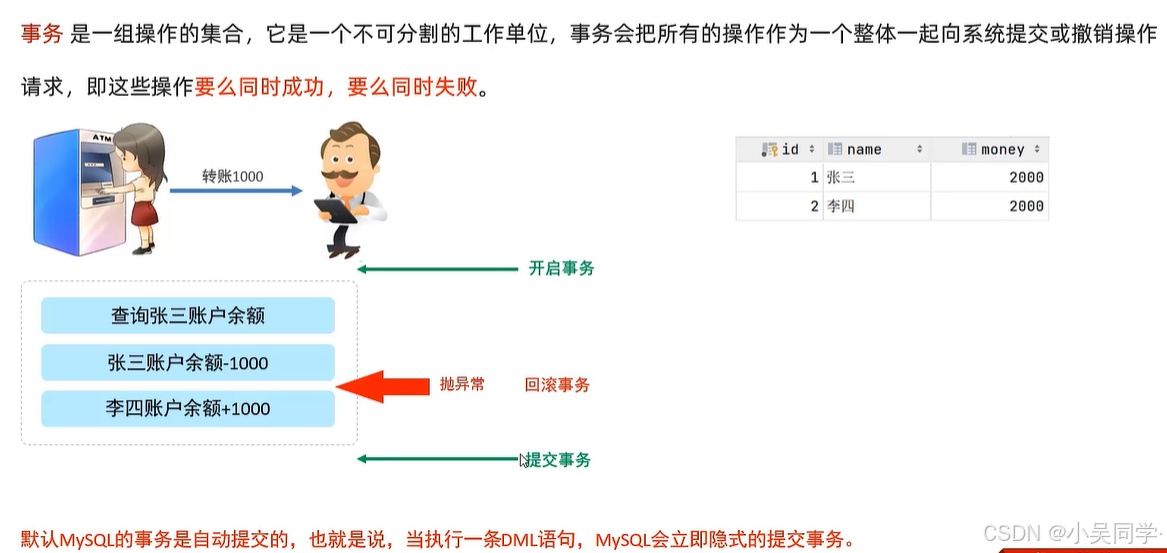
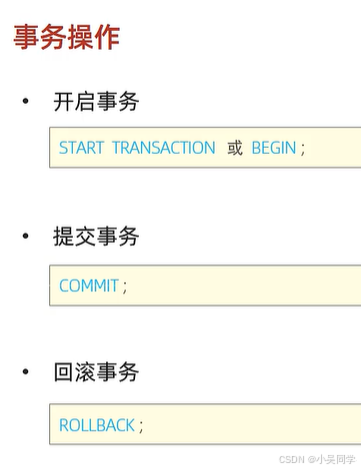
2、事务操作
下面左/右两图作用一样的。
在左图中,SELECT @@autocommit;
如果结果=1,则是自动提交事务;如果结果=0,则是手动提交事务,需要执行commit;

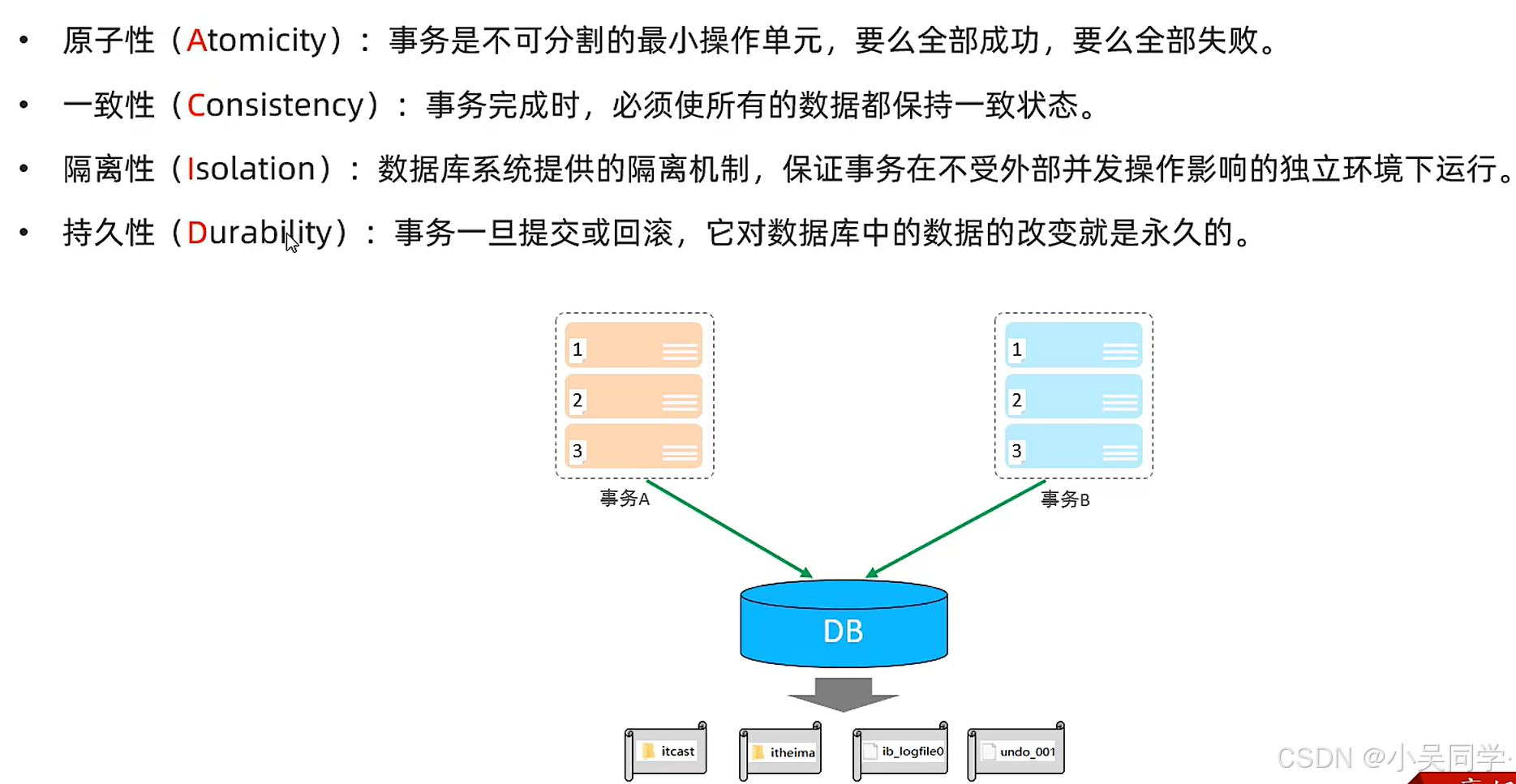
3、事务四大特性(ACID):原子性(A)、一致性(C)、隔离性(I)、持久性(D)
持久性:一旦事务提交,数据就会永久地存储在磁盘中,如下图
4、并发事务问题:脏读、不可重复读、幻读

1>脏读
在下图中,事务A要执行3个操作。事务A在第二个操作时把id的值更新了,但是此时事务A还没有提交。事务B却拿到了更新后的id的值。这种情况称为”脏读“。
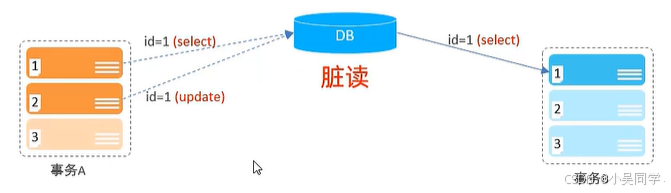
1》问题分析
这属于典型的“脏读”问题。
如果事务 A 后续回滚(Rollback),那么事务 B 读取到的数据实际上是无效的,导致数据不一致。
2》如何避免
提高事务隔离级别到 READ COMMITTED(读已提交) 或更高。
- READ COMMITTED:确保事务只能读取已提交的数据,避免脏读。
2>不可重复读
在下图中,事务A要执行4个操作。事务A执行第一个操作时,没有找到id=1。此后,事务B向数据库提交了id=1的更新。然后,事务A的第三个操作就读到了更新后的id数据。这种情况称为”不可重复读“。
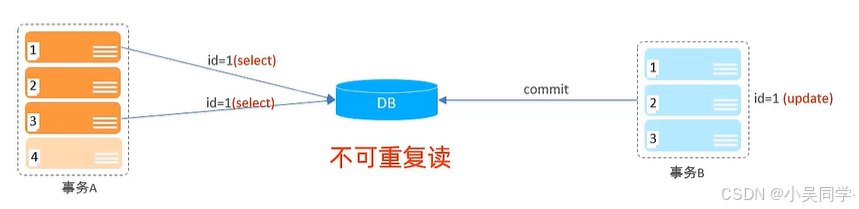
1》问题分析
这属于“不可重复读”问题。
事务 A 在同一个事务中对同一条数据的两次查询结果不一致,可能导致业务逻辑错误
2》如何避免
提高事务隔离级别到 REPEATABLE READ(可重复读) 或更高。
- REPEATABLE READ:在同一事务中,多次读取同一数据时,保证结果一致。即确保事务内多次读取结果一致。
- 不过,在某些数据库(如 MySQL 的 InnoDB 引擎)中,即使在 REPEATABLE READ 隔离级别下,仍可能出现幻读问题。
3>幻读
在下图中,事务A 执行 id=1(insert)时,由于事务B已经插入了id=1(id是主键),那么这句话就会报错。此时在事务A中再次执行id=1(select),会发现id=1这个主键又在了。
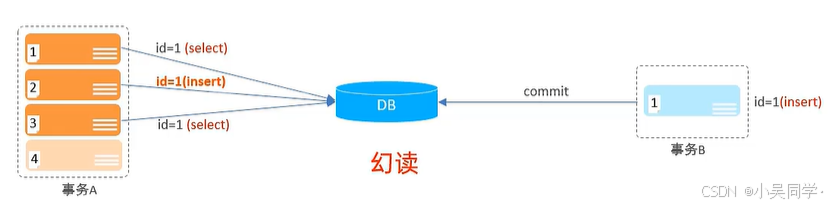
1》问题分析
这属于“幻读”问题。
幻读通常发生在范围查询中(例如 SELECT * FROM table WHERE id > 10),但由于主键冲突的存在,这种现象也可以被归类为幻读的一种表现形式。
2》如何避免
提高事务隔离级别到 SERIALIZABLE(串行化)。
- SERIALIZABLE:最高隔离级别,完全避免脏读、不可重复读和幻读。
- 代价是性能下降,因为事务之间会被串行化执行。
5、事务隔离级别——分析原因见4、
下图中,✔代表允许。
SERIALIZABLE(串行化)隔离级别最高,性能却最差。

举例:
