引言
在机器学习和数据挖掘领域,聚类算法是一种非常重要的无监督学习方法。K-Means算法作为其中最经典和常用的算法之一,因其简单、高效的特点,被广泛应用于图像分割、文本聚类、市场细分等领域。本文将详细介绍K-Means算法的原理、实现步骤、优缺点以及实际应用场景,帮助读者全面理解这一算法。
1. K-Means算法简介
K-Means算法是一种基于距离的聚类算法,其核心思想是通过迭代将数据集划分为K个簇,使得每个簇内的数据点尽可能相似,而不同簇之间的数据点尽可能不同。K-Means算法的目标是最小化簇内误差平方和(Within-Cluster Sum of Squares, WCSS),即每个数据点到其所属簇中心的距离之和。
2. K-Means算法原理
2.1 算法步骤
K-Means算法的实现过程可以分为以下几个步骤:
1. 初始化:随机选择K个数据点作为初始的簇中心(质心)。
2. 分配:对于数据集中的每个数据点,计算其与K个簇中心的距离,并将其分配到距离最近的簇中 心所对应的簇中。
3. 更新:重新计算每个簇的中心,即该簇中所有数据点的均值。
4. 迭代:重复步骤2和步骤3,直到簇中心不再发生变化或达到预定的迭代次数。
2.2 数学表达
K-Means算法的目标是最小化以下目标函数:
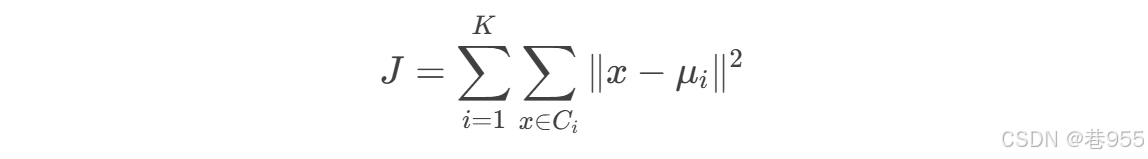
其中:
3. K-Means算法的实现
3.1 Python实现
下面是一个简单的K-Means算法的Python实现:
import numpy as np
def k_means(X, K, max_iters=100):
# 随机初始化簇中心
centroids = X[np.random.choice(range(len(X)), K, replace=False)]
for _ in range(max_iters):
# 分配步骤:将每个数据点分配到最近的簇中心
labels = np.argmin(np.linalg.norm(X[:, np.newaxis] - centroids, axis=2), axis=1)
# 更新步骤:重新计算簇中心
new_centroids = np.array([X[labels == k].mean(axis=0) for k in range(K)])
# 判断是否收敛
if np.all(centroids == new_centroids):
break
centroids = new_centroids
return labels, centroids
# 示例数据
X = np.array([[1, 2], [1, 4], [1, 0],
[10, 2], [10, 4], [10, 0]])
# 调用K-Means算法
labels, centroids = k_means(X, K=2)
print("簇标签:", labels)
print("簇中心:", centroids)
3.2 使用Scikit-learn库
在实际应用中,我们通常使用成熟的机器学习库来实现K-Means算法。Scikit-learn库提供了高效的K-Means实现:
from sklearn.cluster import KMeans
import numpy as np
# 示例数据
X = np.array([[1, 2], [1, 4], [1, 0],
[10, 2], [10, 4], [10, 0]])
# 创建KMeans模型
kmeans = KMeans(n_clusters=2, random_state=0)
# 拟合模型
kmeans.fit(X)
# 输出结果
print("簇标签:", kmeans.labels_)
print("簇中心:", kmeans.cluster_centers_)
4. K-Means算法的优缺点
4.1 优点
- 简单高效:K-Means算法原理简单,易于实现,计算效率高,适合处理大规模数据集。
- 可解释性强:聚类结果直观,簇中心可以解释为每个簇的代表点。
4.2 缺点
- K值选择困难:K-Means算法需要预先指定簇的数量K,而K的选择通常依赖于经验或领域知识。
- 对初始值敏感:初始簇中心的选择会影响最终的聚类结果,可能导致局部最优解。
- 对噪声和异常值敏感:K-Means算法对噪声和异常值较为敏感,可能会影响聚类效果。
- 仅适用于凸数据集:K-Means算法假设簇是凸形的,对于非凸形状的簇效果不佳。
总结
K-Means算法作为一种经典的聚类算法,因其简单、高效的特点,在实际应用中得到了广泛的使用。然而,K-Means算法也存在一些局限性,如对初始值敏感、K值选择困难等。在实际应用中,我们需要根据具体问题的特点选择合适的聚类算法,并结合领域知识对聚类结果进行解释和优化。