文章目录
Visual-RFT: Visual Reinforcement Fine-Tuning
上海交通大学;上海人工智能实验室;香港中文大学
arxiv’25’03
速览
动机
尽管R1风格(强化微调GRPO)的模型在语言模型中取得了成功,但其在多模态模型中探索较少。
方法
引入了视觉强化微调(Visual-RFT),它扩展了在视觉感知任务中使用可验证奖励的强化学习,适用于在有限数据下进行微调的情况。
方法是没有的,就是设计了两个奖励函数:
- 检测任务中的IoU奖励,这个是基于IoU和置信度的奖励函数,置信度是模型对自己输出的坐标的置信度;
- 分类任务中的CLS奖励,这个超级简单,就是分类对了奖励为1,分类错了奖励为0。
实验
跑了很多个数据集,不过应该都是小的、耗时短的数据集,跑的任务有少样本分类、少样本物体检测、推理定位和开放词汇物体检测。这些实验主要是为了证明强化学习可以使得模型仅通过少量数据便可以显著提升,并且模型不是强行记忆数据而是真正理解任务了。
摘要
大推理模型(LRMs)如OpenAI的o1通过反馈学习其回答,这在微调数据稀缺的应用中尤为重要。最近的开源工作,如DeepSeek-R1,展示了带有可验证奖励的强化学习是重现o1的关键方向。尽管R1风格的模型在语言模型中取得了成功,但其在多模态领域的应用仍然较少。本文介绍了视觉强化微调(Visual-RFT),进一步扩展了RFT在视觉任务中的应用领域。具体来说,Visual-RFT首先使用大型视觉-语言模型(LVLMs)为每个输入生成包含推理令牌和最终答案的多个响应,然后使用我们提出的视觉感知可验证奖励函数,通过政策优化算法(如群体相对策略优化(GRPO))更新模型。我们为不同的感知任务设计了不同的可验证奖励函数,如物体检测任务中的交并比(IoU)奖励。关于细粒度图像分类、少量样本物体检测、推理定位以及开放词汇物体检测基准的实验结果表明,Visual-RFT在与监督微调(SFT)相比,具有竞争力的性能和先进的泛化能力。例如,Visual-RFT在仅有约100个样本的情况下,提升了细粒度图像分类的准确度,超出了基线24.3%。在少量样本物体检测中,Visual-RFT在COCO的二次样本设置中提高了21.9,在LVIS中提高了15.4。我们的Visual-RFT代表了一种微调LVLMs的范式转变,提供了一种数据高效、奖励驱动的方法,增强了推理能力和适应性,适用于领域特定的任务。
1. 引言
大型推理模型(LRMs),如OpenAI的o1,代表了前沿的AI模型,旨在在回答之前花费更多的时间“思考”,并取得卓越的推理能力。OpenAI o1的一个令人印象深刻的能力是强化微调(RFT),它通过仅用几十到几千个样本来高效地微调模型,从而在特定领域的任务中表现出色。尽管o1的实现细节没有公开,但最近的开源研究,如DeepSeek R1,揭示了重现o1的一个有前景方向是可验证奖励:强化学习中的奖励分数是直接由预定义规则确定的,而不是由训练在偏好数据上的单独奖励模型预测的。
RFT与之前的监督微调(SFT)之间的一个主要区别在于数据效率。SFT范式(见图2(a))直接模仿在高质量、精心策划数据中提供的“真实答案”,因此依赖大量的训练数据。相比之下,RFT评估模型的响应并根据其是否正确进行调整,帮助模型通过试错进行学习。因此,RFT在数据稀缺的领域中特别有用。然而,过去的共识是,RFT仅应用于像科学(例如数学)和代码生成这样的任务。这是因为数学和编码展示了明确和客观的最终答案或测试案例,使得它们的奖励相对容易验证。在本文中,我们证明了RFT不仅可以应用于数学和代码领域,还可以扩展到视觉感知任务。具体来说,我们引入了视觉强化微调(Visual-RFT),它成功地将RFT扩展到增强大型视觉-语言模型(LVLMs)在各种多模态任务中的能力(见图1),例如少样本分类和开放词汇物体检测。

为了将RFT扩展到视觉任务,我们在图2(b)中展示了Visual-RFT的实现细节。对于每个输入,Visual-RFT使用大型视觉-语言模型(LVLMs)生成包含推理令牌和最终答案的多个响应(轨迹)。关键是,我们定义了针对不同任务的基于规则的可验证奖励函数,以指导模型通过政策优化算法,如GRPO,进行更新。例如,我们为物体检测任务提出了交并比(IoU)奖励。我们的Visual-RFT与SFT形成对比,后者依赖于记忆正确答案。相反,我们的方法探索了不同的解决方案,并学习根据我们验证的奖励函数优化预期结果。这是发现最佳方法,而不仅仅是模仿预定义的答案。我们的方法将训练范式从SFT中的数据扩展转变为针对特定多模态任务设计可变奖励函数的战略性设计。如图2(c)所示,可验证奖励与视觉感知能力(例如检测、定位、分类)的协同组合,使我们的模型能够通过详细的推理过程迅速、高效地掌握新概念。
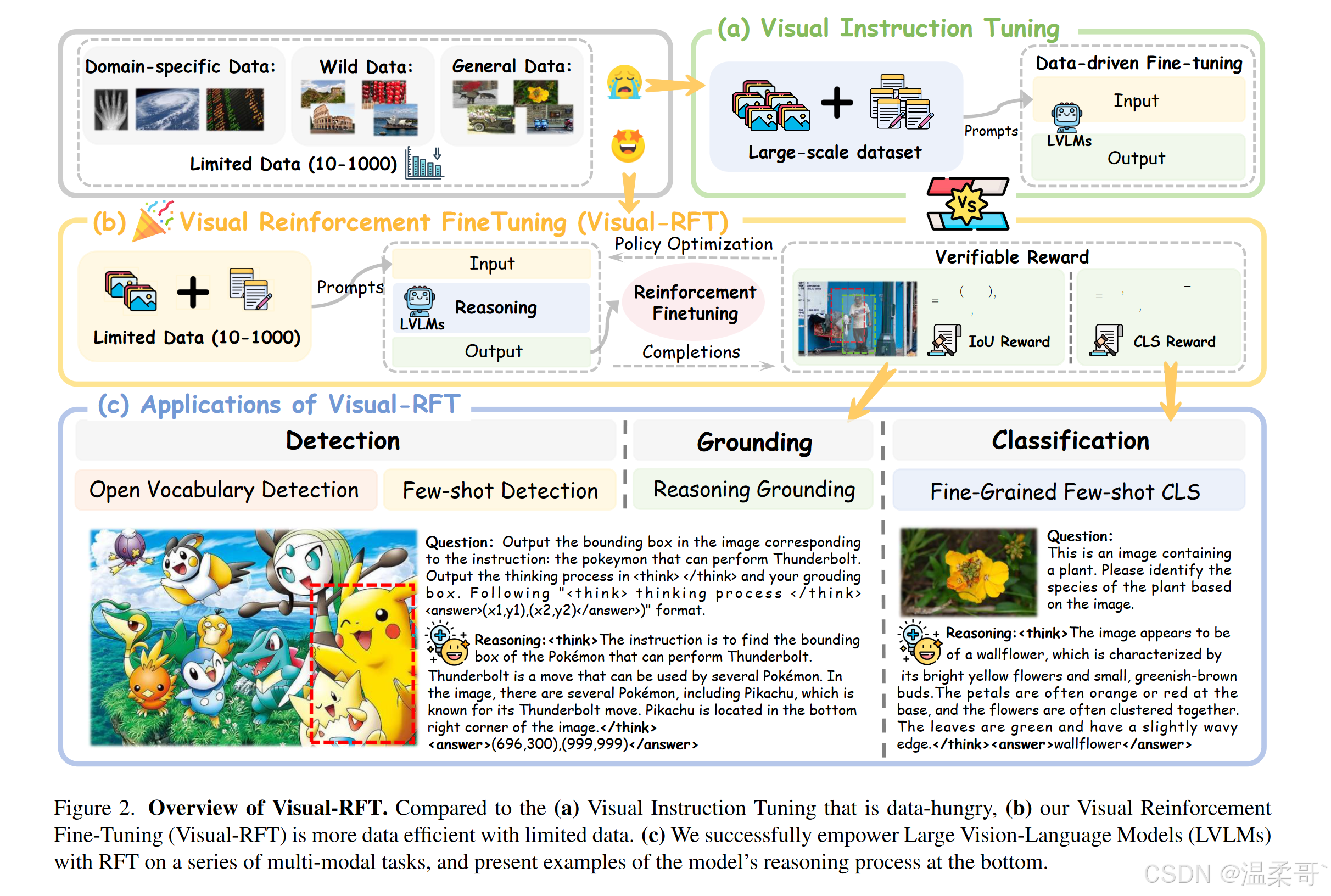
我们验证了Visual-RFT在以下任务中的有效性。在细粒度图像分类中,模型利用其先进的推理能力高精度地分析细粒度类别。在仅有极少量数据(例如,大约100个样本)的单次实验设置中,Visual-RFT使得准确度比基线提高了24.3%,而SFT下降了4.3%。在少样本实验中,Visual-RFT也展示了出色的性能,展示了与SFT相比的超强少样本学习能力。在推理定位任务中,Visual-RFT在LISA数据集上表现出色,超过了像GroundedSAM等专门的模型。此外,在开放词汇物体检测中,Visual-RFT迅速将识别能力转移到新类别,包括LVIS中的稀有类别,展现了强大的泛化能力。具体来说,2B模型在COCO新类别上实现了mAP从9.8提高到31.3,在LVIS选择的稀有类别上从2.7提高到20.7。这些多样的视觉感知任务不仅突出了Visual-RFT在视觉识别中的强大泛化能力,而且强调了强化学习在提升视觉感知和推理中的关键作用。
总结起来,我们的主要贡献如下:
- 我们引入了视觉强化微调(Visual-RFT),它扩展了在视觉感知任务中使用可验证奖励的强化学习,适用于在有限数据下进行微调的情况。
- 我们为不同的视觉任务设计了不同的可验证奖励,能够在几乎没有成本的情况下高效地计算高质量奖励。这使得DeepSeek R1风格的强化学习能够无缝转移到LVLMs中。
- 我们在各种视觉感知任务上进行了广泛的实验,包括细粒度图像分类、少样本物体检测、推理定位和开放词汇物体检测。在所有设置下,Visual-RFT取得了显著的性能提升,显著超越了监督微调的基线。
- 我们完全开源了训练代码、训练数据和评估脚本,托管在Github上,以促进进一步的研究。
2. 相关工作
大型视觉语言模型(LVLMs)
大型视觉语言模型(LVLMs)如GPT-4o通过整合视觉和文本数据,展现了出色的视觉理解能力。这种整合增强了模型理解复杂多模态输入的能力,使其能够处理图像和文本,从而推动更先进的AI系统的发展,这些系统能够同时处理和响应图像和文本。一般来说,LVLMs的训练包括两个步骤:(a)预训练和(b)后训练,其中后训练包含监督微调和强化学习。后训练对于提高模型的响应质量、指令跟随能力和推理能力至关重要。尽管已有大量研究使用强化学习来增强LLMs的后训练能力,但在LVLMs上取得的进展较慢。 在本文中,我们提出了Visual-RFT,使用基于GRPO的强化学习算法和可验证奖励,在后训练阶段增强模型的视觉感知和推理能力。
强化学习
近年来,随着像OpenAI的o1等推理模型的出现,研究焦点逐渐转向了通过强化学习(RL)技术提升大语言模型(LLMs)的推理能力。许多研究探讨了提升LLMs在推理任务中的表现,如解决数学问题和编程等。一个显著的突破是DeepSeek-R1-Zero,它通过仅使用强化学习消除了监督微调(SFT)阶段,从而获得了强大的推理能力。然而,当前关于基于RL的推理的研究主要集中在语言领域,且在多模态设置中的应用探索有限。对于LVLMs,RL主要用于减少幻觉并使模型与人类偏好对齐,但在增强大型视觉语言模型的推理和视觉感知能力方面仍存在显著的研究空白。 为填补这一空白,本文提出了一种新的强化学习微调策略——Visual-RFT,它结合了可验证奖励和基于GRPO的强化学习,应用于各种视觉感知任务。我们的目标是通过此方法在有限的微调数据下,改善LVLMs在处理各种视觉任务中的表现。
3. 方法
3.1. 初步
带可验证奖励的强化学习
带可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards - RLVR)是一种新的训练方法,旨在增强语言模型在任务中的表现,这些任务具有客观可验证的结果,如数学和编码。与之前依赖于训练奖励模型的基于人类反馈的强化学习(RLHF)不同,RLVR则使用直接的验证函数来评估正确性。这种方法简化了奖励机制,同时保持了与任务固有正确性标准的强一致性。给定输入问题 q q q,策略模型 π θ \pi_{\theta} πθ生成响应 o o o并接收可验证的奖励。更具体地,RLVR优化以下目标:
max π θ E o ∼ π θ ( q ) [ R RLVR ( q , o ) ] (1) \max_{\pi_{\theta}} \mathbb{E}_{o \sim \pi_{\theta}(q)}[R_{\text{RLVR}}(q, o)] \tag{1} πθmaxEo∼πθ(q)[RRLVR(q,o)](1)
= [ R ( q , o ) − β KL [ π θ ( o ∣ q ) ∥ π ref ( o ∣ q ) ] ] (2) = \left[ R(q, o) - \beta \text{KL}[\pi_{\theta}(o|q) \parallel \pi_{\text{ref}}(o|q)] \right] \tag{2} =[R(q,o)−βKL[πθ(o∣q)∥πref(o∣q)]](2)
其中, π ref \pi_{\text{ref}} πref是优化前的参考模型, R R R是可验证奖励函数, β \beta β是控制KL散度的超参数。可验证奖励函数 R R R将问题和输出对 ( q , o ) (q, o) (q,o)作为输入,并检查真实答案是否与预测 o o o一致:
R ( q , o ) = { 1 , if o = ground truth , 0 , otherwise . (3) R(q, o) = \begin{cases} 1, & \text{if } o = \text{ground truth}, \\ 0, & \text{otherwise}. \end{cases} \tag{3} R(q,o)={ 1,0,if o=ground truth,otherwise.(3)
250402:策略模型是一个概率分布,表示在某个状态下采取某个动作的概率;参考模型是一个在训练中用来作为对比的标准模型,通常是一个相对已知、经过验证的策略模型。在强化学习过程中,我们希望当前的策略与参考模型在选择动作的方式上尽量相似。KL散度(Kullback-Leibler Divergence)就是用来衡量两个概率分布之间差异的一个指标。
250402:这个公式就是最大化 模型得到的真实奖励 R ( q , o ) R(q, o) R(q,o) 减去 策略模型和参考模型的KL散度。
DeepSeek R1-Zero和GRPO
DeepSeek R1-Zero算法通过使用强化学习进行训练,特别是通过其群体相对策略优化(Group Relative Policy Optimization - GRPO)框架,消除了对监督微调(SFT)的依赖。与需要一个评论家模型来评估策略表现的强化学习算法(如PPO [30])不同,GRPO直接比较候选响应组,从而消除了对额外评论模型的需求。对于给定问题 q q q,GRPO首先从当前策略 π old \pi_{\text{old}} πold生成 G G G个不同的响应 { o 1 , o 2 , … , o G } \{o_1, o_2, \dots, o_G\} { o1,o2,…,oG}。然后,GRPO根据这些响应采取行动,并将获得的奖励表示为 { r 1 , r 2 , … , r G } \{r_1, r_2, \dots, r_G\} { r1,r2,…,rG}。通过计算它们的均值和标准差进行归一化,GRPO确定这些响应的相对质量:
A i = r i − mean ( { r 1 , r 2 , … , r G } ) std ( { r 1 , r 2 , … , r G } ) (4) A_i = \frac{r_i - \text{mean}(\{r_1, r_2, \dots, r_G\})}{\text{std}(\{r_1, r_2, \dots, r_G\})} \tag{4} Ai=std({ r1,r2,…,rG})ri−mean({ r1,r2,…,rG})(4)
其中, A i A_i Ai表示第 i i i个回答的相对质量。GRPO鼓励模型在组内对更好的回答给予较高的奖励值。
250402:这里不是很懂为什么要标准化,我感觉一个 Group 中,他们的奖励范围都是一样的呀,也就是在同一个量级上直接比较奖励不可以吗?
3.2. Visual-RFT
Visual-RFT的框架如图3所示。来自用户的多模态输入数据包括图像和问题。策略模型 π θ \pi_{\theta} πθ根据输入生成推理过程并输出一组响应。每个响应都通过可验证奖励函数来计算奖励。在对每个输出的奖励进行分组计算后,评估每个响应的质量,并用来更新策略模型。为了确保策略模型训练的稳定性,Visual-RFT使用KL散度来限制策略模型与参考模型之间的差异。我们将在3.2.1节进一步讨论如何为视觉任务设计可验证奖励,3.2.2节将讨论数据准备步骤。
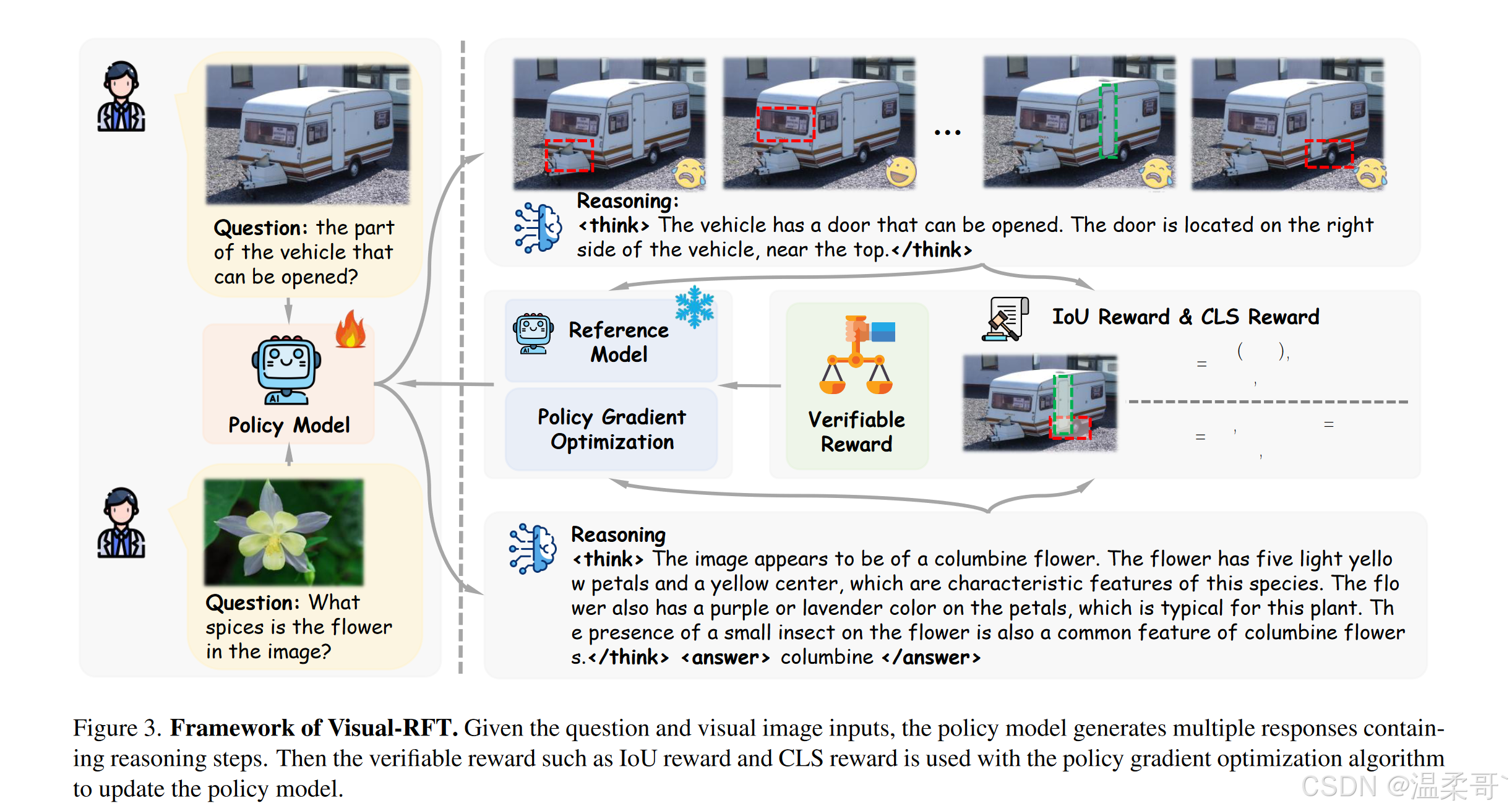
250402:现在还不是很懂,GRPO 中的参考模型指的是什么?
3.2.1. 视觉感知中的可验证奖励
奖励模型是强化学习(RL)中的关键步骤,用于将模型与偏好对齐算法对齐,奖励模型可以是一个简单的验证函数,用于检查预测与真实答案之间的精确匹配。在最近的DeepSeek-R1模型中,RL训练过程通过可验证奖励设计显著提升了模型的推理能力。为了将这一策略转移到视觉领域,我们为各种视觉感知任务设计了不同的基于规则的可验证奖励函数。
检测任务中的IoU奖励
对于检测任务,模型的输出包括边界框(bbox)及其对应的置信度。检测任务的奖励函数应充分考虑交并比(IoU)指标,该指标用于计算评估中的平均精度均值(mAP)。因此,我们设计了一个基于IoU和置信度的奖励函数 R d R_d Rd。首先,对于模型输出的边界框和置信度,我们根据置信度对这些框进行排序,记为 { b 1 , b 2 , . . . , b n } \{b_1, b_2, ..., b_n\} { b1,b2,...,bn}。然后我们将每个 b i b_i bi与真实边界框 { b 1 g , b 2 g , . . . , b m g } \{b_1^g, b_2^g, ..., b_m^g\} { b1g,b2g,...,bmg}进行匹配,并计算IoU,同时设定一个IoU阈值 τ \tau τ。IoU低于该阈值 τ \tau τ的边界框被视为无效,未匹配的边界框IoU为0。匹配完成后,我们得到初始集合中每个框的IoU和置信度,记为 { i o u 1 : c 1 , i o u 2 : c 2 , . . . , i o u n : c n } \{iou_1 : c_1, iou_2 : c_2, ..., iou_n : c_n\} { iou1:c1,iou2:c2,...,ioun:cn}。
接着,我们使用这些IoU结果和置信度来构建奖励 R d R_d Rd。我们的奖励 R d R_d Rd由三部分组成,包括IoU奖励、置信度奖励和格式奖励:
R d = R IoU + R conf + R format (5) R_d = R_{\text{IoU}} + R_{\text{conf}} + R_{\text{format}} \tag{5} Rd=RIoU+Rconf+Rformat(5)
IoU奖励 R IoU R_{\text{IoU}} RIoU是模型输出中所有边界框的平均IoU:
R IoU = i o u 1 + i o u 2 + ⋯ + i o u n n (6) R_{\text{IoU}} = \frac{iou_1 + iou_2 + \dots + iou_n}{n} \tag{6} RIoU=niou1+iou2+⋯+ioun(6)
置信度奖励 R conf R_{\text{conf}} Rconf与IoU相关。对于每个边界框,如果 i o u i iou_i ioui非零,表示成功匹配,则该框的置信度奖励 r c r_c rc根据预测的置信度计算如下:
r c i = { c i , if i o u i ≠ 0 , 1 − c i , if i o u i = 0. (7) r_{ci} = \begin{cases} c_i, & \text{if } iou_i \neq 0, \\ 1 - c_i, & \text{if } iou_i = 0. \end{cases} \tag{7} rci={ ci,1−ci,if ioui=0,if ioui=0.(7)
这意味着,对于成功匹配的框,置信度越高越好。如果 i o u i iou_i ioui为零,表示匹配失败,则该框的置信度奖励 r c r_c rc越低越好。模型输出的整体置信度奖励 R conf R_{\text{conf}} Rconf是该输出中所有边界框的置信度奖励的平均值:
R conf = ∑ i = 1 n r c i n . (8) R_{\text{conf}} = \frac{\sum_{i=1}^n r_{ci}}{n}. \tag{8} Rconf=n∑i=1nrci.(8)
格式奖励 R format R_{\text{format}} Rformat用于强制模型的预测符合要求的HTML标签格式,具体包括<think>和<answer>(将在3.2.2节详细说明)。
250402:IoU 的全称是 Intersection over Union,即交并比,用于衡量两个区域(例如,预测框和真实框)之间的重叠度。 I o U = O v e r l a p / U n i o n IoU=Overlap / Union IoU=Overlap/Union,即两个框重合的区域 比上 两个框所占的所有区域。
分类任务中的CLS奖励
在分类任务中,我们使用的奖励函数由两个部分组成:准确度奖励 R acc R_{\text{acc}} Racc和格式奖励 R format R_{\text{format}} Rformat。准确度奖励通过将模型的输出类别与真实类别进行比较来确定,对于正确分类,奖励为1,对于错误分类,奖励为0:
R cls = R acc + R format (9) R_{\text{cls}} = R_{\text{acc}} + R_{\text{format}} \tag{9} Rcls=Racc+Rformat(9)
3.2.2 数据准备
为了在各种视觉感知任务上训练Visual-RFT,我们需要构建多模态训练数据集。类似于DeepSeek-R1,为了增强模型的推理能力并应用这种能力来提升视觉感知,Visual-RFT设计了一个提示格式来指导模型输出推理过程,之后再给出最终答案。用于检测和分类任务的提示格式见表1。

在训练过程中,我们使用格式奖励来引导模型输出其推理过程和最终答案,并以结构化的格式呈现。推理过程是模型自我学习和在强化微调过程中不断改进的关键,而由答案决定的奖励则引导着模型的优化。
4. 实验
4.1. 实验设置
实现细节 我们的方法适用于各种视觉感知任务。我们采用少样本学习方法,提供给模型一个最小数量的样本进行训练。对于图像分类和物体检测任务,我们采用少样本设置来评估模型在有限数据下的细粒度区分和识别能力,并应用强化学习。然后,对于专注于推理定位的LISA数据集,我们进一步评估模型在推理能力方面的表现,该任务要求强大的推理能力。
接下来,我们使用Visual-RFT训练模型,并评估其推理和感知性能。最后,对于开放词汇物体检测任务,我们通过训练Qwen2-VL-2/7B模型(使用Visual-RFT)并在包含65个基础类别的COCO数据集子集上评估其泛化能力。然后,我们在COCO的15个新类别和来自LVIS的13个稀有类别上进行测试。模型的视觉感知和推理能力将在开放词汇检测设置中进行评估。在我们的检测实验中,我们首先提示模型检查图像中是否存在类别,然后预测图像中存在的类别的边界框。
4.2. 少样本分类
为了展示Visual-RFT在视觉领域的广泛泛化能力,我们进行了细粒度图像分类的少样本实验。我们选择了四个数据集:Flower102、Pets37、FGVC-Aircraft和Car196,这些数据集包含几十到几百个相似类别,增加了分类任务的难度。
如表2所示,仅使用一个样本数据,Visual-RFT就能显著提升性能(+24.3%)。相比之下,SFT在使用相同最小数据量时,表现明显下降(-4.3%)。在4样本设置下,SFT的性能仍略低于基线,而使用Visual-RFT进行强化微调的模型平均性能提升了25.9%。在8样本和16样本设置下,随着数据量的增加,SFT的性能略微超过基线。然而,SFT的表现仍显著落后于Visual-RFT的表现。如图4所示,我们展示了在细粒度分类任务中,经过强化微调的模型推理案例。这些结果不仅展示了Visual-RFT的强泛化能力及其从有限数据中学习的能力,还确认了与SFT相比,强化微调能更好地促进对任务的深刻理解和推理学习。


250402:不是吧,就一个样本就这么有效吗?
4.3. 少样本物体检测
少样本学习一直是传统视觉模型和大规模视觉-语言模型(LVLMs)面临的核心挑战之一。强化微调为该问题提供了新的解决方案,使模型能够在少量数据的情况下快速学习和理解。我们从COCO数据集中选择了8个类别,每个类别有1、2、4、8和16张图片,用于构建有限数据的训练集。对于LVIS数据集,我们选择了6个稀有类别。由于这些稀有类别的训练图像非常稀疏,每个类别的训练图像在1到10张之间,我们将其视为一个10-shot设置。然后,我们使用强化微调和SFT分别训练Qwen2-VL-2/7B模型200步,以评估模型在有限数据下的学习能力。
如表3和表4所示,尽管SFT和强化微调都能在少样本设置下提高模型的识别精度,但强化微调后的模型始终远超SFT模型,并保持显著的领先优势。在COCO类别上,随着训练数据的增加,SFT模型的平均mAP约为31,而强化微调后的模型接近47。在LVIS的少样本实验结果(见表4)中,针对LVIS中6个更具挑战性的稀有类别,强化微调仍然优于SFT。表3和表4中的结果清楚地展示了强化微调在少样本设置中的卓越表现,模型在有限数据下通过强化学习获得了视觉感知能力的显著提升,超越了SFT。


我们进一步在一些抽象的领域外数据集上进行测试。我们选择了MG(Monster Girls)数据集,该数据集包含不同类型的动漫风格怪物女孩。通过使用领域外数据,我们增加了模型识别和推理的难度,并在4-shot和16-shot设置下进行了实验。表5中的结果表明,强化微调实现了显著的性能提升,超越了传统的监督微调(SFT)。

4.4. 推理定位
视觉语言智能的另一个关键方面是根据用户需求定位精确的物体。之前的专门检测系统缺乏推理能力,无法完全理解用户的意图。由LISA开创的研究使得大型语言模型(LLMs)能够输出控制其他模型(如SAM)或通过监督微调直接预测边界框坐标的令牌。我们在这项工作中探索了在此任务中使用Visual-RFT,发现强化学习(RL)相比监督微调显著提高了性能。
我们使用Visual-RFT和监督微调(SFT)对Qwen2-VL 2B/7B模型进行微调,训练数据集为LISA数据集,包含239张带有推理定位物体的图像。我们采用相同的测试设置与LISA进行比较,评估SFT和我们的方法(均使用500步微调)。如表6所示,Visual-RFT在边界框IoU方面显著提高了最终结果,相较于SFT。此外,我们使用Qwen2-VL预测的边界框提示SAM模型生成分割掩码(使用IoU评估)。Visual-RFT显著增强了定位能力,并超越了先前的专门检测系统。

定性结果如图5所示,思考过程显著提高了推理能力和定位精度。通过Visual-RFT,Qwen2-VL学会批判性地思考,并仔细检查图像以产生准确的定位结果。

4.5. 开放词汇物体检测
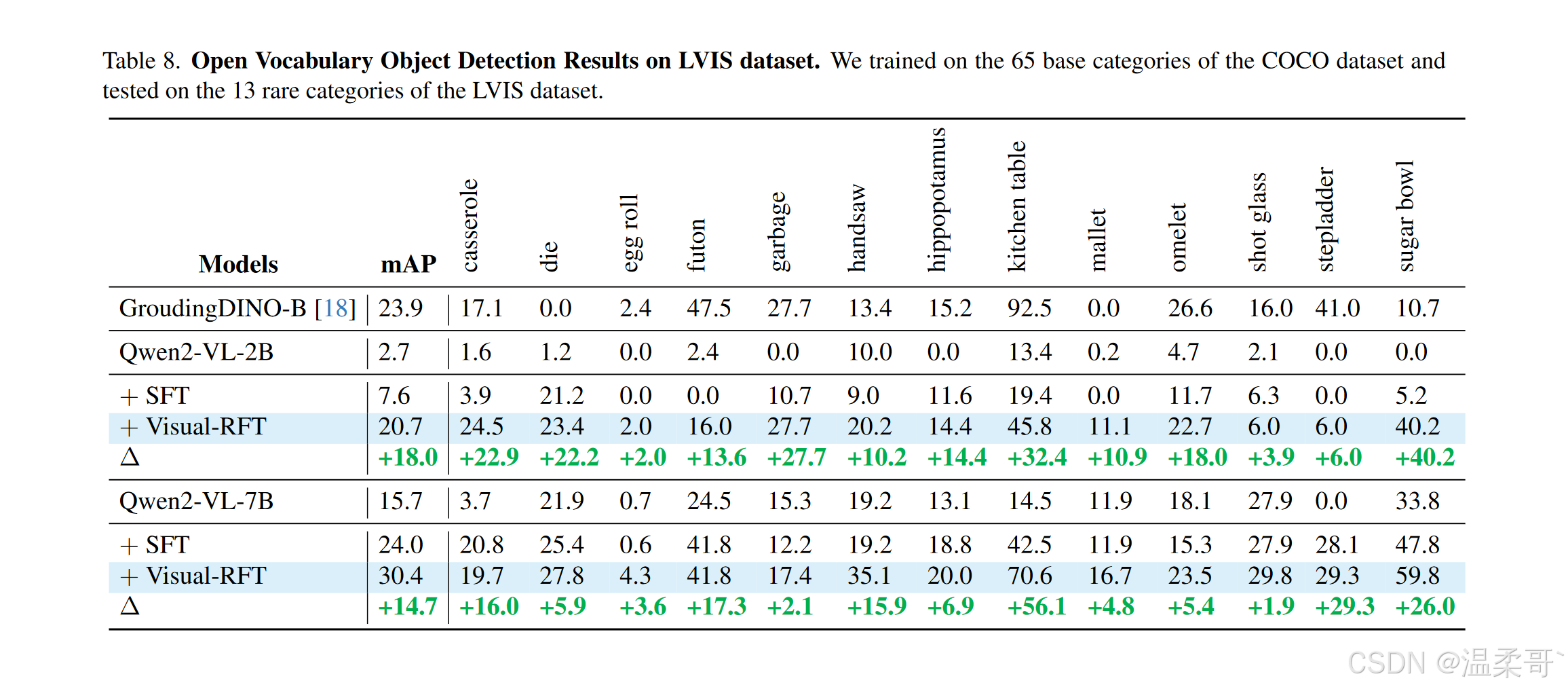
Visual-RFT相较于SFT的优势在于其对任务的真正深刻理解,而非仅仅记忆数据。为了进一步展示强化微调的强泛化能力,我们进行了开放词汇物体检测实验。我们首先从COCO数据集中随机采样了6K条注释,涵盖了65个基础类别。我们对Qwen2-VL-2/7B模型使用这些数据进行Visual-RFT和SFT微调,并测试该模型在15个之前未见过的新类别上的表现。为了增加难度,我们进一步测试了来自LVIS数据集的13个稀有类别。
如表7和表8所示,经过强化微调后,Qwen2-VL-2/7B模型在COCO数据集的15个新类别上取得了平均mAP提升21.5和9.5。在更具挑战性的LVIS稀有类别上,mAP分别提升了18.0和14.7。Visual-RFT不仅将其检测能力从COCO的基础类别转移到新的COCO类别,还在更具挑战性的LVIS稀有类别上取得了显著的改进。特别是,对于表8中一些稀有的LVIS类别,原始或经过SFT训练的模型无法识别这些类别,导致AP为0。然而,经过强化微调后,模型在识别这些先前无法识别的类别(如蛋卷和榻榻米)时,从0跃升至1。这证明了Visual-RFT在提升视觉识别的性能和泛化能力方面,对LVLMs有显著的影响。

5. 结论
在本文中,我们介绍了视觉强化微调(Visual-RFT),这是首个采用基于GRPO的强化学习策略来增强大型视觉-语言模型(LVLMs)视觉感知和定位能力的方法。通过使用基于规则的可验证奖励系统,Visual-RFT减少了对手动标注的需求,并简化了奖励计算,在各种视觉感知任务中取得了显著的改进。大量实验表明,Visual-RFT在细粒度分类、开放词汇检测、推理定位和少样本学习任务中表现优异。与监督微调(SFT)相比,Visual-RFT在最小数据下超越了SFT,并展现了强大的泛化能力。本研究展示了强化学习在增强LVLMs能力方面的潜力,使其在视觉感知任务中更加高效和有效。