【论文推荐|滑坡检测·空间预测·时间预测· 数据驱动的分析】机器学习在滑坡研究中的最新进展与应用(2022)(七)
【论文推荐|滑坡检测·空间预测·时间预测· 数据驱动的分析】机器学习在滑坡研究中的最新进展与应用(2022)(七)
文章目录
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可关注VX “
学术会议小灵通”或参考学术信息专栏:https://blog.csdn.net/2401_89898861/article/details/145551342
论文地址:https://doi.org/10.1007/s11069-022-05423-7
4 滑坡空间预测研究综述
4.1 因子分析
本阶段主要对研究区的专题信息(滑坡控制因子与滑坡清单)进行分析,并构建可用于机器学习(ML)模型的数据集。通常,为优化输入变量(特征)集,使其与输出变量(目标)相关联,本阶段采用经典统计方法。例如,Mergadi等(2020)将因子分析划分为两个步骤:从滑坡清单图与控制因子构建空间数据库;利用方差膨胀因子(VIF)与信息增益(IG)优化滑坡控制因子。类似方法亦见于其他研究,如Huang等(2020)采用频率比双变量统计分析定义输入-输出变量,Chen等(2020)则结合归一化频率比、方差膨胀因子与卡方检验进行因子分析。
在滑坡事件图构建方面,该图作为分析中的因变量,通常以二值栅格表示,其中L类单元由研究区内滑坡发生点定义,NL类单元通过随机选取无滑坡区域获得。滑坡控制因子(输入变量)可来自多源数据,如专题图、野外调查、报告及遥感影像,均需通过GIS工具处理,并转换为栅格单元值,以匹配分析分辨率。数据类型可为离散或连续,在用于ML分析前,可能需要进一步预处理,例如类别变量的数值编码,或将连续变量划分为有限数量的类别。Huang等(2020)指出,若划分类别过少,控制因子的分割过于粗略;若类别过多,则建模复杂度增加。目前尚无统一标准确定最优类别数,通常参考滑坡易发性评估领域的经验法则(如Guzzetti等,1999)。在本综述涉及的七项研究中,连续变量的类别数介于3–9之间,重分类方法包括自然断点、几何间隔、频率分析及启发式评估。类别划分的主观性可能对模型结果产生重要影响。
在建模前,一些研究利用统计分析方法优化训练与验证数据集的输入变量。常见的双变量统计方法,如频率比或信息增益比,可用于评估各控制因子的预测能力,并为每个类别分配权重系数,以量化变量与滑坡发生概率之间的关系。然而,这些控制因子可能存在多重共线性,因此,需进行预检,如使用容差或方差膨胀因子评估变量间的线性相关性(Dormann等,2013)。最终,输入变量通常归一化至[0,1]范围,以提高模型稳定性。
4.2 模型构建
本阶段的首要任务是划分训练集和测试集,以用于机器学习(ML)模型的训练及其精度验证。为了评估模型的预测能力,在训练完成后,应使用独立的数据集进行测试。滑坡预测模型的验证方法主要包括:
- (i)随机抽样建立模型,并利用剩余样本进行验证;
- (ii)采用不同规模的随机样本训练模型,分析函数系数的显著性变化;
- (iii)基于特定事件发生的滑坡数据构建模型,并使用后续事件触发的滑坡数据进行验证;
- (iv)在一个训练区构建模型,并在具有相似特征的目标区域测试其适用性。
其中,第一种方法被广泛应用于滑坡易发性评估研究,通常将超过 70% 的滑坡样本用于训练,其余用于测试,以保证测试数据独立性(Gholamy et al. 2018)。在数据量充足时,可适当提高测试集比例。此外,为避免滑坡(L)与非滑坡(NL)样本比例失衡,训练和测试过程中通常随机抽取等量的 NL 样本,但此方法可能引入其他偏差。交叉验证(CV)作为一种平衡速度、精度和计算成本的方法,近年来被广泛应用于滑坡易发性 ML 研究(Mergadi et al. 2020)。
- 目前,在区域尺度上尚无公认的最佳 ML 算法用于滑坡易发性预测,因为模型性能受算法本身、超参数调整、滑坡数据质量及环境因子的影响。
因此,大多数研究会在相同数据集上比较多个 ML 算法的表现。近年来,该领域研究数量快速增长。例如,在 Scopus 数据库(截至 2020 年 11 月 16 日)中,包含“landslide”和“machine learning”关键词的期刊论文共有 286 篇,其中 64% 研究 ML 在滑坡易发性建模中的应用。ML 研究的多样性较高,自 2010 年以来,支持向量机(SVM)、决策树(DT)和随机森林(RF)分别发表 342、247 和 179 篇相关论文(Mergadi et al. 2020)。尽管 ML 术语近年才被广泛使用,滑坡易发性预测的研究可追溯至 20 世纪 70 年代,如逻辑回归(LR)和人工神经网络(ANN)等方法在 2000 年以来分别发表 1587 和 746 篇论文(Mergadi et al. 2020)。

表 6 中的七项研究共采用了 23 种 ML 模型进行滑坡易发性绘制,每个研究区域对比 3 至 10 种算法(Chen et al. 2019; Mergadi et al. 2020),部分研究还对比了启发式和统计模型(Huang et al. 2020)。最常用的 ML 方法包括 SVM(5 次)、RF(4 次)、DT 和朴素贝叶斯(NB)(3 次),以及 ANN、BRT、CART、GLM 和 MLP-NN(2 次)。一些研究对多种 ML 算法进行了系统比较(Youssef et al. 2016; Pourghasemi and Rahmati 2018),另一些研究探索了混合集成方法(Pham and Prakash 2019)或较少被研究的模型(Chen et al. 2019)。深度学习神经网络(DLNN)也被引入并与 RF、SVM、DT 和 MLP-NN 进行对比(Bui et al. 2020a, b)。此外,Mergadi et al. (2020) 强调了统一的超参数优化策略对 ML 研究的重要性。
- 模型构建的最终目标是生成滑坡易发性分布图。
计算每个像素的滑坡易发性指数后,通常采用 3 到 6 级分类(Pham and Prakash 2019; Bui et al. 2020a, b)。最常见的是 4 级(Youssef et al. 2016)或 5 级分类(Chen et al. 2019; Huang et al. 2020; Mergadi et al. 2020),如“极低”“低”“中等”“高”“极高”易发性(Fell et al. 2008)。此外,部分研究(Bui et al. 2020a, b)增加了“无易发性”类别,以涵盖易发性指数极低的区域。
4.3 测试与验证
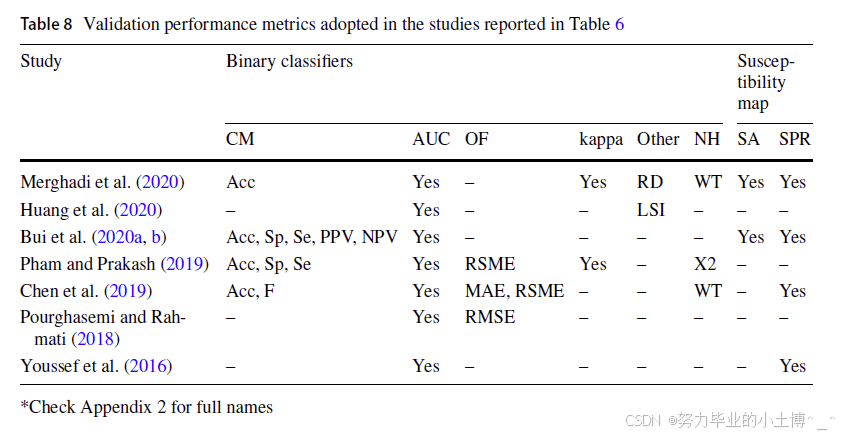
滑坡易发性计算模型的性能评估可分为两个层面(表 8):
- (1)基于二分类模型的滑坡存在/不存在结果,评估分类质量;
- (2)验证最终生成的滑坡易发性分布图,即通过对比滑坡密度分布与已建立的滑坡编目,评估各易发性等级区域的准确性。
分类精度评估
在第一层面的测试中,常用的性能评估指标包括:
- 混淆矩阵(CM) 相关指标,如总体准确率(Acc)、特异性(Sp)、敏感性(Se)、F1 分数(F)等;
- 受试者工作特征曲线(ROC)下面积(AUC),通过计算不同阈值下的假阳性率和真阳性率,获得其积分值;
- 误差评估,基于均值绝对误差(MAE)和均方根误差(RMSE)等目标函数(OF)量化分析误差;
- Cohen’s kappa 系数(Kappa),衡量预测结果与随机一致性之间的超额一致性;
- 可靠性图(RD)及滑坡易发性指数(LSI)分布,用于进一步评估预测模型的可靠性。
此外,在同一研究区域内对多个机器学习(ML)算法进行比较时,可采用 零假设检验(NH),如 Wilcoxon 符号秩检验(WT) 或 卡方检验(χ²),评估模型结果差异的统计显著性(表 6)。
易发性分布验证
- 第二层面的评估基于以下假设:当滑坡易发性等级从低到高变化时,滑坡密度比应逐步增加,同时高易发性区域的空间占比应较小(Pradhan & Lee, 2010)。
为实现这一目标,需要对机器学习算法计算的滑坡发生概率进行分类,划分为不同的易发性等级,并在滑坡易发性分布图中表示。随后,可通过 充分性分析(SA) 将各易发性等级的面积分布与滑坡编目的滑坡密度进行比对,以验证预测结果。此外,还可绘制 成功率曲线(SPR) 和 预测率曲线,并计算对应的 AUC 值,以进一步量化模型性能。
下节请参考:【论文推荐|滑坡检测·空间预测·时间预测· 数据驱动的分析】机器学习在滑坡研究中的最新进展与应用(2022)(八)