【论文推荐|滑坡检测·空间预测·时间预测· 数据驱动的分析】机器学习在滑坡研究中的最新进展与应用(2022)(六)
【论文推荐|滑坡检测·空间预测·时间预测· 数据驱动的分析】机器学习在滑坡研究中的最新进展与应用(2022)(六)
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可关注VX “
学术会议小灵通”或参考学术信息专栏:https://blog.csdn.net/2401_89898861/article/details/145551342
论文地址:https://doi.org/10.1007/s11069-022-05423-7
4 滑坡空间预测研究综述
滑坡空间预测旨在评估目标区域内未来滑坡的可能发生位置,而不考虑其发生时间及频率。基于数据驱动的方法,尤其是机器学习(ML)算法,广泛用于计算滑坡易发性,即某区域发生滑坡的概率(Brabb, 1984)。目前,统计方法和ML方法的应用基于两个关键假设(Varnes, 1984; Reichenbach et al., 2018; Lombardo et al., 2020):
- (i) 未来滑坡更可能发生在曾导致坡面失稳的环境条件下;
- (ii) 可采集的影响坡面失稳的因子可用于构建滑坡空间分布预测模型。
相较于传统统计分析,ML算法可直接学习滑坡发生与环境因子之间的关联,而无需预设数据结构模型。其核心在于通过迭代优化,自动提取数据中的潜在模式,而非依赖基础统计或人工观察(Korup & Stolle, 2014)。Mergadi等(2020)系统回顾了滑坡易发性研究中常用的ML技术,并指出仅少数研究者采用ML进行滑坡易发性制图。相关研究表明,采用神经网络(NN)、随机森林(RF)、决策树(DT)、支持向量机(SVM)等算法的文献分别占该领域论文的47%、70%、83%和86%。基于此,本文主要探讨这些研究者的最新成果,并比较不同ML技术的表现。
这些发现促使本节综述主要聚焦于上述研究者的最新成果,并对不同 ML 技术的对比分析展开讨论。此外,我们还参考了其他相关研究,包括:
- 变量重要性分析与预测图解读(Goetz et al., 2015);
- 空间自相关对超参数调整及模型性能的影响(Schratz et al., 2019);
- 训练/测试数据分辨率的混合影响(Duric et al., 2019);
- 多模型融合的创新方法(Di Napoli et al., 2020);
- 基于对象的预测方法,相较于传统栅格法具有更优性能(Wang et al., 2021a);
- 结合 ML 与主动学习(Active Learning)的方法(Wang & Brenning, 2021)。
本节讨论将综合以上研究成果,以确保全面评估 ML 在滑坡易发性预测中的应用。
表 6 统计了各研究采用的机器学习(ML)算法、研究区域及案例面积。Mergadi 等(2020)基于阿尔及利亚 2760 km² 研究区,对多种 ML 方法进行系统对比分析,并基于多项评估指标总结了算法的精度、优劣势。研究表明,树模型集成算法(如随机森林,RF)在滑坡易发性制图中表现优越,且模型训练所需参数调整较少。

所有列入 表 6 的研究均采用基于像素(pixel-based)的计算方法,即将研究区离散化为 GIS 环境中的规则网格(栅格),利用滑坡清单关联输入因子(如专题地图)与模型输出(滑坡易发性图,见 图 5)。尽管在 ML 语境下,输入变量通常称为“特征”(features),输出变量称为“目标”(target),但数据驱动的滑坡易发性分析原则保持一致。
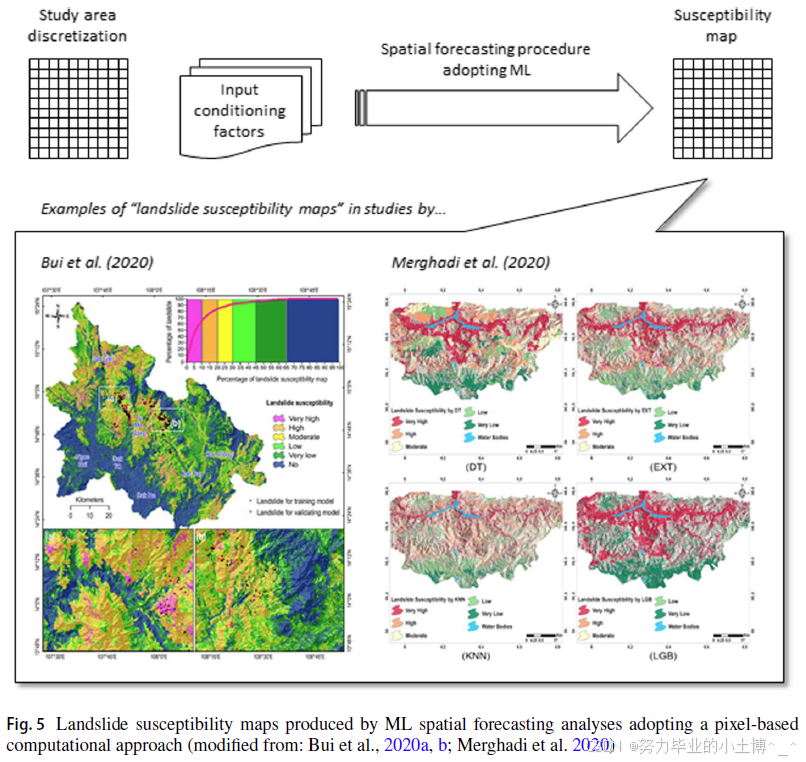
表 7 进一步汇总了各研究采用的滑坡易发性计算模型的核心信息,包括:
- (i)栅格分辨率,
- (ii)输入因子数量,
- (iii)滑坡数量及类型,
- (iv)ML 训练样本(滑坡/非滑坡单元数),
- (v)训练集与测试集数据比例,
- (vi)最终易发性图的分类数。
这些研究多采用 20 m × 20 m 至 30 m × 30 m 的中等分辨率像元。
地形因子的尺度选择(特别是基于 DEM 的地形变量)直接影响预测精度,但提高 DEM 分辨率并不必然提升模型表现(Guzzetti et al., 1999)。Chang 等(2019)指出,过高分辨率的 DEM 可能反映微地貌变化,而非与滑坡相关的中尺度过程,因此 30 m DEM 可能是较优选择,对应的最小可识别滑坡面积约 0.1 公顷(1 公顷 = 100 m × 100 m)。但另一方面,基于 LiDAR 或无人机(UAV)高分辨率数据下采样生成的 DEM,可在一定程度上提升易发性模型的精度。
在滑坡易发性分析中,研究普遍采用9至18个环境因子(conditioning factors),涵盖五大类:
- (i) DEM派生地形因子(高程、坡度、坡向、曲率等);
- (ii) 地貌因子(河流距离、排水密度、流能指数、地形湿度指数等);
- (iii) 地质因子(岩性、基岩深度、断层距离等);
- (iv) 土地利用与植被因子(NDVI、土地利用类型、太阳辐射等);
- (v) 其他因素(降雨量、道路距离等)。
因子选择需结合滑坡类型,确保研究对象的同质性,并利用可获取的滑坡编目与诱发机制相关的专题信息进行分析。
大多数研究聚焦于平移型和旋转型滑坡,覆盖从粘土—粉质土到块石等不同地质环境。ML模型训练时,采用滑坡编目数据的70–75%用于训练,剩余数据用于测试。所有研究均采用二元分类(滑坡区L vs. 非滑坡区NL),并在训练与测试阶段确保L与NL样本数量平衡,NL样本从无滑坡区域随机选取。部分研究仅使用滑坡中心点作为L样本,另一些研究使用整个滑坡区域,从而显著增加L样本数量。不同采样策略对滑坡易发性预测的影响可参考Dou等(2020)的讨论。
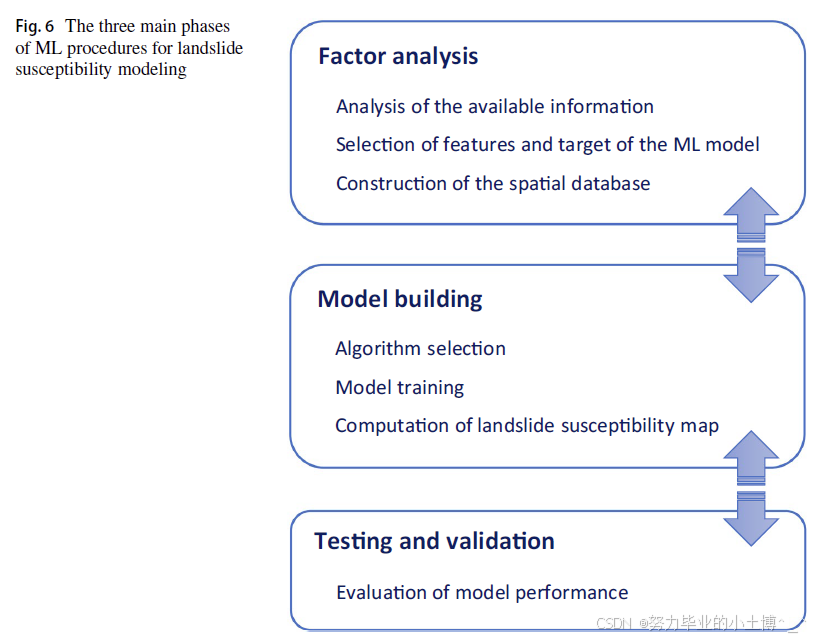
滑坡易发性图通过将计算出的易发性指数(susceptibility index)划分为3至6个等级,常见的5级分类包括“极低”、“低”、“中等”、“高”、“极高”(Fig. 6)。研究在构建空间数据库、生成滑坡易发性图及评估模型性能时,普遍遵循三个主要阶段:
- (i)因子分析(factor analysis),即选取并计算ML模型的输入输出变量;
- (ii)模型构建(model building),包括ML算法选择、参数校准及滑坡易发性图生成;
- (iii)测试与验证(testing and validation),评估模型表现。
这三个阶段依次进行,但通常包含子步骤与循环迭代,特别是在多个ML算法对比分析以确定最优滑坡易发性图时。
下节请参考:【论文推荐|滑坡检测·空间预测·时间预测· 数据驱动的分析】机器学习在滑坡研究中的最新进展与应用(2022)(七)