1.安装build wheel时报错:
The detected CUDA version (12.1) mismatches the version that was used to compile
PyTorch (11.7). Please make sure to use the same CUDA versions.
由于cuda版本和 当前虚拟环境中的pytorch-cudatoolkit版本不同,
解决:
安装好对应低版本cuda 11.7后,在当前命令行输入export CUDA_HOME=/usr/local/cuda-11.7
这样检测cuda版本时用的就是11.7版本,换一个窗口就需要重新export
2.解决tar (child): gzip: Cannot exec: Too many levels of symbolic links
解决:
原命令使用tar xjf 解压lib.tar.bz2文件到指定目录
新命令:先用bunzip解压,在tar解压,分为两部

若是出现ar (child): lbzip2: Cannot exec: no such file …
则是没安装lbzip2,使用sudo spt安装
3.apt无法解析域名,浏览器不能上网,网卡未启动
解决:
- 先输入>ifconfig 查看发现只有lo网卡,没有ens33或eth0网卡,
- 网卡重启 sudo service network-manager restart不能解决
- ifconfig ens33 up启动网卡,发现没有ip,
- 更新IP sudo dhclient ens33(网卡名字)
4.使用yolov10不能resume,即不能从上一次断点继续训练:
解决:在model.py中
1.注释掉
self.model = self.trainer.model
2.在trainer.py中resume_trainning加入ckpt = torch.load(‘./runs/detect/train15/weights/last.pt’)

3.check_resume函数中将原来的#resume = self.args.resume 改为resume=‘./runs/detect/train15/weights/last.pt’

4.改完这三个运行成功后记得改回去,否则影响后续重新训练模型
5.有高版本cuda,安装低版本cuda,如有12.1,安装cuda11.3
解决:在nvidia官网下载runfile文件运行

1.continue回车

2.输入accept

3.只保留CUDA Tookit 11.3其余使用回车取消

4.选择option回车,选择Tool kit 菜单,全部回车取消,结束后选择Done返回上一级

5.选择步骤3中的install,回车,等待安装结束,此时/usr/local中有cuda-11.3即为安装成功

6. luckfox将LCD使用framebuffer驱动LCD不能生成/dev/fb0
###解决:设备树中,SPI 配置需要禁用spidev@0,否则fb无法进行初始化。
dts设备树部分:
&spi0 {
status = "okay";
pinctrl-names = "default";
pinctrl-0 = <&spi0m0_cs0 &spi0m0_pins>;
spidev@0 {
//这三行不能少
status = "disabled";
};
st7789v@0{
status = "okay";
compatible = "sitronix,st7789v";
reg = <0>;
spi-max-frequency = <20000000>;
fps = <30>;
buswidth = <8>;
debug = <0x7>;
led-gpios = <&gpio2 RK_PB0 GPIO_ACTIVE_LOW>;//BL
dc = <&gpio2 RK_PB1 GPIO_ACTIVE_HIGH>; //DC
reset = <&gpio1 RK_PC3 GPIO_ACTIVE_LOW>; //RES
};
};
&pinctrl {
spi0 {
/omit-if-no-ref/
spi0m0_pins: spi0m0-pins {
rockchip,pins =
/* spi0_clk_m0 */
<1 RK_PC1 4 &pcfg_pull_none>,
/* spie_miso_m0 */
// <1 RK_PC3 6 &pcfg_pull_none>,
/* spi_mosi_m0 */
<1 RK_PC2 6 &pcfg_pull_none>;
};
};
};
7. mmdetection多GPU运行时报错’DataContainer ’ is not a subscript
步骤:
1.注释加载预训练模型,未解决

2.pip install onnx未解决,export CUDA_HOME=/usr/local/cuda11-3未解决
3.python tools/misc/print_config.py 查看mmcv版本1.5.3
安装mmcv-full==1.6.0解决
8.zsh提示zsh: corrupt history file /home/b607/.zsh_history不能使用
解决:
- 使用bash命令进入普通界面
- cd ~
- mv .zsh_history .zsh_history_bad
- strings .zsh_history_bad > .zsh_history
- zsh
- 正常运行不报错
9.Permissions 0755 for ‘/etc/ssh/ssh_host_ed25519_key’ are too open.
解决:chmod 600 文件,减少权限
10,c++程序报错:{”: 缺少函数标题(是否是老式的形式表?)
解决:一般是函数没正确声明,看看声明后面有没有多了或者少了声明,如果都不是,可能是换行符的问题:由LF改为CRLF
11.QtCreator报错
需要设置一个不同的镜像
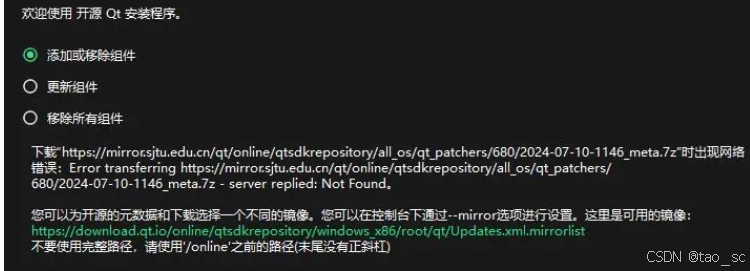
解决:意思是想要换镜像了,解决如下:
(把MaintenanceTool关闭,cmd进入其当前目录,输入合适的镜像地址)
MaintenanceTool.exe --mirror https://mirror.nju.edu.cn/qt