目录

一、引言
卷积神经网络(Convolutional Neural Networks, CNNs)是一种深度学习模型,广泛应用于计算机视觉任务中,尤其是在图像分类和物体识别方面。与传统的全连接神经网络相比,CNNs 通过引入局部连接、权重共享和池化层等机制,能够有效捕捉图像中的空间特征,从而提升模型的性能和计算效率。
本实验旨在利用卷积神经网络构建一个图像分类模型,以识别手写数字数据集 MNIST(Modified National Institute of Standards and Technology)。MNIST 数据集包含 70,000 张 28x28 像素的灰度手写数字图像,涵盖从 0 到 9 的十个类别。由于其规模适中且相对简单,MNIST 数据集成为深度学习研究和教学中常用的基准数据集。
二、实验目的
- 理解卷积神经网络的原理:掌握卷积层、池化层、全连接层等 CNN 结构的功能和作用,了解其在特征提取和分类中的应用。
- 构建 CNN 模型:设计一个有效的卷积神经网络架构,能够处理 MNIST 数据集中的手写数字图像,并实现数字分类任务。
- 训练与优化模型:通过使用合适的损失函数和优化算法,训练模型并调整超参数,以提高分类准确率。
- 评估模型性能:利用准确率、混淆矩阵等指标,评估模型在 MNIST 数据集上的分类效果,并与其他基准算法进行对比分析。
- 掌握深度学习工具:熟悉使用深度学习框架(如 TensorFlow 或 PyTorch)进行模型构建、训练和评估的过程,提升实践能力。
- 探索卷积神经网络的扩展:在实验基础上,探索更复杂的 CNN 架构或数据增强技术,进一步提升模型性能。
三、实验前准备
- 安装搭建pytorch环境,可参考 PyTorch安装教程_pytorch 安装-CSDN博客
- 熟悉python语法;
- 熟悉相关深度学习知识;
四、卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN)是一种在计算机视觉领域取得了巨大成功的深度学习模型。它们的设计灵感来自于生物学中的视觉系统,旨在模拟人类视觉处理的方式。在过去的几年中,CNN已经在图像识别、目标检测、图像生成和许多其他领域取得了显著的进展,成为了计算机视觉和深度学习研究的重要组成部分。
卷积神经网络的结构与其他的神经网络相似也包含输入层、隐含层和输出层。卷积神经网络的输入层可以处理多维数据,常见地,一维卷积神经网络的输入层接收一维或二维数组,其中一维数组通常为时间或频谱采样;二维数组可能包含多个通道;二维卷积神经网络的输入层接收二维或三维数组;三维卷积神经网络的输入层接收四维数组。由于卷积神经网络在计算机视觉领域应用较广,因此许多研究在介绍其结构时预先假设了三维输入数据,即平面上的二维像素点和RGB通道。
卷积神经网络的隐含层包含卷积层、池化层和全连接层3类常见构筑,在一些更为现代的算法中可能有Inception模块、残差块(residual block)等复杂构筑。在常见构筑中,卷积层和池化层为卷积神经网络特有。卷积层中的卷积核包含权重系数,而池化层不包含权重系数,因此在文献中,池化层可能不被认为是独立的层。
- 卷积
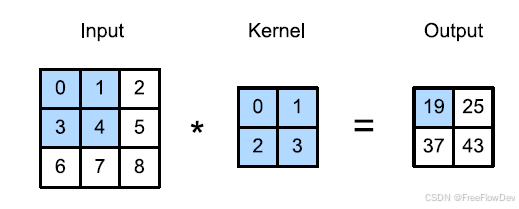
- 池化
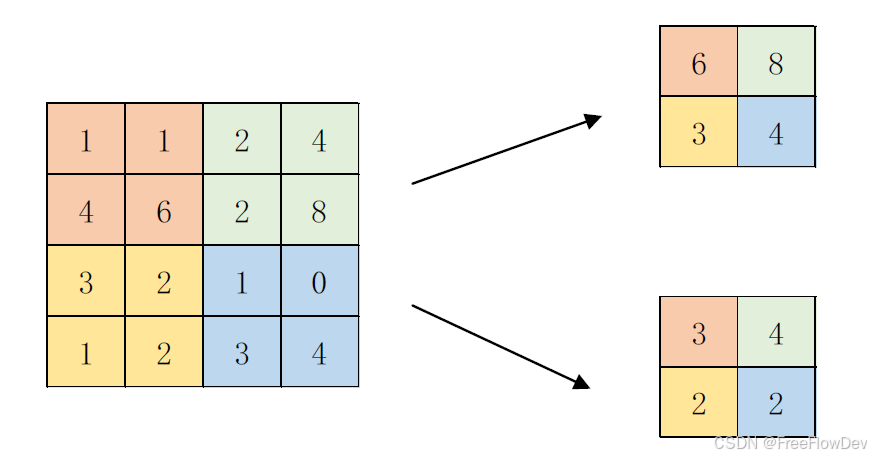
五、实验过程
1.数据下载
使用 torchvision.datasets 导入 MNIST 数据集。在使用 PyTorch 进行模型训练时,首先需要准备好数据集。对于手写数字识别任务,我们使用 MNIST 数据集。MNIST 数据集包含 70000 张 28x28 像素的灰度图像,分为 60000 张训练图像和 10000 张测试图像。
1.from torchvision import datasets, transforms
2.from torch.utils.data import DataLoader
3.#导入训练集
4.trainDataset =datasets.MNIST(root=r'./data',
5. transform=transforms.ToTensor(),
6. train=True,
7. download=True)
8.#导入测试集
9.testDataset =datasets.MNIST(root=r'data',#数据集路径
10. transform=transforms.ToTensor(),
11. train=False,
12. download=True)
13.#加载训练集
14.trainDataLoader =DataLoader(dataset=trainDataset,#加载训练姐
15. batch_size=32, # 批尺寸大小
16. shuffle=True) # 数据集打乱
17.#加载测试集
18.testDataLoader =DataLoader(dataset=testDataset,
19. batch_size=32,
20. shuffle=True) 运行程序后,在根目录下能看到data数据集
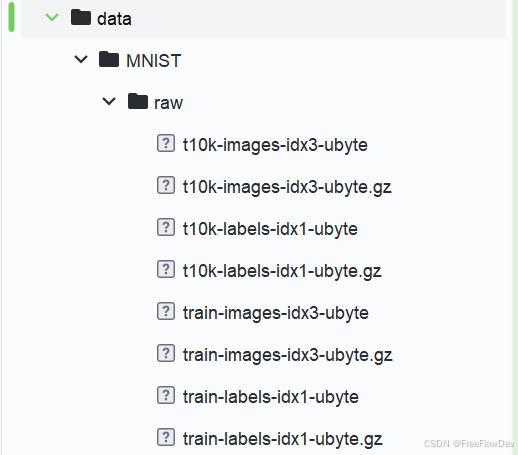
2.构建深度学习网络,训练模型
定义下采样块(Downsample_block):
1.class Downsample_block(nn.Module):
2. def __init__(self, in_channels, out_channels):
3. super(Downsample_block, self).__init__()
4. self.conv1 = nn.Conv2d(in_channels, out_channels, 3, padding=1)
5. self.bn1 = nn.BatchNorm2d(out_channels)
6. self.conv2 = nn.Conv2d(out_channels, out_channels, 3, padding=1)
7. self.bn2 = nn.BatchNorm2d(out_channels)
8.
9. def forward(self, x):
10. x = F.relu(self.bn1(self.conv1(x)))
11. x = F.relu(self.bn2(self.conv2(x)))
12. x = F.max_pool2d(x, 2, stride=2)
13. return x Downsample_block 是一个用于特征提取的模块,包含两个卷积层和批量归一化层,并通过最大池化层实现下采样。
定义简单的卷积神经网络(SimpleCNN):
1.class SimpleCNN(nn.Module):
2. def __init__(self):
3. super(SimpleCNN, self).__init__()
4. self.layer1 = Downsample_block(1, 32)
5. self.layer2 = Downsample_block(32, 64)
6. self.fc1 = nn.Linear(64 * 7 * 7, 128)
7. self.fc2 = nn.Linear(128, 10)
8.
9. def forward(self, x):
10. x = self.layer1(x)
11. x = self.layer2(x)
12. x = x.view(x.size(0), -1) # 展平为1维
13. x = F.relu(self.fc1(x))
14. x = self.fc2(x)
15. return x SimpleCNN 是整个网络的结构,它由两个下采样层和两个全连接层组成。
数据预处理和加载:
1.transform = transforms.ToTensor()
2.
3.trainDataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
4.testDataset = datasets.MNIST(root='./data', train=False, transform=transform, download=True)
5.
6.trainDataLoader = DataLoader(dataset=trainDataset, batch_size=32, shuffle=True)
7.testDataLoader = DataLoader(dataset=testDataset, batch_size=32, shuffle=False) - transform = transforms.ToTensor():将输入数据转换为张量格式,这样可以更方便地用于模型训练。
- trainDataset 和 testDataset:分别加载 MNIST 数据集的训练集和测试集。
- trainDataLoader 和 testDataLoader:使用 DataLoader 将数据集包装为可迭代的对象,支持批处理(batching)和随机打乱(shuffling)训练数据。
实例化模型、损失函数和优化器:
1.model = SimpleCNN()
2.criterion = nn.CrossEntropyLoss() # 对于分类任务,使用交叉熵损失
3.optimizer = optim.Adam(model.parameters(), lr=0.001)- 实例化模型 model 为 SimpleCNN。
- 使用交叉熵损失函数 nn.CrossEntropyLoss() 作为损失计算方法,这是分类任务中常用的损失函数。
- 使用 Adam 优化器 optim.Adam(),其学习率设置为 0.001,用于优化模型的参数。
训练过程:
1.for epoch in range(10): # 训练10个周期
2. model.train()
3. running_loss = 0.0
4. for input_x, label in trainDataLoader:
5. optimizer.zero_grad() # 梯度清零
6. output = model(input_x) # 前向传播
7. loss = criterion(output, label) # 计算损失
8. loss.backward() # 反向传播
9. optimizer.step() # 更新参数
10.
11. running_loss += loss.item()
12.
13. print(f"Epoch [{epoch+1}/10], Loss: {running_loss/len(trainDataLoader):.4f}") - 训练循环遍历 10 个周期。
- model.train() 将模型设置为训练模式。
- 在每个批次中,清零梯度,进行前向传播,计算损失,执行反向传播,并更新模型参数。
- running_loss 用于累计每个周期的损失,并在每个周期结束时打印平均损失。
保存模型、测试模型性能:
1.torch.save(model.state_dict(), 'model.pth')
2.model.eval()
3.correct = 0
4.total = 0
5.with torch.no_grad():
6. for input_x, label in testDataLoader:
7. output = model(input_x)
8. _, predicted = torch.max(output.data, 1)
9. total += label.size(0)
10. correct += (predicted == label).sum().item()
11.
12.print(f'Accuracy on the test set: {100 * correct / total:.2f}%') - 将模型设置为评估模式 model.eval()。
- 通过 torch.no_grad() 禁用梯度计算,以减少内存使用和加快计算。
- 遍历测试数据集,获取模型的输出并计算预测结果,统计正确分类的样本数量。
- 最后输出模型在测试集上的准确率。
运行结果:
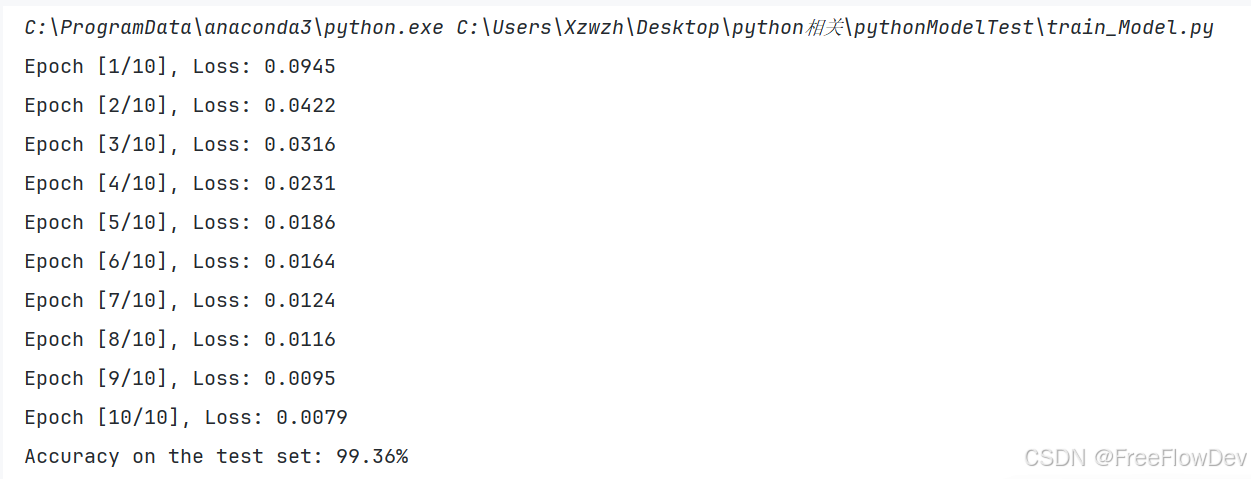
输出模型准确率99.36%,并生成模型。
3.模型推理
1.import os
2.import torch
3.from torchvision import transforms
4.from PIL import Image
5.from sklearn.metrics import accuracy_score, recall_score
6.from train_Model import SimpleCNN # 导入模型
7.
8.# 设置设备
9.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
10.
11.# 实例化模型并加载训练好的权重
12.model = SimpleCNN().to(device)
13.model.load_state_dict(torch.load('model.pth', map_location=device, weights_only=True))
14.model.eval()
15.
16.# 数据预处理
17.transform = transforms.Compose([
18. transforms.Grayscale(),
19. transforms.Resize((28, 28)),
20. transforms.ToTensor(),
21. transforms.Normalize((0.1307,), (0.3081,))
22.])
23.
24.# 预测单张图片的函数
25.def predict_image(image_path):
26. image = Image.open(image_path).convert('L') # 确保是灰度图
27. image = transform(image).unsqueeze(0).to(device) # 增加批次维度
28. with torch.no_grad():
29. output = model(image)
30. _, predicted = torch.max(output, 1)
31. return predicted.item()
32.
33.# 假设你的图片存放在 'images' 文件夹中
34.image_folder = 'images'
35.
36.all_true_labels = []
37.all_predicted_labels = []
38.
39.for filename in os.listdir(image_folder):
40. if filename.endswith(".png") or filename.endswith(".jpg"):
41. image_path = os.path.join(image_folder, filename)
42. try:
43. true_label = int(filename[-5]) # 根据文件名提取真实标签
44. all_true_labels.append(true_label)
45. prediction = predict_image(image_path)
46. all_predicted_labels.append(prediction)
47. print(f'Image {filename} is predicted as: {prediction}')
48. except (IndexError, ValueError) as e:
49. print(f"Error processing '{filename}': {e}. Skipping.")
50.
51.# 计算准确率和召回率
52.if all_true_labels and all_predicted_labels:
53. accuracy = accuracy_score(all_true_labels, all_predicted_labels)
54. recall = recall_score(all_true_labels, all_predicted_labels, average='macro', zero_division=1)
55. print(f'Overall Accuracy: {accuracy:.4f}, Overall Recall: {recall:.4f}')
56.else:
print("No valid labels to calculate accuracy and recall.") 六、实验结果与分析

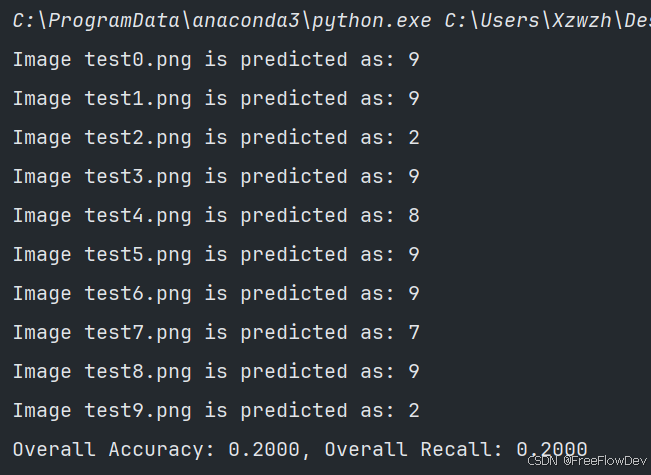
通过预测推理,得到如上图所示结果,发现准确率只有20%,图像识别不准确。分析原因:可能是训练的数据量不够大,也可能是传入的照片不过标准,模型训练参数不太准确,导致模型结果不尽人意。(可自行将数字截图进行预测检验)