欢迎回来朋友们,废话不多说,今天带来王林教授团队的编写的3DGS综述-Recent Advances in 3D Gaussian Splatting。如果觉得本文帮到您的话,麻烦顺手点个赞吧。
1.Abstract
三维高斯溅射(3DGS)的出现极大地加快了新视图合成的渲染速度。与神经辐射场(NeRF)等神经隐式表示方法不同,神经隐式表示方法使用基于位置和视角条件的神经网络来表示三维场景,而三维高斯溅射则利用一组高斯椭球体对场景进行建模,这样就可以通过将高斯椭球体光栅化为图像来实现高效渲染。这里只展示3DGS的总体概述,具体细节请参阅我的往期博客三维高斯溅射(3D Gaussian Splatting,3DGS)-CSDN博客
本篇综述旨在帮助初学者快速进入该领域,并为有经验的研究人员提供全面的概述,从而推动三维高斯溅射表示法在未来的发展。
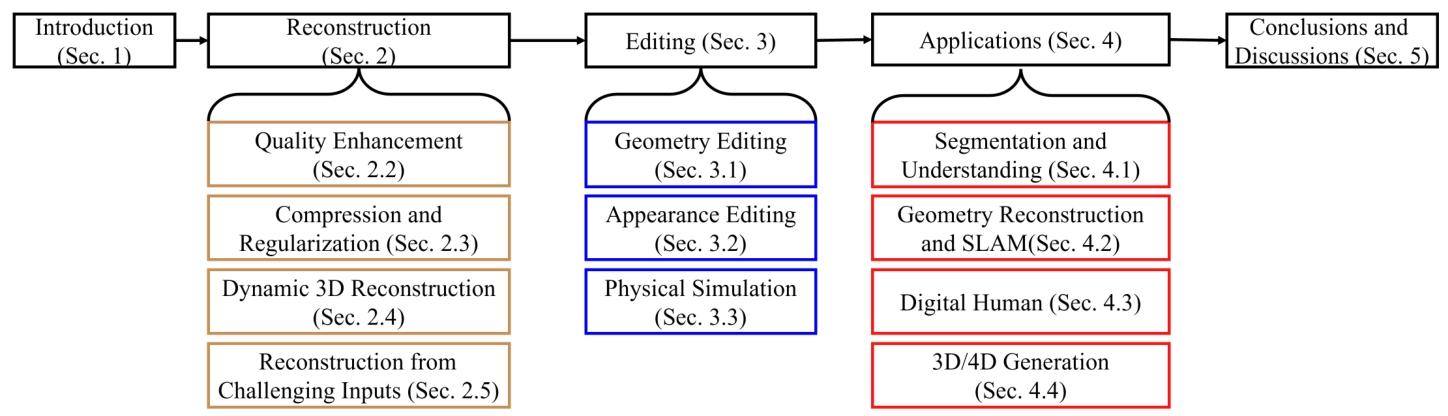
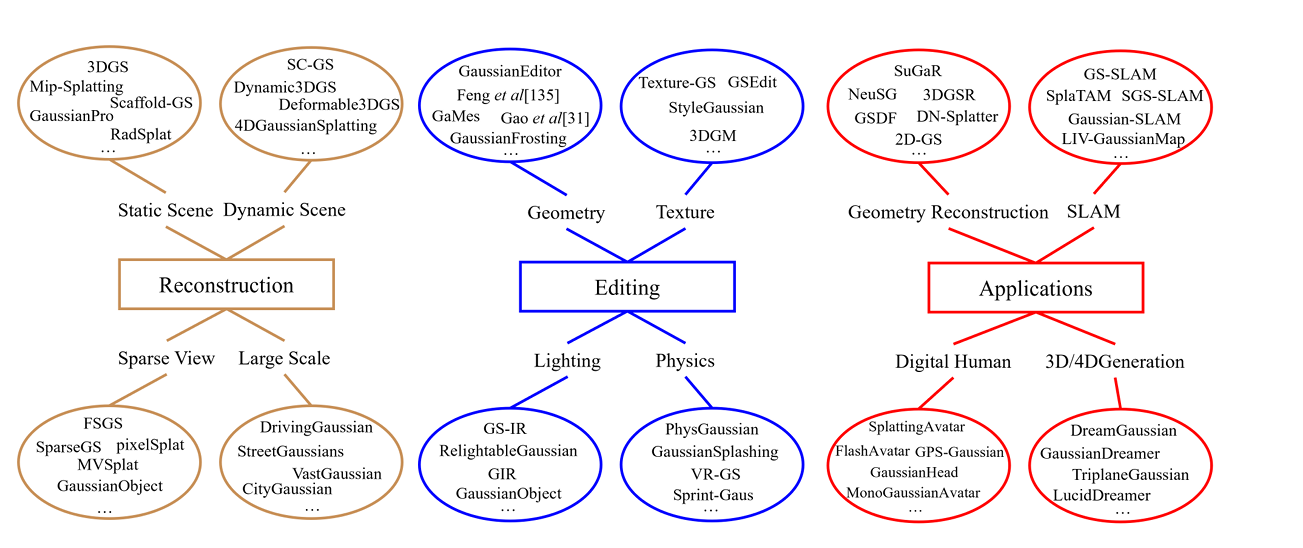
本篇综述根据功能将这些研究成果分为三个部分。
1.介绍三维高斯溅射如何在各种场景下实现逼真的场景重建。
2.介绍使用三维高斯溅射的场景编辑技术以及三维高斯溅射如何使诸如数字人之类的下游应用成为可能。
3.从更高层面总结了近期关于三维高斯溅射的研究成果,并提出了该领域有待开展的未来研究工作。
下图为本篇综述的总览图
2.Gaussian Splatting for 3D Reconstruction
2.1 Point-based Rendering
基于点的渲染技术旨在通过渲染一组离散的几何基元来生成逼真的图像。Grossman和Dally提出了基于纯基于点表示的基于点的渲染技术(the point-based rendering technique based on the purely point-based representation),在这种技术中,每个点仅影响屏幕上的一个像素。Zwicker等人没有采用渲染点的方式,而是提出渲染喷绘片(椭球体),这样每个喷绘片可以占据多个像素,并且它们之间的相互重叠相比纯基于点的表示法更容易生成无孔洞的图像。后来,一系列的喷绘方法旨在通过引入用于抗锯齿渲染的纹理过滤器、提高渲染效率以及解决不连续着色问题来对其进行改进。
传统的基于点的渲染方法更多地关注如何在给定几何形状的情况下生成高质量的渲染结果。随着近期隐式表示方法的发展,研究人员开始探索在没有任何给定几何形状的情况下,结合神经隐式表示来进行基于点的渲染,以完成三维重建任务。一个具有代表性的成果是神经辐射场(NeRF),它使用一个隐式密度场对几何形状进行建模,并通过另一个外观场来预测与视角相关的颜色ci。基于点的渲染通过以下方式将相机光线上所有采样点的颜色进行组合,从而生成一个像素颜色c。
为了加快训练和渲染速度,三维高斯溅射(3D Gaussian Splatting)没有使用神经网络来预测所有采样点的密度值和颜色,而是摒弃了神经网络,直接优化高斯椭球体。这些高斯椭球体附有诸如位置P、旋转R、缩放S、不透明度α以及表示与视角相关颜色的球谐系数(SH)等属性。像素颜色由从给定视角投影到该像素上的高斯椭球体决定。三维高斯椭球体的投影可以表示为:
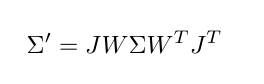
其中,∑′ 和 ∑=RSSTRT 分别是三维高斯椭球体和从具有视图变换矩阵W的视角投影到二维图像上的高斯椭球体的协方差矩阵,J是投影变换的雅可比矩阵。三维高斯溅射(3DGS)与神经辐射场(NeRF)的渲染过程类似,但它们之间有两个主要区别:
1.三维高斯溅射(3DGS)直接对不透明度值进行建模,而神经辐射场(NeRF)则是将密度值转换为不透明度值。
2.三维高斯溅射(3DGS)采用基于光栅化的渲染方式,这种方式无需对采样点进行采样,而神经辐射场(NeRF)则需要在三维空间中进行密集采样。
由于无需进行采样点操作以及查询神经网络,三维高斯溅射(3DGS)的速度变得极快,并且能在普通设备上达到约 30 帧 / 秒的帧率,同时其渲染质量可与神经辐射场(NeRF)相媲美。
2.2 Quality Enhancement
尽管 3DGS(三维高斯溅射)能够生成高质量的重建结果,但其渲染方面仍存在改进空间。
2.2.1.The Aliasing Problem(混叠问题)
1.Mip-Splatting作者观察到,改变采样率,例如改变焦距,会通过引入高频类高斯形状伪影或强烈的膨胀效应,极大地影响渲染图像的质量。为了消除高频类高斯形状伪影,Mip-Splatting 方法 将三维表示的频率限制在由训练图像确定的最大采样频率的一半以下。此外,为了避免膨胀效应,它引入了另一个二维 Mip 滤波器,对投影的高斯椭球体进行处理,以近似于类似于 EWA-Splatting 方法中的盒式滤波器。具体细节可参阅我的往期博客:Mip-Splatting: Alias-free 3D Gaussian Splatting(多尺度点云溅射)-CSDN博客
2.MS3DGS 方法同样旨在解决原始 3DGS 中的混叠问题,并引入了一种多尺度高斯溅射表示。当以新的分辨率级别渲染场景时,它从不同的尺度级别中选择高斯分布,以生成无混叠的图像。解析溅射方法 使用逻辑函数来近似高斯分布的累积分布函数,以便更好地为抗混叠对每个像素的强度响应进行建模。
论文地址:[2311.17089] Multi-Scale 3D Gaussian Splatting for Anti-Aliased Rendering
3.SA-GS 方法在测试时根据渲染分辨率和相机距离使用自适应的二维低通滤波器。
论文地址:[2403.19615] SA-GS: Scale-Adaptive Gaussian Splatting for Training-Free Anti-Aliasing
2.2.2.the capability of render- ing view-dependent effects(渲染与视角相关效果的能力)
1.为了生成更逼真的与视角相关的效果,VDGS提议对 3DGS 进行建模,以表示三维形状,并使用类似于神经辐射场(NeRF)的神经网络来预测与视角相关的颜色和不透明度等属性,而不是像原始 3DGS 那样使用球谐(SH)系数。
论文地址:[2312.13729] Gaussian Splatting with NeRF-based Color and Opacity
2.Scaffold - GS提议初始化一个体素网格,并将可学习的特征附加到每个体素点上,高斯分布的所有属性由插值特征和轻量级神经网络来确定。
论文地址:
[2312.00109] Scaffold-GS: Structured 3D Gaussians for View-Adaptive Rendering
3.基于 Scaffold - GS,Octree - GS引入了一种细节层次策略,以便更好地捕捉细节。
论文地址:[2403.17898] Octree-GS: Towards Consistent Real-time Rendering with LOD-Structured 3D Gaussians
4.StopThePop没有改变与视角相关的外观建模方法,而是指出由于每条光线的深度排序,3DGS 倾向于通过弹出三维高斯分布来 “伪造” 与视角相关的效果,这导致在旋转视角时结果不够逼真。为了减轻弹出三维高斯分布的可能性,StopThePop用基于图块的排序取代了每条光线的深度排序,以确保在局部区域内排序顺序的一致性。
论文地址:[2402.00525] StopThePop: Sorted Gaussian Splatting for View-Consistent Real-time Rendering
5.GaussianPro引入了一种渐进传播策略,通过考虑相邻视图之间的法线一致性并添加平面约束来更新高斯分布。
论文地址:[2402.14650] GaussianPro: 3D Gaussian Splatting with Progressive Propagation
6.GeoGaussian提议在高斯分布的切平面上对高斯进行加密,并促进相邻高斯之间几何属性的平滑过渡。
论文地址:[2403.11324] GeoGaussian: Geometry-aware Gaussian Splatting for Scene Rendering
7.RadSplat 用训练好的神经辐射场导出的点云来初始化 3DGS,并通过多视图重要性得分对高斯进行裁剪。
8.Spec - Gaussian提议使用各向异性球面高斯来近似三维场景的外观。
论文地址:[2402.15870] Spec-Gaussian: Anisotropic View-Dependent Appearance for 3D Gaussian Splatting
9.TRIPS将一个神经特征附加到高斯分布上,并根据投影高斯的大小渲染类似金字塔的图像特征平面,以解决原始 3DGS 中的模糊问题。
论文地址:[2401.06003] TRIPS: Trilinear Point Splatting for Real-Time Radiance Field Rendering
10.同样是处理该问题,FreGS对渲染的二维图像应用频域正则化,以促进高频细节的恢复。
论文地址:[2403.06908] FreGS: 3D Gaussian Splatting with Progressive Frequency Regularization
11.GES利用广义正态分布(NFD)来锐化场景边缘。
论文地址:arxiv.org/abs/2402.10128v2
12.为了解决 3DGS 对初始化敏感的问题,RAIN - GS提议从结构光运动(SfM)点云以大方差稀疏地初始化高斯分布,并逐步应用低通滤波,以避免二维高斯投影小于一个像素。
论文地址:[2403.09413] Relaxing Accurate Initialization Constraint for 3D Gaussian Splatting
13.Pixel - GS在分裂过程中考虑了从所有输入视角看一个高斯所覆盖的像素数量,并根据到相机的距离对梯度进行缩放,以抑制 “漂浮物”。
论文地址:[2403.15530] Pixel-GS: Density Control with Pixel-aware Gradient for 3D Gaussian Splatting
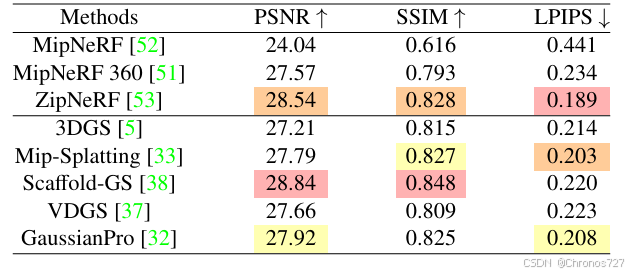
以下是效果对比图
2.3 Compression and Regularization
尽管三维高斯溅射(3D Gaussian Splatting)实现了实时渲染,但在降低计算需求和优化点分布方面仍有提升空间。一些方法致力于改变原始表示形式,以减少计算资源的消耗。
矢量量化是信号处理领域的一种传统压缩方法,该方法涉及将多维数据聚类为有限的一组表示形式,主要应用于高斯模型中 。
1.C3DGS采用残差矢量量化(R-VQ)来表示包括缩放和旋转在内的几何属性。
论文地址:[2311.13681] Compact 3D Gaussian Representation for Radiance Field
2.SASCGS利用矢量聚类,通过一种对敏感度感知的 K 均值方法,将颜色和几何属性编码到两个码本中。
论文地址:[2401.02436] Compressed 3D Gaussian Splatting for Accelerated Novel View Synthesis
3.EAGLES对包括颜色、位置、不透明度、旋转和缩放在内的所有属性进行量化,他们表明在新视图合成任务中,对不透明度的量化会产生更少的瑕疵点或视觉伪影。
论文地址:[2312.04564] EAGLES: Efficient Accelerated 3D Gaussians with Lightweight EncodingS
4.CompGS不对不透明度和位置进行量化,因为共享这些属性会导致高斯模型重叠。
论文地址:[2311.18159] CompGS: Smaller and Faster Gaussian Splatting with Vector Quantization
5.LightGaussian会修剪掉重要性分数较低的高斯模型,并且由于位置属性对后续光栅化精度较为敏感,因此在G-PCC中采用基于八叉树的无损压缩方法来处理位置属性。
论文地址:arXiv reCAPTCHA
6.基于相同的重要性分数计算方法,Mini-Splatting对高斯模型进行采样而不是修剪点,以避免因修剪而产生的伪影。
论文地址:arXiv reCAPTCHA
7.SOGS采用了与矢量量化不同的方法。他们将高斯属性排列到多个二维网格中。对这些网格进行排序,并应用平滑度正则化,对二维网格上与局部邻域像素值差异很大的所有像素进行惩罚。
论文地址:arXiv reCAPTCHA
8.HAC采用了 Scaffold-GS的思想,用一组锚点以及这些锚点上的可学习特征对场景进行建模。之后,它引入了一个自适应量化模块,利用多分辨率哈希网格来压缩锚点的特征。
论文地址:arXiv reCAPTCHA
Jo 等人提出识别不必要的高斯模型,以压缩 3DGS 并加速计算。除了三维压缩之外,三维高斯溅射法还应用于二维图像压缩 ,在这种情况下,三维高斯模型退化为二维高斯模型。
论文地址:arXiv reCAPTCHA
在磁盘数据存储方面,SASCGS利用熵编码方法 DEFLATE 来压缩数据,该方法结合了 LZ77 算法和霍夫曼编码。SOGS使用 JPEG XL 压缩 RGB 网格,并将所有其他属性存储为经过 zip 压缩的 32 位 OpenEXR 图像。
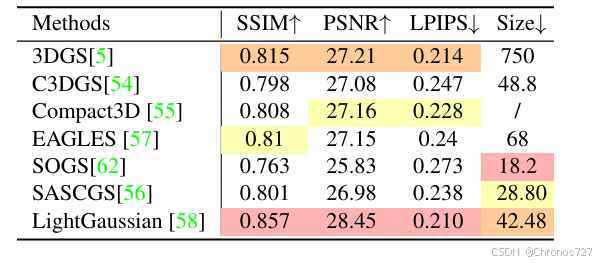
以下是效果对比图
2.4 Dynamic 3D Reconstruction
与神经辐射场(NeRF)的表示方法相同,三维高斯溅射法(3DGS)也可以扩展用于重建动态场景。动态三维高斯溅射法的核心在于如何对高斯属性值随时间的变化进行建模。
Luiten等人将三维高斯的中心和旋转(四元数)视为随时间变化的变量,而其他属性在所有时间步都保持不变,从而通过重建动态场景实现了六自由度跟踪。然而,逐帧的离散定义缺乏连续性,这可能会在长期跟踪中导致不佳的结果。
因此引入基于物理的约束条件(physical-based constraints),其中包括三种正则化损失,即短期局部刚性损失(short-term local-rigidity loss)、局部旋转相似性损失(local-rotation similarity loss)以及长期局部等距损失(long-term local-isometry loss)。
然而,这种方法仍然缺乏帧间相关性,并且对于长序列数据需要较高的存储开销。因此,将时空信息进行分解,并分别利用规范空间和变形场对其进行建模,成为了另一个探索方向。规范空间是静态的三维高斯溅射(3DGS),那么问题就变成了如何对变形场进行建模。一种方法是使用多层感知机(MLP)网络对其进行隐式拟合,这与动态神经辐射场(NeRF)[66] 类似。
1.yang等人遵循这一思路,提出将经过位置编码的高斯位置和时间步长 t 输入到 MLP 中,该 MLP 输出三维高斯的位置、旋转和缩放的偏移量。然而,不准确的位姿可能会影响渲染质量。这在 NeRF 的连续建模中并不明显,但离散的 3DGS 会放大这个问题,尤其是在时间插值任务中。所以,他们在编码后的时间向量中添加线性衰减的高斯噪声,以在不增加额外计算开销的情况下提高时间平滑度。
论文地址:arXiv reCAPTCHA
2.4D-GS采用多分辨率六面体平面体素来编码每个三维高斯的时空信息,而非位置编码,并针对不同属性使用不同的紧凑 MLP。为了实现稳定的训练,它首先优化静态的 3DGS,然后再优化由 MLP 表示的变形场。
论文地址:arXiv reCAPTCHA
3.GauFRe在添加了 MLP 预测的增量值后,分别对缩放和旋转进行指数运算和归一化操作,以确保优化过程方便且合理。由于动态场景包含大量的静态部分,它将点云随机初始化为动态点云和静态点云,分别对它们进行优化,然后将它们一起渲染,以实现动态部分和静态部分的解耦。
论文地址:[2312.11458] GauFRe: Gaussian Deformation Fields for Real-time Dynamic Novel View Synthesis
4.3DGStream通过将帧间变换建模为神经变换缓存,并自适应地添加三维高斯来处理新出现的物体,从而允许对 3DGS 进行在线训练以用于动态场景重建。
论文地址:arXiv reCAPTCHA
5.4DGaussianSplatting将三维高斯转换为四维高斯,并在每个时间步将四维高斯切片为三维高斯。切片后的三维高斯被投影到图像平面上,以重建相应的帧。
论文地址:[2310.08528] 4D Gaussian Splatting for Real-Time Dynamic Scene Rendering
6.guo等人和 GaussianFlow将二维光流估计结果引入到动态三维高斯的训练中,这支持了相邻帧之间的变形建模,并实现了出色的四维重建和四维生成结果。
论文地址:arXiv reCAPTCHA
7.TOGS构建了一个不透明度偏移表,以对数字减影血管造影中的变化进行建模。
8.zhang等人利用扩散先验来增强动态场景重建,并提出了一个神经骨骼变换模块,用于从单目视频中重建可动画的物体。
与 NeRF 相比,3DGS 是一种显式表示,而隐式变形建模需要大量参数,这可能会导致过拟合问题,因此也提出了一些显式变形建模方法,以确保快速训练。
1.Katsumata等人受到人和关节物体的运动有时具有周期性这一事实的启发,提出使用傅里叶级数来拟合高斯位置的变化。旋转则用线性函数进行近似。其他属性随时间保持不变。因此,动态优化就是优化傅里叶级数和线性函数的参数,并且参数的数量与时间无关。这些参数化函数是关于时间的连续函数,确保了时间上的连续性,从而保证了新视图合成的鲁棒性。
论文地址:arXiv reCAPTCHA
除了图像损失外,还引入了双向光流损失。多项式拟合和傅里叶近似分别在建模平滑运动和剧烈运动方面具有优势。因此,Gaussian-Flow在时域和频域中结合了这两种方法,以捕捉属性随时间变化的残差,称为双域变形模型(DDDM)。位置、旋转和颜色被认为是随时间变化的。为了避免由均匀时间划分引起的优化问题,这项工作采用了自适应时间步长缩放。最后,优化过程在静态优化和动态优化之间迭代,并引入了时间平滑度损失和 K 近邻刚性损失。
2.引入了时间径向基函数来表示时间不透明度,可以有效地对出现或消失的场景内容进行建模。然后,利用多项式函数对三维高斯的运动和旋转进行建模。他们还使用特征来代替球谐函数,以表示与视图和时间相关的颜色。这些特征由三个部分组成:基色、与视图相关的特征以及与时间相关的特征。后两者通过添加到基色上的 MLP 转换为残差颜色,从而得到最终的颜色。在优化过程中,将根据训练误差和粗略深度在优化不足的位置采样新的三维高斯。上述方法中使用的显式建模方法均基于常用函数。
论文地址:arXiv reCAPTCHA
3.DynMF假设每个动态场景由有限且固定数量的运动轨迹组成,并认为学习到的轨迹基会更加平滑且更具表现力。场景中的所有运动轨迹都可以由这个学习到的基进行线性表示,并且使用一个小型的时间 MLP 来生成这个基。位置和旋转随时间变化,并且它们在不同的运动基下共享运动系数。在优化过程中引入了运动系数的正则化项、稀疏性项和局部刚性项。
论文地址:arXiv reCAPTCHA
还有一些其他的探索方向。4DGS将场景的时空视为一个整体,并将三维高斯转换为四维高斯,即将定义在高斯上的属性值转换到四维空间。例如,缩放矩阵是对角矩阵,因此在对角线上添加一个时间维度的缩放因子,就形成了四维空间中的缩放矩阵。球谐函数(SH)的四维扩展可以表示为 SH 与一维基函数的组合。
SWAGS根据运动量将动态序列划分为不同的窗口,并在不同的窗口中训练独立的动态 3DGS 模型,每个模型具有不同的规范空间和变形场。变形场使用可调节的 MLP ,它更专注于对场景的动态部分进行建模。最后,通过使用重叠帧添加约束来进行微调,以确保窗口之间的时间一致性。在微调过程中,MLP 是固定的,仅对规范表示进行优化。
论文地址:arXiv reCAPTCHA
这些动态建模方法可以进一步应用于医学领域,例如用于婴儿和新生儿运动分析的无标记运动重建 ,该应用引入了额外的掩码和深度监督,以及单目内窥镜重建。基于代表性的 NeRF 方法和 3DGS 方法的定量重建结果见下图。基于 3DGS 的方法与基于 NeRF 的方法相比具有明显优势,因为它们的显式几何表示能够更轻松地对动态进行建模。3DGS 的高效渲染还避免了基于 NeRF 的方法中对神经场的密集采样和查询,使得动态重建的下游应用(如自由视点视频)更加可行。
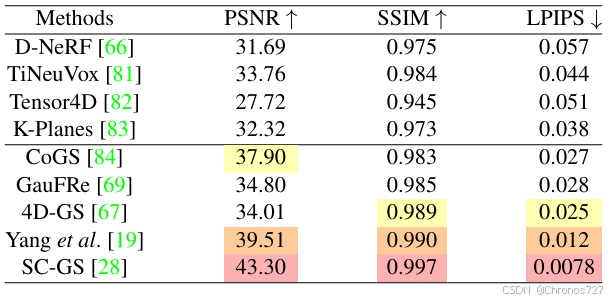
2.5 3D Reconstruction from Challenging Inputs
虽然大多数方法是在相对较小的场景中,对具有密集视点的常规输入数据进行实验,但也有一些研究致力于使用具有挑战性的输入数据来重建三维场景,比如稀疏视点输入、没有相机参数的数据,以及像城市街道这样的大型场景。
1.FSGS是首个探索从稀疏视点输入数据中重建三维场景的方法。它通过运动恢复结构(SfM)方法初始化稀疏的高斯模型,并通过反池化现有的高斯模型来识别它们。为了实现精确的几何重建,一个额外的预训练二维深度估计网络有助于监督渲染的深度图像。
论文地址:arXiv reCAPTCHA
2.SparseGS、CoherentGS和 DNGaussian也旨在通过引入由预训练的二维网络估计的深度输入,从稀疏视点输入数据中进行三维重建。该方法进一步去除了深度值不正确的高斯模型,并利用分数蒸馏采样(SDS)损失来促使新视点的渲染结果更加精确。
论文地址:arXiv reCAPTCHA
3.GaussainObject则是用视觉外壳来初始化高斯模型,并对预训练的 ControlNet [99] 进行微调,以修复因向高斯模型的属性添加噪声而生成的质量下降的渲染图像,该方法的效果优于之前基于神经辐射场(NeRF)的稀疏视点重建方法。
论文地址:arXiv reCAPTCHA
4.更进一步的是,pixelSplat可以在没有任何数据先验的情况下,从单视点输入数据中重建三维场景。它提取与 PixelNeRF类似的像素对齐图像特征,并使用神经网络预测每个高斯模型的属性。
5.MVSplat将代价体表示引入稀疏视点重建中,并将其作为高斯模型属性预测网络的输入。
论文地址:arXiv reCAPTCHA
6.Splatter Image同样处理单视点数据,但它使用 U-Net网络将输入图像转换为高斯模型的属性。通过变形操作聚合来自不同视点的预测高斯模型,它可以扩展到多视点输入数据的处理。
论文地址:arXiv reCAPTCHA
对于城市场景数据:
1.PVG使高斯模型的均值和不透明度值成为以相应高斯模型的生命周期峰值(随时间变化的最大突出值)为中心的时间相关函数。
论文地址:arXiv reCAPTCHA
2.DrivingGaussian和 HUGS 通过首先逐步优化静态三维高斯模型,然后将它们与动态物体的三维高斯模型组合起来,来重建动态驾驶数据。这个过程还借助了分割一切模型(Segmentation Anything Model)和输入的激光雷达深度数据。
论文地址:arXiv reCAPTCHA
3.StreetGaussians使用静态的三维高斯溅射模型(3DGS)对静态背景进行建模,使用动态的 3DGS 对动态物体进行建模,其中高斯模型通过跟踪到的车辆位姿进行变换,并且它们的外观用与时间相关的球谐函数(SH)系数进行近似。
论文地址:arXiv reCAPTCHA
4.SGD将扩散先验融入街道场景重建中,以改善新视点合成结果,这与 ReconFusion 类似。
论文地址:arXiv reCAPTCHA
5.HGS-Mapping分别对无纹理的天空、地平面和其他物体进行建模,以实现更精确的重建。
论文地址:arXiv reCAPTCHA
6.VastGaussian根据投影在地面上的相机分布,将大型场景划分为多个区域,并通过基于可见性标准逐步将更多视点添加到训练中,来学习重建场景。此外,它通过为每个视点设置可优化的外观嵌入来对外观变化进行建模。
论文地址:arXiv reCAPTCHA
7.CityGaussian也采用分而治之的策略对大规模场景进行建模,并进一步引入了基于相机到高斯模型之间距离的细节层次渲染。
论文地址:arXiv reCAPTCHA
8.为了便于对 3DGS 方法在城市场景中的效果进行比较GauU-Scene提供了一个覆盖面积超过 1.5 平方公里的大规模数据集。
论文地址:arXiv reCAPTCHA
3.Gaussian Splatting for 3D Editing
3DGS 中的编辑操作已在多个领域中得到了研究。文中将 3DGS 中的编辑操作归纳为三类:几何形状编辑(geometry editing)、外观编辑(appearance editing)以及物理模拟(physical simulation)。
3.1 Geometry Editing
在几何方面:
1.高斯编辑器(GaussianEditor)利用文本提示以及通过所提出的高斯语义追踪得到的语义信息来控制三维几何结构系统(3DGS),这使得三维图像修复、物体移除和物体合成成为可能。
论文地址:[2311.14521] GaussianEditor: Swift and Controllable 3D Editing with Gaussian Splatting
2.“高斯分组”(Gaussian Grouping)在来自 “分割一切模型”(SAM)的二维掩模预测以及三维空间一致性约束的监督下,同时重建和分割开放世界中的三维物体,这进一步实现了包括三维物体移除、图像修复以及具有高质量视觉效果和时间效率的合成等多种编辑应用。
论文地址:[2312.00732] Gaussian Grouping: Segment and Edit Anything in 3D Scenes
3.此外,“点动”(Point’n Move)将交互式场景物体操作与暴露区域的图像修复相结合。由于三维几何结构系统(3DGS)的显式表示,该方法提出了双阶段自提示掩模传播过程,将给定的二维提示点转换为三维掩模分割,从而带来了具有高质量效果且用户友好的编辑体验。
4.Feng等人提出了一种新的高斯分裂算法,以避免非均匀的三维高斯重建,并使移除操作后的三维场景边界更加清晰。
论文地址:[2403.09143] A New Split Algorithm for 3D Gaussian Splatting
尽管上述方法实现了对三维几何结构系统(3DGS)的编辑,但它们仍局限于对三维物体的一些简单编辑操作(移除、旋转和平移)。
5.“表面生成与修复”(SuGaR)通过对表面上的高斯分布进行正则化,从三维几何结构系统(3DGS)表示中提取显式网格。此外,它依靠基于变形网格对高斯参数进行手动调整来实现所需的几何编辑,但在处理大规模变形时存在困难。
6.“场景控制高斯系统”(SC-GS)为三维场景动态学习了一组稀疏控制点,但在处理剧烈运动和详细表面变形时面临挑战。
论文地址:[2312.14937] SC-GS: Sparse-Controlled Gaussian Splatting for Editable Dynamic Scenes
7.“基于高斯的网格编辑系统”(GaMeS)[30] 引入了一种新的基于高斯系统(GS)的模型,该模型结合了传统网格和普通高斯系统(GS)。显式网格被用作输入,并使用顶点对高斯分量进行参数化,这样在推理过程中可以通过改变网格分量来实时修改高斯分布。然而,它无法处理显著的变形或变化,尤其是大面的变形,因为它在训练过程中无法改变网格拓扑结构。
论文地址:[2402.01459] GaMeS: Mesh-Based Adapting and Modification of Gaussian Splatting
尽管上述方法能够完成一些简单的刚性变换和非刚性变形,但它们在编辑效果和大规模变形处理方面仍然面临挑战。
8.Gao等人还通过利用显式表示的先验知识(如网格的法线等表面属性,以及由显式变形方法生成的梯度),将基于网格的变形应用于三维几何结构系统(3DGS),并学习面分割来优化高斯分布的参数和数量,这为三维几何结构系统(3DGS)提供了足够的拓扑信息,并提高了重建和几何编辑结果的质量。
论文地址:[2402.04796] Mesh-based Gaussian Splatting for Real-time Large-scale Deformation
9.“高斯磨砂”(GaussianFrosting)与Gao等人的思路类似,构建了一个基础网格,但进一步开发了一个磨砂层,使高斯分布能够在网格表面附近的小范围内移动。
论文地址:[2403.14554] Gaussian Frosting: Editable Complex Radiance Fields with Real-Time Rendering
3.2 Appearance Editing
在外观方面:
1.高斯编辑器(GaussianEditor)提出,首先利用扩散模型 ,在近期二维分割模型生成的掩膜区域内,通过语言输入对二维图像进行修改,然后像之前的神经辐射场(NeRF)编辑工作 “指令式神经辐射场转换”(Instruct - NeRF2NeRF)那样,再次更新高斯分布的属性。
Instruct - NeRF2NeRF论文地址:[2303.12789] Instruct-NeRF2NeRF: Editing 3D Scenes with Instructions
2.另一项同样名为高斯编辑器(GaussianEditor)的独立研究工作操作方式类似,但它进一步引入了分层高斯 splatting(HGS),以支持像物体修复这样的三维编辑。
3.“高斯系统编辑”(GSEdit)将纹理网格或预训练的三维几何结构系统(3DGS)作为输入,并利用 “指令式图像转换”(Instruct - Pix2Pix)和可微表面距离(SDS)损失来更新输入的网格或三维几何结构系统(3DGS)。
论文地址:[2403.05154] GSEdit: Efficient Text-Guided Editing of 3D Objects via Gaussian Splatting
4.为缓解不一致性问题,“高斯控制”(Gauss - Ctrl)引入深度图作为控制网络(ControlNet)[99] 的条件输入,以促进几何一致性。
论文地址:[2403.08733] GaussCtrl: Multi-View Consistent Text-Driven 3D Gaussian Splatting Editing
ControlNet 地址:[2302.05543] Adding Conditional Control to Text-to-Image Diffusion Models
5.Wang等人也旨在通过引入多视图交叉注意力图来解决这一不一致性问题。
论文地址:[2403.11868] View-Consistent 3D Editing with Gaussian Splatting
6.“纹理高斯系统”(Texture - GS)提出分离三维几何结构系统(3DGS)的几何和外观,并为底层表面附近的点学习一个 UV 映射网络,从而实现包括纹理绘制和纹理交换在内的操作。
论文地址:[2403.10050] Texture-GS: Disentangling the Geometry and Texture for 3D Gaussian Splatting Editing
7.“三维几何建模”(3DGM)同样用具有固定 UV 映射的代理网格表示三维场景,高斯分布存储在纹理映射上。这种分离式表示也支持动画和纹理编辑。
论文地址:[2402.19441] 3D Gaussian Model for Animation and Texturing
为了能更易于控制纹理和光照,研究人员开始分离纹理和光照,以实现独立编辑。
1.“高斯系统图像渲染”(GS - IR)和 “可重光照高斯系统”(RelightableGaussian)分别对纹理和光照进行建模。在每个高斯分布上定义额外的材质参数来表示纹理,光照则通过一个可学习的环境图进行近似。
论文地址:[2311.16473] GS-IR: 3D Gaussian Splatting for Inverse Rendering
2.“高斯图像渲染”(GIR)和 “高斯着色器”(Gaussian - Shader)采用相同的分离范式,将材质参数绑定到三维高斯分布上,但为了处理更具挑战性的反射场景,它们像 “反射神经辐射场”(Ref - NeRF)[153] 一样,为高斯分布添加了法线方向约束。在纹理和光照分离后,这些方法可以独立修改纹理或光照,而不会相互影响。
论文地址:[2312.05133] GIR: 3D Gaussian Inverse Rendering for Relightable Scene Factorization
[2311.17977] GaussianShader: 3D Gaussian Splatting with Shading Functions for Reflective Surfaces
Ref-NeRF论文地址:[2112.03907] Ref-NeRF: Structured View-Dependent Appearance for Neural Radiance Fields
3.3 Physical Simulation
在基于物理的三维几何结构系统(3DGS)编辑方面:
1.“物理高斯系统”(PhysGaussian)利用来自三维几何结构系统(3D GS)的离散粒子云,通过高斯核的连续体变形来实现基于物理的动力学模拟和逼真的照片级渲染。
论文地址:[2311.12198] PhysGaussian: Physics-Integrated 3D Gaussians for Generative Dynamics
2.“高斯飞溅”(Gaussian Splashing)将三维几何结构系统(3DGS)与基于位置的动力学(PBD)相结合,以统一处理渲染、视图合成以及固体 / 流体动力学。与 “高斯着色器”(Gaussian shaders)类似,法线被应用于每个高斯核,使其方向与表面法线对齐,从而改进基于位置的动力学(PBD)模拟,同时也允许基于物理的渲染增强流体上动态表面的反射效果。
论文地址:[2401.15318] Gaussian Splashing: Unified Particles for Versatile Motion Synthesis and Rendering
3.“虚拟现实高斯系统”(VR-GS)是一个适用于虚拟现实(VR)的、感知物理动力学的交互式高斯 splatting 系统,它解决了实时编辑高保真虚拟内容的难题。“虚拟现实高斯系统”(VR-GS)利用三维几何结构系统(3DGS)来缩小生成的三维内容与手工制作的三维内容之间的质量差距。通过利用基于物理的动力学,增强了沉浸感,并提供了精确的交互和操作可控性。
4.“弹簧高斯系统”(Spring-Gaus)将弹簧 - 质量模型应用于动态三维几何结构系统(3DGS)的建模,并从输入视频中学习质量和速度等物理属性,这些属性可用于真实世界的模拟编辑。
论文地址:[2403.09434] Reconstruction and Simulation of Elastic Objects with Spring-Mass 3D Gaussians
5.“特征 splatting”(Feature Splatting)进一步整合了来自预训练网络的语义先验知识,使对象级别的模拟成为可能。
论文地址:[2404.01223] Feature Splatting: Language-Driven Physics-Based Scene Synthesis and Editing
4 .Applications of Gaussian Splatting
4.1 Segmentation and Understanding
开放世界的三维场景理解对于机器人技术、自动驾驶以及虚拟现实 / 增强现实环境而言,是一项至关重要的挑战。随着分割一切模型(SAM)及其衍生模型在二维场景理解方面取得了显著进展,现有的方法已尝试将诸如对比语言 - 图像预训练模型(CLIP)/ 可变形视觉 Transformer(DINO)[160] 等语义特征集成到神经辐射场(NeRF)中,以处理三维分割、理解和编辑任务。
SAM论文地址:[2304.02643] Segment Anything
CLIP论文地址:[2103.00020] Learning Transferable Visual Models From Natural Language Supervision
DINO论文地址:[2104.14294] Emerging Properties in Self-Supervised Vision Transformers
基于神经辐射场(NeRF)的方法由于其隐式且连续的表示形式,计算量很大。最近的方法尝试将二维场景理解方法与三维高斯模型相结合,以生成一种实时且易于编辑的三维场景表示。大多数方法利用像分割一切模型(SAM)这样的预训练二维分割方法,来生成输入多视图图像的语义掩码 ,或者提取每个像素的密集语言特征,如对比语言 - 图像预训练模型(CLIP)/ 可变形视觉 Transformer(DINO)。
1.LEGaussians 为每个高斯模型添加了一个不确定性值属性和语义特征向量属性。然后,它从给定的视角渲染出带有不确定性的语义图,以便与真实图像经量化后的 CLIP 和 DINO 密集特征进行比较。
论文地址:[2311.18482] Language Embedded 3D Gaussians for Open-Vocabulary Scene Understanding
2.为了实现跨视图的二维掩码一致性,“高斯分组”(Gaussian Grouping)采用了动态实例分割与视频对象分割模型(DEVA)来传播和关联来自不同视角的掩码。它为三维高斯模型添加了身份编码属性,并渲染出身份特征图,以便与提取出的二维掩码进行比较。
论文地址:[2312.00732] Gaussian Grouping: Segment and Edit Anything in 3D Scenes
4.2 Geometry Reconstruction and SLAM
几何重建和同时定位与地图构建(SLAM)也是三维重建中的重要子任务。
4.2.1.Geometry reconstruction
在神经辐射场(NeRF)的背景下,一系列研究成果已成功地从多视图图像中重建出高质量的几何形状。然而,由于三维高斯溅射(3DGS)的离散特性,涉足这一领域的研究工作寥寥无几。
1.SuGaR是一项开创性的研究,它利用三维高斯溅射(3DGS)表示法从多视图图像中构建三维表面。该研究引入了一种简单而有效的自正则化损失函数,用于约束相机与最近的高斯模型之间的距离,使其尽可能接近渲染深度图中相应像素的深度值,这有助于使三维高斯溅射(3DGS)与真实的三维表面对齐。(这篇工作在之前已经出现过了,这里不再贴出论文地址)
2.另一项研究成果 NeuSG则选择将先前基于神经辐射场(NeRF)的表面重建方法 NeuS融入到三维高斯溅射(3DGS)表示法中,以便将表面属性转移到三维高斯溅射(3DGS)上。更具体地说,它促使高斯模型的有符号距离值为零,并使三维高斯溅射(3DGS)的法线方向与 NeuS 方法的法线方向尽可能一致。(这篇工作在之前已经出现过了,这里不再贴出论文地址)
3.3DGSR [175] 和 GSDF [176] 同样致力于促使符号距离函数(SDF)与三维高斯溅射(3DGS)之间保持一致,以提高几何形状的重建质量。
3DGSR论文地址:[2404.00409] 3DGSR: Implicit Surface Reconstruction with 3D Gaussian Splatting
GSDF论文地址:[2403.16964] GSDF: 3DGS Meets SDF for Improved Rendering and Reconstruction
4.DN-Splatter利用从常见设备中获取的深度和法线先验信息,或从通用网络中预测得到的这些信息,来提升三维高斯溅射(3DGS)的重建质量。
论文地址:[2403.17822] DN-Splatter: Depth and Normal Priors for Gaussian Splatting and Meshing
5.Wolf等人首先训练一个三维高斯溅射(3DGS)模型,以渲染经过立体校准的新视图,并对渲染后的视图应用立体深度估计。估计得到的密集深度图通过截断符号距离函数(TSDF)融合在一起,形成一个三角网格。(就是之前提到的那篇GS2Mesh工作)
6.2D-GS [179] 用二维高斯模型取代了三维高斯模型,以实现更精确的光线溅射相交计算,并采用低通滤波器来避免退化的线投影。(这篇工作在我之前的博客中有详细的讲解,有兴趣的读者可以去看看:2D Gaussian Splatting for Geometrically Accurate Radiance Fields(用于实现几何精确辐射场的二维高斯溅射)-CSDN博客)
论文地址:[2403.17888] 2D Gaussian Splatting for Geometrically Accurate Radiance Fields
尽管在几何形状重建领域已经做出了一些尝试,但由于三维高斯溅射(3DGS)的离散特性,与基于具有连续场假设(在这种假设下,表面很容易确定)的隐式表示方法相比,目前的方法所取得的结果相当,甚至更差。
4.2.2.SLAM
也有一些三维高斯溅射(3DGS)方法旨在同时对相机进行定位并重建三维场景。
1.GS-SLAM提出了一种自适应的三维高斯扩展策略,以便在训练阶段添加新的三维高斯模型,并根据获取的深度值和渲染的不透明度值删除不可靠的三维高斯模型。
论文地址:
[2311.11700] GS-SLAM: Dense Visual SLAM with 3D Gaussian Splatting
2.为了避免重复的致密化,SplaTAM为高斯模型使用了与视图无关的颜色,并创建了一个致密化掩码,通过考虑当前的高斯模型以及新帧获取的深度来确定新帧中的某个像素是否需要进行致密化。
论文地址:[2312.02126] SplaTAM: Splat, Track & Map 3D Gaussians for Dense RGB-D SLAM
3.为了稳定定位和建图,GaussianSplattingSLAM和 Gaussian-SLAM在高斯模型的尺度上添加了额外的尺度正则化损失项,以促使高斯模型呈现各向同性。
GaussianSplattingSLAM论文地址:[2312.06741] Gaussian Splatting SLAM
Gaussian-SLAM论文地址:[2312.10070] Gaussian-SLAM: Photo-realistic Dense SLAM with Gaussian Splatting
4.为了更便于初始化,LIV-GaussMap利用激光雷达点云对高斯模型进行初始化,并为全局地图构建了一个可优化的尺寸自适应体素网格。
5.SGS-SLAM [185]、NEDS-SLAM [186] 和 SemGauss-SLAM [187] 通过提取可使用二维分割方法获取或由数据集提供的二维语义信息,在同时定位与建图过程中进一步考虑了高斯模型的语义信息。
SGS-SLAM论文地址:[2402.03246] SGS-SLAM: Semantic Gaussian Splatting For Neural Dense SLAM
NEDS-SLAM论文地址:[2403.11679] NEDS-SLAM: A Neural Explicit Dense Semantic SLAM Framework using 3D Gaussian Splatting
SemGauss-SLAM论文地址:[2403.07494v2] SemGauss-SLAM: Dense Semantic Gaussian Splatting SLAM
6.Deng等人基于滑动窗口掩码避免了冗余的高斯分裂,并使用矢量量化进一步促使形成紧凑的三维高斯溅射(3DGS)。
论文地址:[2403.11247] Compact 3D Gaussian Splatting For Dense Visual SLAM
7.CG-SLAM基于渲染的深度在训练过程中引入了不确定性图,极大地提高了重建质量。
论文地址:[2403.16095] CG-SLAM: Efficient Dense RGB-D SLAM in a Consistent Uncertainty-aware 3D Gaussian Field
基于基于同时定位与建图(SLAM)方法重建的地图,诸如重定位、导航 、六自由度姿态估计 、多传感器校准以及操作等机器人领域的任务都可以高效地执行。
下图为各算法的效果展示:
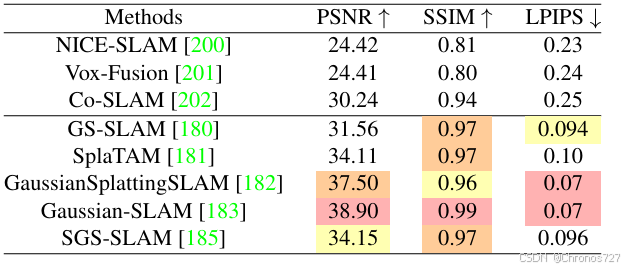
三维高斯溅射(3DGS)所提供的显式几何表示能够实现灵活的重投影,从而减轻不同视点之间的不对齐问题,因此与基于神经辐射场(NeRF)的方法相比能实现更好的重建效果。三维高斯溅射(3DGS)的实时渲染特性也使得基于神经网络的同时定位与建图(SLAM)方法更具实用性,因为先前基于神经辐射场(NeRF)的方法的训练需要更多的硬件资源和时间。
4.3 Digital Human
通过隐式表示来学习虚拟人已经以多种方式得到了探索,尤其是对于神经辐射场(NeRF)和符号距离函数(SDF)表示而言。这两种表示方法从多视角图像中能呈现出高质量的效果,但存在计算成本过高的问题。得益于三维生成式模型(3DGS)的高效率,相关研究工作蓬勃发展,并将三维生成式模型应用到了数字人的创作中。
4.3.1.Human body
在全身建模方面,相关研究致力于从多视角视频中重建动态的人体。
1.D3GA 首次使用可驱动的三维高斯模型和四面体网格来创建可动画化的人体虚拟形象,在几何和外观建模上取得了不错的成果。
论文地址:[2311.08581] Drivable 3D Gaussian Avatars
2.为了捕捉更多的动态细节,SplatArmor利用两个不同的多层感知器(MLP)来预测基于 SMPL 模型和规范空间的大幅度动作,并通过提出的 SE (3) 场实现了与姿势相关的效果,从而得到了更细致的结果。
3.HuGS使用线性混合蒙皮和基于局部学习的优化方法创建了一个从粗到细的变形模块,用于基于三维生成式模型(3DGS)构建和动画化虚拟人体形象。它以每秒 20 帧的速度实现了当前最先进的人体神经渲染性能。
论文地址:[2311.17113] Human Gaussian Splatting: Real-time Rendering of Animatable Avatars
4.同样,HUGS利用三平面表示法 [207] 对规范空间进行分解,能够在 30 分钟内从单目视频(50 到 100 帧)中重建人物和场景。
论文地址:[2311.17910] HUGS: Human Gaussian Splats
5.由于三维生成式模型要学习大量的高斯椭球体,HiFi4G将三维生成式模型与由其双图机制提供的非刚性跟踪相结合,以实现高保真渲染,成功地以更紧凑的方式保持了时空一致性。
论文地址:[2312.03461] HiFi4G: High-Fidelity Human Performance Rendering via Compact Gaussian Splatting
6.为了在消费级设备上以高分辨率实现更高的渲染速度,GPS-Gaussian在稀疏源视图上引入了高斯参数图,以便与深度估计模块一起联合回归高斯参数,且无需任何微调或优化。
7.除此之外,GART基于三维生成式模型的表示,将人体扩展到了更多可关节活动的模型(如动物)。
论文地址:[2311.16099] GART: Gaussian Articulated Template Models
8.为了充分利用多视角图像中的信息,“可动画化的高斯模型”(Animatable Gaussians)结合了三维生成式模型和二维卷积神经网络(2D CNNs),通过模板引导的参数化和姿势投影机制,实现了更准确的人体外观和逼真的衣物动态效果。
9.“高斯壳图”(Gaussian Shell Maps,简称 GSMs)将基于卷积神经网络的生成器与三维生成式模型相结合,以重现具有精细细节(如衣物和配饰)的虚拟人。
论文地址:[2311.17857] Gaussian Shell Maps for Efficient 3D Human Generation
10.ASH使用网格 UV 参数化将三维高斯学习投影到二维纹理空间中,以捕捉外观信息,从而实现了实时且高质量的动画人体。
论文地址:[2312.05941] ASH: Animatable Gaussian Splats for Efficient and Photoreal Human Rendering
11.此外,为了重建人体上的丰富细节(如衣物),3DGS-Avatar引入了一个浅层多层感知器(MLP)来代替球面调和函数(SH)对三维高斯的颜色进行建模,并利用几何先验对变形进行正则化处理,提供了具有与姿势相关的衣物变形的逼真渲染效果,并且能有效地推广到新的姿势。
论文地址:[2312.09228] 3DGS-Avatar: Animatable Avatars via Deformable 3D Gaussian Splatting
12.对于基于单目视频的动态数字人建模,GaussianBody进一步利用基于物理的先验知识,在规范空间中对高斯模型进行正则化处理,以避免单目视频中动态衣物出现伪影。
论文地址:[2401.09720] GaussianBody: Clothed Human Reconstruction via 3d Gaussian Splatting
13.GauHuman重新设计了原始三维生成式模型的修剪 / 分割 / 克隆操作,以实现高效优化,并结合了姿势优化和权重场模块来学习精细细节。它实现了分钟级的训练和实时渲染(每秒 166 帧)。
论文地址:[2312.02973] GauHuman: Articulated Gaussian Splatting from Monocular Human Videos
14.GaussianAvatar将可优化张量与动态外观网络相结合,以更好地捕捉动态信息,从而能够实时重建动态虚拟形象并生成逼真的新动画。
15.Human101使用固定视角的相机,进一步将高保真动态人体创建的速度提升到了 100 秒。
论文地址:[2312.15258] Human101: Training 100+FPS Human Gaussians in 100s from 1 View
16.SplattingAvatar和 GoMAvatar将高斯模型嵌入到规范人体网格上。高斯模型的位置由重心点和沿法线方向的位移决定。
SplattingAvatar:[2403.05087] SplattingAvatar: Realistic Real-Time Human Avatars with Mesh-Embedded Gaussian Splatting
17.为了解决由密度增加和分割操作导致的高斯模型聚集不均衡的问题,GVA提出了一种表面引导的高斯模型重新初始化策略,使训练后的高斯模型更好地拟合输入的单目视频。
论文地址:[2402.16607] GVA: Reconstructing Vivid 3D Gaussian Avatars from Monocular Videos
18.HAHA也将高斯模型附着在网格表面,但将带纹理的人体网格的渲染结果与高斯模型的渲染结果结合在一起,以减少高斯模型的数量。
论文地址:[2404.01053] HAHA: Highly Articulated Gaussian Human Avatars with Textured Mesh Prior
4.3.2.Head
1.在使用三维生成式模型(3DGS)进行人类头部建模方面,MonoGaussianAvatar首先将三维生成式模型应用于动态头部重建,采用了规范空间建模和变形预测的方法。
论文地址:[2312.04558] MonoGaussianAvatar: Monocular Gaussian Point-based Head Avatar
2.此外,PSAvatar [224] 引入了显式的 Flame 人脸模型来初始化高斯模型,它能够捕捉高保真的面部几何形状,甚至包括复杂的体积物体(如眼镜)。
3.GaussianHead使用了三平面表示法和运动场,来模拟连续运动中几何形状不断变化的头部,并渲染出包括皮肤和头发在内的丰富纹理。
论文地址:[2312.01632] GaussianHead: High-fidelity Head Avatars with Learnable Gaussian Derivation
4.为了更方便地控制头部表情,GaussianAvatars将几何先验(Flame 参数化人脸模型 )引入到三维生成式模型中,将高斯模型绑定到显式网格上,并对高斯椭球体的参数进行优化。
论文地址:[2312.02069] GaussianAvatars: Photorealistic Head Avatars with Rigged 3D Gaussians
5.Rig3DGS采用了一种可学习的变形方式,为新的表情、头部姿势和观看方向提供稳定性和泛化能力,从而在便携式设备上实现可控制的人像生成。
论文地址:[2402.03723] Rig3DGS: Creating Controllable Portraits from Casual Monocular Videos
6.另一方面,HeadGas为三维生成式模型赋予了一个由来自三维可变形模型(3DMMs)[230] 的表情向量加权的潜在特征基础,实现了可实时动画的头部重建。
论文地址:[2312.02902] HeadGaS: Real-Time Animatable Head Avatars via 3D Gaussian Splatting
7.FlashAvatar进一步在参数化人脸模型中嵌入了均匀的三维高斯场,并学习额外的空间偏移量来捕捉面部细节,成功地将渲染速度提升到了每秒 300 帧。
论文地址:[2312.02214] FlashAvatar: High-fidelity Head Avatar with Efficient Gaussian Embedding
8.为了合成高分辨率的结果,Gaussian Head Avatar采用了超分辨率网络来实现高保真的头部虚拟形象学习。
论文地址:[2312.03029] HHAvatar: Gaussian Head Avatar with Dynamic Hairs
9.为了从少视角输入中合成高质量的虚拟形象,SplatFace提出首先在模板网格上初始化高斯模型,然后通过 “喷绘到网格” 的距离损失来联合优化高斯模型和网格。
论文地址:[2403.18784] SplatFace: Gaussian Splat Face Reconstruction Leveraging an Optimizable Surface
10.GauMesh提出了一种混合表示方法,该方法包含了跟踪的纹理网格和规范的三维高斯模型,以及一个可学习的变形场,用于表示动态的人类头部。
论文地址:[2403.11453] Hybrid Explicit Representation for Ultra-Realistic Head Avatars
除此之外,一些研究工作将三维生成式模型扩展应用到了基于文本的头部生成、深度伪造(DeepFake)和重新打光 等领域。
基于文本的头部生成论文地址:[2402.06149] HeadStudio: Text to Animatable Head Avatars with 3D Gaussian Splatting
重新打光论文地址:[2312.03704] Relightable Gaussian Codec Avatars
4.3.3.Hair and hands
人类的其他部位也得到了研究探索,比如头发和手部。
1.3D-PSHR将手部几何先验知识(MANO 模型)与三维生成式模型(3DGS)相结合,首次实现了手部的实时重建。
论文地址:[2312.13770] 3D Points Splatting for Real-Time Dynamic Hand Reconstruction
2.MANUS进一步利用三维生成式模型(3DGS)探究了手部与物体之间的互动。
论文地址:[2312.02137] MANUS: Markerless Grasp Capture using Articulated 3D Gaussians
3.此外,GaussianHair首次将Marschner Hair Model与虚幻引擎 4(UE4)的实时毛发渲染技术相结合,创建了高斯毛发散射模型。该模型能够捕捉复杂的头发几何形状和外观,以实现快速光栅化和体渲染,从而支持包括编辑和重新打光在内的多种应用。
论文地址:[2402.10483] GaussianHair: Hair Modeling and Rendering with Light-aware Gaussians
4.4 3D/4D Generation
基于扩散模型,跨模态图像生成已经取得了令人惊叹的成果。然而,由于缺乏三维数据,很难直接训练大规模的三维生成模型。
1.开创性的工作 DreamFusion [97] 利用了预训练的二维扩散模型,并提出了分数蒸馏采样(SDS)损失函数,该函数无需三维数据进行训练就能将二维生成先验知识提炼到三维中,实现了文本到三维的生成。然而,神经辐射场(NeRF)表示法带来了沉重的渲染开销。每个案例的优化时间需要几个小时,而且渲染分辨率较低,这导致生成结果的质量较差。
论文地址:[2209.14988] DreamFusion: Text-to-3D using 2D Diffusion
尽管一些改进的方法从训练好的神经辐射场中提取网格表示进行微调以提高质量 ,但这种方式会进一步增加优化时间。三维网格场景(3DGS)表示法能够以高帧率(FPS)和低内存渲染高分辨率图像,因此在最近的一些三维 / 四维生成方法中,它取代了神经辐射场(NeRF)作为三维表示方法。
4.4.1.3D generation
1.DreamGaussian在 DreamFusion框架中,使用 SDS 损失来优化三维高斯分布的 3DGS 取代了 MipNeRF表示法。3DGS 的分裂过程非常适合生成式设置下的优化进程,因此基于 SDS 损失,3DGS 的效率优势能够在文本到三维生成任务中得以发挥。为了提高最终质量,该工作借鉴了 Magic3D的思路,即从生成的 3DGS 中提取网格,并通过逐像素均方误差(MSE)损失优化 UV 纹理来细化纹理细节。
DreamGaussian论文地址:[2309.16653] DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creation
Magic3D论文地址:[2211.10440] Magic3D: High-Resolution Text-to-3D Content Creation
2.除了二维 SDS,GSGEN基于文本到点云扩散模型 Point - E 引入了三维 SDS 损失,以缓解多面或双面问题。它采用 Point - E 初始化点云作为优化的初始几何结构,并且仅利用二维图像先验来细化外观。
GSGEN:[2309.16585] Text-to-3D using Gaussian Splatting
Point-E: [2212.08751] Point-E: A System for Generating 3D Point Clouds from Complex Prompts
3.GaussianDreamer同样结合了二维和三维扩散模型的先验知识。它利用 Shap - E生成初始点云,并使用二维 SDS 优化 3DGS。然而,生成的初始点云相对稀疏,因此进一步提出了噪声点增长和颜色扰动方法来使其致密化。不过,即使引入了三维 SDS 损失,由于视角是逐个采样的,优化过程中仍可能存在双面问题。
GaussianDreamer:[2310.08529] GaussianDreamer: Fast Generation from Text to 3D Gaussians by Bridging 2D and 3D Diffusion Models
Shap-E:[2305.02463] Shap-E: Generating Conditional 3D Implicit Functions
4.一些方法微调二维扩散模型以一次性生成多视角图像,从而在 SDS 优化过程中实现多视角监督。
论文地址:[2308.16512] MVDream: Multi-view Diffusion for 3D Generation
[2312.02201] ImageDream: Image-Prompt Multi-view Diffusion for 3D Generation
二维扩散模型:[2112.10752] High-Resolution Image Synthesis with Latent Diffusion Models
5.BoostDream提出的多视角 SDS 通过将 4 个采样视角的渲染图像拼接成一个大的 2×2 图像,并在多视角法线贴图的条件下计算梯度。这是一种即插即用的方法,它可以首先通过渲染监督将三维属性转换为包括 NeRF、3DGS 和 DMTet [249] 在内的可微表示,然后对其进行优化以提高三维属性的质量。
一些方法对 SDS 损失进行了改进。
6.LucidDreamer提出了区间分数匹配(ISM)方法,该方法用 DDIM 反演取代了 SDS 中的 DDPM,并引入了扩散过程区间步骤的监督,以避免一步重建中的高误差。
论文地址:[2311.11284] LucidDreamer: Towards High-Fidelity Text-to-3D Generation via Interval Score Matching
7.GaussianDiffusion提出引入多视角的结构化噪声来缓解双面问题,并采用变分 3DGS 来减少悬浮物以获得更好的生成结果。
8.Yang等人指出,扩散先验和扩散模型训练过程之间的差异会损害三维生成的质量,因此他们提出对三维模型和扩散先验进行迭代优化。具体来说,在无分类器引导公式中引入了两个额外的可学习参数,一个是可学习的无条件嵌入,另一个是添加到网络中的额外参数,如 LoRA参数。这些方法并不局限于 3DGS,其他原本基于 NeRF 且旨在改进 SDS 损失的方法,包括 VSD 和 CSD ,也可用于 3DGS 生成。
LoRA:[2106.09685] LoRA: Low-Rank Adaptation of Large Language Models
9.GaussianCube则基于通过最优传输对固定数量的高斯分布进行体素化转换得到的 GaussianCube 表示来训练一个三维扩散模型。
10.GVGEN同样在三维空间中工作,但基于三维高斯体积表示。
论文地址:[2403.12957] GVGEN: Text-to-3D Generation with Volumetric Representation
11.作为一个特殊类别,人体可以引入模型先验,如 SMPL ,来辅助生成。GSMs [211] 从 SMPL 模板构建多层壳层,并将三维高斯分布绑定在壳层上。通过利用 3DGS 的可微渲染和 StyleGAN2 [259] 的生成对抗网络,高效地生成了可动画化的三维人体。
SMPL:https://dl.acm.org/doi/10.1145/2816795.2818013
GSMs:[2311.17857] Gaussian Shell Maps for Efficient 3D Human Generation
StyleGAN2:[1912.04958] Analyzing and Improving the Image Quality of StyleGAN
12.GAvatar采用附着在 SMPL - X上的基于基元的表示法,并将三维高斯分布附着到每个基元的局部坐标系中。三维高斯分布的属性值由一个隐式网络预测,不透明度通过类似 NeuS的方法转换为有符号距离场,从而提供几何约束并提取详细的纹理网格。该生成过程基于文本,主要由 SDS 损失引导。
GAvatar:[2312.11461] GAvatar: Animatable 3D Gaussian Avatars with Implicit Mesh Learning
SMPL-X:[1904.05866] Expressive Body Capture: 3D Hands, Face, and Body from a Single Image
基于基元的表示法:[2103.01954] Mixture of Volumetric Primitives for Efficient Neural Rendering
13.HumanGaussian 通过在 SMPL - X模板表面随机采样点来初始化三维高斯分布。它扩展了 Stable Diffusion [140] 以同时生成 RGB 和深度信息,并构建了一个双分支 SDS 作为优化引导。它还结合了空文本提示提供的分类器分数和负提示提供的负分数,构建负提示引导以解决过饱和问题。
HumanGaussian:[2311.17061] HumanGaussian: Text-Driven 3D Human Generation with Gaussian Splatting
Stable Diffusion:[2112.10752] High-Resolution Image Synthesis with Latent Diffusion Models
上述方法主要侧重于单个对象的生成,而场景生成需要考虑不同对象之间的交互和关系。
1.CG3D将用户手动解构的文本提示输入到场景图中,文本场景图被解释为一个概率图模型,其中有向边的尾部是对象节点,头部是交互节点。然后,场景生成变成了一个先生成对象再生成其交互的祖先采样过程。优化过程分为两个阶段,在第二阶段引入了重力和法向接触力。
论文地址:[2311.17907] CG3D: Compositional Generation for Text-to-3D via Gaussian Splatting
2.LucidDreamer和 Text2Immersion 都基于参考图像(用户指定或文本生成)并向外扩展以实现三维场景生成。前者利用 Stable Diffusion进行图像修复,以在采样视角上生成未观察到的区域,并结合单目深度估计和对齐从这些视角建立三维点云。最后,将点云作为初始值,使用投影图像作为真实标签训练一个 3DGS,以实现三维场景生成。后一种方法思路类似,但有一个去除点云中离群点的过程,并且 3DGS 优化分为两个阶段:训练粗粒度 3DGS 和细化。
LucidDreamer:[2311.13384] LucidDreamer: Domain-free Generation of 3D Gaussian Splatting Scenes
Text2Immersion:[2312.09242] Text2Immersion: Generative Immersive Scene with 3D Gaussians
3.为了探索三维场景生成,GALA3D同时利用对象级文本到三维模型 MVDream生成逼真的对象,并利用场景级扩散模型对它们进行组合。
MVDream:[2308.16512] MVDream: Multi-view Diffusion for 3D Generation
4.DreamScene提出了多时间步采样用于多阶段场景级生成,以合成周围环境、地面和对象,避免复杂的对象组合。
5.RealmDreamer没有对每个对象进行单独建模,而是利用图像修复和深度估计模型的扩散先验来迭代生成场景的不同视角。
论文地址:[2404.07199] RealmDreamer: Text-Driven 3D Scene Generation with Inpainting and Depth Diffusion
6.DreamScene360则生成一个 360 度全景图像,并通过深度估计将其转换为三维场景。
文本到三维生成方法经过一些简单修改后可应用于图像到三维生成或单目三维重建。
例如,SDS 损失中使用的预训练扩散模型可以用 Zero - 1 - to - 3 XL 替换 。我们还可以在输入图像和输入视角下的相应渲染图像之间添加损失,使生成结果更符合输入图像。
论文地址:[2303.11328] Zero-1-to-3: Zero-shot One Image to 3D Object
1.基于 DreamGaussian的图像到三维生成,Repaint123提出了一种渐进式可控修复机制来细化生成的网格纹理。在修复遮挡部分的过程中,它通过注意力特征注入融合参考图像的纹理信息,并提出了一种感知可见性的修复过程,以不同强度细化重叠区域。最后,细化后的图像将作为真实标签,通过 MSE 损失直接优化纹理,实现快速优化。
2.其他方法探索利用现有的三维数据集 [275, 276] 并构建大型模型,以从单张图像直接生成 3DGS 表示。
数据集:[2212.08051] Objaverse: A Universe of Annotated 3D Objects
[2307.05663] Objaverse-XL: A Universe of 10M+ 3D Objects
3.TriplaneGaussian提出了三平面和 3DGS 的混合表示法。它分别通过基于 Transformer 的点云解码器和三平面解码器,从输入图像特征中生成点云和编码 3DGS 属性信息的三平面。生成的点云通过上采样方法进行致密化,然后投影到三平面上查询特征。查询到的特征通过投影图像特征进行增强,并使用多层感知机(MLP)转换为三维高斯属性,从而实现从单张图像生成 3DGS。
4.LGM首先利用现成的模型从文本 或单张图像 生成多视角图像。然后,它训练一个基于 U - Net 的网络,从多视角图像生成 3DGS。该 U - Net 是不对称的,允许输入高分辨率图像,同时限制输出高斯分布的数量。
论文地址:[2402.05054] LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation
5.AGG也引入了一个混合生成器来获取点云和三平面特征。但它首先生成一个粗粒度的 3DGS,然后通过基于 U - Net 的超分辨率模块对其进行上采样,以提高生成结果的保真度。
论文地址:[2401.04099] AGG: Amortized Generative 3D Gaussians for Single Image to 3D
6.BrightDreamer不是从图像预测点云,而是预测一组固定锚点的偏差来确定高斯分布的中心。
论文地址:[2403.11273] BrightDreamer: Generic 3D Gaussian Generative Framework for Fast Text-to-3D Synthesis
7.GRM利用现有的多视角生成模型,通过单次前向传播训练一个像素对齐的高斯表示,以实现逼真的三维生成。
论文地址:[2403.14621] GRM: Large Gaussian Reconstruction Model for Efficient 3D Reconstruction and Generation
8.IM - 3D微调基于 Emu [282] 的图像到视频模型,生成围绕对象旋转的类似转盘的视频,并将其作为 3DGS 重建的输入。
IM-3D:[2402.08682] IM-3D: Iterative Multiview Diffusion and Reconstruction for High-Quality 3D Generation
Emu:[2309.15807] Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack
9.Gamba提出用最近的 Mamba [284] 网络预测高斯属性,以更好地捕捉高斯分布之间的关系。
Gamba:[2403.18795] Gamba: Marry Gaussian Splatting with Mamba for single view 3D reconstruction
Mamba:[2312.00752] Mamba: Linear-Time Sequence Modeling with Selective State Spaces
10.MVControl 将 ControlNet扩展到三维生成任务,并允许将额外的条件输入,如边缘、深度、法线和涂鸦,输入到现有的多视角生成模型中。
论文地址:[2403.09981] Controllable Text-to-3D Generation via Surface-Aligned Gaussian Splatting
11.Hyper - 3DG基于超图学习提出了一个几何和纹理细化模块,以提高生成质量,其中每个节点是一个粗粒度 3DGS 的小块图像。
论文地址:[2403.09236] Hyper-3DG: Text-to-3D Gaussian Generation via Hypergraph
12.出于同样的目的,DreamPolisher利用基于 ControlNet 的网络进行纹理细化,并通过视角一致的几何引导确保不同视角之间的一致性。
论文地址:[2403.17237] DreamPolisher: Towards High-Quality Text-to-3D Generation via Geometric Diffusion
13.FDGaussian将三平面特征注入扩散模型以实现更好的几何生成。
4.4.2.4D generation
基于当前三维生成的进展,人们也利用 3DGS 表示法对四维生成进行了初步探索。
1.AYG 通过一个变形网络赋予 3DGS 动态特性,以实现文本到四维的生成。这一过程分为两个阶段,首先是基于 Stable Diffusion 和 MVDream的 SDS 损失来生成静态的 3DGS,然后是基于文本到视频扩散模型 [289] 的视频 SDS 损失来进行动态生成。在动态生成阶段,仅对变形场网络进行优化,并随机选择一些帧添加基于图像的 SDS,以确保生成质量。
文本到视频扩散模型:[2304.08818] Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
2.DreamGaussian4D 在给定参考图像的情况下实现了四维生成。首先使用 DreamGaussian 的改进版本生成一个静态的 3DGS。利用现成的 Stable Diffusion Video 从给定的图像生成一个视频。然后,通过对添加到静态 3DGS 上的变形网络进行优化来实现动态生成,生成的视频将作为监督信息,同时结合基于从采样视角得到的 Zero-1-to-3 XL 的 3D SDS 损失。最后,该方法还会提取一个网格序列,并使用图像到视频的扩散模型来优化纹理。
论文地址:[2312.17142v1] DreamGaussian4D: Generative 4D Gaussian Splatting
3.最后,对于从视频到四维的生成,4DGen和 Efficient4D都提出利用 SyncDreamer [292] 从输入帧生成多视角图像,将其作为伪真实标签来训练一个动态的 3DGS。前者引入了 HexPlane [68] 作为动态表示,并使用生成的多视角图像作为三维变形的伪真实标签来构建点云。后者则直接将三维高斯分布转换为四维高斯分布,并通过融合相邻时间戳的空间体来增强 SyncDreamer 的时间连续性,实现时间同步,从而生成更好的跨时间多视角图像用于监督。
4DGen:[2312.17225] 4DGen: Grounded 4D Content Generation with Spatial-temporal Consistency
Efficient4D:[2401.08742] Efficient4D: Fast Dynamic 3D Object Generation from a Single-view Video
SyncDreamer:[2309.03453] SyncDreamer: Generating Multiview-consistent Images from a Single-view Image
HexPlane:[2301.09632] HexPlane: A Fast Representation for Dynamic Scenes
4.SC4D 将 SC-GS 中稀疏控制点的思想进行迁移,以更高效地对变形和外观进行建模。
论文地址:[2404.03736] SC4D: Sparse-Controlled Video-to-4D Generation and Motion Transfer
5.STAG4D提出了一种时间一致的多视角扩散模型,用于从单目视频生成多视角视频以进行四维重建或实现四维生成。
论文地址:[2403.14939] STAG4D: Spatial-Temporal Anchored Generative 4D Gaussians
6.为了克服之前四维生成模型以对象为中心的局限性,Comp4D首先生成单个的四维对象,然后在轨迹约束下将它们组合起来。
论文地址:[2403.16993] Comp4D: LLM-Guided Compositional 4D Scene Generation
为了实现更逼真的三维 / 四维生成,大多数方法都利用了扩散模型的先验知识,这些扩散模型作用于二维图像,并且需要生成对象的渲染视角。与基于 NeRF 且渲染速度较慢的方法相比,3DGS 中基于快速光栅化的渲染使得这些先验知识能更高效地得到应用。
本文就到此为止了,大家科研顺利!