Leetcode周赛第 416 场
题目1:3295. 举报垃圾信息
给你一个字符串数组
message和一个字符串数组bannedWords。如果数组中 至少 存在两个单词与
bannedWords中的任一单词 完全相同,则该数组被视为 垃圾信息。如果数组message是垃圾信息,则返回true;否则返回false。
示例 :
输入: message = ["hello","world","leetcode"], bannedWords = ["world","hello"]
输出: true
解释:数组
message中的"hello"和"world"都出现在数组bannedWords中。
思考:
可以直接通过暴力循环,遍历message数组,同时遍历bannedWords查看该词是否出现,单次查询效率是O(m),若出现次数大于等于2则直接返回false。但随着样例规模的增大,肯定会超时。
那么避免无效重复的循环查找最好的办法就是哈希表,我们创建一个哈希表,里面存储bannedWords数组中出现的词,这样查找单词的效率就是O(1)。
1.创建bannedWords的哈希表
初始化的值可以为int型或bool型,只是为了证明某个单词存在于数组中。
unordered_map<string, int> map;//key为string类型,value随便
for(int i=0;i<bannedWords.size();i++){
map[bannedWords[i]]=1;
}2.遍历message
int all=0;//message中禁词出现次数
for(int j=0;j<message.size();j++){
if(map[message[j]]==1){
all++;
}
}
if(all>=2){
return true;
}
return false;完整可通过代码:
class Solution {
public:
bool reportSpam(vector<string>& message, vector<string>& bannedWords) {
unordered_map<string, int> map;
for(int i=0;i<bannedWords.size();i++){
map[bannedWords[i]]=1;
}
int al=0;
for(int j=0;j<message.size();j++){
if(map[message[j]]==1){
al++;
}
}
if(al>=2){
return true;
}
return false;
}
};
题目2:3296. 移山所需的最少秒数
给你一个整数
mountainHeight表示山的高度。同时给你一个整数数组workerTimes,表示工人们的工作时间(单位:秒)。工人们需要 同时 进行工作以 降低 山的高度。对于工人
i:
- 山的高度降低
x,需要花费workerTimes[i] + workerTimes[i] * 2 + ... + workerTimes[i] * x秒。例如:
- 山的高度降低 1,需要
workerTimes[i]秒。- 山的高度降低 2,需要
workerTimes[i] + workerTimes[i] * 2秒,依此类推。返回一个整数,表示工人们使山的高度降低到 0 所需的 最少 秒数。
示例 1:
输入: mountainHeight = 4, workerTimes = [2,1,1]
输出: 3
解释:将山的高度降低到 0 的一种方式是:
- 工人 0 将高度降低 1,花费
workerTimes[0] = 2秒。- 工人 1 将高度降低 2,花费
workerTimes[1] + workerTimes[1] * 2 = 3秒。- 工人 2 将高度降低 1,花费
workerTimes[2] = 1秒。因为工人同时工作,所需的最少时间为
max(2, 3, 1) = 3秒。
第一遍看题目时没有看明白,就又看了一遍。大概意思是说:这里有一座山高h,有一堆工人,第i个工人第一次挖1m的山要workerTimes[i]的时间,第二次挖要2*workerTimes[i]......所有工人是可以并行工作的,问挖完整个山最少要多久?
最初的思路:1m接1m的把任务分配给每个工人,到最后再找出花费时间最大的工人,即题目所求。
遇到了一个问题:该以什么为条件选择该次挖掘的工人呢?(是workerTimes?是该工人当前花费时间?是工人下一次花费时间?)
想法:我们可以用一个数组next来存储:"若该次挖掘由第i位工人进行,则该工人总共的花费时间为next[i]"。
mountainHeight = 4, workerTimes = [2,1,1]
对于这个示例,勾造next[];
1.第一次挖掘:next[0]=2 next[1]=1 next[2]=1 (选择下标为1的工人 next[1]=1+2*1
2.第二次挖掘:next[0]=2 next[1]=3 next[2]=1 (选择下标为2的工人 next[2]=1+2*1
3.第三次挖掘:next[0]=2 next[1]=3 next[2]=3 (选择下标为0的工人 next[0]=2+2*2
4第四次挖掘:next[0]=6 next[1]=3 next[2]=3 (选择下标为1的工人 next[1]=3+3*1
最后maxTime=next[1]-3*1=4;
每次我们从next中挑最小的工人i来做此次挖掘,同时记得更新next[i]的值,可以额外开一个数组v来记录工人已经挖掘的次数
next[i]+=(该工人已挖次数+1)*workerTimes[i];
1.构造两个数组v和next
for(int i=0;i<workerTimes.size();i++){
v.push_back(0);//每位工人挖的次数
next.push_back(workerTimes[i]);
}2.用while循环进行挖山工作
这里的min_element是寻找当前next中最小的数(此处为下文出问题埋下伏笔)
while(mountainHeight>0){
minPosition = min_element(next.begin(),next.end()) -next.begin();//找到一个花费最小的人
v[minPosition]++;//次数增加
next[minPosition]+=(v[minPosition]+1)*workerTimes[minPosition];
mountainHeight--;
if(mountainHeight==0){
break;
}
}3.找到next[i]-(v[i]+1)*workerTimes[i]最大的数
因为next中保存的是下一次挖掘,某个工人所需要耗的时间,但山已经挖完了,所以每个工人要减去下一次挖掘的时间,就可以得出真正的总花费。
for(int i=0;i<workerTimes.size();i++){
num[i]-=v[i]*workerTimes[i];
}
long long maxValue = *max_element(num.begin(),num.end());
return maxValue;完整代码:
#include<iostream>
#include<vector>
#include<algorithm>
#include<set>
#include <numeric>
#include <string>
using namespace std;
class Solution {
public:
long long minNumberOfSeconds(int mountainHeight, vector<int>& workerTimes) {
vector<long long>num;
long long p;
long long k=workerTimes[0];
long long q=mountainHeight;
if(workerTimes.size()==1){
p=k*(1+q)*q/2;
return p;
}
vector<int>v;
for(int i=0;i<workerTimes.size();i++){
v.push_back(0);
num.push_back(workerTimes[i]);
}
int minPosition;
while(mountainHeight>0){
minPosition = min_element(num.begin(),num.end()) - num.begin();//找到一个移除当前高度花费最小的人
v[minPosition]++;//下次翻倍
num[minPosition]+=(v[minPosition]+1)*workerTimes[minPosition];
mountainHeight--;
if(mountainHeight==0){
break;
}
}
for(int i=0;i<workerTimes.size();i++){
num[i]-=(v[i]+1)*workerTimes[i];
}
long long maxValue = *max_element(num.begin(),num.end());
return maxValue;
}
};恭喜,超时了!
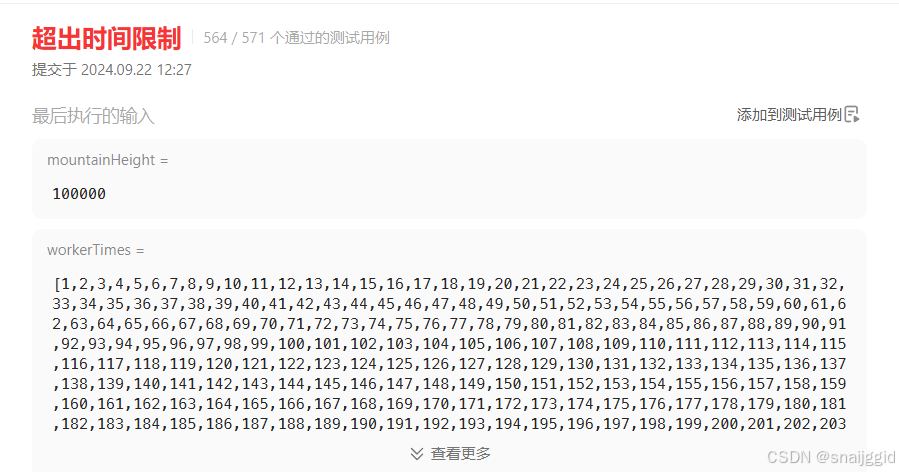
emm,大量的时间被花费在寻找next数组中最小的数上了,时间复杂度为O(n),导致遇上较大测试集就会超时。如果用小顶堆是否可以更快速的实现找最小数呢。开干!直接使用了优先队列。
1.定义结构体
struct node
{
long long x,y,z;//x即next中的数,y即工人在workerTimes中的下标,z即v中的数
bool operator < (const node & a) const
{
return x>a.x;//小顶堆
}
}nodes;2.初始化队列
priority_queue<node>que;
for(int i=0;i<workerTimes.size();i++){
nodes.y=i;
nodes.z=1;
nodes.x=workerTimes[i]*(nodes.z);//x记录下一次让该位员工移山的总时间
que.push(nodes);
}3.移山
while(mountainHeight>0){
node m=que.top();
m.x+=(m.z+1)*workerTimes[m.y];
m.z++;//下次翻倍
que.pop();
que.push(m);
mountainHeight--;
if(mountainHeight==0){
break;
}
}4.找到耗时最大的人
for(int i=0;i<workerTimes.size();i++){
node u=que.top();
temp=u.x-u.z*workerTimes[u.y];
if(temp>maxs){
maxs=temp;
}
que.pop();
}整体就是把上面的代码改成用优先队列来存了,唯一不同的是我直接给z初值赋为1了,这样就使nodes.x更新使避免了z+1的操作。
完整代码:
#include<iostream>
#include<vector>
#include<algorithm>
#include<set>
#include <numeric>
#include <string>
#include<queue>
using namespace std;
struct node
{
long long x,y,z;
bool operator < (const node & a) const
{
return x>a.x;
}
}nodes;
class Solution {
public:
long long minNumberOfSeconds(int mountainHeight, vector<int>& workerTimes) {
vector<long long>num;
long long p;
long long k=workerTimes[0];
long long q=mountainHeight;
long long maxs=0;
if(workerTimes.size()==1){
p=k*(1+q)*q/2;
return p;
}
priority_queue<node>que;
for(int i=0;i<workerTimes.size();i++){
nodes.y=i;
nodes.z=1;
nodes.x=workerTimes[i]*(nodes.z);//x记录下一次让该位员工移山的总时间
que.push(nodes);
}
while(mountainHeight>0){
node m=que.top();
m.x+=(m.z+1)*workerTimes[m.y];
m.z++;//下次翻倍
que.pop();
que.push(m);
mountainHeight--;
if(mountainHeight==0){
break;
}
}
long long temp;
for(int i=0;i<workerTimes.size();i++){
node u=que.top();
temp=u.x-u.z*workerTimes[u.y];
if(temp>maxs){
maxs=temp;
}
que.pop();
}
return maxs;
}
};还有两题还没弄明白,留着明天做吧