大家好,我是摇光~
本文主要讲解 4种窗口函数(非聚合窗口函数、聚合窗口函数、窗口函数的重命名、动态窗口函数),为了让大家都懂得,我尽量用通俗易懂的讲法讲给大家。
零、前言
一、非聚合窗口函数
非聚合函数有以下函数(注:我只列举了常用的。)
看不明白没关系,我下面会一一对这些进行讲解。
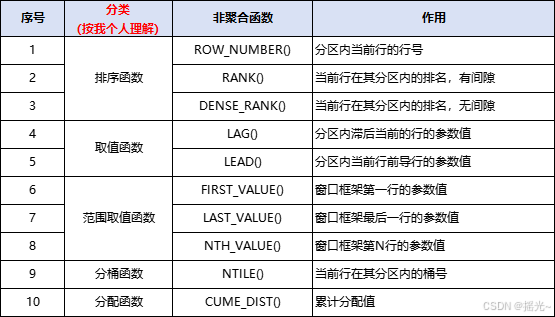
1、排序函数
- 先举个例子:
比如现在有一张公司各部门的工资表,如果你想知道每个部门中工资最高的人,那么就可以用
ROW_NUMBER()、RANK()、DENSE_RANK()函数进行计算。
排序函数作用就是: 在一个区间内(比如将部门分类,一个部门为一个区间),再进行排序(就可以对工资从大到小进行排序),返回排序的序号;那么序号为 1 的就是各个部门中工资最高的人。
如果区间内不存在重复值,计算结果就会一致。,如果有重复值,三个的结果不一样。
- ROW_NUMBER(): 不考虑重复值,会给两个相同值分配不同的编号。
- RANK(): 重复值会生成相同的编号,不过重复值的下一项编号和重复值编号不连续
- DENSE_RANK(): 重复值会生成相同的编号,不过重复值的下一项编号和重复值编号连续
实际案例
- 现有数据:
employee_id | name | department | salary
------------|-------|------------|-------
1 | Alice | HR | 60000
2 | Bob | HR | 60000
3 | Carol | HR | 50000
4 | Dave | IT | 80000
5 | Eve | IT | 75000
6 | Frank | IT | 75000
- SQL语句:
SELECT
employee_id, -- 员工id
name, -- 员工名字
department, -- 员工所属部门
salary, -- 员工工资
ROW_NUMBER() OVER (PARTITION BY department ORDER BY salary DESC) AS row_num,
RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS rank,
DENSE_RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS dense_rank
FROM
employees;
- 解析 SQL:
ROW_NUMBER() OVER (PARTITION BY department ORDER BY salary DESC) AS row_num
ROW_NUMBER() OVER ():是固定写法- 在OVER()里面的
PARTITION BY department:是针对部门进行分区,一个部门一个区间- 在OVER()里面的
ORDER BY salary DESC:是对每个分区内的数据进行从大到小排序AS row_num:别名(row_num)
- 结果展示:
employee_id | name | department | salary | row_num | rank | dense_rank
------------|-------|------------|--------|---------|------|----------
1 | Alice | HR | 60000 | 1 | 1 | 1
2 | Bob | HR | 60000 | 2 | 1 | 1
3 | Carol | HR | 50000 | 3 | 3 | 2
4 | Dave | IT | 80000 | 1 | 1 | 1
5 | Eve | IT | 75000 | 2 | 2 | 2
6 | Frank | IT | 75000 | 3 | 2 | 2
- 结果分析:
- 字段:row_num 、rank、dense_rank 就是分部门,对部门内部工资的排序结果。
- 可以观察这三个字段的排序,就能够知道三个函数的区别。
- 可以看出字段 row_num 中等于 1 的就是工资最高的。
- 如果想求得每个部门中工资最高的,可以用下面语句:
-- 这里使用 ROW_NUMBER()、RANK()、DENSE_RANK() 都可以
WITH RankedEmployees AS (
SELECT
employee_id,name,department,salary,
ROW_NUMBER() OVER (PARTITION BY department ORDER BY salary DESC) AS row_num
FROM employees
)
SELECT * FROM RankedEmployees
WHERE row_num = 1; -- 只选择每个部门中工资最高的员工
-- where 语句可以控制,比如求前三名工资高的,可以 WHERE row_num <= 3,根据自己需求来定
2、取值函数
- 先举个例子:
假设我们有一个名为 sales 的表,其中包含以下列:sales_id(销售ID)、sales_date(销售日期)和 amount(销售金额)。我们想要计算每一天的销售金额与前一天或后一天相比的增长或减少情况;这时候可以使用 LAG()、LEAD() 函数。
LAG()、LEAD() 函数作用: 取当前数据行前面数据和后面数据。
- LAG():取得当前行
前面的数据- LEAD():取得当前行
后面的数据
实际案例
- 现有数据
sales_id | sales_date | amount
---------|------------|-------
1 | 2023-01-01 | 100
2 | 2023-01-02 | 150
3 | 2023-01-03 | 120
4 | 2023-01-04 | 200
- SQL
SELECT
sales_id, -- 销售id
sales_date, -- 销售日期
amount, -- 销售额
LAG(amount, 1) OVER (ORDER BY sales_date) AS previous_day_amount, -- 前一天的销售金额
LEAD(amount, 1) OVER (ORDER BY sales_date) AS next_day_amount -- 后一天的销售金额
FROM
sales
ORDER BY
sales_date;
- SQL解析
LAG(amount, 1) OVER (ORDER BY sales_date) AS previous_day_amount
LAG(amount, 1):amount 是需要取值的字段,1 是指偏移量;如果是LAG(amount, 2),就是获取前面的第二天数据。ORDER BY sales_date:因为我们需要根据日期来获取前后的数据,所以需要对日期进行排序。- 其实也可以加上分区,比如如果有每个分店每天的销售额,按照分店来分区,再来获取前后的数据。(分区的设置:
PARTITION BY 分区字段)
- 结果:
sales_id | sales_date | amount | previous_day_amount | next_day_amount
---------|------------|--------|---------------------|-----------------
1 | 2023-01-01 | 100 | NULL | 150
2 | 2023-01-02 | 150 | 100 | 120
3 | 2023-01-03 | 120 | 150 | 200
4 | 2023-01-04 | 200 | 120 | NULL
- 结果分析
- previous_day_amount 字段数据,就是获取当前日期前面一行的数据。
- next_day_amount 字段数据,就是获取当前日期后面一行的数据。
- 如果需要看出销量的增减,就可以使用 amount ± previous_day_amount、next_day_amount
3、范围取值函数
先举个例子:
如果你是一个店铺的管理人员,你想知道每个客户的第一次消费金额、最后一次消费金额、第5次消费金额(如果有的话),这样便于分析客户的消费情况;这时候就可以使用范围取值函数。
实际案例
- 数据:
order_id customer_id order_date order_value
1 1001 2023-01-15 250.00
2 1002 2023-01-16 150.00
3 1001 2023-01-17 300.00
4 1003 2023-01-18 400.00
5 1001 2023-01-19 275.00
6 1002 2023-01-20 175.00
- SQL
SELECT
customer_id,
FIRST_VALUE(order_value) OVER (PARTITION BY customer_id ORDER BY order_date) AS first_order_value,
LAST_VALUE(order_value) OVER (PARTITION BY customer_id ORDER BY order_date) AS last_order_value,
NTH_VALUE(order_value, 2) OVER (PARTITION BY customer_id ORDER BY order_date) AS second_order_value
FROM
orders
ORDER BY
customer_id, order_date;
- SQL解析
FIRST_VALUE(order_value) OVER (PARTITION BY customer_id ORDER BY order_date) AS first_order_value
FIRST_VALUE(order_value):表示取 order_value(消费金额) 这个字段的数据PARTITION BY customer_id:对 customer_id(客户) 这个字段进行分区,以便于求每个客户的第一次消费情况。ORDER BY order_date:按照 order_date(下单日期)进行排序。
- 结果
customer_id first_order_value last_order_value second_order_value
1001 250.00 275.00 300.00
1002 150.00 175.00 NULL
1003 400.00 400.00 NULL
- 结果解析
其实这个也可以用 ROW_NUMBER() 排序函数做到,但是排序函数就会多一步where筛选出第一条数据,这个函数可以直接求出第一条数据。
4、分桶函数
- 举个例子
比如现在你有一份你店铺里面所有产品的销售信息,你想把商品按照价格分成4等,然后对销售产品和销售总额进行观察,是否需要对现有的产品进行调整。
实例
- 数据:
product_id product_name price sales_quantity
1 Product A 9.99 50
2 Product B 19.99 80
3 Product C 4.99 30
4 Product D 29.99 120
5 Product E 14.99 70
6 Product F 34.99 90
7 Product G 7.99 40
8 Product H 24.99 110
- SQL
WITH PriceQuartiles AS (
SELECT
product_id,
product_name,
price,
sales_quantity,
NTILE(4) OVER (ORDER BY price) AS price_quartile # 分桶
FROM sales
)
SELECT
price_quartile, # 桶号
COUNT(product_id) AS number_of_products, # 每个桶中产品的品种有多少个
SUM(sales_quantity) AS total_sales_quantity # 每个桶中产品的销售额
FROM PriceQuartiles
GROUP BY price_quartile
ORDER BY price_quartile;
- SQL解析
NTILE(4) OVER (ORDER BY price) AS price_quartile
- NTILE(4):分成 4 个桶(就是4个类别)
- ORDER BY price:按照价格进行分桶,所以需要对价格进行排序,这样才能保持平衡,价格低的在一个桶里面。
- 结果
price_quartile number_of_products total_sales_quantity
1 2 70
2 2 150
3 2 150
4 2 210
二、聚合窗口函数
常见的聚合函数有以下几种:
- SUM():计算指定列或表达式的总和。
- AVG():计算指定列或表达式的平均值。
- MIN():找到指定列或表达式的最小值。
- MAX():找到指定列或表达式的最大值。
- COUNT():计算指定列或表达式的行数。
如果在上面的聚合函数上,加上 OVER()子句,就变成聚合窗口函数。
实例:
表结构:
salesperson_id:销售员ID
region:销售区域
sales_amount:销售金额
sale_date:销售日期
数据计算:
- 累计销售额(Cumulative Sales):使用SUM()函数计算每个销售员在其销售区域内的累计销售额。
- 平均销售额(Average Sales):使用AVG()函数计算每个销售员在其销售区域内的平均销售额(这里为了简单起见,我们按销售员分区,但在实际应用中可能会按其他维度如月份或季度分区)。
- 最小销售额(Minimum Sales):使用MIN()函数找到每个销售员在其销售区域内的最小销售额。
- 最大销售额(Maximum Sales):使用MAX()函数找到每个销售员在其销售区域内的最大销售额。
- 销售次数(Sales Count):使用COUNT()函数计算每个销售员在其销售区域内的销售次数。
SELECT
salesperson_id,
region,
sales_amount,
sale_date,
SUM(sales_amount) OVER (PARTITION BY salesperson_id, region ORDER BY sale_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cumulative_sales,
AVG(sales_amount) OVER (PARTITION BY salesperson_id ORDER BY sale_date) AS average_sales, -- 注意:这里为了简单起见,仅按销售员分区
MIN(sales_amount) OVER (PARTITION BY salesperson_id, region) AS minimum_sales,
MAX(sales_amount) OVER (PARTITION BY salesperson_id, region) AS maximum_sales,
COUNT(sales_amount) OVER (PARTITION BY salesperson_id, region) AS sales_count
FROM
sales_data
ORDER BY
salesperson_id,
region,
sale_date;
SQL解析
其实我们只需要理解到,PARTITION BY 是对数据进行分区,ORDER BY 是对数据进行排序,就可以进行数据计算,计算完之后,不会改变数据的行数。
三、窗口函数重命名
对窗口函数重命名可以用一个例子来理解。
例如有这么一段SQL:
SELECT
number_id,
ROW_NUMBER() OVER (ORDER BY number_id) AS 'row_number',
RANK() OVER (ORDER BY number_id) AS 'rank',
DENSE_RANK() OVER (ORDER BY number_id) AS 'dense_rank'
FROM emp;
可以看到上面的 OVER 子句括号里面都有(ORDER BY number_id),三个都是一样的,其实是有些繁琐,这时候我们可以用上窗口函数的重命名。
改造后的SQL:
SELECT
number_id,
ROW_NUMBER() OVER w AS 'row_number', # OVER 子句里面使用重命名的 w ,代码更加简洁
RANK() OVER w AS 'rank',
DENSE_RANK() OVER w AS 'dense_rank'
FROM emp
WINDOW w AS (ORDER BY number_id); # 可以将OVER子句重新命名为 w
通过上面的例子,可以知道窗口函数重命名的作用了,下面举一个复杂的例子:
SELECT
sale_date,
sale_amt,
ROW_NUMBER() OVER w2 AS 'row_number',
RANK() OVER (w1 ORDER BY sale_amt) AS 'rank',
DENSE_RANK() OVER w3 AS 'dense_rank'
FROM emp
WINDOW w1 AS(PARTITION BY sale_date),
w2 AS(ORDER BY sale_amt),
w3 AS(w2)
ORDER BY sal;