随着AI技术加速落地,大模型相关的专业术语频繁出现在行业讨论中。无论是技术文档、产品方案还是投资分析,掌握这些“黑话”已成为从业者的必备技能。我将用最简明的语言,拆解 Token、RAG、RL、上下文长度、量化、蒸馏、智能体 7个高频概念,助你快速读懂大模型核心逻辑。
定义:Token是AI处理文本的最小单位,相当于自然语言中的“字词片段”。例如“人工智能”可能被拆分为“人工”+“智能”两个Token,或保留为单个Token(不同模型分词规则不同)。
DeepSeek官方也给出Token数和字数的大致换算比例如下:
- 1 个英文字符 ≈ 0.3 个 token。
- 1 个中文字符 ≈ 0.6 个 token。
核心价值:
- 计费基准:大模型服务通常按输入输出Token总量收费(如1元/百万Tokens)。
- 性能指标:上下文长度(如128K Tokens)决定模型单次处理文本的能力。例如128K Tokens≈6.5万汉字,可解析整本《三体》。
应用场景:
- 长文本摘要:一次性处理超长合同、论文。
- 成本估算:根据Token单价计算AI客服对话成本。
定义:Retrieval-Augmented Generation(检索增强生成),通过实时检索外部知识库提升模型回答准确性17。
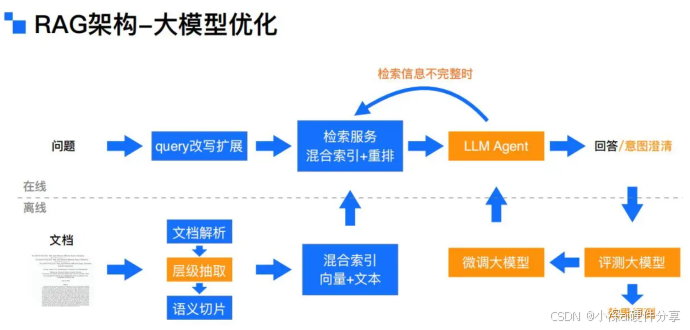
运作原理:
- 用户提问 → 2. 从数据库/文档中检索相关片段 → 3. 将检索结果与问题拼接输入模型 → 4. 生成精准回答。
优势:
- 解决大模型“幻觉”(虚构事实)问题
- 动态更新知识,利用检索到的外部信息辅助生成更准确、时效性更强的文本
典型案例:
- 法律咨询:检索判例库生成法律意见书
- 医疗诊断:结合最新医学论文输出建议
定义:Reinforcement Learning(强化学习),通过奖励机制让模型自主优化行为策略12。
训练过程:
- 模型输出答案 → 2. 人类标注/规则系统打分 → 3. 高分结果强化对应策略 → 4. 迭代提升准确率。
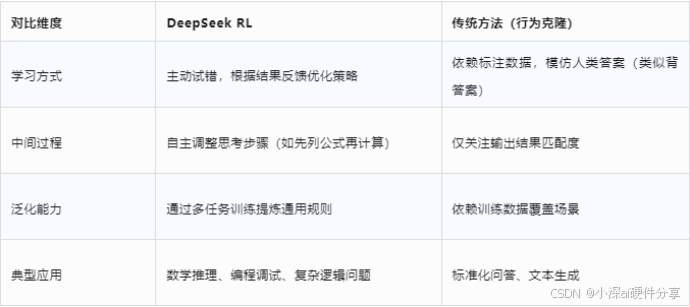
- 与传统的训练方式相比特点如下:
应用突破:
- DeepSeek-R1:通过RLHF(人类反馈强化学习)将事实错误率降低40%
- 游戏AI:AlphaGo通过RL战胜人类棋手
行业价值:
- 客服对话优化:奖励“解决用户问题”的行为
- 内容安全:惩罚生成违规内容的策略
定义:模型单次处理文本的Token上限,直接影响长文本理解能力。
分级标准:
- 4K(≈2000汉字):基础对话
- 32K(≈1.6万字):中篇小说分析
- 128K(≈6.5万字):学术论文改写
技术突破:
- DeepSeek V3:支持128K上下文,可解析500页PDF并提取核心结论
选型建议:
- 短文本交互(如营销文案)选4K-8K模型
- 长文档处理(如法律合同)需32K以上
定义:降低参数精度(如FP32→INT8),以缩小模型体积、提升推理速度。
效果对比:
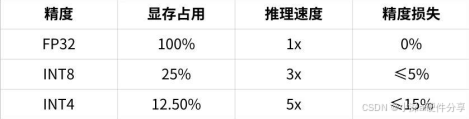
点击图片可查看完整电子表格
- 手机端部署:7B模型量化后可在iPhone14运行
- 边缘计算:工厂质检AI用INT8模型实时识别缺陷
量化程度越高,显存占用越少,但可能带来一定的精度损失
FP8 需要 H系列或者40系列 GPU 硬件支持、FP4需要B系列或者50系列支持
建议根据实际需求在性能和精度间权衡
定义:大模型“蒸馏”技术是把大语言模型中的能力和知识迁移到更小的模型的技术,目的是在于构造出来资源高效和性能优异的小模型,未经过蒸馏的模型好比是老师,经过蒸馏的小模型可以比作学生
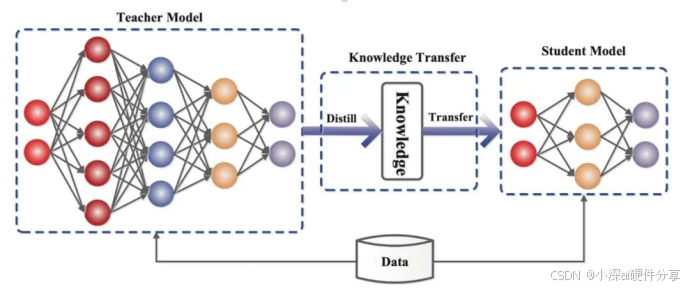
技术价值:
- 成本降低:7B蒸馏模型推理成本仅为千亿模型的1/20
- 性能保留:部分任务精度可达教师模型的90%
典型案例:
- R1-Distill-Qwen-7B:DeepSeek将671B大模型能力迁移到7B小模型,支持本地化部署1
- 医疗助手:三甲医院知识库蒸馏到轻量模型,供社区诊所使用
定义:具备自主规划、工具调用、环境交互能力的AI系统。
核心组件:
- 大脑:大模型(决策中心)
- 手脚:API/机器人(执行指令)
- 记忆:数据库/知识图谱
应用场景:
- AutoGPT:自动拆解复杂任务(如“策划北京三日游”),调用地图、订票API执行
- Manus:分析用户需求→生成设计稿→联动3D打印机生产样品
从Token的经济账到RAG的精准性,从量化的效率革命到智能体的自动化突破,这些术语背后折射出AI技术的演进逻辑。对于从业者而言,理解这些概念不仅是技术对话的入场券,更是设计产品、评估方案、洞察趋势的关键。你还有不理解的ai术语吗?可以在下方留言告诉我。