一、快速部署:5 分钟开启 AI 绘画之旅
1. 硬件准备
-
显卡要求
NVIDIA 显卡(推荐 RTX 3060 及以上,显存 8GB+)
-
系统
Windows 10/11 或 Ubuntu 20.04
-
存储空间
预留至少 20GB(含模型文件)
2. 一键安装方案
方案 A:新手友好型(秋叶整合包)
-
步骤
-
- 下载秋叶整合包
- 解压至非中文目录(如 D:\SD)
- 双击
启动器.exe,等待环境配置完成(约 5 分钟) - 浏览器自动打开
http://127.0.0.1:7860
有需要stable diffusion整合包以及提示词插件,可以扫描下方,免费获取

方案 B:技术流(手动部署)
-
步骤
-
-
安装 Python 3.10(勾选 “Add to PATH”)
-
安装 Git
-
克隆 WebUI 仓库:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
-
进入目录并启动:
cd stable-diffusion-webui webui-user.bat
-
3. 模型下载与管理
-
主流模型推荐
模型名称 适用场景 下载地址 Realistic Vision V5.1 人像写真 Hugging Face Anything V5 二次元动漫 Civitai Lyriel 梦幻风格 Civitai -
模型存放路径
stable-diffusion-webui/models/Stable-diffusion/
二、核心操作:10 分钟掌握文生图全流程
1. 界面布局解析
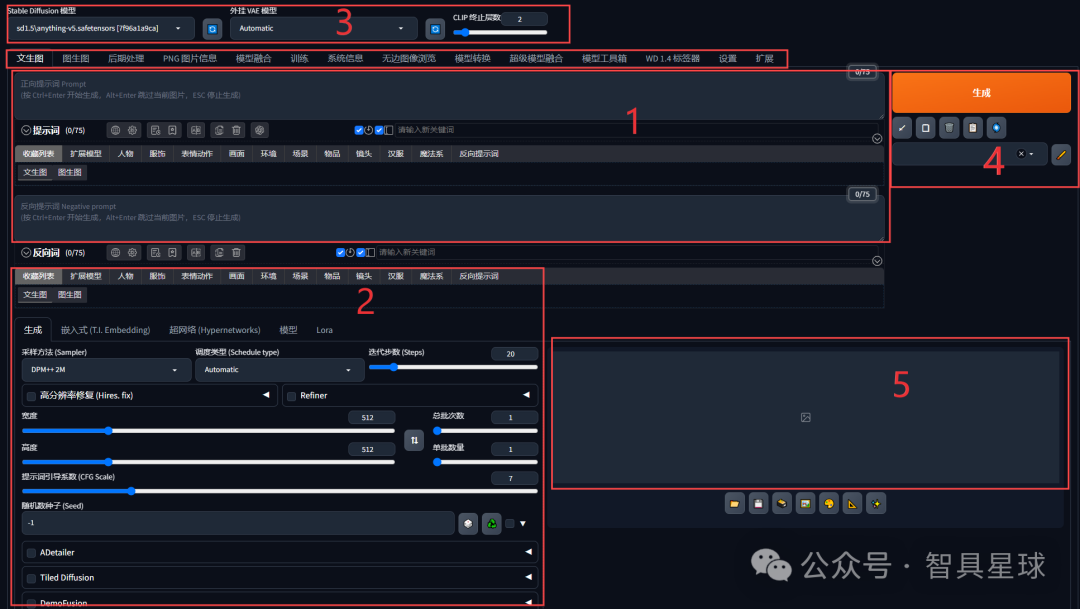
-
提示词输入区
输入生成指令(如 “赛博朋克城市夜景”)
-
参数设置区
调整生成参数(如步数、CFG Scale)
-
模型选择区
切换大模型、LoRA、VAE
-
生成按钮
开始生成图片
-
历史记录
查看过往生成记录
2. 提示词撰写技巧
基础公式:
主体 + 风格 + 环境 + 细节 + 质量控制``
示例:
(1girl:1.3), cyberpunk style, neon lights, futuristic cityscape, detailed cybernetic implants, (masterpiece, best quality):1.5
高级技巧:
-
权重调整
使用
()提升关键词权重(如(cyberpunk:1.2)) -
否定提示词
避免生成瑕疵(如
lowres, bad anatomy, watermark) -
风格组合
叠加多种风格(如
anime + oil painting)
3. 参数调优策略
关键参数说明:
| 参数名称 | 作用 | 推荐值 |
|---|---|---|
| 采样步数 (Steps) | 控制图像细节(步数越多越精细) | 25-50 |
| CFG Scale | 控制与提示词的贴合度 | 7-10 |
| 宽高比 | 常用比例:16:9(横版)/ 9:16(竖版) | 512x768 |
优化技巧:
-
高清修复
生成小图后使用 “高清修复” 功能放大(推荐 ESRGAN 模型)
-
面部修复
勾选 “GFPGAN” 提升人像面部细节
-
种子值 (Seed)
固定种子值可复现相同画面
三、实战案例:30 分钟产出商业级图片
案例 1:电商产品图生成
需求:生成一张 “白色运动鞋,运动场景,时尚风格” 的产品图
-
提示词
white sports shoes, running on a track, modern fashion style, high-quality product photography, (sharp focus, detailed textures):1.2 -
参数设置
-
- 模型:Realistic Vision V5.1
- 步数:35
- CFG Scale:8
案例 2:二次元角色设计
需求:生成 “银发少女,魔法学院制服,手持魔杖” 的角色图
-
提示词**
****silver-haired girl, magic academy uniform, holding a wand, fantasy style, (anime:1.4), dynamic pose, detailed magical effects
** -
参数设置
-
- 模型:Anything V5
- 步数:40
- CFG Scale:9
-
生成结果**
**

四、进阶工具:提升效率的秘密武器
1. ControlNet 插件
-
功能
精准控制画面结构(如人物姿势、建筑线条)
-
操作流程
-
- 安装插件:在 WebUI 扩展中搜索 “ControlNet”
- 上传参考图(如线稿或姿势图)
- 选择控制类型(如 OpenPose/Canny)
- 生成图片
-
示例
-
- 参考图:人物姿势照片 → 生成图:同姿势的赛博朋克风格人像
2. LoRA 模型
-
功能
微调模型风格(如特定画家风格或主题)
-
操作流程
-
- 下载 LoRA 模型(如 “宫崎骏风格”)
- 放置于
models/Lora/目录 - 在提示词中添加
lora:model_name:0.7
-
示例
-
- 原图:普通风景 → 应用 LoRA 后:宫崎骏风格动画场景
五、避坑指南:新手常见问题解决方案
1. 安装报错
-
问题
缺少依赖库(如 torch)
-
-
解决
使用整合包或手动安装
pip install torch
-
-
问题
显存不足
-
-
解决
降低分辨率或启用 “低显存模式”
-
2. 生成效果差
-
问题
画面模糊
-
-
解决
增加步数至 40+,开启 “高清修复”
-
-
问题
不符合预期
-
-
解决
调整 CFG Scale(值越大越贴合提示词)
-
3. 版权风险
-
商用注意
部分模型(如 SD v1)禁止商用,需购买 Stability AI 会员
-
素材版权
避免使用受版权保护的参考图或模型
一、快速部署:5 分钟开启 AI 绘画之旅
1. 硬件准备
-
显卡要求
NVIDIA 显卡(推荐 RTX 3060 及以上,显存 8GB+)
-
系统
Windows 10/11 或 Ubuntu 20.04
-
存储空间
预留至少 20GB(含模型文件)
2. 一键安装方案
方案 A:新手友好型(秋叶整合包)
-
步骤
-
- 下载秋叶整合包
- 解压至非中文目录(如 D:\SD)
- 双击
启动器.exe,等待环境配置完成(约 5 分钟) - 浏览器自动打开
http://127.0.0.1:7860
方案 B:技术流(手动部署)
-
步骤
-
-
安装 Python 3.10(勾选 “Add to PATH”)
-
安装 Git
-
克隆 WebUI 仓库:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
-
进入目录并启动:
cd stable-diffusion-webui webui-user.bat
-
3. 模型下载与管理
-
主流模型推荐
模型名称 适用场景 下载地址 Realistic Vision V5.1 人像写真 Hugging Face Anything V5 二次元动漫 Civitai Lyriel 梦幻风格 Civitai -
模型存放路径
stable-diffusion-webui/models/Stable-diffusion/
二、核心操作:10 分钟掌握文生图全流程
1. 界面布局解析
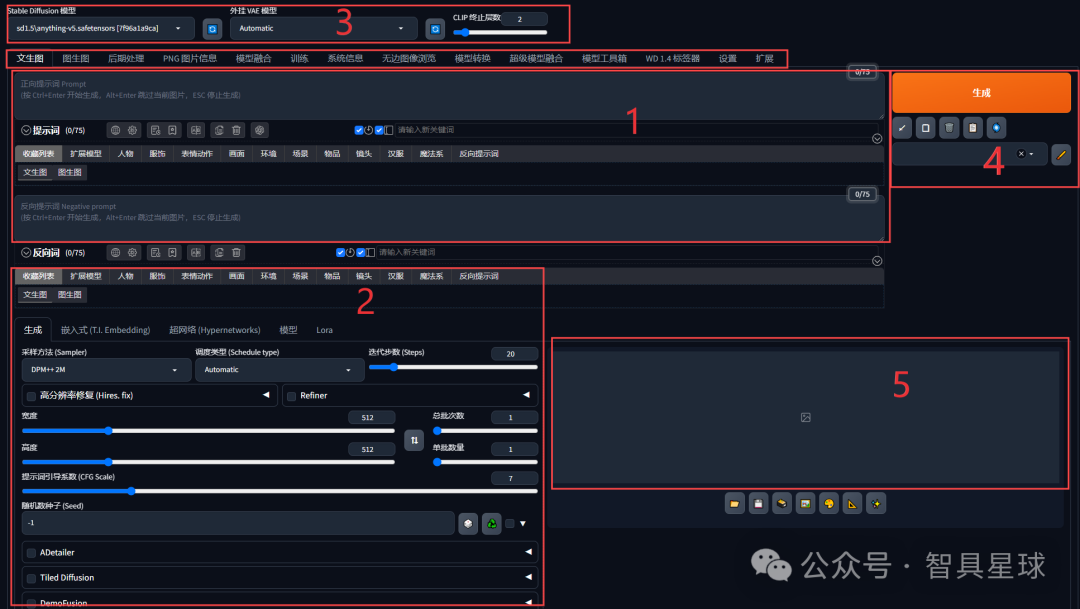
-
提示词输入区
输入生成指令(如 “赛博朋克城市夜景”)
-
参数设置区
调整生成参数(如步数、CFG Scale)
-
模型选择区
切换大模型、LoRA、VAE
-
生成按钮
开始生成图片
-
历史记录
查看过往生成记录
2. 提示词撰写技巧
基础公式:
主体 + 风格 + 环境 + 细节 + 质量控制``
示例:
(1girl:1.3), cyberpunk style, neon lights, futuristic cityscape, detailed cybernetic implants, (masterpiece, best quality):1.5
高级技巧:
-
权重调整
使用
()提升关键词权重(如(cyberpunk:1.2)) -
否定提示词
避免生成瑕疵(如
lowres, bad anatomy, watermark) -
风格组合
叠加多种风格(如
anime + oil painting)
3. 参数调优策略
关键参数说明:
| 参数名称 | 作用 | 推荐值 |
|---|---|---|
| 采样步数 (Steps) | 控制图像细节(步数越多越精细) | 25-50 |
| CFG Scale | 控制与提示词的贴合度 | 7-10 |
| 宽高比 | 常用比例:16:9(横版)/ 9:16(竖版) | 512x768 |
优化技巧:
-
高清修复
生成小图后使用 “高清修复” 功能放大(推荐 ESRGAN 模型)
-
面部修复
勾选 “GFPGAN” 提升人像面部细节
-
种子值 (Seed)
固定种子值可复现相同画面
三、实战案例:30 分钟产出商业级图片
案例 1:电商产品图生成
需求:生成一张 “白色运动鞋,运动场景,时尚风格” 的产品图
-
提示词
white sports shoes, running on a track, modern fashion style, high-quality product photography, (sharp focus, detailed textures):1.2 -
参数设置
-
- 模型:Realistic Vision V5.1
- 步数:35
- CFG Scale:8
案例 2:二次元角色设计
需求:生成 “银发少女,魔法学院制服,手持魔杖” 的角色图
-
提示词**
****silver-haired girl, magic academy uniform, holding a wand, fantasy style, (anime:1.4), dynamic pose, detailed magical effects
** -
参数设置
-
- 模型:Anything V5
- 步数:40
- CFG Scale:9
-
生成结果**
**

四、进阶工具:提升效率的秘密武器
1. ControlNet 插件
-
功能
精准控制画面结构(如人物姿势、建筑线条)
-
操作流程
-
- 安装插件:在 WebUI 扩展中搜索 “ControlNet”
- 上传参考图(如线稿或姿势图)
- 选择控制类型(如 OpenPose/Canny)
- 生成图片
-
示例
-
- 参考图:人物姿势照片 → 生成图:同姿势的赛博朋克风格人像
2. LoRA 模型
-
功能
微调模型风格(如特定画家风格或主题)
-
操作流程
-
- 下载 LoRA 模型(如 “宫崎骏风格”)
- 放置于
models/Lora/目录 - 在提示词中添加
lora:model_name:0.7
-
示例
-
- 原图:普通风景 → 应用 LoRA 后:宫崎骏风格动画场景
五、避坑指南:新手常见问题解决方案
1. 安装报错
-
问题
缺少依赖库(如 torch)
-
-
解决
使用整合包或手动安装
pip install torch
-
-
问题
显存不足
-
-
解决
降低分辨率或启用 “低显存模式”
-
2. 生成效果差
-
问题
画面模糊
-
-
解决
增加步数至 40+,开启 “高清修复”
-
-
问题
不符合预期
-
-
解决
调整 CFG Scale(值越大越贴合提示词)
-
3. 版权风险
-
商用注意
部分模型(如 SD v1)禁止商用,需购买 Stability AI 会员
-
素材版权
避免使用受版权保护的参考图或模型