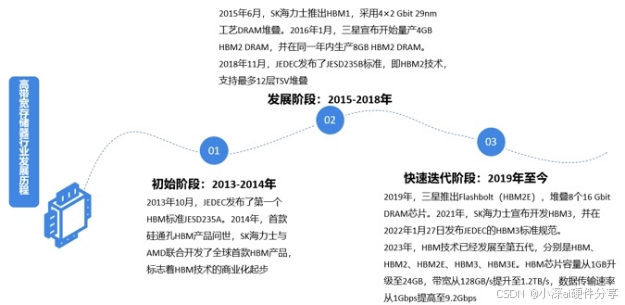
HBM:高带宽内存的崛起
在数据爆炸时代,HBM(高带宽内存)作为新型内存解决方案正崭露头角。它通过先进封装技术,将多个 DRAM 芯片垂直堆叠,借硅中介层与逻辑芯片相连。传统内存如独立小平房,HBM 则似高楼大厦,其叠层设计大幅提升存储密度与数据传输效率。
以数据比作汽车,传统内存的传输路径像又窄又长的公路,易拥堵,数据传输慢;HBM 的叠层设计则如宽阔高速公路,位宽增加、传输路径缩短,大大提高数据传输速度。
HBM 为数据中心和人工智能领域带来生机。在数据中心,凭高带宽、高容量特性,快速读写数据,提升处理效率;在人工智能领域,利用低延迟和高带宽优势,加速模型训练与推理,提升系统性能。HBM 已成为推动这两个领域发展的关键力量,提供坚实基础支撑 。
HBM2:性能飞跃的第二代
2016 年,HBM2 强势登场,它就像是 HBM 的一位进阶版 “选手”,相较于第一代 HBM,实现了性能的大幅跨越。这一代产品继续沿用了硅通孔(TSV)技术来堆叠 DRAM 芯片,使得存储密度和带宽进一步提升。打个比方,如果说 HBM 是在高速公路上增加了车道,那么 HBM2 则是在拓宽车道的同时,还提升了车辆的行驶速度。
从数据上看,HBM2 的典型数据速率从 HBM 的每引脚 1Gbps - 1.6Gbps 提升到了 2Gbps 至 3.2Gbps ,这就意味着数据传输的 “车辆” 跑得更快了。总带宽也随之大幅提升,能够达到每秒几百 GB,犹如一条更加宽阔的信息高速公路,让数据能够更加顺畅、快速地流通。
凭借这些显著的性能优势,HBM2 在 GPU 和高性能计算领域得到了极为广泛的应用。NVIDIA 的 V100 和 A100 GPU,以及 AMD 的 Vega 架构显卡等,都纷纷采用 HBM2 作为其显存,以充分发挥这些高端硬件的强大性能。在 NVIDIA 的 A100 GPU 中,HBM2 的运用使得它在处理大规模数据和复杂计算任务时,能够快速地从显存中读取和写入数据,大大提高了计算效率,为深度学习、科学计算等领域的应用提供了强有力的支持。在 AMD 的 Vega 架构显卡中,HBM2 显存与高带宽缓存控制器相结合,为显卡提供了更高带宽的缓存,有效提升了显卡在图形处理和游戏运行时的性能,让玩家能够享受到更加流畅、逼真的视觉体验。可以说,HBM2 的出现,为 GPU 和高性能计算领域的发展注入了强大的动力,推动了这些领域不断迈向新的高度。
HBM3:迈向更高性能

2020 年,HBM3 问世,在高带宽内存领域树立又一里程碑。它传承 HBM2 技术优势,实现带宽与容量双重飞跃,带来更卓越体验。
HBM3 带宽提升显著,最高超每秒 1TB 。打个比方,若 HBM2 是八车道高速公路,HBM3 则是十六条车道的超级高速公路,数据传输速度更快、流量更大。其数据处理速度优势明显,能在极短时间内完成大量数据读写,为复杂计算任务提供有力支撑。
功耗方面,HBM3 采用先进制程工艺与低功耗设计,在保证高性能的同时有效降低能耗,如同高速行驶还能降低油耗的汽车。
正因如此,HBM3 在高端 GPU 和数据中心广泛应用。NVIDIA 的 H100 GPU、AMD 的 MI300 系列等高端产品,都选用 HBM3 作为显存。H100 GPU 因 HBM3 显存,处理大规模数据与复杂计算时读写更迅速,提高计算效率,助力深度学习等领域。MI300 系列结合 HBM3 显存与高性能计算核心,满足专业用户对高性能计算的严苛需求。HBM3 为高端 GPU 和数据中心发展注入活力,推动其不断进步。
HBM3e:前沿的内存技术
HBM3e 作为 HBM3 的扩展版本,代表着当前内存技术的前沿水平。它在多方面实现突破,为人工智能和高性能计算提供强大动力支持。
带宽上,HBM3e 大幅提升,部分产品带宽能突破每秒 1.2TB,相比 HBM3,如同在十六条车道的高速公路上新增应急车道,拓宽数据传输通道,保障大规模数据快速处理。
容量方面,HBM3e 通过增加堆叠层数等技术得以扩充。三星、SK 海力士、美光等厂商推出的 12 层堆叠 HBM3e 产品,容量最高达 36GB ,满足了大数据处理需求。
在研发和生产上,三星 HBM3e 产品引脚速度 9.8Gbps,整体传输速率超 1.2TBps;SK 海力士率先量产 12 层堆叠 HBM3e,内存运行速度 9.6Gbps;美光 12 层堆栈产品容量 36GB,带宽超 1.2TB/s,传输速率超 9.2Gb/s,功耗低且有内置自测系统。
这些产品广泛应用于 AI 领域,在 AI 服务器、大型语言模型训练中,加速数据处理,提升模型性能,是推动 AI 技术发展的核心力量之一,未来将带来更多创新突破。
四者深度对比
为了让大家更清晰直观地了解 HBM、HBM2、HBM3 和 HBM3e 之间的差异,我们通过下面的表格来进行详细对比:
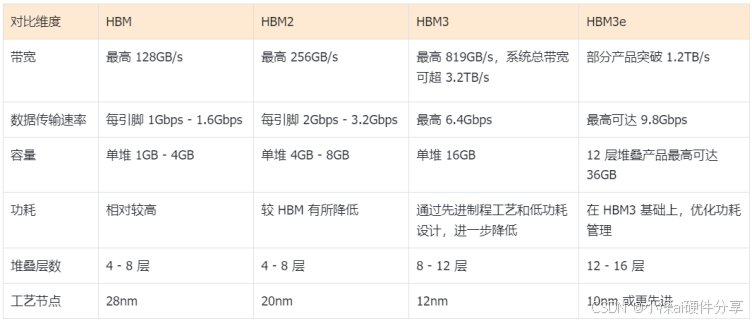
从表格中可以清晰地看出,随着技术的不断演进,HBM 系列产品在带宽、数据传输速率、容量等关键性能指标上都实现了显著提升,同时在功耗控制、堆叠层数和工艺节点等方面也取得了长足的进步。这一系列的技术突破,不仅为人工智能、高性能计算等领域带来了更强大的动力支持,也为未来的科技发展奠定了坚实的基础。
HBM 家族的未来展望
展望未来,HBM 技术有望多维度进化。
性能上,技术突破将提升带宽和数据传输速率,为人工智能、高性能计算等领域提供更强算力,如 SK 海力士计划开发的新 HBM 内存标准性能预计比当前快 20 到 30 倍。
成本方面,一直是普及障碍,厂商将通过优化制造工艺、采用新材料、扩大生产规模等降低成本,浙江禾芯的非 TSV 的 HBM 芯片封装结构专利提供了新思路。
散热是关键问题,未来有望通过改进封装技术、采用新型散热材料解决,如混合键合技术改善了热管理。
随着 5G、物联网、人工智能等技术发展,数据量爆发式增长,对高带宽、大容量内存需求迫切,HBM 凭借卓越性能,有望在数据中心、人工智能等多领域广泛应用,推动技术创新与发展 。