我最近购买了四台 GH200 服务器,用于试用和探索它们在 Transformer 模型推理和训练方面的潜在优势。我的背景是基础设施和系统工程领域,过去一年来,我一直在研究 GenAI 和 Transformer。“统一内存”(从技术上讲这不是)和 InfiniBand 上的 GPUDirect 的概念似乎很有趣。
我将在这些博客中测试的特定系统是Supermicro ARS-111GL-NHR。我当前的设置还包含一个 Bluefield-3 卡和 Mellanox SN3700 交换机,用于通过 2x200Gbps 以太网(总共 400Gbps)互连节点。
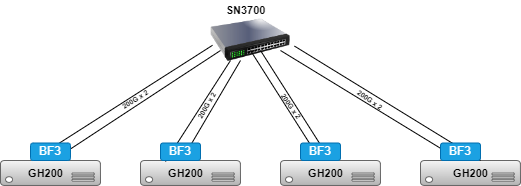
4xGH200 和 Nvidia SN3700 切换
Nvidia 确实销售另一种基于 GH200 的系统,其性能要高得多,但我选择了成本较低的 Supermicro 路线,只是为了尝试和了解该架构。GPTShop.ai也有一个桌面版的 GH200 架构,Phoronix 在多篇文章中对其进行了评论。
GH200 架构
GH200 中的“GH”代表 Grace Hopper。这是 Nvidia“Grace”CPU 架构和“Hopper”GPU 架构的组合。将它们组合在一起,Nvidia 能够有效地控制整个系统和互连,以确保最高水平的性能。如果您感兴趣,Nvidia 会详细介绍。
当前基于 GPU 的系统的主要缺点之一是 PCIe 总线的速度。Nvidia 创建了 NVLink 作为高带宽/低延迟互连,因此它们不依赖 PCIe 进行 GPU 到 GPU 的内存传输。对于 Grace Hopper,他们使用 NVLink 将 CPU 连接到 GPU,这意味着 GPU 不再需要依赖 PCIe 在系统内存和 GPU 内存之间进行传输。
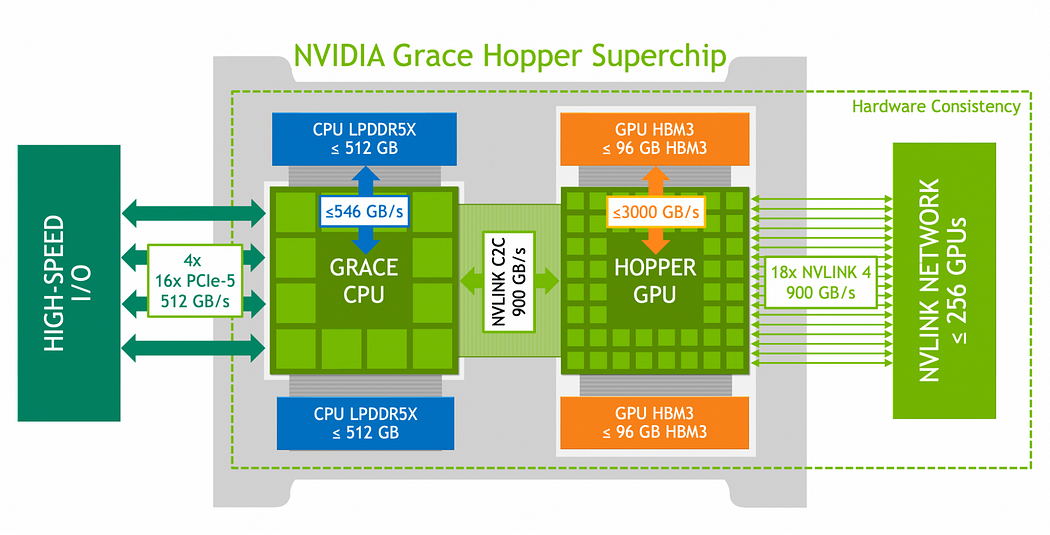
Nvidia GH200 架构
这不是“统一记忆”……
很多人说 GH200 是一种“统一内存”架构,希望它与Apple 在新款 Mac 中所做的类似。但事实并非如此。这可能会产生误导,因为当您运行htop或时cat /proc/meminfo,系统会同时显示 CPU 和 GPU 内存。但是,如上图所示,CPU 有 LPDDR5X(在我的情况下是 480GB),GPU 有 HBM3(96GB)。内存速度不同,芯片也不同。如果您尝试将 140GB 的 Llama-3 权重加载到内存中,您将遇到 OOM 故障。您可以在 FP8 中加载 70B 模型。有关这方面的更多信息,请参阅未来的博客。
不过,拥有这种高速总线也有一些好处,例如 GPU 可以访问存储、网络和系统的其他部分。稍后会详细介绍……
安装操作系统和 Nvidia 驱动程序
我花了一个多星期才设置好第一个服务器并使其正常运行。Nvidia 在这方面的文档并不好(因此写了这篇博客)。对于自动安装,我创建了一个可以轻松修改以供您使用的 repo。目前,安装需要互联网连接才能安装必要的软件包:GitHub - drikster80/gh200-Ubuntu-22.04-autoinstall: Automated installation of GH200 system using Ubuntu 22.04
在此过程中我学到了几个关键点:
- Nvidia 有Ubuntu和RHEL/Rocky 9的安装手册。我花了很长时间才找到这些。
- 建议使用 64K 内核页面大小版本的内核。对于 Ubuntu,Nvidia 在 Ubuntu Repo 中有自己的内核版本(`linux-nvidia-64k-hwe-22.04`)
- 使用 Nvidia “Open” 驱动程序 (nvidia-kernel-open-555),而不是专有版本
- 安装软件包的顺序确实很重要
- apt-get install -y mlnx-fw-updater mlnx-ofed-all (适用于 Bluefield-3 卡)
- apt-get 安装 -y cuda-drivers-555 nvidia-kernel-open-555
- apt-get install -y cuda-toolkit-12-4 nvidia-container-toolkit
- 为 nvidia-persistenced 创建服务
安装后检查系统:
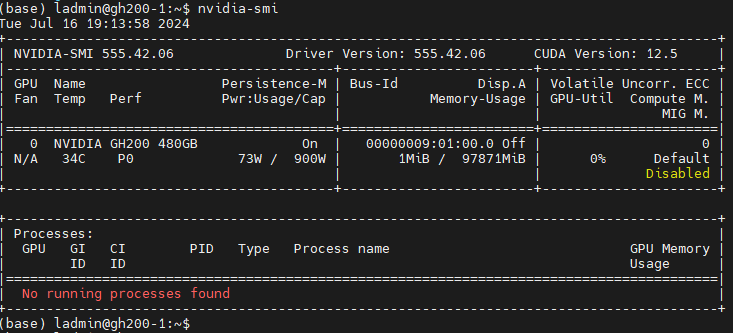
系统安装完成后,您应该能够运行“nvidia-smi”并查看 GH200 GPU(它只是一个带有 96GB 或 144GB HMB3 的 H100)。需要注意以下几点:
- 功耗显示为 900W,而不是普通 H100 显示的 350W。我假设这里同时考虑了 CPU 和 GPU。在我运行推理的测试中,我从未见过服务器总功耗超过 700W。
- GPU 显示 GPU 内存为 97871MiB (96GB)。
运行时htop将显示具有 574G 内存的系统的不同图片,这是 480GB LPDDR5X 系统内存和 96GB HBM3 GPU 内存的组合。我相信这就是围绕“统一内存”的很多混乱的来源,但不幸的是它实际上并不是那样工作的。
您还可以看到 ARM64 Grace 处理器的 72 个核心:

NCCL测试
在这篇文章中,我们将深入研究节点间 GPU 通信路径,并使用 NVIDIA 集体通信库 (NCCL)(发音为“nickel”)通过 RoCE(融合以太网上的 RDMA)测试 GPU 到 GPU 的直接内存访问。NCCL-Tests是 Nvidia 提供的开源工具,用于在执行某些功能(例如 all_reduce、all_gather 等)时测试 GPU 之间的带宽和操作速度。我们将介绍如何在 GH200 上构建它并在节点之间运行一些测试。我们还将它与较旧的 4xA100(NVLink)系统进行比较,以便我们可以看到架构差异以及它与整体性能的关系。
您可以深入了解 NCCL 如何优化 GPU 之间的通信。需要了解的主要一点是,在运行时,它会尝试找到用于 GPU 间通信的最佳路径和结构,并在您在应用程序中调用它时设置所有内容(包括环或树、RDMA 等)。
如果您有兴趣深入了解,请查看 NCCL 文档:Overview of NCCL — NCCL 2.26.2 documentation
查看 GH200 互连:
首先,我们来看一下GPU信息:
<span style="background-color:#f9f9f9"><span style="color:#242424">nvidia-smi</span></span>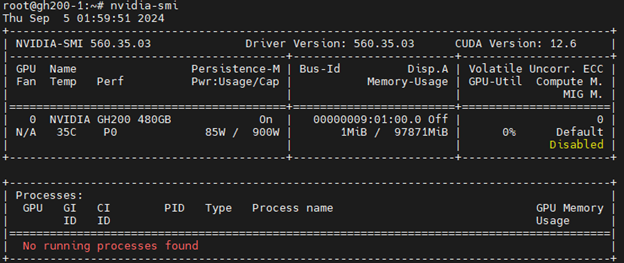
GH200 配备单个 GPU(H100–96GB)。对于此设置,我们运行驱动程序 560 + CUDA 12.6。
我们可以使用“nvidia-smi topo -m”查看拓扑。这将告诉我们数据如何在 GPU 和网络组件之间传输。
<span style="background-color:#f9f9f9"><span style="color:#242424">nvidia-smi topo -m</span></span>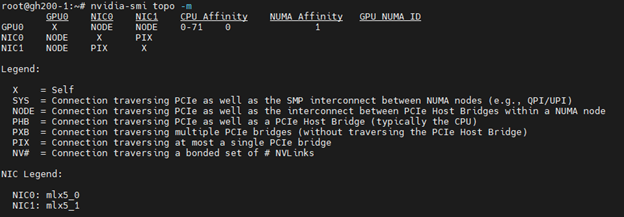
我们可以看到 H100 GPU 以及 Bluefield-3 NIC 以及它们如何在系统内进行通信。
NODE意味着 GPU 和 NIC 之间的通信将穿过 CPU(在本例中为单个 NUMA)。通常情况下,这不是最理想的,但由于 GH200 在 CPU 和 GPU 之间有 NVLink,因此它实际上比通过 PCIe 通道更有效率。
PIX表示 2 个网络接口位于同一物理卡上。
为了进行比较,这是我的旧 4xA100 系统的拓扑结构,它要复杂得多。它有两个 CPU(例如 2 个 NUMA)、两个 Bluefield-2,每对 A100 卡都通过 NVLink 连接。
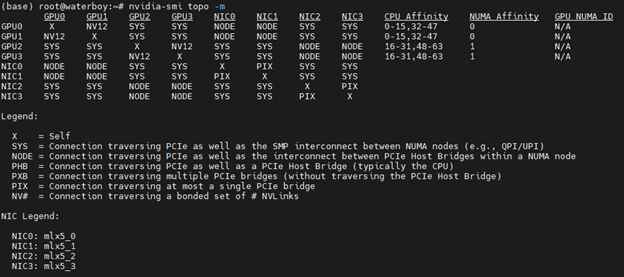
在这种情况下,即使 GPU0 和 GPU2 位于同一台服务器中,连接到同一块主板,它实际上也比两个 GH200 节点通过网络相互通信慢得多。这是因为该系统中的通信路径是 GP0 (PCIe 4.0) → CPU0 → CPU1 → GPU2 (PCIe 4.0)。GPU1 和 GPU3 也是如此。
当我们运行 NCCL 测试时,我们将更详细地了解这一点。这意味着现在我们需要构建它们……
在 Grace Hopper 上构建 NCCL 测试
NCCL-Test 使用 MPI(消息传递接口)进行节点间通信。不幸的是,Ubuntu repo 中的 OpenMPI 较旧,并且与 nvidia 驱动程序 repo 中的软件包冲突,因此我们需要下载并构建最新版本的 OpenMPI:
注意:在所有节点上重复这些说明。
步骤1:安装依赖项:
<span style="background-color:#f9f9f9"><span style="color:#242424">sudo apt-get 安装 libpmix-dev libfabric-dev libev-dev zlib1g-dev</span></span>步骤 2:下载并解压最新版本的 OpenMPI(撰写本文时为 5.0.5)
<span style="background-color:#f9f9f9"><span style="color:#242424">wget https://download.open-mpi.org/release/open-mpi/v5.0/openmpi-5.0.5.tar.gz
tar xzf openmpi-5.0.5.tar.gz
<span style="color:#5c2699">cd</span> openmpi-5.0.5/</span></span>步骤 3:配置(45 秒)、构建(74 秒)和安装(12 秒)源代码
<span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#007400"># 注意:安装到 /opt/openmpi 以防我们稍后需要删除。</span>
<span style="color:#007400"># 这将要求我们接下来导出 $PATH 和 $LD_LIBRARY_PATH</span>
./configure --prefix=/opt/openmpi \
--enable-mpi-ext=cuda \
--with-cuda=/usr/local/cuda \
--with-cuda-libdir=/usr/local/cuda/lib64 \
--with-ucx --with-libfabric --enable-builtin-atomics \
--without-cma --with-libevent=external \
--with-hwloc=external --disable-silent-rules \
--enable-ipv6 --with-devel-headers \
--with-slurm --with-sge --without-tm --with-zlib \
--enable-heterogeneous 2>&1 | <span style="color:#5c2699">tee</span> config.out
make -j 72 all 2>&1 | <span style="color:#5c2699">tee</span> make.out
sudo make install 2>&1 | <span style="color:#5c2699">tee</span> install.out</span></span>步骤 4:将我们刚刚安装的 OpenMPI 的路径导出到 /opt/openmpi
<span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#5c2699">导出</span>PATH=/opt/openmpi/bin/:<span style="color:#3f6e74">$PATH</span>
<span style="color:#5c2699">导出</span>LD_LIBRARY_PATH=/opt/openmpi/lib/:<span style="color:#3f6e74">$LD_LIBRARY_PATH</span></span></span>现在我们可以构建具有 MPI 支持的 nccl-tests(在所有节点上重复):
步骤 1:安装 nccl-tests 构建依赖项
<span style="background-color:#f9f9f9"><span style="color:#242424">sudo apt-get 安装 libnccl-dev</span></span>第 2 步:克隆 repo
<span style="background-color:#f9f9f9"><span style="color:#242424">git<span style="color:#5c2699">克隆</span>https://github.com/NVIDIA/nccl-tests.git</span></span>步骤 3:构建测试二进制文件(25 秒):
<span style="background-color:#f9f9f9"><span style="color:#242424">使-j 72 MPI = 1 MPI_HOME = / opt / openmpi CUDA_HOME = / usr / local / cuda /</span></span>运行一些 nccl 测试
此时我们可以开始运行测试。我不会深入解释测试中所有内容的含义……但您可以在 GitHub 上的PERFORMANCE.md中阅读有关不同测试的更多信息。
我们主要关注的是总线带宽测量。
单节点测试:
<span style="background-color:#f9f9f9"><span style="color:#242424">./build/all_reduce_perf -b 8 -e 2048M -f 2 -g 1</span></span>该命令具有以下标志:
-b 8 :从 8 字节开始
-e 2048M :以 2GB 结束
-f 2 :起始和结束尺寸之间增加 2 倍
-g 1:仅使用单个 GPU(GH200 中仅安装 1 个)
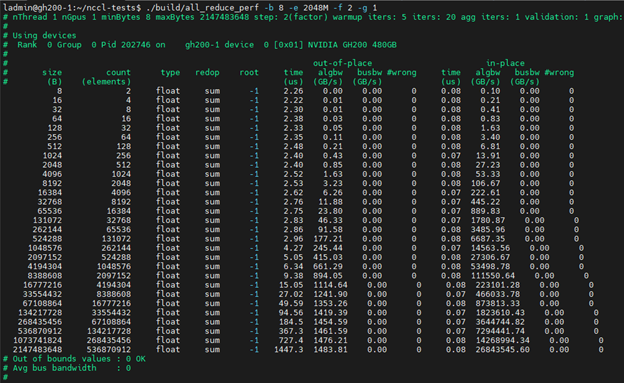
您会注意到算法带宽非常大,但这是因为我们只使用单个 GPU,因此没有使用实际带宽。这只是为了显示命令标志并确保它可以以最不复杂的形式运行。
多节点测试:
在本测试中,我们将研究节点间的 GPU 通信。首先,确保在主节点和所有其他节点之间设置了无密码 ssh 。
我们将运行与之前相同的测试,但使用 MPI 并在两个节点之间运行:
<span style="background-color:#f9f9f9"><span style="color:#242424">mpirun -np 2 -host localhost,172.16.10.12 ./build/all_reduce_perf \
-b 8 -e 2048M -f 2 -g 1</span></span>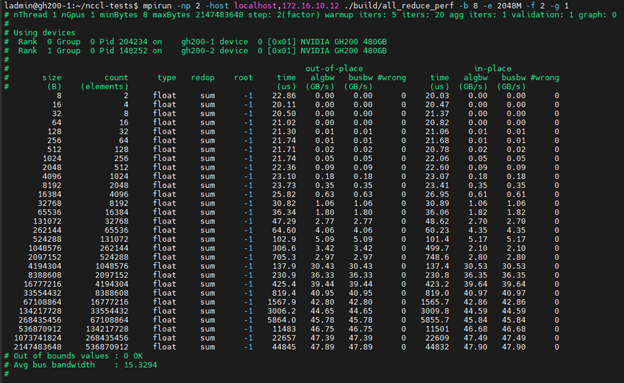
算法速度和总线带宽最高约为 ~48GB/s (~384Gbps)。这实际上是 RoCE 的最大可用带宽,我们将在单个节点上使用单个 Bluefield-3 卡 (2x200Gbps 端口) 来查看。
如果我们查看这两个端口,您会注意到其中只有一个具有 IP 地址:
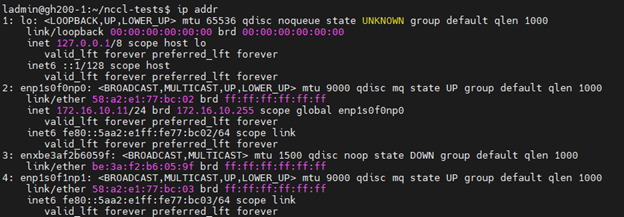
这意味着 NCCL 发现两个端口均可用于节点间通信,即使只有一个端口能够通过 IPv4 进行通信。
让我们更深入地了解一下幕后发生了什么。为此,我们将告诉 NCCL 使用环境变量“NCCL_DEBUG=Info”显示更多调试信息(以及将起始值增加到 65k,因为低于这个值是没有意义的)
<span style="background-color:#f9f9f9"><span style="color:#242424">NCCL_DEBUG=信息 mpirun -np 2 -host localhost,172.16.10.12 \
./build/all_reduce_perf -b 65k -e 2048M -f 2 -g 1</span></span>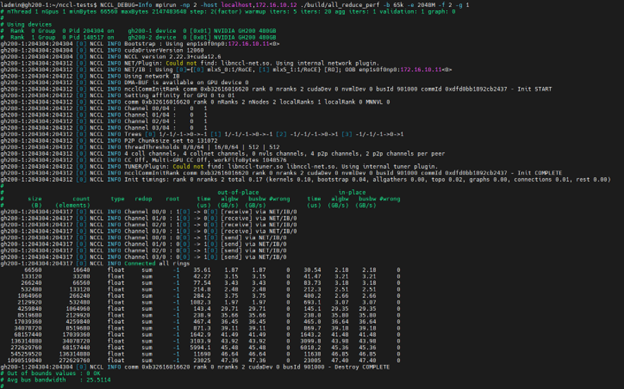
(注意:关于未找到 libnccl-net.so 的警告是无害的,仅适用于 InfiniBand。在此设置中,我们使用 RoCE 作为 Infiniband 路径)
您可以看到,它将具有 IP 地址的端口标识为“带外”接口,将两个端口标识为支持 RoCE/IB,并确定它需要具有 4 个通道的树算法。还值得注意的是,它选择了 DMA-BUF(而不是传统的“nvidia-peermem”),这是直接内存访问的默认选择,并在较新的内核中受支持。
您可以尝试使用环境变量来调整一些其他旋钮和刻度盘,例如:NCCL_NSOCKS_PERTHREAD、NCCL_SOCKET_NTHREADS,但我发现 NCCL 使用的设置似乎可以最大限度地提高带宽。
与 4xA100 节点的比较
当我们在一台拥有 4 个 A100 GPU 并连接到 2 个处理器的服务器上运行相同的测试时,我们可以看到算法带宽下降到 13.6GB/s,总线带宽最高达到 ~20GB/s:
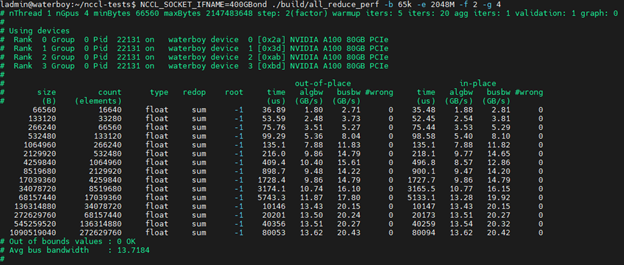
20.42GB/秒 = 163.36Gbps
值得注意的是,A100 卡是 PCIe Gen 4.0(x16 通道)。其最大理论带宽为 31.5GB/s。因此,我们可能还会因遍历 NUMA 节点而损失一些带宽。
现在,让我们在通过 NVLink 连接的 2 张 A100 卡上运行测试:
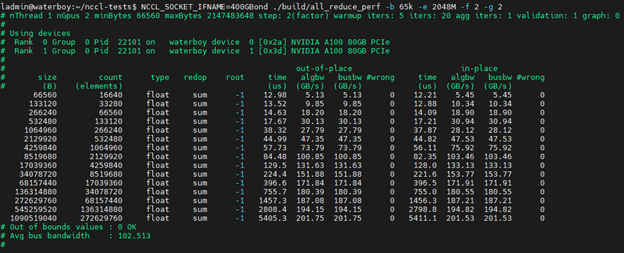
您可以看到 2 与 4 相比,运行速度提高了 10 倍。这是由于两个 GPU 之间的 NVLink 带宽避免了 PCIe 通信,并允许每个 GPU 通过非常高速的互连直接与对方的内存通信。
因此,在该系统上执行推理时,将其拆分到 2 个 GPU 上比拆分到所有 4 个 GPU 上要快得多。(这也是 Nvidia 股票性能如此之高的原因!)
专业提示:如果模型太大,无法放入 2 个 GPU 的内存中,但您又不想使用 NUMA 降低其速度,则可以使用架构技巧有效地将服务器拆分为 2 个独立的推理节点,并在它们之间创建一个射线集群。然后在 2 个 NVlink 节点中的每一个上使用张量并行,并在 NUMA 节点之间使用管道并行。但我们将在下一篇博文中讨论这个问题以及更多多节点推理架构构建……