简介
本文深度解析基于 NVIDIA H20-3e 141G GPU 的 AI 开发全流程,重点呈现其相比前代 H20 在硬件架构、显存容量(141GB vs 96GB)及计算效率上的跨越式升级。通过 LLaMA Factory 框架实现 Qwen2.5-14B 模型的监督微调(SFT)训练,结合 Transformer 引擎与多实例 GPU 技术,突破传统显存限制,实现混合精度训练吞吐量提升。在推理环节,vllm 引擎借助 H20-3e 的 FP8 计算核心与更快的 NVLink 互联,使 DeepSeek-R1-FP8 671B 超大模型的全量推理成为现实,实测单卡吞吐量较 H20 提升倍,同时保持数值精度一致性。文章还对比了 H20-3e 在训练稳定性、推理延迟等方面的优化表现,验证其作为新一代 AI 计算平台的技术优势。
平台部分
驱动安装
首先需要安装NVIDIA-driver-xxx以及NVIDIA Fabricmanager-xxx,这两者都可以通过apt安装或者通过NVIDIA 官网进行下载安装,安装部分不再赘述,其中后者尤其重要,因为其关乎NVLINK能否正常使用
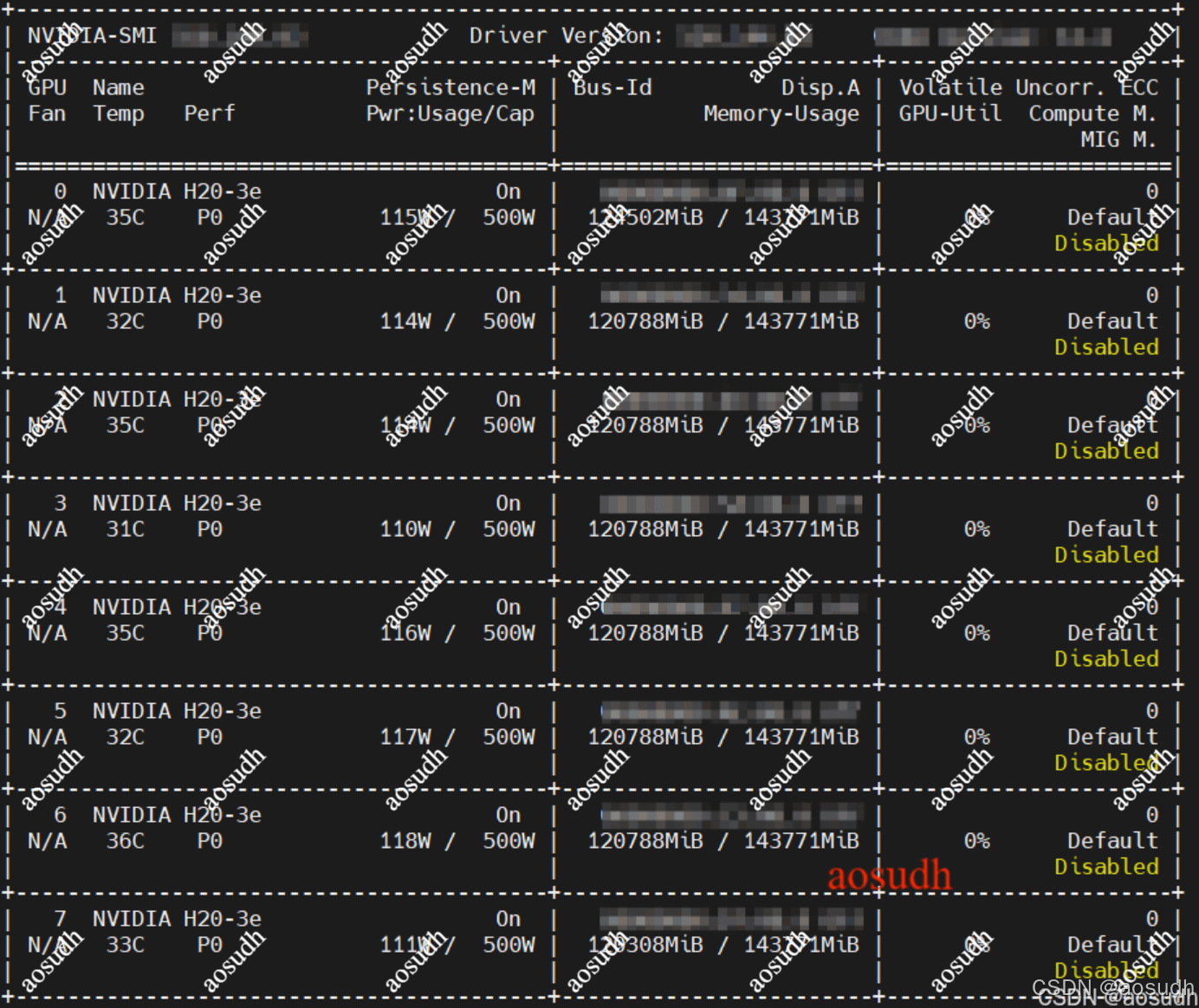

安装docker
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpgecho "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/nullsudo apt updatesudo apt install docker-ce docker-ce-cli containerd.io配置NVIDIA-docker-toolkit
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.listsudo apt-get install -y nvidia-container-toolkitsudo nvidia-ctk runtime configure --runtime=dockersudo systemctl restart docker假如运行完上述代码后没有报错,说明已经安装成功
简单测试
直接从NGC拖适合驱动版本的m5c镜像,之后从GitHub - NVIDIA/cuda-samples at v12.4.1
与GitHub - wilicc/gpu-burn: Multi-GPU CUDA stress test,中下载即可
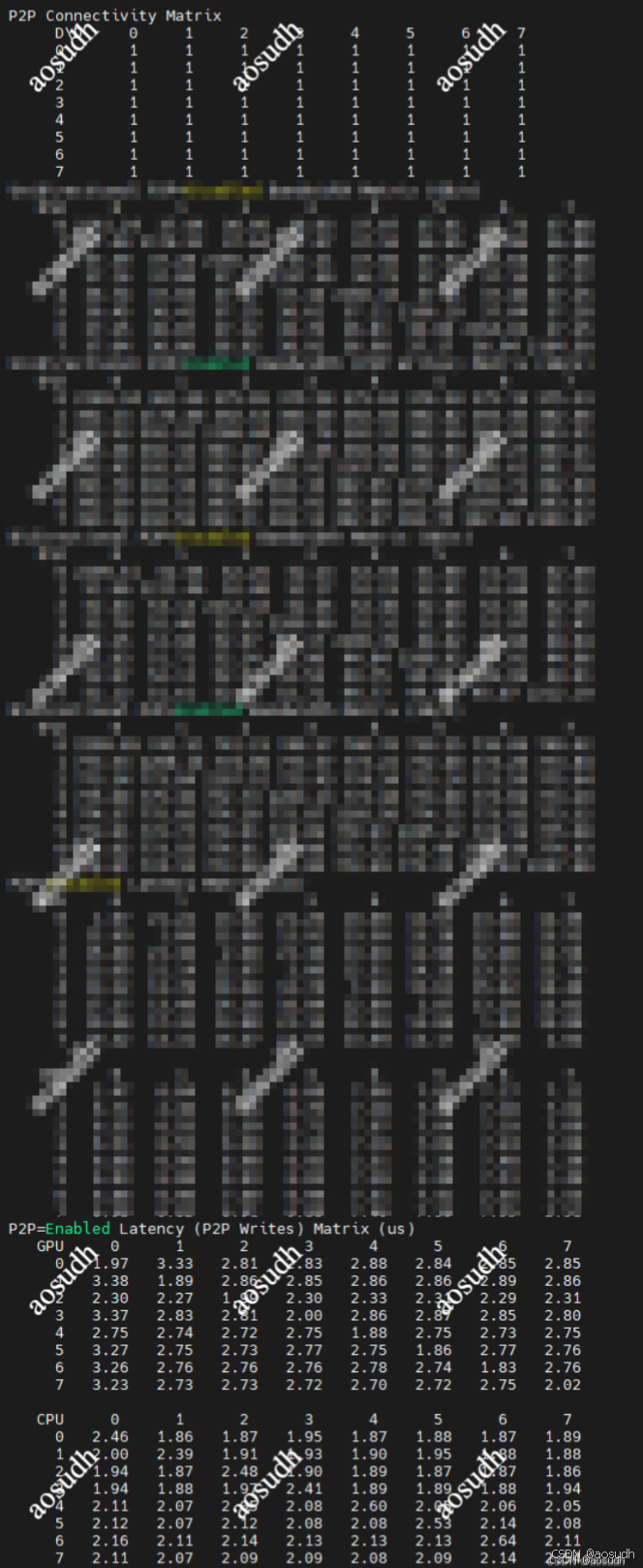
P2P 性能简单测试
GPU burn测试
不知道为什么,在跑到将近30秒的时候算力会突然倍增

训练部分
下载镜像
从NGC 镜像站中下载较新的pytorch 镜像PyTorch | NVIDIA NGC
docker pull nvcr.io/nvidia/pytorch:xx.xx-py3然后本地通过下面的命令启动镜像,其中,network与ipc=host较为重要,决定了容器内网络的状态以及宿主机允许直通给容器的资源数量和性能
docker run -v 宿主机路径:容器内需要挂在的路径 --privileged --network=host --ulimit stack=68719476736 --ipc=host --entrypoint=/bin/bash --gpus all -it nvcr.io/nvidia/pytorch:xx.xx-py3
安装LLAMA Factory
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
在输入上述命令后,可能会出现一些在线或离线安装pip包的过程,其中有些包的兼容性可能存在冲突,但是假如是不常用的包可以直接不管
成功安装后,输入下面的命令,能成功运行即为安装成功
llamafactory-cli version
修改SFT配置文件
进入examples/train_lora/llama3_lora_sft.yaml配置文件
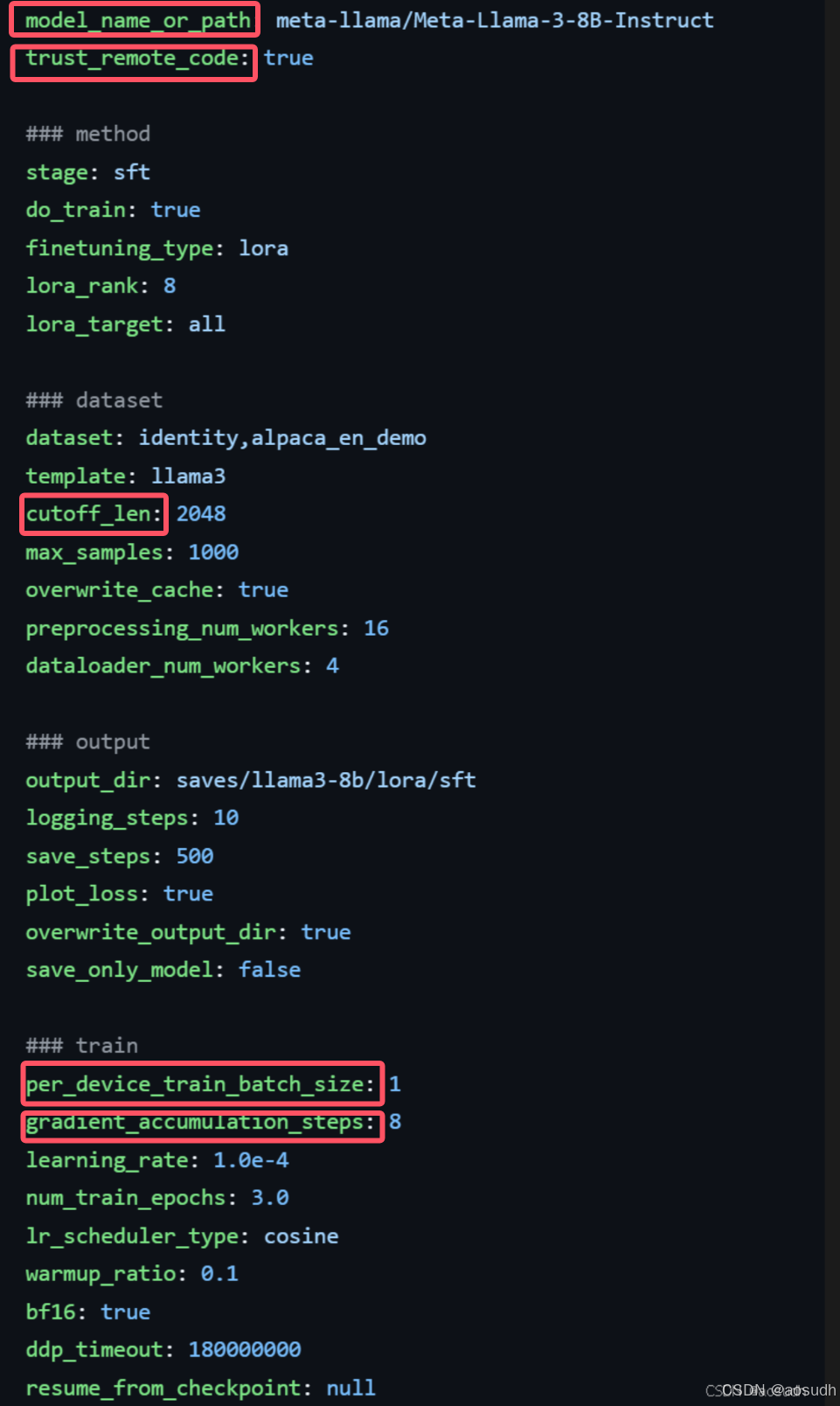
主要需要修改的有几点
modelnameorpah:根据本地或云端模型的路径位置修改
trust_remote_code: 假如模型在本地就删掉,假如是云端模型需要下载的就保留
dataset:数据集实际路径,也可以选择/data目录下有的示例数据集
cutoff lengh:实际输入padding长度,根据实际数据集输入修改
batch_size与accumulation_step:按需修改
启动训练
进入LLaMa factory 工程主目录
llamafactory-cli train ./examples/train_lora/llama3_lora_sft.yaml
训练占用
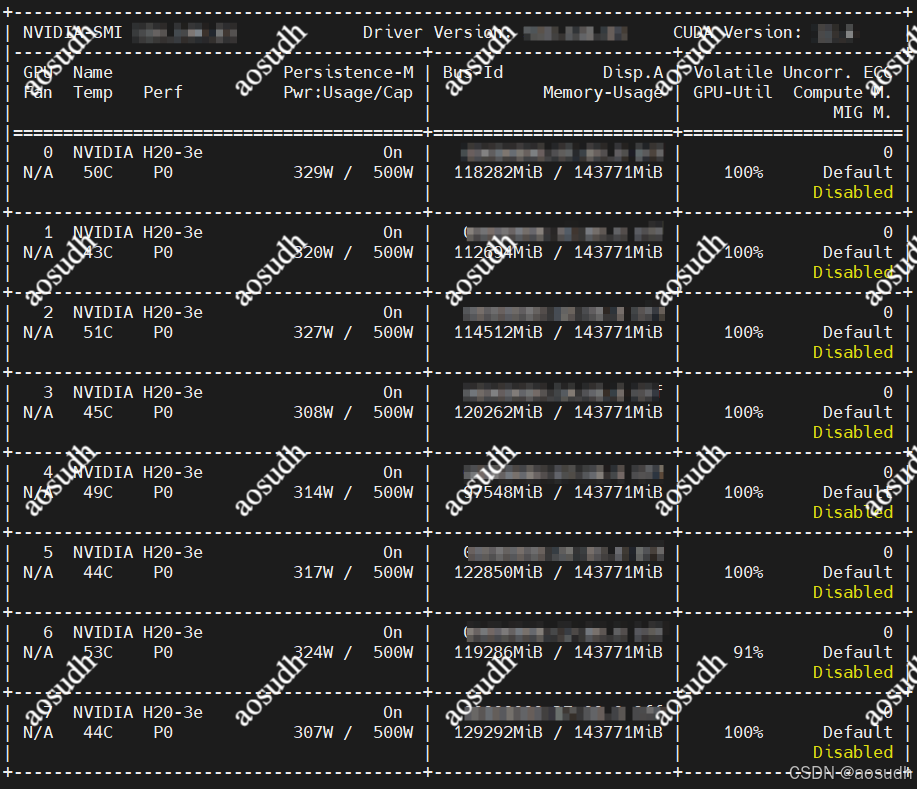
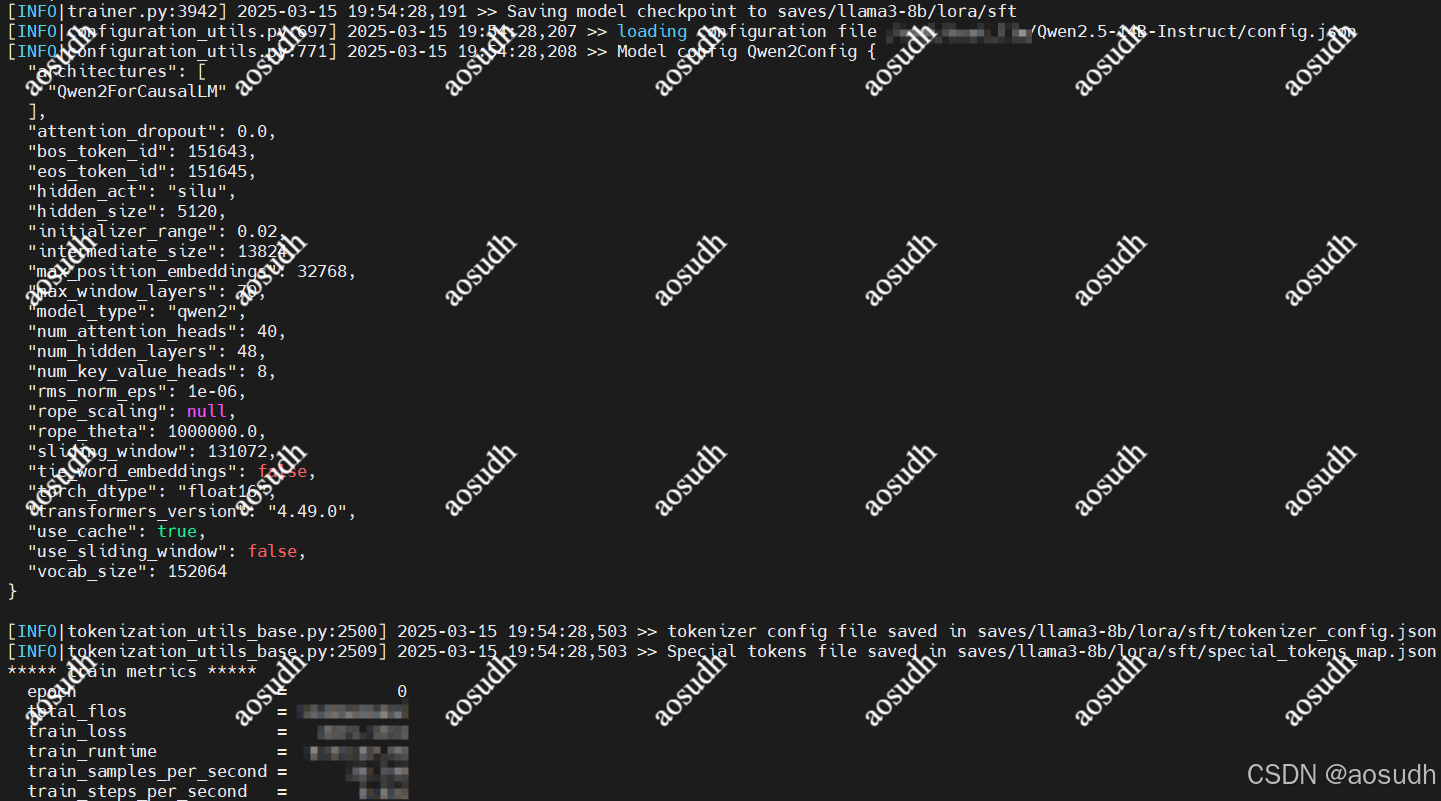
最后出现下图结果,即为训练完成
推理部分
下载镜像
docker pull docker.io/vllm/vllm-openai:v0.7.3docker run -v 宿主机路径:容器内需要挂在的路径 --privileged --network=host --ulimit stack=68719476736 --ipc=host --entrypoint=/bin/bash --gpus all -it docker.io/vllm/vllm-openai:v0.7.3启动后输入
vllm -v出现下图即为安装成功

运行推理
首先,下载好全量的FP8 DeepSeek-R1 模型,然后输入(deepseek的模型推理命名一般就为deepseek-reasoner)
python3 -m vllm.entrypoints.openai.api_server --host 0.0.0.0 --max-model-len 65536 --max-num-batched-tokens 65536 --trust-remote-code --tensor-parallel-size 8 --gpu-memory-utilization 0.9 --served-model-name deepseek-reasoner --model 容器内模型路径最后出现图片中的结果,即为部署成功

实际部署占用
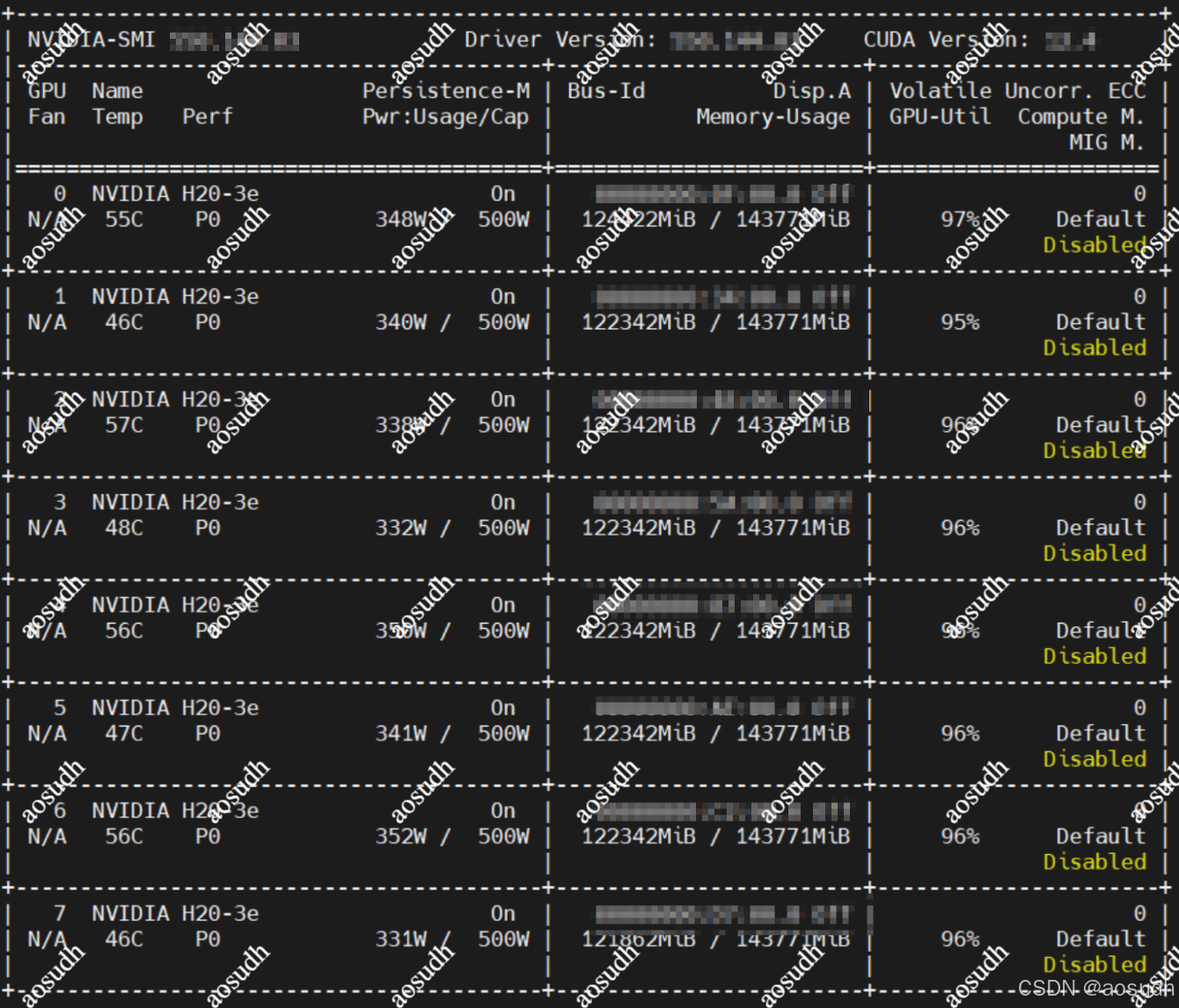
API 调用
首先需要pip 安装 openai
单并发
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="token-abc123",
)
completion = client.chat.completions.create(
model="deepseek-reasoner",
messages=[
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message.content)
from openai import OpenAI
import threading
import queue
import sys
from concurrent.futures import ThreadPoolExecutor, as_completed
class AsyncStreamProcessor:
def __init__(self, base_url="http://localhost:8000/v1", max_workers=4):
self.client = OpenAI(base_url=base_url, api_key="None")
self.max_workers = max_workers
self.executor = ThreadPoolExecutor(max_workers=max_workers)
def process_stream(self, response, output_queue):
try:
for chunk in response:
if chunk.choices[0].delta.content is not None:
output_queue.put(chunk.choices[0].delta.content)
except Exception as e:
output_queue.put(f"Error: {str(e)}")
finally:
output_queue.put(None)
def print_output(self, output_queue, request_id):
while True:
content = output_queue.get()
if content is None:
break
print(f"Request {request_id}: {content}", end="", flush=True)
print() # Final newline
def process_single_request(self, prompt, request_id):
output_queue = queue.Queue()
try:
response = self.client.chat.completions.create(
model="/root/model/DeepSeek-R1-Distill-Qwen-32B/",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
}
],
}
],
temperature=0.6,
stream=True
)
# Create and start the stream processing thread
stream_thread = threading.Thread(
target=self.process_stream,
args=(response, output_queue)
)
stream_thread.start()
# Create and start the printing thread
print_thread = threading.Thread(
target=self.print_output,
args=(output_queue, request_id)
)
print_thread.start()
# Wait for both threads to complete
stream_thread.join()
print_thread.join()
return f"Request {request_id} completed"
except Exception as e:
return f"Request {request_id} failed: {str(e)}"
def process_multiple_requests(self, prompts):
futures = []
# Submit all requests to the thread pool
for idx, prompt in enumerate(prompts):
future = self.executor.submit(
self.process_single_request,
prompt,
idx + 1
)
futures.append(future)
# Wait for all requests to complete and get results
results = []
for future in as_completed(futures):
results.append(future.result())
return results
def shutdown(self):
self.executor.shutdown(wait=True)
def main():
# Example prompts
prompts = [
"""已知函数 $f(x) = \ln \frac{x}{2-x} + ax + b(x-1)^3$
(1) 若 $b=0$,且 $f'(x) \geq 0$,求 $a$ 的最小值;""",
"""已知函数 $f(x) = \ln \frac{x}{2-x} + ax + b(x-1)^3$
(2) 证明:曲线 $y=f(x)$ 是中心对称图形;""",
"""已知函数 $f(x) = \ln \frac{x}{2-x} + ax + b(x-1)^3$
(3) 若 $f(x) > -2$ 当且仅当 $1 < x < 2$,求 $b$ 的取值范围。"""
]
# Initialize the processor with 4 worker threads
processor = AsyncStreamProcessor(max_workers=4)
try:
# Process all requests
results = processor.process_multiple_requests(prompts)
# Print final results
print("\nFinal results:")
for result in results:
print(result)
finally:
# Ensure the thread pool is properly shut down
processor.shutdown()
if __name__ == "__main__":
main()