一、简介
K-means 聚类是一种非常流行的基于距离的无监督学习算法,用于将数据点划分为预定义的 K 个簇(或组),其中每个簇由其质心(即簇中所有点的均值)定义。K-means 算法的目标是使簇内的点尽可能紧密地聚集在一起,同时使不同簇之间的点尽可能远离。
二、算法原理

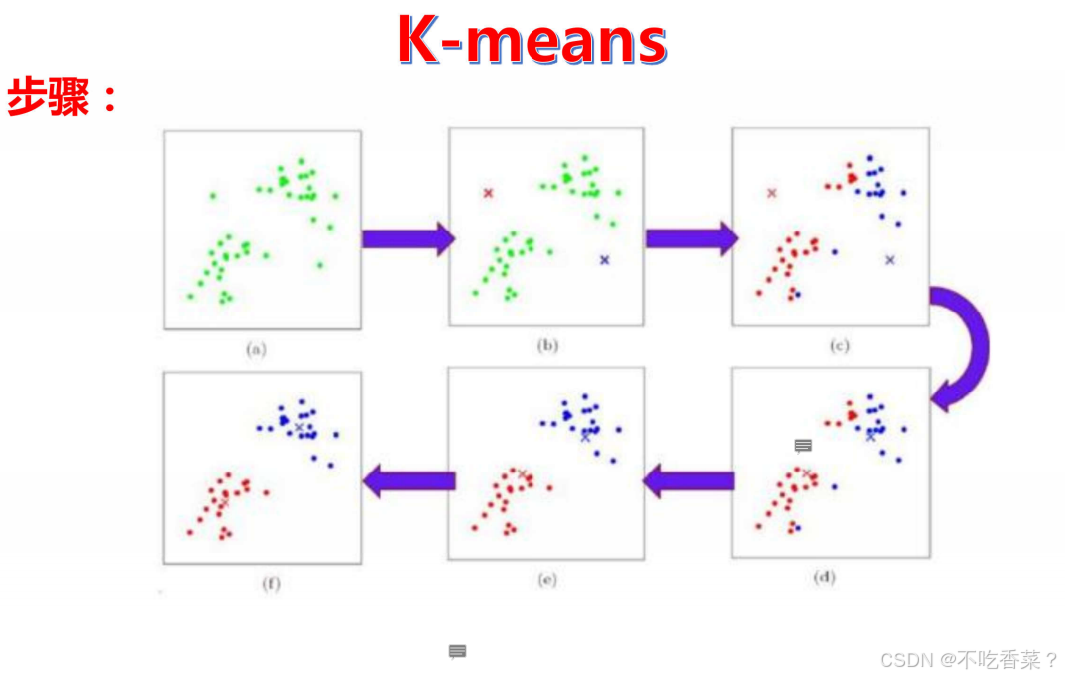
1,选择 K 值:首先,你需要决定将数据分成多少个簇,即 K 的值。K 的选择通常是基于问题的上下文或通过一些启发式方法(如肘部法则)来确定。
2,初始化质心:随机选择 K 个数据点作为初始的簇质心。质心可以是数据集中的任意点,但通常选择相距较远的点作为起始点,以避免局部最优解。
3,分配簇:对于数据集中的每个点,将其分配到最近的质心所在的簇。通常使用欧几里得距离来测量点与质心之间的距离。
4,更新质心:对于每个簇,重新计算其质心(即簇内所有点的均值)。
5,重复迭代:重复步骤 3 和 4,直到质心的位置不再显著变化或达到预设的迭代次数。
6,输出结果:最终,算法会输出 K 个簇和它们的质心。


三、代码实现
以下是文本data.txt的内容
name calories sodium alcohol cost
Budweiser 144 15 4.7 0.43
Schlitz 151 19 4.9 0.43
Lowenbrau 157 15 0.9 0.48
Kronenbourg 170 7 5.2 0.73
Heineken 152 11 5.0 0.77
Old_Milwaukee 145 23 4.6 0.28
Augsberger 175 24 5.5 0.40
Srohs_Bohemian_Style 149 27 4.7 0.42
Miller_Lite 99 10 4.3 0.43
Budweiser_Light 113 8 3.7 0.40
Coors 140 18 4.6 0.44
Coors_Light 102 15 4.1 0.46
Michelob_Light 135 11 4.2 0.50
Becks 150 19 4.7 0.76
Kirin 149 6 5.0 0.79
Pabst_Extra_Light 68 15 2.3 0.38
Hamms 139 19 4.4 0.43
Heilemans_Old_Style 144 24 4.9 0.43
Olympia_Goled_Light 72 6 2.9 0.46
Schlitz_Light 97 7 4.2 0.471、数据预处理
import pandas as pd
from sklearn.cluster import KMeans
from sklearn import metrics
#读取文件
beer = pd.read_table('data.txt',sep=' ', encoding='utf8', engine='python')
#传入变量(列名)
X = beer[['calories','sodium','alcohol','cost']]pandas:用于数据处理和分析;
KMeans:K-Means 聚类算法;
metrics:用于评估聚类效果的指标(如轮廓系数)。
使用pandas的read_table函数读取名为data.txt的文本文件,该文件中的数据通过空格分隔,并指定编码格式为utf-8。
选择 calories、sodium、alcohol、cost 四个特征作为聚类输入,X 是一个 DataFrame,包含用于聚类的特征数据。
2、交叉验证
scores = []
for k in range(2,10):
lables = KMeans(n_clusters=k).fit(X).labels_#从左到右依次计算
score = metrics.silhouette_score(X, lables)#轮廓系数
scores.append(score)
print(scores)
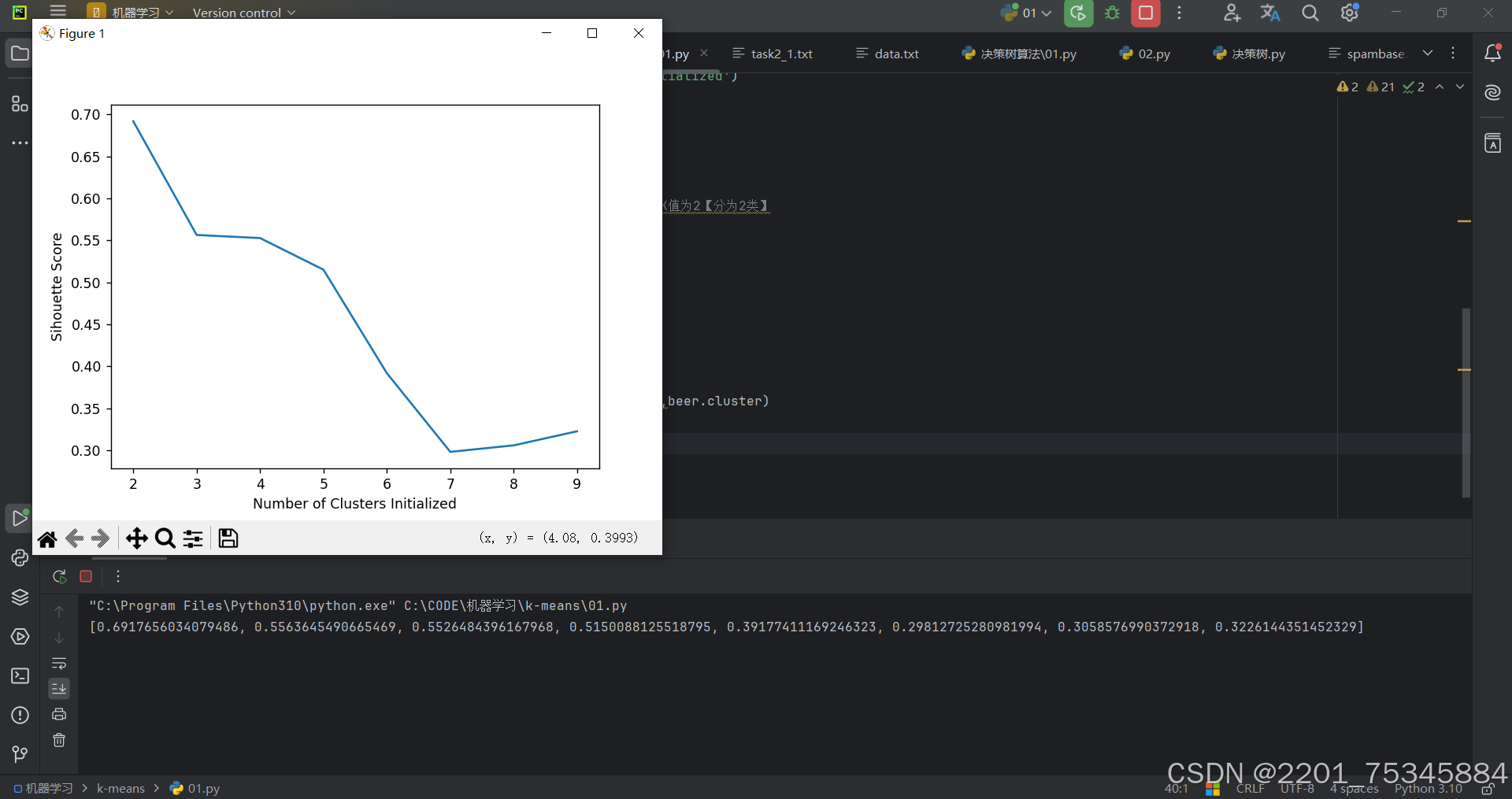
上述代码是用于计算不同簇数(k 从 2 到 9)对应的轮廓系数。
KMeans(n_clusters=k):初始化 K-Means 模型,设置簇数为 k。
fit(X):对数据进行聚类。
labels_:获取每个样本的聚类标签。
metrics.silhouette_score(X, labels):计算轮廓系数,评估聚类效果。
scores:存储每个 k 值对应的轮廓系数
3、可视化轮廓系数
import matplotlib.pyplot as plt
plt.plot(list(range(2,10)),scores)
plt.xlabel('Number of Clusters Initialized')
plt.ylabel('Sihouette Score')
plt.show()
绘制轮廓系数随簇数变化的曲线图。
plt.plot:绘制曲线图,横轴为簇数(k 从 2 到 9),纵轴为轮廓系数。
plt.xlabel 和 plt.ylabel:设置横轴和纵轴标签。
plt.show():显示图形
4、最终聚类
#聚类
km = KMeans(n_clusters=2).fit(X) #K值为2【分为2类】
beer['cluster'] = km.labels_
#对聚类结果评分
'''
采用轮廓系数评分
X:数据集 scaled_cluster:聚类结果
score:非标准化聚类结果的轮廓系数
'''
score = metrics.silhouette_score(X,beer.cluster)
print(score)使用 K-Means 算法将数据分为 2 类,并将聚类结果添加到数据集中。
KMeans(n_clusters=2):初始化 K-Means 模型,设置簇数为 2。
fit(X):对数据进行聚类。
km.labels_:获取每个样本的聚类标签。
beer['cluster']:将聚类标签添加到 beer DataFrame 中。
最后计算聚类结果的轮廓系数,评估聚类效果。
metrics.silhouette_score(X, beer.cluster):计算轮廓系数。
score:轮廓系数的值,范围在 [-1, 1] 之间,值越接近 1 表示聚类效果越好
5、最终运行结果
四、总结
K-means 聚类广泛应用于市场细分、图像分割、文档聚类等领域。例如,在市场营销中,可以将客户划分为不同的群体,以便进行更针对性的推广策略;在图像处理中,可以将图像分割成多个区域,以便进一步分析或压缩。但同时也拥有自己的优缺点。
优点:
简单易实现;
对大数据集具有较好的可扩展性;
当簇的密度大致相同且簇间分离良好时,效果非常好。
缺点:
需要预先指定 K 值,而 K 的选择通常不直观;
结果可能受到初始质心选择的影响,可能导致局部最优解;
对异常值(噪声)和簇的形状(非球形)敏感。