一、简介
逻辑回归是一种预测分类结果的线性模型。它使用逻辑函数(通常是Sigmoid函数)来将线性模型的输出转换为概率。逻辑回归的目标是最小化预测概率和实际标签之间的误差,这通常通过梯度下降等优化算法实现。
在许多实际应用中,数据集往往是不平衡的,即某些类别的样本数量远多于其他类别。这种不平衡可能导致模型偏向于多数类,从而影响少数类的预测性能。
下采样是一种处理不平衡数据集的方法,通过减少多数类的样本来平衡数据集。在下采样过程中,可以从多数类中随机选择样本进行删除,直到多数类和少数类的样本数量达到一个相对平衡的状态。
逻辑回归与下采样相结合,可以处理不平衡数据集上的二分类问题。
二、下采样的运用
1、导入相关包
导入相关的包,并绘制混淆矩阵,其中对应包的作用如下:
pandas:用于数据处理和分析。
matplotlib.pyplot:用于绘制图形,这里主要用于绘制散点图来直观展示数据之间的关系。
numpy:提供了高性能的多维数组对象以及这些数组的操作。
2、数据预处理
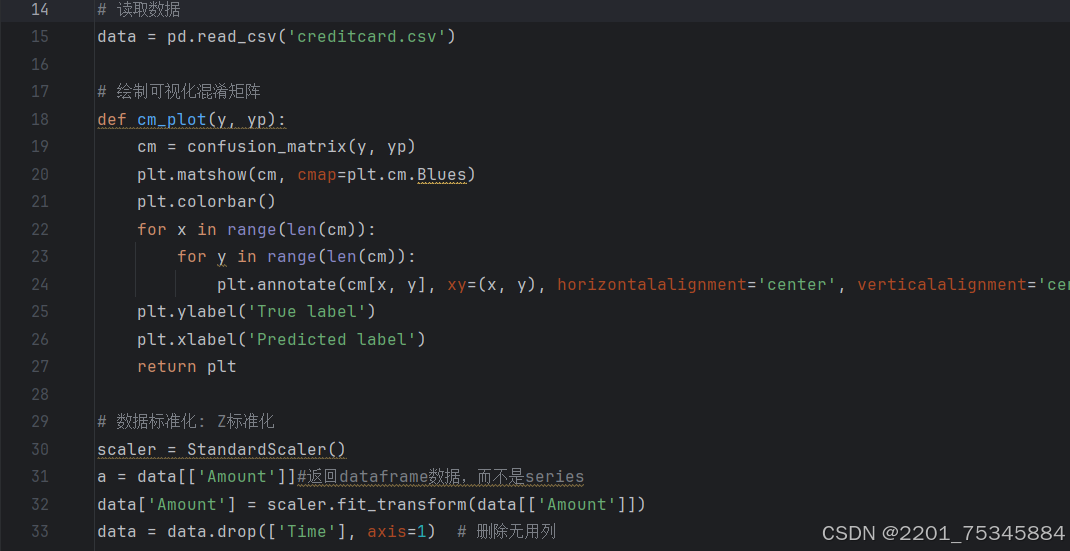
读取数据:使用pandas库读取creditcard.csv文件。
数据标准化:使用StandardScaler对Amount列进行标准化处理,使其符合正态分布。
删除无用列:删除Time列,因为它对欺诈检测不是很有用
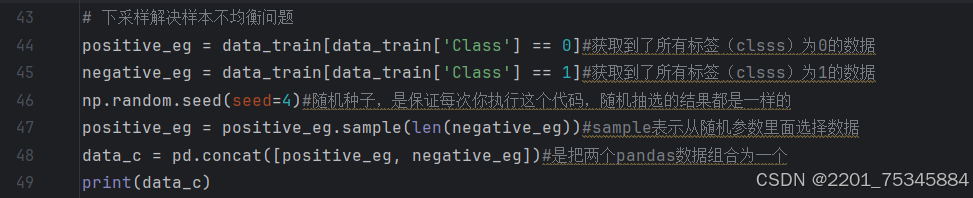
3、对数据进行下采样并合并
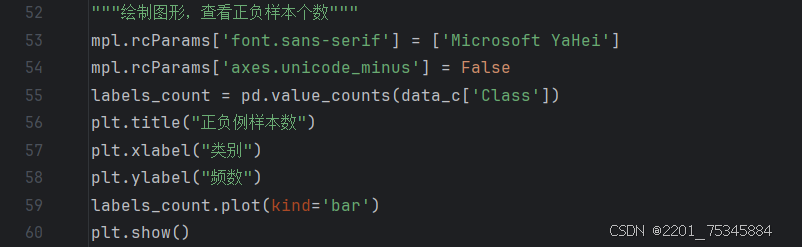
4、绘制下采样的图像
5、划分数据集

6、交叉验证选择最佳参数c
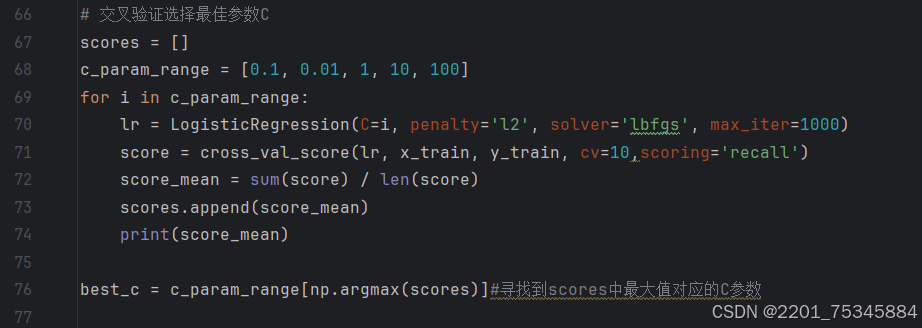
交叉验证:通过交叉验证(cross_val_score)来找到最佳的正则化参数C,这里使用召回率(recall)作为评分指标。使用最佳参数C建立最终模型,并在训练集和测试集上进行预测。
7、模型训练
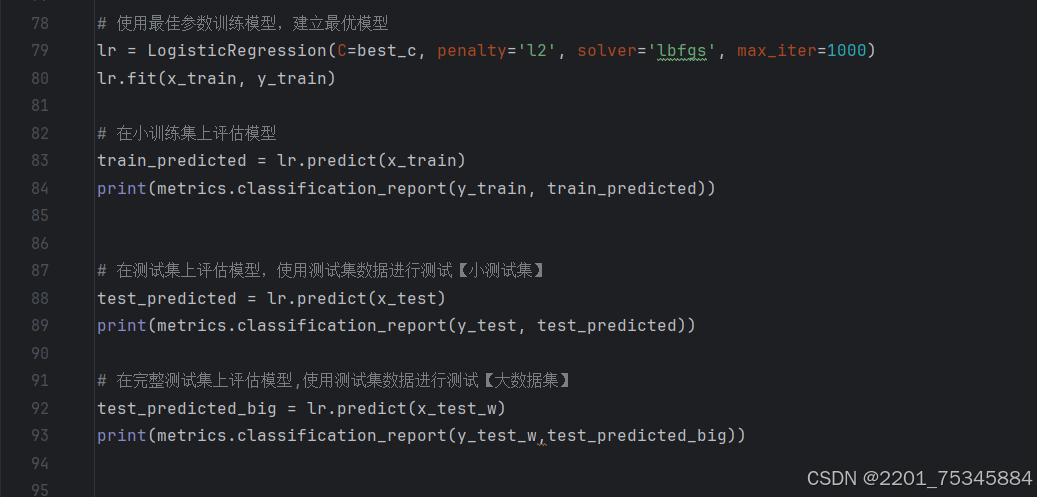
8、调整参数和性能评估
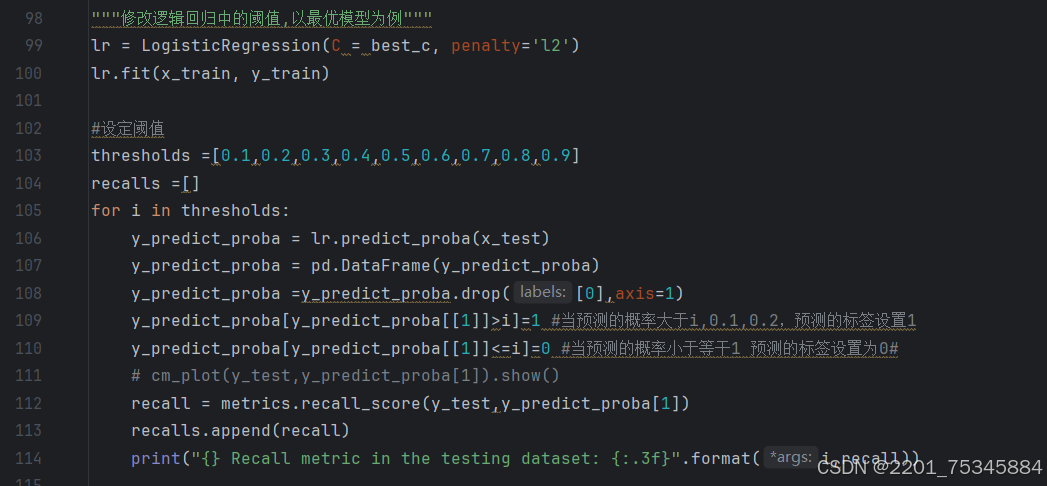
阈值调整:通过调整预测概率的阈值来探索不同阈值对召回率的影响。逻辑回归模型输出的是属于每个类别的概率,通过调整这个阈值,可以改变预测结果。
三、总结
下采样是一种处理类别不平衡问题的技术,它通过减少多数类样本的数量来平衡数据集。
优点:平衡数据:减少多数类样本,使类别更均衡。降低计算成本:数据量变小,训练更快。减少模型偏差:防止模型过度关注多数类。
缺点:丢失信息:删除样本可能导致重要信息丢失。
可能引入偏差:随机删除样本可能扭曲数据分布
对少数类敏感:如果少数类样本很少,下采样后数据可能太少,导致过拟合。