Unsupervised Fusion of Misaligned PAT and MRI Images via Mutually Reinforcing Cross-Modality Image Generation and Registration
摘要:光声断层扫描(PAT)和磁共振成像(MRI)是两种广泛应用于临床前研究的先进成像技术。 PAT具有高光学对比度和深成像范围,但软组织对比度较差,而MRI提供良好的软组织信息,但时间分辨率较差。 尽管最近在使用预对齐多模态数据的医学图像融合方面取得了进展,但由于图像未对齐和空间失真,PAT-MRI 图像融合仍然具有挑战性。 为了解决这些问题,我们提出了一种名为 PAMRFuse 的无监督多阶段深度学习框架,用于未对齐的 PAT 和 MRI 图像融合。 PAMRFuse 包括一个多模态到单模态配准网络,用于精确对齐输入 PAT-MRI 图像对,以及一个自注意力融合网络,用于选择信息丰富的特征进行融合。 我们在配准网络中采用端到端的相互增强模式,从而能够联合优化跨模态图像生成和配准。 据我们所知,这是针对未对准的 PAT 和 MRI 进行信息融合的首次尝试。 定性和定量实验结果表明,我们的方法在融合从商业成像系统捕获的小动物的 PAT-MRI 图像方面具有出色的性能。
问题背景:
PAT 的软组织对比度较差,这阻碍了器官或组织类型的识别。 相比之下,MRI 是一种成熟的高分辨率成像方式。由于临床前 MRI 和 PAT 具有相似的空间分辨率(约 100 um)并提供不同的组织对比度,因此它们彼此高度互补。现有的集成 PAT-MRI 双峰信息的方法仅限于图像配准,而不是图像融合。 有效的图像融合涉及将多个图像集成或合并为单个图像,而融合图像应表现出源图像的突出特征和详细信息,避免可能导致信息丢失或模糊的过度处理[19]。在我们的案例中,PAT 具有高光学对比度和深度成像能力,但缺乏软组织对比度,而 MRI 提供良好的软组织信息,但时间分辨率有限。 因此,除了执行 PAT/MRI 图像的图像对齐之外,PAT/MRI 融合的目的是通过组合来自这两种模态的图像来提供更全面的目标信息。
虽然目前的大多数图像融合网络都是健壮的,但它们不能直接应用于PAT-MRI图像融合,原因如下:首先,PAT-MRI图像融合是一项未经探索和无监督的任务,这使得构造有效的特征提取网络和准确的损失函数具有挑战性。其次,由于PAT-MRI图像来自不同的设备和环境,图像的不对准往往是不可避免的。

为了解决先前工作的上述局限性和未探索的问题,我们将PAT-MRI图像配准和融合统一到一个相互增强的框架中,并提出了一种称为PAMRFuse的无监督多模态融合网络,以实现PAT-MRI双模态信息的高质量和高效融合 。 如图1所示,PAMRFuse的结果不仅展示了PAT成像模式下组织吸收的亮度,还包含了MRI成像模式下的软组织信息。 相反,PAT和MRI图像的简单叠加,无论是否进行图像配准,融合效果最差。 正如红色箭头所指出的,PAT的亮度信息几乎完全被遮挡,MRI的软组织信息也变得模糊。 U2Fusion 和 Average 融合方法的结果未能充分描绘 PAT 和 MRI 图像的独特特征。 具体来说,U2Fusion 主要显示来自 PAT 的高强度亮度信息,而 Average 方法主要显示来自 MRI 的高对比度软组织信息。
本文的主要贡献总结如下:
1. PAMRFuse 是第一个用于 PAT 和 MRI 图像信息融合的医学图像融合网络。
2.为了减轻PAT和MRI图像的错位,我们提出了一种多模态到单模态配准网络,其中图像合成和配准是相辅相成的。
3.为了获得准确且平滑的变形场,我们引入了全局互相关损失和二阶变形场梯度损失的组合来训练配准网络。
4. 我们将自注意力机制纳入融合网络中,以捕获 PAT 和 MRI 图像之间的全局依赖性和内部相关性。
5.对小动物PAT-MRI图像进行广泛的定性和定量实验表明,我们的方法可以生成高质量的PAT-MRI融合图像。

PAT-MRI 图像合成网络
PAT 和 MRI 之间成像环境的差异导致图像未对准。 未配准未对齐图像的直接融合通常会导致重影伪影。 然而,为多模态对齐构建准确且稳健的损失函数具有挑战性,导致直接对齐无效。 为了解决这个问题,我们提出了一种 PAT-MRI 图像合成网络,表示为 GSyn,使用输入的 PAT 图像生成伪 MRI 图像。 GSyn 的结构为生成对抗网络(GAN)[28],如图 3 所示。 在无监督图像生成的背景下,GAN 是一种流行的方法,它利用最小-最大策略来估计学习过程中目标的分布。 然而,原始的GAN模型逐层生成图像,导致较低层无法学习较高层特征,从而限制了生成图像的多样性。 此外,增加层数会带来训练困难,并可能导致训练不稳定和梯度消失等问题。
为了解决这些问题,我们提出了一种生成模型,该模型结合了残差连接来增强生成图像的多样性和质量。 具体来说,通过融合高层通过跳跃连接学到的特征,该模型提高了训练稳定性并减轻了梯度消失。
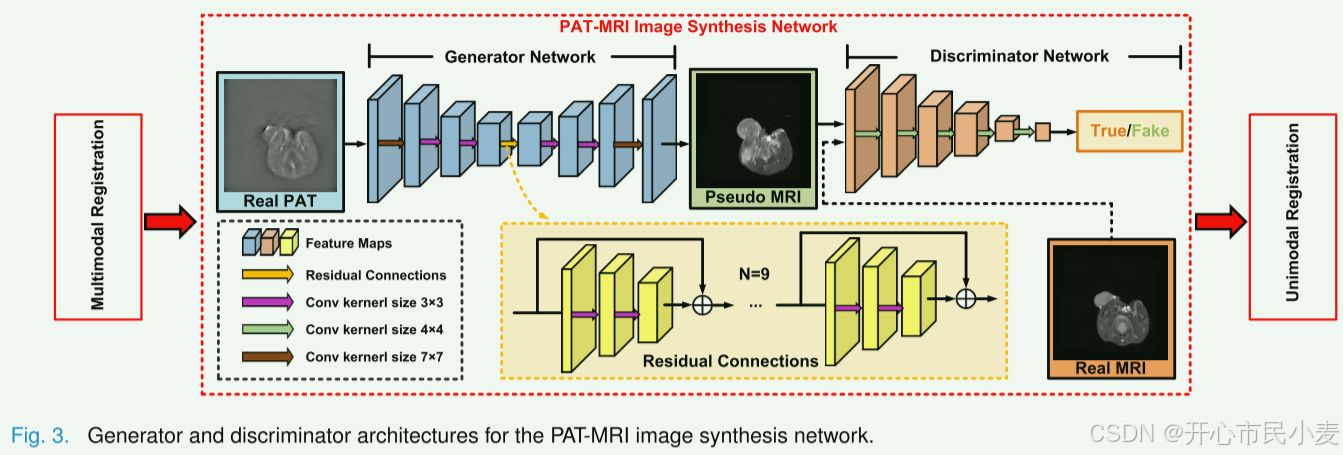
1)Generator Architecture:
在本研究中,编码器通过一系列填充、卷积、归一化和激活操作将输入张量维度从1扩展到256。 整流线性单元(ReLU)[29]用作除最后一个输出层(其中使用 tanh)之外的所有层的激活函数。 为了实现特征传播并防止梯度退化,每个残差层的输入都连接到归一化输出。 解码器通过应用多个卷积核来调整残差块输出维度,直到最终层输出,从而生成伪MRI图像。
2)判别器架构:
网络的输入是单通道灰度图像,通过五个卷积层提取其图像特征。 每层使用不同数量的 4 × 4 卷积核来产生不同维度的张量。 LeakyReLU用作所有层的激活函数以引入非线性。最后,利用全卷积层进行分类,输出图像为真实图像的概率。
配准网络
为了解决PAT和MRI成像中普遍存在的不对准和变形问题,我们提出了一种利用图像合成网络生成的伪MRI图像和运动的MRI图像生成图像变形场的配准网络。这种方法将具有挑战性的多模式图像配准问题简化为一个更易于管理的单峰配准问题。如图4所示,注册网络遵循与U-Net模型[30]类似的结构,具有编码器-解码器和跳过连接。为了提高网络性能,我们还将剩余块整合到体系结构中。
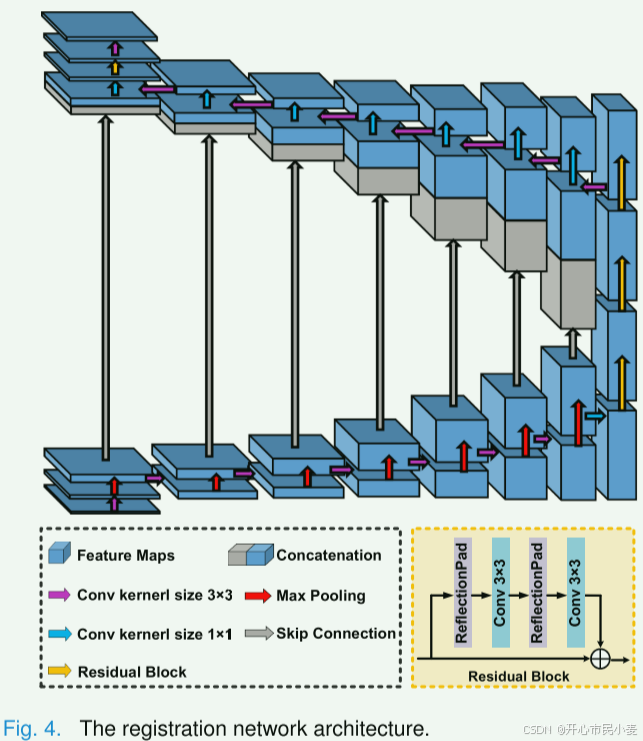
1)网络架构:
在本研究中,我们采用由伪MRI和移动MRI图像组成的双通道输入策略。 为了处理输入数据,我们在编码器和解码器中都采用了 2D 卷积,其内核大小如图 4 所示。 具体来说,在编码器中,我们实现卷积以将每层的空间维度减少两倍。 在解码阶段,我们利用激活、卷积和跳跃连接将编码阶段学到的特征传播到生成对齐变形场的层中。
自注意力融合网络
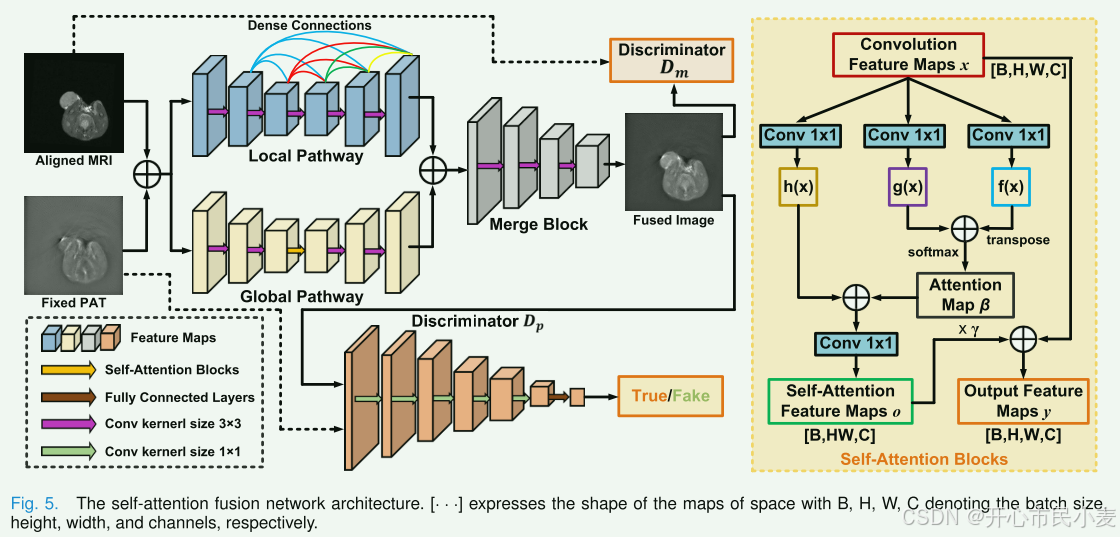
如图5所示,融合网络的生成器网络包括三个子组件:全局路径、局部路径和合并块。 全局路径利用自注意力机制从所有位置提取特征。 由于全局路径中的最大池层会减少特征图的比例并导致失真,因此我们添加局部路径来保留细节。 然后通过应用合并块将从全局路径和局部路径获得的特征合并以生成最终的融合图像。 采用两个对抗性鉴别器 Dm 和 Dp 分别将融合图像与对齐的 MRI 图像和 PAT 图像区分开。
1)全局路径:
在以前的生成模型中,不同图像区域之间的相关性主要使用卷积运算来建模。 然而,卷积层的感受野有限,这需要多个卷积层来处理长程依赖性。 此外,仅通过卷积层对图像中的远程依赖性进行建模在计算上可能效率低下。 自注意力在建模长期依赖性、计算成本和统计效率之间提供了良好的平衡[31]。 我们通过应用全局模型[32]将自注意力引入融合网络中的GAN框架。 具体来说,经过两个卷积层后,特征进入自注意力层,并使用最近邻插值对输入特征图进行上采样。 最后,再经过两个卷积层和上采样层,就得到了最终的特征图。
全局路径是作为所有位置的特征计算的位置响应的加权和,其中权重或注意力向量以较小的计算成本获得。
最后,我们将注意力层的输出与尺度参数相乘,并将输入特征图加回。 因此,最终输出由以下等式给出。
2)局部路径:
为了解决全局路径可能导致的细节丢失问题,我们引入了由五个卷积层组成的局部路径。在卷积之后的第一层中应用批归一化以便于训练并防止梯度爆炸[33]。RELU被用作激活函数。在随后的卷积层中,我们采用了卷积核的光谱归一化[34],这已被证明可以增强GaN的性能[35]。此外,我们在局部路径中采用密集连接来克服梯度消失,并利用先前计算的特征。
3)合并块:
通过将来自全局路径和局部路径的特征连接起来作为合并块的输入来组合它们。合并块由三个卷积层组成,频谱归一化仅应用于前两层。前两层使用RELU激活函数,而最后一层使用TANH激活函数来生成最终的融合图像。
4)鉴别器结构:鉴别器DM,DP具有相同的六层结构,其中前五层是卷积层,其统一步长设置为2,并且对这些卷积层进行谱归一化。然后,第五层的输出被馈送到完全连接的层,并由tanh函数激活以生成标量,该标量估计输入图像是否类似于地面真实图像或生成的融合图像的概率。
损失函数
1)图像合成和配准的损失函数:
在图像合成网络中,生成器G将源域PAT图像IP的分布转换为目标域MRI图像IM的分布。 鉴别器D用于确定目标域图像是来自生成器还是真实数据。 期望算子,用符号E表示,用于表示随机变量或函数的期望值。
我们引入随机变形,旨在将未对齐的目标图像视为带有噪声的标签。这种处理将图像到图像翻译的训练转变为监督学习过程。
我们使用配准网络R作为标签噪声模型来校正结果。 校正损失如(5)所示。

除了均方误差和L1参数损失之外,我们还使用全局互相关,因为它在鲁棒性方面表现更好。 与局部互相关[37]相反,全局互相关是针对整个图像计算的,并且不依赖于窗口。
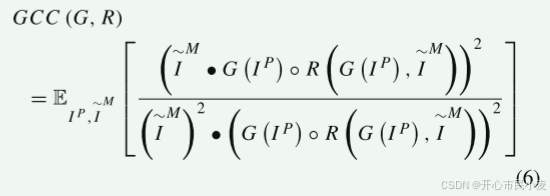
GCC 越高表示配准效果越好,因此损失函数由以下等式定义,其中 b 代表偏差。
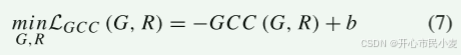
最后,我们在生成器和鉴别器之间添加对抗性损失 LAdv。 图像合成和配准的总损失如(9)所示。
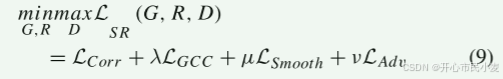
其中,不同损失之间的权衡由权重λ、μ、ν控制。 这种损失函数鼓励图像合成网络生成有利于配准的图像。 因此,图像合成网络和图像配准网络在网络训练过程中是相辅相成的。
2)图像融合的损失函数:
训练生成器 GF 的目标是学习从 PAT 图像 Ip 和对齐的 MRI 图像 IregM 到融合图像的映射,该映射集成了来自两种
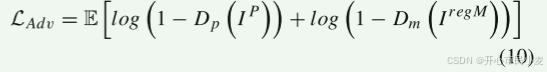
LAdv 迫使生成器 GF 生成近似理想融合图像的图像。 为了衡量和绑定IP和IregM在像素方向上与IF的内容相似度,我们使用均方误差损失作为内容损失
众所周知,均方误差可能会导致高频分量的缺失。 为了补偿均方误差的缺失并保留高频内容,我们使用基于梯度的损失 Lgrad 来补偿 LMSE