以下是针对高并发环境下超发现象的详细分析,包含场景示例、影响分析及解决方案:
高并发下的超发详解
1. 超发现象定义
超发(Over-issuance)指在并发操作中,系统实际发放的资源(如商品库存)超过实际可用量。例如,用户下单时系统显示库存充足,但实际扣减后库存为负数,导致超发。
2. 超发现象的典型场景
场景示例:商品抢购
假设某商品库存为 100,在高并发环境下,多个用户同时发起购买请求,可能导致以下流程:
3. 超发现象的时间线分析(表格)
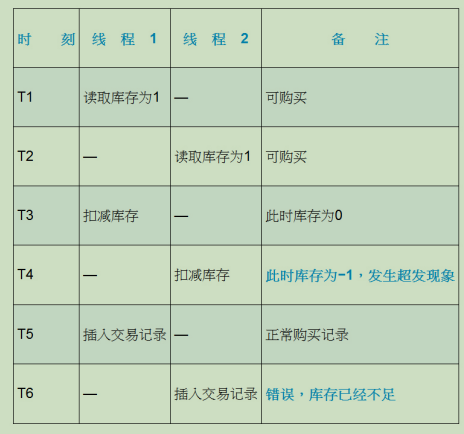
|
超发现象结果:
- 线程1和线程2在开始阶段都同时读入库存为1,但是在T3时刻线程1扣减库存后产品就没有库存了,线程2此时并不会感知线程1的这个操作,而是继续按自己原有的判断,按照库存为1扣减库存,这样就出现了T4时刻库存为−1,而T6时刻插入错误记录的超发现象在高并发的环境下,除了考虑超发的问题,还应该考虑性能问题,因为速度太慢会影响用户的体验。
4. 超发现象的影响
- 数据不一致:
- 库存显示与实际不符,导致用户收到订单但商品已售罄。
- 系统账目混乱,可能引发财务问题。
- 用户体验差:
- 用户支付后无法收到商品,引发投诉。
- 系统稳定性:
- 频繁的超发现象可能导致系统崩溃或数据损坏。
5. 超发的根源分析
超发现象的根本原因是 并发操作未保证原子性和一致性。具体原因如下:
- 读-修改-写操作的非原子性:
- 多个线程同时读取库存,各自计算后写回,导致覆盖。
- 缺乏锁机制:
- 未对共享资源(如库存)加锁,导致多个线程同时修改。
- 事务隔离级别不足:
- 默认的读已提交(Read Committed)隔离级别无法避免脏读或不可重复读。
6. 解决方案:悲观锁与乐观锁
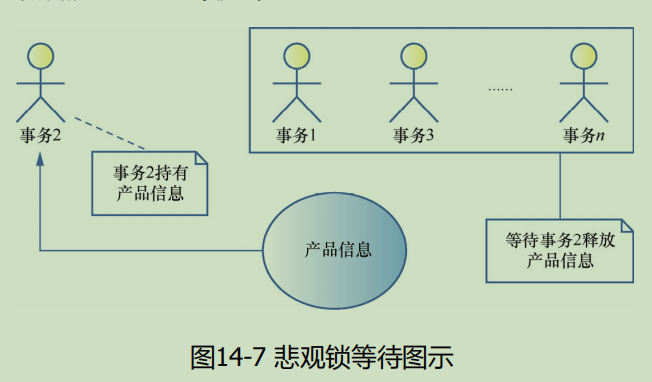
6.1 悲观锁(Pessimistic Lock)
悲观锁是使用数据库内部的锁对记录进行加锁,从而使其他事务等待,以保证数据的一致性。但这样会造成过多的等待和事务上下文的切换,导致系统运行缓慢,因为使用悲观锁时资源只能被一个事务锁持有,所以悲观锁也被称为独占锁或者排他锁
原理:
通过数据库锁(如 SELECT FOR UPDATE)独占资源,阻塞其他事务,确保操作原子性。
实现步骤:
-
加锁查询:
SELECT * FROM product WHERE id = 1 FOR UPDATE; -- 加锁查询库存 -
扣减库存:
UPDATE product SET stock = stock - 1 WHERE id = 1;
代码示例(Spring Boot + MyBatis):
@Service
public class ProductService {
@Autowired
private ProductMapper productMapper;
@Transactional(rollbackFor = Exception.class)
public boolean deductStockWithPessimisticLock(Long productId, Integer quantity) {
// 1. 加锁查询库存
Product product = productMapper.queryForUpdate(productId);
if (product == null || product.getStock() < quantity) {
throw new RuntimeException("库存不足");
}
// 2. 扣减库存(锁定期间数据一致)
productMapper.deductStock(productId, quantity);
return true;
}
}
// Mapper接口
public interface ProductMapper {
// 悲观锁查询(锁定行)
@Select("SELECT * FROM product WHERE id = #{id} FOR UPDATE")
Product queryForUpdate(@Param("id") Long id);
// 扣减库存
@Update("UPDATE product SET stock = stock - #{quantity} WHERE id = #{id}")
void deductStock(@Param("id") Long id, @Param("quantity") Integer quantity);
}
优点:
- 数据一致性强,避免超发。
- 实现简单,直接依赖数据库锁。
缺点:
- 阻塞导致吞吐量低,高并发下性能下降。
- 易引发死锁(如多个线程相互等待锁)。
6.2 乐观锁(Optimistic Lock)
乐观锁是一种不使用数据库锁的机制,不会造成线程的阻塞,而是采用多版本号机制来实现请求。但是,因为版本的冲突造成请求失败的概率剧增,所以这时往往需要通过重入机制降低请求失败的概率。不过,多次的重入会带来过多运行SQL语句的问题。为了克服这个问题,可以考虑使用按时间戳或者限定重入次数的办法。可,乐观锁是一个相对复杂的机制
—比较交换(compare and swap,CAS)
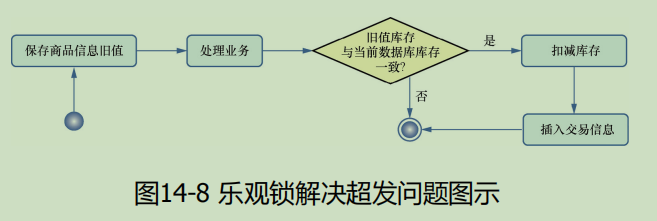
—比较交换(compare and swap,CAS)方案会引发一种ABA问题
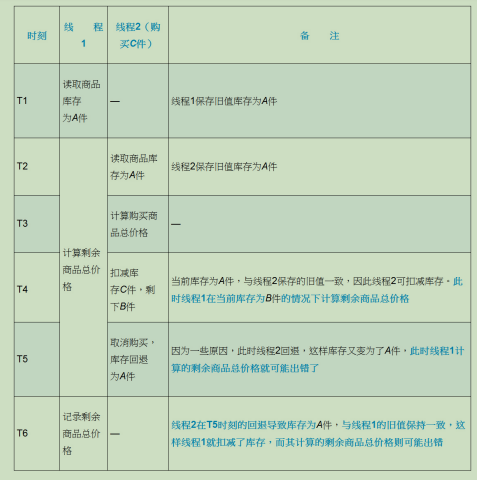
在T2到T5时刻,线程1计算剩余商品总价格的时候,当前库存会被线程2修改,它是一个
A→B→A的过程,所以被形象地称为“ABA问题”。换句话说,线程1在计算剩余商品总价格时,当前库存是一个变化的值,这样就可能出现错误的计算。显然,表14-2所示的共享值回退导致了数据的不一致,为了克服这个问题,开发者引入了一些规则,典型的如增加版本号(version),并且规定:只要操作过程中修改共享值,无论业务是正常、回退还是异常,版本号只能递增,不能递减。使用这个规则重新执行数据库事务
使用版本号解决ABA问题
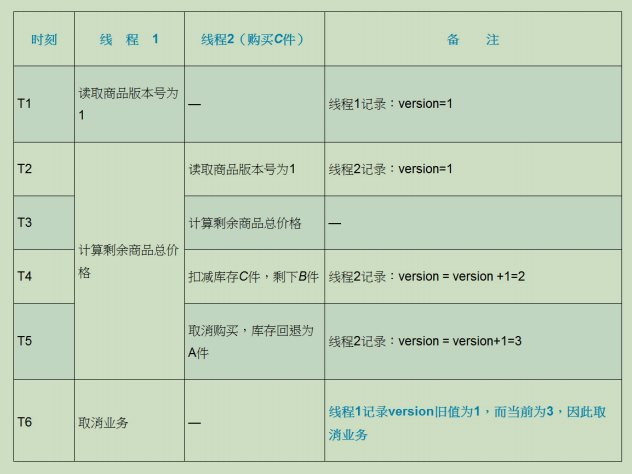
可以看出,由于版本号只能递增而不能递减,因此无论是线程2进行扣减库存还是回退商品,版本号都只会递增而不会递减,这样在T6时刻,线程1使用其保存的version旧值1与当前version值3进行比较,就会发现商品被修改过了,数据已经不可信,于是便取消业务。
加入版本号导致失败数量多,请求量大,对数据库造成压力,一般会考虑使用限制时间或者重入次数的办法,压制过多的SQL语句被运行。
因为加入了版本号的判断,所以大量的请求得到了失败的结果,而且这个失败率有点高。下面我们要处理这个问题。在上面的测试中,可以看到大量的请求更新失败。为了处理这个问题,乐观锁还可以引入重入机制,也就是一旦更新失败,就重新做一次,因此有时候也可以称乐观锁为可重入的锁。其原理是一旦发现版本号被更新,不结束请求,而是重新运行一次乐观锁流程,直至成功为止。但是流程的重入可能造成大量的SQL语句被运行。例如,原本一个请求需要运行3条SQL语句,如果需要重入4次才能成功,那么就会有十几条SQL语句被运行,在高并发场景下,会给数据库带来很大的压力。为了克服这个问题,一般会考虑使用限制时间或者重入次数的办法,压制过多的SQL语句被运行。
按时间戳重入的乐观锁测试
进入方法后则记录了开始时间,然后进入循环。在执行业务逻辑之前,先判断结束时间
(end)和开始时间(start)的时间戳。如果循环时间小于等于100 ms,则继续尝试;如果大于100 ms,则返回失败。在扣减库存的时候,如果扣减成功,则返回更新条数不为0;如果为0,则扣减失败,进入下一次循环,直至扣减成功或者超时
按时间戳限制重入的方法也有一个弊端,就是系统会因为自身的忙碌而大大减少重入的次数。因此有时候也会采用限定重入次数的机制来避免重试过多
但是按时间戳限制重入的方法也有一个弊端,就是系统会因为自身的忙碌而大大减少重入的次数。因此有时候也会采用限定重入次数的机制来避免重试过多的情况,不同的地方在于使用for循环限定了最多3次尝试。在实际的测试中可以发现,请求失败的次数也会大大降低
原理:
通过版本号(Version)或时间戳检测冲突,在提交时验证数据未被修改。若冲突则回滚并重试。
实现步骤:
-
读取数据:
SELECT * FROM product WHERE id = 1; -- 读取库存和版本号 -
验证版本号:
UPDATE product SET stock = stock - 1, version = version + 1 WHERE id = 1 AND version = #{currentVersion}; -- 带版本号校验的更新
代码示例(Spring Boot + MyBatis):
@Service
public class ProductService {
@Autowired
private ProductMapper productMapper;
@Transactional(rollbackFor = Exception.class)
public boolean deductStockWithOptimisticLock(
Long productId,
Integer quantity,
int retryCount) {
int retry = 0;
while (retry < retryCount) {
// 1. 获取当前库存和版本号
Product product = productMapper.queryProduct(productId);
if (product == null || product.getStock() < quantity) {
throw new RuntimeException("库存不足");
}
// 2. 尝试扣减库存(带版本号校验)
int affectedRows = productMapper.deductStockWithOptimisticLock(
productId, quantity, product.getVersion());
if (affectedRows > 0) {
return true;
}
// 3. 版本冲突,重试
retry++;
try {
Thread.sleep(10); // 避免频繁重试
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
throw new RuntimeException("库存扣减失败,版本冲突");
}
}
// Mapper接口
public interface ProductMapper {
// 查询库存(不加锁)
@Select("SELECT * FROM product WHERE id = #{id}")
Product queryProduct(@Param("id") Long id);
// 乐观锁扣减库存(带版本号校验)
@Update("UPDATE product SET stock = stock - #{quantity}, version = version + 1 " +
"WHERE id = #{id} AND version = #{version}")
int deductStockWithOptimisticLock(
@Param("id") Long id,
@Param("quantity") Integer quantity,
@Param("version") Integer version);
}
优点:
- 避免阻塞,高并发下吞吐量更高。
- 减少锁竞争,降低系统开销。
缺点:
- 需处理版本冲突,重试可能增加开销。
- 多次重试可能导致过多SQL语句执行。
7. 其他解决方案
7.1 分布式锁(如Redis)
通过Redis的SETNX命令实现分布式锁,确保跨节点资源操作的原子性。
7.2 预扣减策略
- 预扣减缓存:将库存预扣减到缓存(如Redis),再异步更新数据库。
- 优点:减少数据库压力,提升性能。
- 缺点:需处理缓存与数据库的最终一致性。
7.3 限流降级
- 通过熔断器(如Hystrix)、限流算法(如令牌桶)限制并发请求,避免系统过载。
8. 总结
| 场景 | 推荐方案 | 原因 |
|---|---|---|
| 高并发低冲突 | 乐观锁 | 减少锁竞争,提升吞吐量,版本冲突概率低时无需频繁重试。 |
| 高冲突且数据敏感 | 悲观锁 | 保证数据绝对一致性,适用于金融等对数据强一致要求高的场景。 |
| 混合场景 | 乐观锁+重试机制 | 结合版本号和有限次数的重试,在保证性能的同时降低冲突影响。 |
9. 关键代码注释说明
悲观锁代码关键点
SELECT FOR UPDATE:锁定记录,阻塞其他事务。- 事务注解
@Transactional:确保查询和更新操作的原子性。
乐观锁代码关键点
- 版本号字段
version:记录数据修改次数。 - 重试机制:通过有限次数的重试降低版本冲突的影响。
通过以上方案,可以有效解决高并发下的超发现象,确保系统数据一致性与性能平衡。