目录
导读:在分布式架构中,当我们将数据分库分表后,传统的自增主键机制面临着唯一性挑战。本文深入剖析了分布式系统中全局唯一ID生成的四种主流方案:UUID、单表自增、多表步长和雪花算法,从性能、存储空间、有序性和可用性等维度进行全面对比。你是否好奇为何Twitter选择了雪花算法?或者如何解决雪花算法中的时钟回拨问题?文章不仅提供了各方案的实现原理和代码示例,还分享了微博、美团等大厂的实践经验,帮助你在实际项目中做出最合适的技术选择。无论是小型应用还是高并发大型分布式系统,这里都有你需要的ID生成最佳实践。
一、引言
在互联网高速发展的今天,随着用户量和数据量的爆发式增长,传统单库单表架构已无法满足大型系统的性能需求,分库分表成为了应对海量数据的必然选择。然而,当我们将一张表水平拆分到多个数据库实例后,原本依赖数据库自增主键的唯一性保障机制就面临了严峻挑战。
问题背景:在单体架构中,我们习惯使用数据库的自增主键(AUTO_INCREMENT)作为记录的唯一标识。但在分库分表环境下,多个数据库实例各自独立生成的自增ID不可避免地会出现冲突。例如,订单表被拆分到5个数据库实例后,每个实例都可能生成ID为"1"的订单记录,这显然违背了业务唯一性的要求。
核心挑战:如何在分布式系统中设计一种全局唯一ID生成方案,既能保证ID的唯一性和单调递增特性,又能满足高性能、高可用性的要求,同时尽可能兼顾ID的可读性和业务含义,成为了分布式系统设计的关键技术挑战之一。
二、全局唯一ID生成方案
A. UUID方案
实现原理
UUID(Universally Unique Identifier,通用唯一标识符)是一种由算法生成的128位标识符,按照开放软件基金会(OSF)制定的标准生成,用于在分布式系统中唯一标识信息而不需要中央协调。
UUID的标准格式为:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx(8-4-4-4-12,共36个字符,包含32个十六进制数字和4个连字符)。例如:550e8400-e29b-41d4-a716-446655440000。
在Java中,生成UUID非常简单:
String uuid = UUID.randomUUID().toString();优缺点分析
优点:
- 全局唯一性:基于MAC地址、时间戳、随机数等多重因素生成,理论上重复概率极低(世界上50亿人,每人每秒生成10亿个UUID,持续100年,重复概率仅有50%)
- 生成简单:无需中央控制节点,任何服务器、客户端都可以独立生成
- 高性能:本地生成,无网络消耗,TPS可达数百万
- 高可用:无单点故障风险
缺点:
- 存储空间:长度为36字节,比整型ID(一般4-8字节)占用更多存储空间
- 查询效率低:不是整型,作为数据库主键时索引效率较低
- 无序性:不保证时间和数值有序,不适用于需要排序的场景
- 无业务含义:纯随机字符串,人类无法从ID值本身获取有用信息
- 用户体验差:不便于用户记忆和输入
详细UUID原理请看我另一篇文章:UUID详解:全局唯一标识符的工作原理、版本对比与实践指南_uuid32 版本 变体-CSDN博客
B. 基于单表的自增主键方案
实现原理
该方案通过设置一个专门的ID生成表,利用数据库自增特性来生成全局唯一ID。这是一种集中式ID生成方案,所有服务在需要ID时都会请求这个中心化的ID生成服务。
ID生成表结构通常非常简单:
CREATE TABLE `id_generator` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`business_type` varchar(128) NOT NULL COMMENT '业务类型',
`description` varchar(256) DEFAULT NULL COMMENT '说明',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_business_type` (`business_type`)
) ENGINE=InnoDB;工作流程
- 应用服务启动时,向ID生成服务请求一批ID
- ID生成服务执行类似这样的SQL:
INSERT INTO id_generator(business_type) VALUES('order') ON DUPLICATE KEY UPDATE id=LAST_INSERT_ID(id+1); SELECT LAST_INSERT_ID(); - 应用服务获取到ID后,用于后续的数据写入操作
为了优化性能,通常会采用批量获取策略,即每次获取一批ID并在本地缓存,待用完后再次请求。
局限性
- 系统性能瓶颈:随着系统规模扩大,所有服务都依赖这个单点获取ID,容易成为整个系统的性能瓶颈
- 单点故障风险:一旦ID生成服务不可用,整个系统将无法写入新数据
- 扩展性差:难以水平扩展来提升ID生成能力
C. 基于多表+步长的自增主键方案
实现原理
为了解决单表方案的单点问题,我们可以部署多个ID生成实例,每个实例负责生成不同区间的ID,通过设置不同的起始值和步长来避免ID冲突。这种方式实质上是一种取模分片的思想,每个ID生成器负责生成特定模数的ID。
步长机制
假设我们有N个ID生成实例,则:
- 实例1生成的ID模N余1
- 实例2生成的ID模N余2
- 实例n生成的ID模N余n
这可以通过MySQL的自增属性参数实现:
- auto_increment_increment:自增步长
- auto_increment_offset:自增起始值
配置示例(假设部署4个实例):
# 实例1配置
set @@auto_increment_increment=4;
set @@auto_increment_offset=1;
# 实例2配置
set @@auto_increment_increment=4;
set @@auto_increment_offset=2;
# 实例3配置
set @@auto_increment_increment=4;
set @@auto_increment_offset=3;
# 实例4配置
set @@auto_increment_increment=4;
set @@auto_increment_offset=4;实现示例
初始分配:
- 实例1生成的ID:1, 5, 9, 13, 17, ...
- 实例2生成的ID:2, 6, 10, 14, 18, ...
- 实例3生成的ID:3, 7, 11, 15, 19, ...
- 实例4生成的ID:4, 8, 12, 16, 20, ...
这种方式也可以理解为区间分配:
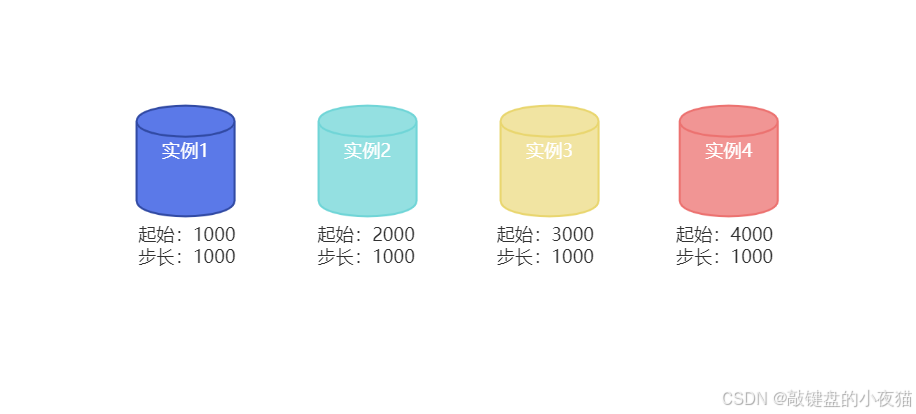
- 实例1生成的ID从1000开始,到1999结束
- 实例2生成的ID从2000开始,到2999结束
- 实例3生成的ID从3000开始,到3999结束
- 实例4生成的ID从4000开始,到4999结束
动态调整: 当某个实例的ID区间耗尽时,可以分配新的区间:
- 实例1生成的ID从5000开始,到5999结束
- 实例2生成的ID从6000开始,到6999结束
- 实例3生成的ID从7000开始,到7999结束
- 实例4生成的ID从8000开始,到8999结束
优势
- 解决单点故障:多个ID生成实例可以同时工作,某个实例故障不会影响整体系统
- 提高系统吞吐量:负载分散到多个实例,整体性能提升
- 保持ID连续性:生成的ID基本保持连续性,便于业务使用
- 水平扩展:可以通过增加ID生成实例来提升系统容量
D. 雪花算法(Snowflake)
算法特点
雪花算法是Twitter开源的分布式ID生成算法,其设计初衷正是为了解决分布式系统中全局唯一ID的需求。雪花算法具有全局唯一、单调递增、高性能等特点,是目前分布式系统中最流行的ID生成方案之一。
结构组成
雪花算法生成的ID是一个64位的长整型数字,由以下部分组成:
- 1bit符号位:恒为0,保证ID为正数
- 41bit时间戳位:精确到毫秒,可容纳约69年的时间(从算法设计的基准时间开始计算)
- 10bit工作进程位:
- 5bit数据中心ID:最多支持32个数据中心
- 5bit工作节点ID:每个数据中心最多支持32个节点
- 组合起来最多支持1024个节点
- 12bit序列号位:每个节点每毫秒从0开始自增,最多可生成4096个ID
性能容量
雪花算法的理论性能极高:
- 单个节点每毫秒可生成4096个ID
- 1024个节点同时工作时,每毫秒可生成约419万个ID
- 每秒可生成约42亿个ID
实际应用中,受到网络传输和服务器性能的限制,单节点实际吞吐量通常在每秒数万到数十万个ID。
详细雪花算法学习,请看我另一篇文章:分布式系统必修课:5分钟掌握雪花算法核心原理与自实现陷阱-CSDN博客
三、方案对比与选择建议
| 方案 | 性能 | 存储空间 | 有序性 | 可读性 | 实现复杂度 | 高可用性 | 适用场景 |
|---|---|---|---|---|---|---|---|
| UUID | 高 | 36字节 | 无 | 差 | 低 | 高 | 简单系统,对ID格式无特殊要求 |
| 单表自增 | 低 | 8字节 | 高 | 好 | 低 | 低 | 小型系统,对有序性要求高 |
| 多表步长 | 中 | 8字节 | 中 | 好 | 中 | 中 | 中型系统,对ID连续性有要求 |
| 雪花算法 | 高 | 8字节 | 高 | 中 | 中 | 高 | 大型分布式系统 |
选择建议:
- 小型应用:用户量小、性能要求不高的系统可以选择UUID或单表自增方案,实现简单快捷
- 中型应用:并发量中等、有一定扩展需求的系统可以采用多表步长方案
- 大型分布式系统:高并发、高可用要求的大型系统建议使用雪花算法,它在性能、可用性和ID特性上取得了很好的平衡
实际案例参考:
- 微博使用了类雪花算法的实现方案
- 美团点评采用了改进的雪花算法
- 百度的UidGenerator在雪花算法基础上增加了更多工作机器位
- 滴滴的TinyID采用了号段模式与雪花算法相结合的方案
四、实践中的常见问题与解决方案
1. 时钟回拨问题
问题:分布式环境中,服务器时钟可能因NTP同步等原因出现回拨,导致雪花算法可能生成重复ID。
解决方案:
- 记录上一次生成ID的时间戳,发现回拨时拒绝服务或等待
- 使用更可靠的时间源,如原子钟
- 增加时钟回拨位,回拨时自动递增
2. 节点编号分配问题
问题:大型分布式系统中,如何动态管理工作节点编号?
解决方案:
- 使用ZooKeeper等配置中心动态分配节点ID
- 结合服务注册发现机制自动管理节点编号
- 使用机器IP、MAC地址等信息计算节点ID
3. ID安全性问题
问题:雪花算法生成的ID包含时间信息,可能泄露业务数据量。
解决方案:
- 对外部可见的ID进行加密或混淆
- 使用不同的ID用于内部系统和外部展示
- 在ID基础上增加随机性
五、总结与展望
分布式系统中的全局唯一ID生成是一个看似简单但实际充满挑战的技术难题。从最初的UUID到结构化的雪花算法,ID生成方案不断演进,每种方案都有其适用场景和局限性。
选择合适的ID生成方案需要综合考虑系统规模、性能需求、可用性要求和业务特性。在实际应用中,我们常常需要对标准方案进行定制化改造,以满足特定业务场景的需求。
随着分布式系统的进一步发展,全局唯一ID生成技术也在不断创新。未来的发展趋势可能包括:
- 更智能的自适应算法:根据系统负载自动调整ID生成策略
- 与区块链技术结合:利用分布式账本技术保证ID的不可篡改性
- 跨组织的ID协议标准:建立行业统一的ID生成和交换标准
你对分布式系统中的全局唯一ID生成有什么实践经验或疑问?欢迎在评论区分享和讨论!
扩展阅读: