目录
1. ShardingSphere (原Sharding-JDBC)
导读:当数据库面临高并发与大数据量的双重挑战时,分库分表成为打破性能瓶颈的关键技术。本文系统梳理了分库分表的核心价值与实施策略:分库主要解决并发连接数不足问题,分表则应对单表数据量过大导致的性能下降。你是否知道MySQL默认最大连接数仅为151?又是否了解单表数据量达到多少时应考虑分表?文章不仅提供了判断分库分表时机的量化标准,还详细对比了ShardingSphere、TDDL、Mycat等主流工具的特性与适用场景,并通过具体代码示例展示了横向与纵向拆分的实现方式。无论你是刚接触分布式数据库的开发者,还是正面临数据库扩展难题的架构师,这篇技术指南都能助你在复杂数据架构中做出正确决策。
一、核心概念与基础认知
1. 分库分表的本质
当我们谈论"分库分表"时,实际上是在讨论三种不同的技术策略:只分库不分表、只分表不分库、既分库又分表。每种策略针对的痛点各不相同。
只分库不分表:将原本存储在单个数据库实例中的表分散到多个数据库实例中,表结构保持不变。
只分表不分库:在同一数据库实例内,将一张表按照某种规则拆分成多张表,数据库实例数量不变。
既分库又分表:同时实施上述两种策略,既增加数据库实例数,又拆分单表结构。
这些策略并非简单的技术选择,而是应对不同系统瓶颈的针对性解决方案。理解它们的区别,是正确实施分库分表的第一步。
2. 分库的核心价值
分库主要解决的是并发连接数不足的问题。
在高并发场景下,数据库连接资源往往成为首要瓶颈。MySQL默认最大连接数为151,虽然可以调整到数千,但硬件资源和性能会限制其上限。当系统QPS(每秒查询量)持续攀升,单个数据库实例无法承载所有连接请求时,分库策略通过增加数据库实例数量,线性提升系统整体的并发处理能力。
// 假设单个MySQL实例最大有效连接数为500
// 4个数据库实例可提供约2000个并发连接
单实例最大连接数 * 实例数量 = 系统总连接容量 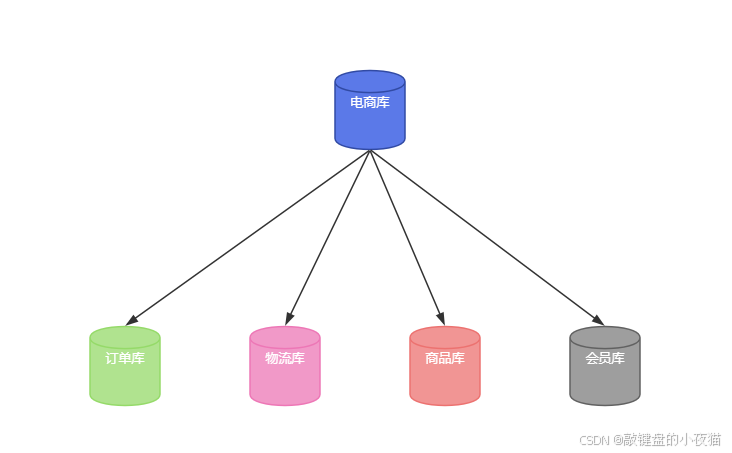
3. 分表的核心价值
分表主要解决的是单表数据量过大导致的存储与查询性能下降问题。
当表中的数据量达到一定规模,即使创建了合适的索引,查询性能仍会显著下降。这是因为:
- B+树索引深度增加,需要更多的I/O操作
- 数据页分裂频繁,索引碎片增多
- 缓存命中率下降,物理读增加
分表通过将数据分散到多个表中,控制单表数据规模,从而维持较高的查询性能和较低的存储压力。

4. 分库分表的综合应用
在实际生产环境中,高并发与大数据量问题往往同时存在。例如,电商平台的订单系统,既面临着下单高峰期的并发压力,又要处理海量的历史订单数据。
这种情况下,既分库又分表的综合应用成为必然选择:分库解决并发瓶颈,分表解决数据量瓶颈,两者结合形成完整的水平扩展方案。
二、分库分表的时机判断
1. 分库的适用场景
判断是否需要分库,主要考虑以下几个场景:
数据库连接资源不足:监控显示数据库连接数经常接近上限,且已优化连接池配置但效果不明显。
// MySQL连接情况监控SQL
SHOW STATUS LIKE 'Threads_connected'; // 当前连接数
SHOW VARIABLES LIKE 'max_connections'; // 最大连接数微服务架构拆分:按照业务边界进行微服务拆分时,将不同业务模块的数据分别存储到独立的数据库中,实现数据隔离和服务自治。例如,将电商系统中的订单、商品、用户、支付等数据分别存储到专用数据库。
冷热数据分离:将不常访问的历史数据迁移到独立的历史库,减轻主库负担。例如,将两年前的订单数据迁移到历史订单库。
2. 分表的量化标准
关于分表的时机,业界有一些参考标准:
阿里巴巴Java开发手册标准:单表行数超过500万行或单表容量超过2GB时,建议考虑分表。
实践经验标准:根据现代硬件条件和优化实践,单表抗2000万数据量通常问题不大,但需要根据具体情况评估。
影响单表承载能力的因素包括:
- 记录大小(字段数量和类型)
- 存储引擎及配置(InnoDB、MyISAM等)
- 索引设计(数量、复合索引等)
- 硬件配置(特别是I/O性能)
- 查询复杂度和访问模式
实际判断标准应结合以上因素和系统实际性能表现,而非简单依据数据量阈值。
3. 优先级原则
分库分表不应作为性能优化的首选方案,而应遵循以下优先级原则:
- 首先尝试常规优化手段:
- SQL语句优化(避免全表扫描、减少JOIN等)
- 索引优化(添加合适索引、避免索引失效)
- 数据库参数调优(缓冲池大小、日志配置等)
- 读写分离(分担读压力)
- 缓存应用(Redis减轻数据库负担)
- 当常规优化无法满足需求,且数据量或并发量接近瓶颈时,再考虑分库分表。
分库分表会增加系统复杂度,带来分布式事务、跨库查询等挑战,应审慎决策。
三、拆分策略与实现方式
1. 横向拆分(水平拆分)
定义:将同一表的不同数据行按照某种规则分散到多个表中,这些表结构完全相同。
原理图示:

拆分规则示例:
- 按订单ID取模:
order_id % 表数量 - 按时间区间:如按月拆分
- 按地理位置:如按区域拆分
适用场景:数据量大但表结构相对稳定的场景,如订单表、日志表等。
实现案例:电商平台订单表,可按用户ID进行水平拆分:
-- 创建8个分表
CREATE TABLE order_0 LIKE order;
CREATE TABLE order_1 LIKE order;
...
CREATE TABLE order_7 LIKE order;
-- 根据用户ID路由到对应分表
-- 用户ID为10001的订单将被插入到order_1表(10001 % 8 = 1)
INSERT INTO order_1 (id, user_id, ...) VALUES (...)2. 纵向拆分(垂直拆分)
定义:将同一表的不同字段拆分到多个表中,通常以某个字段作为关联键。
原理图示:
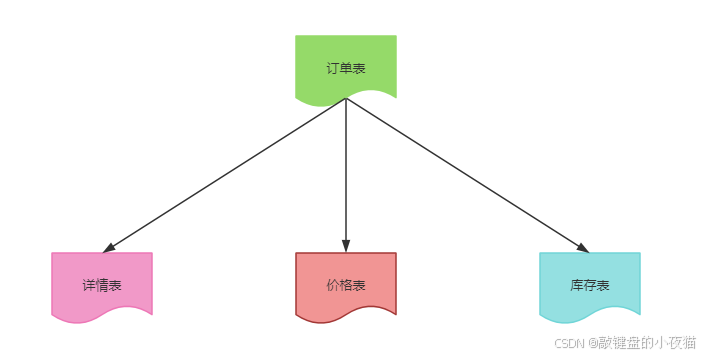
拆分规则示例:
- 按访问频率:高频访问字段放入一表
- 按字段功能:不同业务属性分离
- 按字段类型:如大文本字段独立存储
适用场景:表字段较多,且不同字段访问频率差异大的场景。
实现案例:商品信息表的纵向拆分:
-- 原始商品表
CREATE TABLE product (
id BIGINT PRIMARY KEY,
name VARCHAR(100),
price DECIMAL(10,2),
stock INT,
description TEXT,
specifications TEXT,
images TEXT
);
-- 纵向拆分后
-- 基本信息表(高频访问)
CREATE TABLE product_base (
id BIGINT PRIMARY KEY,
name VARCHAR(100),
price DECIMAL(10,2),
stock INT
);
-- 详情表(低频访问)
CREATE TABLE product_detail (
product_id BIGINT PRIMARY KEY,
description TEXT,
specifications TEXT,
FOREIGN KEY (product_id) REFERENCES product_base(id)
);
-- 图片表(特殊类型)
CREATE TABLE product_images (
product_id BIGINT,
image_url VARCHAR(255),
PRIMARY KEY (product_id, image_url),
FOREIGN KEY (product_id) REFERENCES product_base(id)
);业务纵向拆分:按业务边界将不同业务的表分布到不同的数据库实例中,也属于纵向拆分范畴。例如,将订单库、用户库、商品库分离。
3. 关键技术点
分表字段选择原则:
- 数据分布均匀,避免数据倾斜
- 查询条件中高频出现的字段
- 尽量避免跨表/跨库关联查询
- 业务意义明确且相对稳定
常见的分表字段:用户ID、订单ID、创建时间等。
分表算法设计:
- 哈希取模法:
字段值 % 分表数量- 优点:数据分布均匀
- 缺点:扩容困难,需要数据迁移
- 范围分片法:按照字段值范围划分
- 优点:扩容简单,只添加新表
- 缺点:可能导致数据倾斜
- 一致性哈希算法:解决普通哈希扩容问题
- 优点:扩容时仅需迁移部分数据
- 缺点:实现复杂,可能存在数据分布不均问题
全局唯一ID生成方案:
- UUID:简单但长度大、无序
- 数据库自增序列:简单但依赖数据库
- 号段模式:批量申请ID段提高性能
- 雪花算法(Snowflake):分布式高效ID生成方案
- Leaf方案:美团开源的分布式ID方案,结合数据库和ZooKeeper
四、主流分库分表工具对比
1. ShardingSphere (原Sharding-JDBC)
定位:Apache开源的分布式数据库中间件生态,专注于数据分片、分布式事务和数据库治理。
架构组成:
- Sharding-JDBC:客户端分片方案,以JAR包形式提供服务
- Sharding-Proxy:独立部署的服务器,支持异构语言
- Sharding-Sidecar:云原生数据库代理,Kubernetes友好
核心特性:
- 强大的SQL解析引擎,支持复杂查询
- 灵活的分片策略配置
- 分布式事务支持(XA、SAGA、BASE)
- 数据加密、影子库压测等功能
适用场景:Java生态系统,特别是Spring Boot项目;需要透明化分库分表的场景。
配置示例:
spring:
shardingsphere:
datasource:
names: ds0,ds1
ds0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/ds0
username: root
password: root
ds1:
# ...类似配置
rules:
sharding:
tables:
t_order:
actual-data-nodes: ds$->{0..1}.t_order$->{0..1}
database-strategy:
standard:
sharding-column: user_id
sharding-algorithm-name: database-inline
table-strategy:
standard:
sharding-column: order_id
sharding-algorithm-name: table-inline
sharding-algorithms:
database-inline:
type: INLINE
props:
algorithm-expression: ds$->{user_id % 2}
table-inline:
type: INLINE
props:
algorithm-expression: t_order$->{order_id % 2}2. TDDL
来源:阿里巴巴淘宝团队开发的分布式数据库中间件,"透明分布式数据层"的缩写。
核心特性:
- 集成分库分表、读写分离功能
- 支持动态数据源配置和权重调配
- 客户端封装,对应用透明
- 兼容JDBC接口,可平滑迁移
技术架构:
- Diamond配置中心:管理动态配置
- 规则引擎:解析SQL并路由
- 连接池管理:高效连接复用
适用场景:阿里生态系统,淘宝、天猫等电商平台内部广泛使用。
3. Mycat
定位:基于Java的开源分布式数据库中间件,前身是阿里开源的Cobar。
工作模式:
- 独立的代理服务器模式
- 兼容MySQL通信协议
- 支持多种后端数据库
核心特性:
- 支持跨库JOIN和子查询
- 多种分片算法
- 读写分离、SQL防火墙
- 支持NoSQL数据库接入
适用场景:异构系统、需要独立部署数据库中间件的场景、DBA主导的分库分表项目。
配置示例:
<!-- schema.xml -->
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<table name="travelrecord" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
</schema>
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="localhost:3306" user="root" password="root">
<readHost host="hostS1" url="localhost:3307" user="root" password="root" />
</writeHost>
</dataHost>工具对比总结:
| 特性 | ShardingSphere | TDDL | Mycat |
|---|---|---|---|
| 部署方式 | 客户端JAR包/独立服务器 | 客户端JAR包 | 独立服务器 |
| 开源程度 | 完全开源(Apache) | 部分开源 | 完全开源 |
| 社区活跃度 | 高 | 中 | 中 |
| 学习曲线 | 中等 | 较陡 | 较陡 |
| 适用生态 | Java/异构 | 阿里生态 | 异构系统 |
| 分布式事务 | 支持多种模式 | 支持 | 有限支持 |
| 动态配置 | 支持 | 支持(Diamond) | 支持 |
五、总结与展望
1. 技术价值与挑战
分库分表作为解决高并发大数据量场景的有效手段,已在互联网企业广泛应用。它通过水平扩展的方式突破了单机数据库的资源限制,但同时也带来了一系列技术挑战:
- 分布式事务一致性问题
- 跨库查询性能降低
- 运维复杂度提升
- 业务代码侵入性
面对这些挑战,我们需要在架构设计初期就充分考虑分库分表策略,避免后期大规模重构带来的高昂成本。
2. 技术发展趋势
随着云原生技术的发展和数据库产品的演进,分库分表技术也在不断发展:
更智能的分片策略:
- 自适应数据分布算法
- 基于访问模式的智能分片
- 自动化数据再平衡
更完善的分布式事务支持:
- ACID兼容的分布式事务
- 更高性能的柔性事务实现
- 跨异构数据库的事务协调
与云原生技术的融合:
- Kubernetes原生数据库代理
- Serverless数据库分片服务
- 容器化部署与弹性扩展
在实施分库分表时,我们应当保持技术前瞻性,选择具有良好扩展性和社区活跃度的解决方案,为系统未来的演进留下足够的空间。