导读: 当你的分布式系统面临扩容时,传统哈希算法是否让你头疼?数据全量迁移导致的系统压力和性能下降是许多架构师的噩梦。一致性哈希算法通过巧妙的环形空间设计,实现了一个令人惊叹的特性:当节点数量变化时,平均只有K/n的数据需要重新映射。这意味着从64个节点扩展到65个时,只有约1.5%的数据需要迁移,而非传统哈希的接近100%!
本文将深入剖析一致性哈希的工作原理、实现步骤和优化策略,特别是如何通过虚拟节点技术解决数据倾斜问题。无论你正在构建分布式缓存、数据库集群还是微服务架构,这套技术都能帮你突破系统扩展性瓶颈,在保持高性能的同时,实现真正的弹性伸缩。
这是你迈向高可用分布式架构的关键一步,值得每位后端工程师掌握。
一、传统哈希算法的局限性
1.1 传统哈希在分库分表中的应用
在大规模数据存储场景中,分库分表是提升系统性能的常见方案。传统的哈希分片策略通常采用"哈希取模"的方式:
目标分表 = hash(分表键) % 分表数量例如,假设我们有64张表,需要存储或查询一条订单记录,可以通过对买家ID进行哈希运算,再对64取模:
表索引 = hash(buyer_id) % 64这样就能得到一个0-63之间的数字,唯一定位到某个分表。这种方法在分表数量固定时工作良好。
1.2 扩容困境
随着业务增长,当64张表不足以支撑业务需求时,系统面临扩容挑战。如果我们将表数量从64增加到65,使用传统哈希算法会带来什么问题?
新表索引 = hash(buyer_id) % 65这一简单变化会导致灾难性后果: 几乎所有数据的位置都会改变。具体分析:
- 对于任意键值k,只有当
hash(buyer_id) % 64 == hash(buyer_id) % 65时,数据位置才不变 - 这种情况发生的概率极低,意味着接近100%的数据需要重新分布
- 在TB级数据环境下,这将导致大规模数据迁移,系统可能长时间处于高负载状态
- 迁移过程中,系统响应速度下降,可能影响用户体验
如:
扩容前(64表):hash(buyer_id) % 64 = 5 → 数据存储在表5
扩容后(65表):hash(buyer_id) % 65 = 37 → 数据需迁移到表37这种"全局洗牌"式的数据迁移在生产环境中几乎不可接受。

二、一致性哈希算法概述
2.1 核心定义
一致性哈希(Consistent Hashing) 是由MIT的Karger等人在1997年提出的分布式算法,专门解决分布式系统中节点动态变化导致的数据分布问题。其核心目标是:
在分布式环境中,当节点数量发生变化时,尽可能减少数据迁移量,保持系统稳定性。
与传统哈希不同,一致性哈希算法具有以下特性:
- 平滑性: 当节点变化时,平均只有K/n的数据需要重新映射(K是键的数量,n是节点数)
- 单调性: 添加新节点时,只会导致数据从旧节点到新节点的迁移,不会引起数据在旧节点之间的移动
- 分散性: 负载均衡,数据尽可能均匀分布
2.2 基本原理
一致性哈希算法的核心思想是将数据和节点映射到同一个抽象的"哈希环"上。这一环形结构是算法的关键所在:
- 哈希环构建: 将哈希空间(通常是2^32)想象成一个首尾相连的环形结构
- 节点映射: 将服务器节点通过哈希函数映射到环上的某个位置
- 数据映射: 将数据同样哈希到环上的某个位置
- 数据分配规则: 数据沿着哈希环顺时针方向寻找到的第一个节点即为其存储位置
这种映射机制确保了在节点变化时,只有部分数据需要重新分配。
三、一致性哈希的实现步骤
3.1 构建哈希环
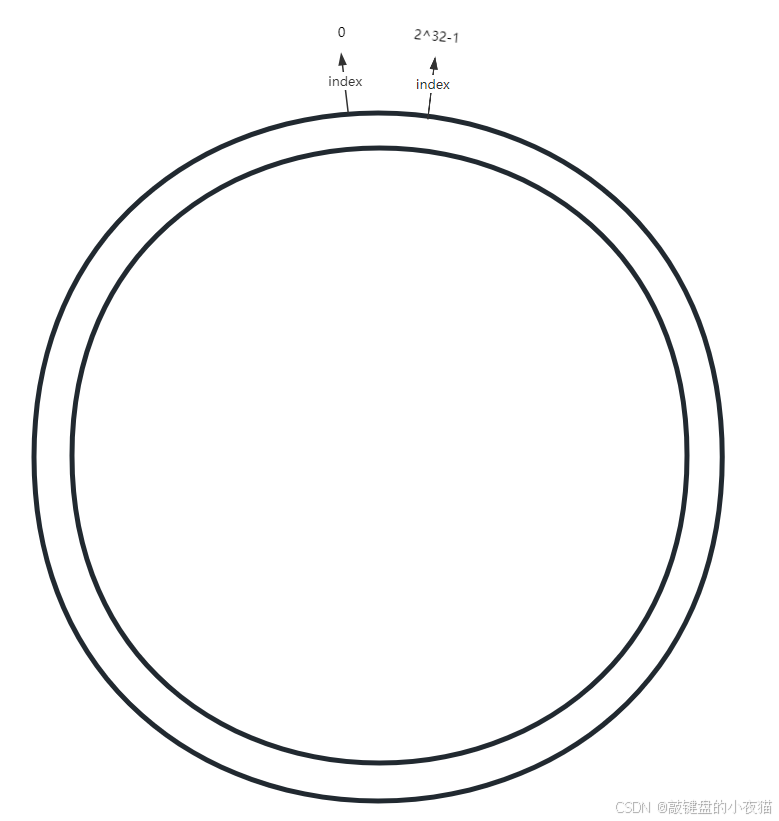
首先,我们需要构建一个哈希空间,通常是一个32位无符号整数范围(0 ~ 2^32-1):
哈希空间范围:[0, 2^32-1] 这个空间可以想象成一个首尾相连的环形结构,环上的每个点都对应一个哈希值。哈希函数的选择需要满足均匀分布特性,常用的有MD5、SHA-1等,然后取其一部分作为整数映射值。
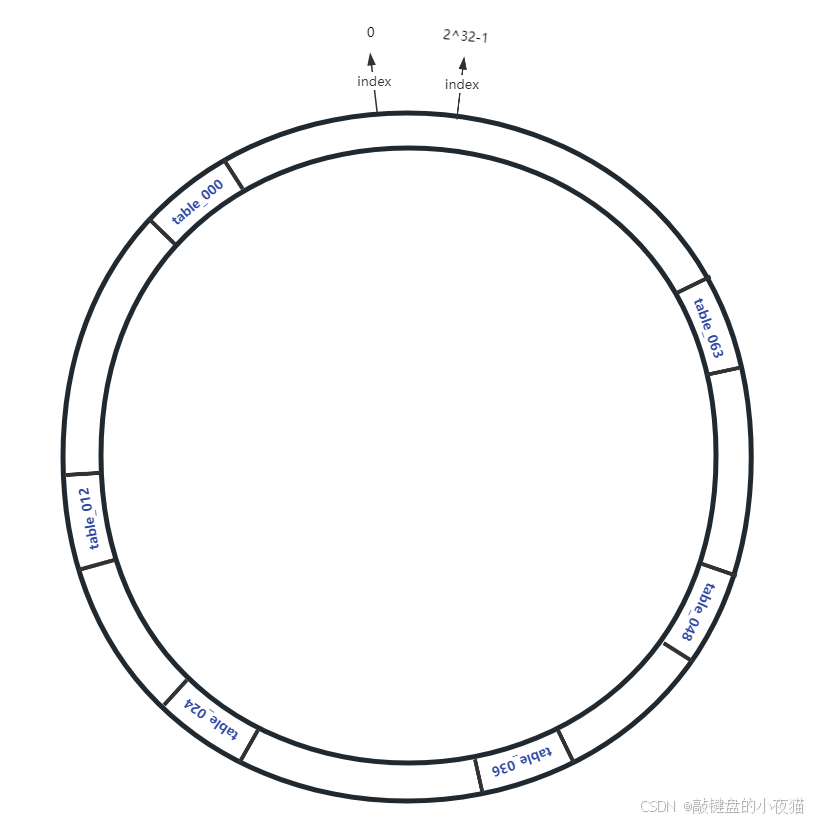
3.2 节点映射
假设我们有64个数据库分表节点,需要将它们映射到哈希环上:、
// 伪代码:节点映射过程
for (int i = 0; i < 64; i++) {
String tableName = "table_" + String.format("%04d", i);
long hashValue = hash(tableName) % (1L << 32);
ring.addNode(hashValue, tableName);
}每个节点在环上的位置由其哈希值决定:
这样,64个分表节点就被分散到了哈希环的不同位置上。
3.3 数据映射与存储
当需要存储或查询数据时,同样使用哈希函数计算数据的哈希值,然后将其映射到环上:
数据位置 = hash(buyer_id) % 2^32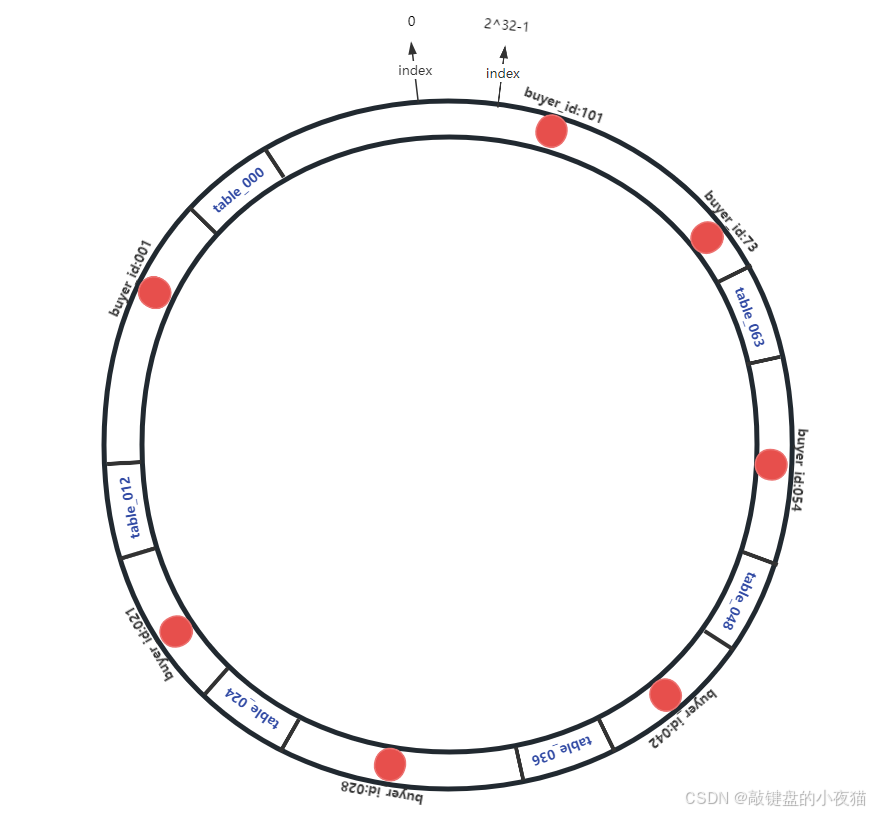
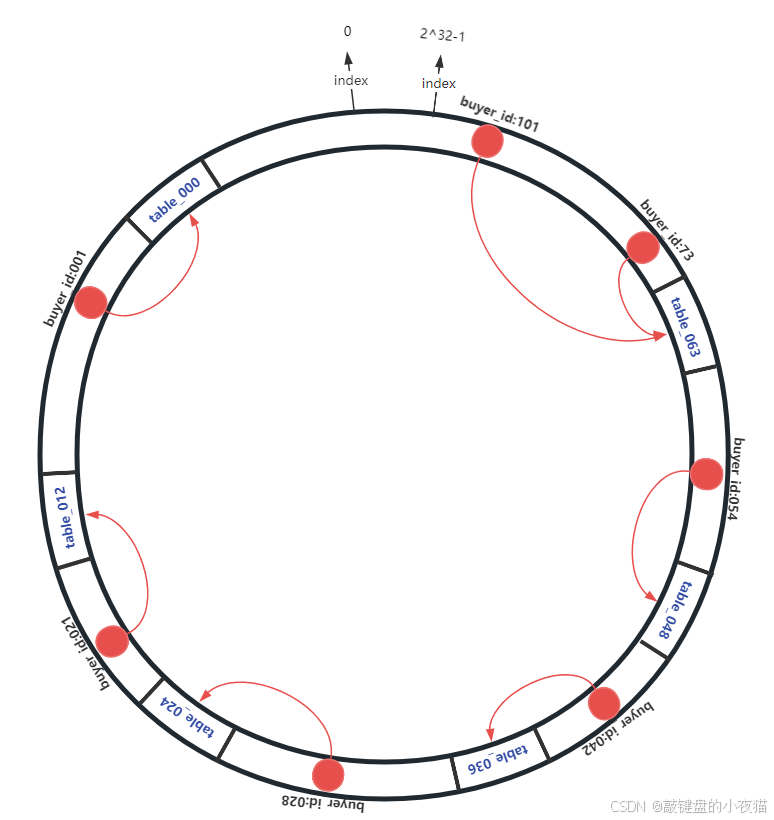
确定数据应该存储在哪个节点时,遵循"顺时针查找最近节点"原则:
// 伪代码:数据定位过程
public Node locate(Object key) {
long hashValue = hash(key) % (1L << 32);
if (!ring.containsKey(hashValue)) {
// 顺时针找到第一个节点
SortedMap<Long, Node> tailMap = ring.tailMap(hashValue);
hashValue = tailMap.isEmpty() ? ring.firstKey() : tailMap.firstKey();
}
return ring.get(hashValue);
}具体过程如下:
- 计算数据key的哈希值
- 在环上顺时针方向查找,直到找到第一个节点
- 将数据存储在该节点上
这种机制确保了数据分布的确定性和一致性,无论何时查询,只要使用相同的哈希函数,都能找到正确的数据位置。
四、节点变更处理机制
4.1 新增节点场景
当系统需要扩容,增加新节点时,一致性哈希的优势开始显现:
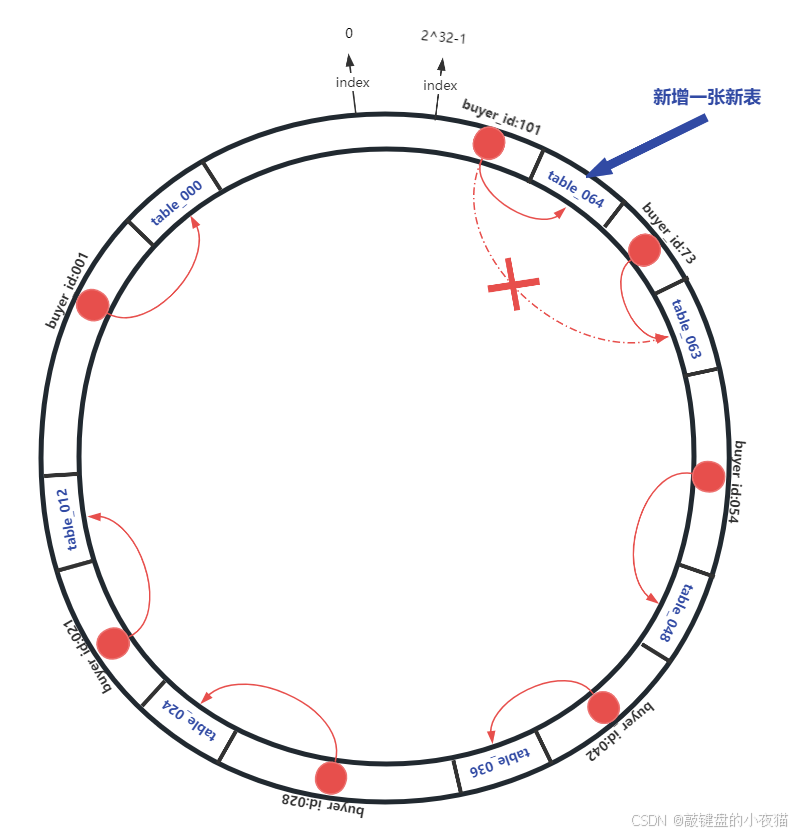
- 新节点映射: 将新节点通过哈希函数映射到环上某个位置
- 数据重分配: 只有落在新节点与其逆时针方向最近节点之间的数据需要迁移
- 局部影响: 其他位置的数据分布不受影响
假设我们在64个节点的基础上增加第65个节点:
新节点位置 = hash(table_064) % 2^32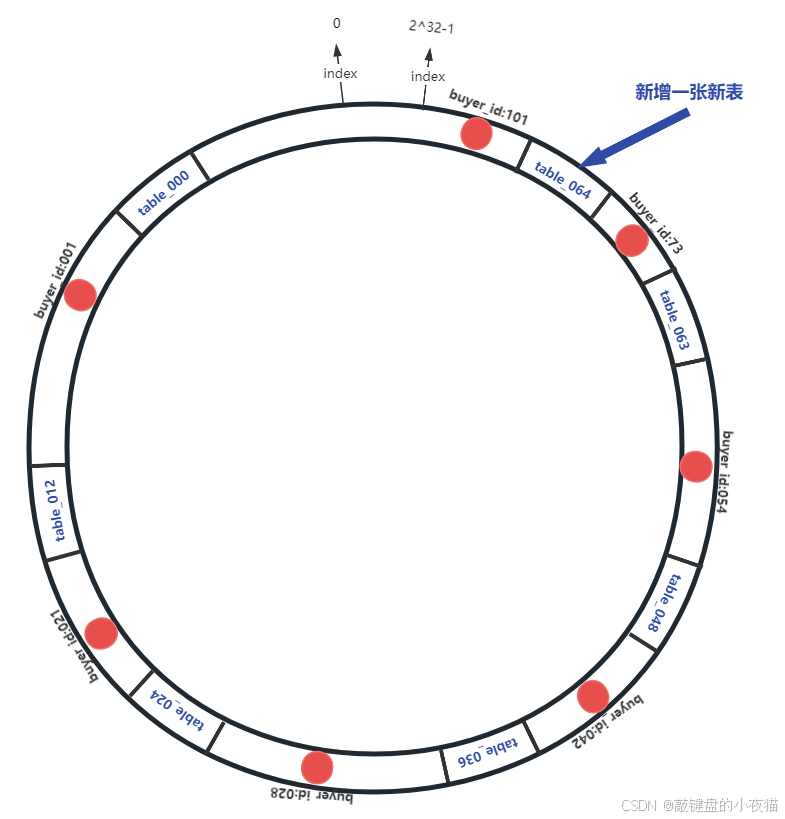
与传统哈希相比:
- 传统哈希:近100%的数据需要重新分布
- 一致性哈希:平均而言,只有1/65(约1.5%)的数据需要迁移
这种局部性是一致性哈希算法最大的优势。
4.2 移除节点场景
当系统需要缩容或节点故障时,一致性哈希同样能够很好地处理:
- 节点移除: 将故障节点从哈希环上移除
- 数据迁移: 只有原本存储在该节点上的数据需要重新分配
- 迁移目标: 这部分数据会被重新分配到顺时针方向的下一个节点
数据迁移范围被严格限制在受影响的区域内,不会对整个系统造成冲击。
五、一致性哈希的优缺点
5.1 主要优势
- 数据迁移最小化: 节点变更时,只有少量数据受影响,大幅降低系统负载
- 高可用性: 节点故障对系统整体影响较小,支持优雅降级
- 高扩展性: 支持动态增删节点,适应弹性扩缩容需求
- 单调性保证: 添加节点时,键与节点间的映射关系保持单调变化,不会引起数据在旧节点间的迁移
5.2 潜在问题
- 哈希倾斜: 当节点数量较少时,数据可能在环上分布不均,导致某些节点负载过重
示例:3个节点在环上的哈希值分别为10、30、50,则[10-30]区间的数据都会存储在节点30上 如果[10-30]区间的数据量远大于其他区间,节点30将承受过大负载 - 热点问题: 即使数据均匀分布,某些高频访问的数据可能集中在少数节点上
- 一致性维护: 在分布式环境中,需要额外机制维护节点状态的一致性视图
六、优化策略
6.1 虚拟节点技术
为解决哈希倾斜问题,一致性哈希算法引入了"虚拟节点"(Virtual Node)概念:
- 基本思想: 为每个物理节点创建多个虚拟节点,分散到哈希环的不同位置
- 实现方式: 通常通过在节点标识符后添加序号来创建不同的虚拟节点
// 伪代码:为每个物理节点创建虚拟节点
for (int i = 0; i < physicalNodes.size(); i++) {
String physical = physicalNodes.get(i);
for (int j = 0; j < VIRTUAL_COPIES; j++) {
String virtual = physical + "#" + j;
long hashValue = hash(virtual) % (1L << 32);
ring.put(hashValue, physical);
}
}虚拟节点带来的好处:
- 均衡负载: 物理节点通过多个虚拟节点分散在环上,数据分布更加均匀
- 降低方差: 减少数据分布的偶然性,使系统性能更加稳定
- 灵活配置: 可以根据节点的处理能力分配不同数量的虚拟节点
通常,为每个物理节点分配100-200个虚拟节点即可达到良好的负载均衡效果。
6.2 实践建议
在实际应用一致性哈希算法时,有以下实践建议:
- 哈希函数选择: 使用分布均匀的哈希函数,如MurmurHash,避免哈希碰撞
- 虚拟节点数量: 根据系统规模和数据分布特性调整,通常每个物理节点映射100-500个虚拟节点
- 渐进式迁移: 节点变更时,采用渐进式数据迁移策略,避免系统负载突增
- 权重分配: 可以根据节点处理能力,动态调整其虚拟节点数量,实现加权负载均衡
- 监控与调优: 实时监控数据分布情况,及时调整算法参数
// 伪代码:考虑节点权重的虚拟节点分配
for (Node node : physicalNodes) {
int virtualCopies = calculateVirtualCopies(node.getCapacity());
for (int i = 0; i < virtualCopies; i++) {
String virtual = node.getId() + "#" + i;
long hashValue = hash(virtual) % (1L << 32);
ring.put(hashValue, node);
}
}七、总结与应用场景
一致性哈希算法通过巧妙的环形哈希空间设计和顺时针查找机制,有效解决了分布式系统中节点动态变化导致的数据分布问题。它在以下场景中具有广泛应用:
- 分布式缓存系统: Memcached、Redis集群等使用一致性哈希进行数据分片
- 内容分发网络(CDN): 通过一致性哈希将用户请求路由到最近的边缘节点
- 分布式数据库: NoSQL数据库如Cassandra使用一致性哈希进行数据分区
- 负载均衡系统: 对客户端请求进行智能路由,均衡服务器负载
- 微服务架构: 服务发现和路由中使用一致性哈希提高缓存命中率
在实际应用中,一致性哈希已经成为分布式系统设计的关键技术之一,它不仅解决了节点扩缩容问题,还为系统提供了更好的可扩展性和容错能力。
思考问题: 在你的系统中,数据分片策略是如何实现的?如果需要进行系统扩容,会面临哪些挑战?一致性哈希算法是否适合你的场景?
参考资料:
- Karger, D. et al. (1997). "Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web"
- 《大型网站技术架构:核心原理与案例分析》
- 《分布式系统:概念与设计》
拓展阅读: