目录
导读:在高并发互联网应用中,MySQL热点数据更新一直是技术团队面临的核心挑战。当秒杀、抢购等场景中数十万并发请求同时涌向少数几行记录时,传统的MySQL锁机制往往成为系统瓶颈。本文系统讲解了四种实用的热点数据更新方案:库存拆分、请求合并、Updates转Insert以及MySQL内核改造方案,并提供了详细的技术实现和代码示例。
你是否思考过,为何有些电商平台在双十一能承受上千万TPS而系统依然稳健?文中揭示的批量更新方案如何将数据库写入压力降低99%?
无论你是面临高并发业务挑战的架构师,还是希望深入理解数据库性能优化的开发者,这篇文章都将为你提供一套完整的解决思路与实践指南。
引言
在当今高并发互联网应用场景下,MySQL热点数据更新一直是技术团队面临的重大挑战。特别是在秒杀、抢购、积分变更等业务场景中,数百万甚至上千万的并发请求可能同时涌向数据库中的少数几行记录。若处理不当,轻则用户体验下降,重则可能导致数据库服务崩溃,造成重大业务损失。
据统计,许多知名电商平台在大促期间,热点商品的库存数据每秒可能面临数十万次的并发更新请求。这种极端场景下,传统的MySQL锁机制和事务处理方式往往捉襟见肘,成为整个系统的性能瓶颈。
本文将系统探讨如何在MySQL层面有效应对热点数据高并发更新挑战,从理论分析到实践经验,为开发者提供一套完整的解决思路与具体实施方案。
常见MySQL热点数据更新方案
库存拆分方案
工作原理: 库存拆分方案的核心思想是将一个大的库存值拆分成多个小的库存记录,分散到不同的数据库实例或数据表中。例如,将10000件商品的库存拆分为100条记录,每条记录代表100件商品。
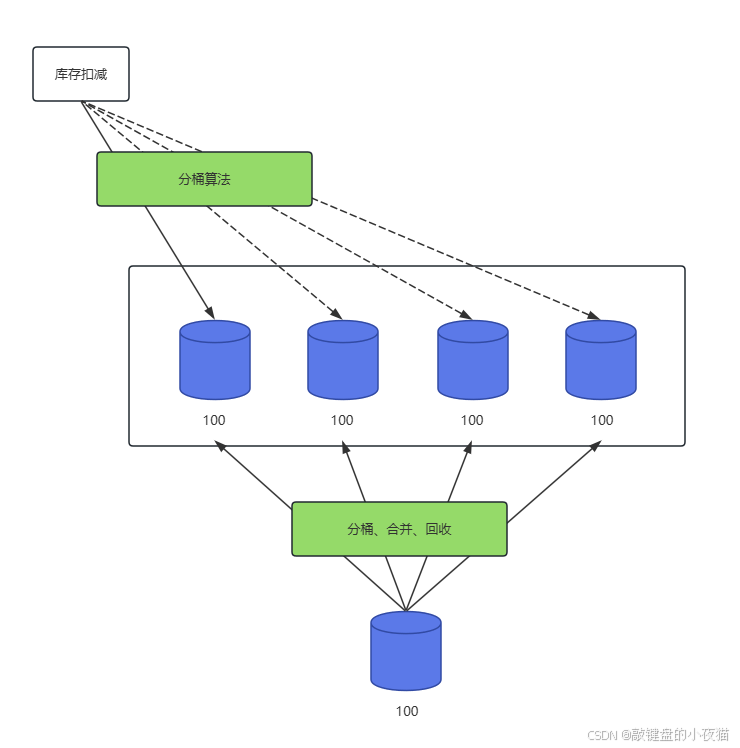
技术实现:
-- 创建拆分后的库存表
CREATE TABLE inventory_shards (
product_id INT,
shard_id INT,
inventory INT,
PRIMARY KEY (product_id, shard_id)
);
-- 初始化库存分片(以10000件商品拆分为10个分片为例)
INSERT INTO inventory_shards (product_id, shard_id, inventory)
SELECT 1001, number, 1000 FROM generate_series(1, 10) AS number;
-- 扣减库存时随机选择一个分片
UPDATE inventory_shards
SET inventory = inventory - 1
WHERE product_id = 1001 AND shard_id = FLOOR(RANDOM() * 10) + 1
AND inventory > 0;优点:
- 实现相对简单,无需修改数据库内核
- 显著降低了锁粒度,将单行锁竞争分散到多行
- 可以根据并发压力灵活调整拆分粒度
缺点:
- 存在库存碎片问题,可能导致部分库存无法售出
- 库存调控与统计变得复杂
- 事务一致性保证难度增加
适用场景: 适合可接受库存碎片化的高并发秒杀活动,例如电影票预售、限时促销等对库存精确控制要求不太严格的场景。
请求合并方案
工作原理: 请求合并方案通过临时存储并批量处理更新请求,将多个独立的数据修改操作合并为一次批量操作,大幅减少数据库写入次数与锁竞争。
技术实现:
- 设置请求队列或缓冲区收集短时间内的更新请求
- 定时或达到阈值后触发批量更新操作
- 返回操作结果给原请求方
优点:
- 显著减少数据库写入压力,提高吞吐量
- 降低锁竞争,减少死锁风险
- 实现相对简单,无需复杂基础设施
缺点:
- 引入一定的操作延迟,不适合强实时场景
- 需要额外的请求缓存与状态管理机制
- 失败恢复机制设计较复杂
适用场景: 适合可接受轻微延迟的高频操作场景,如用户积分变更、商品评分统计、浏览量更新等非核心交易类操作。
Update转Insert方案
工作原理: 该方案彻底规避了UPDATE操作带来的锁竞争问题,而是采用INSERT方式记录每次操作,通过累计流水记录计算最终结果。
技术实现:
-- 创建操作流水表
CREATE TABLE inventory_transactions (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
product_id INT,
quantity INT, -- 负数表示减少,正数表示增加
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 记录一次扣减操作
INSERT INTO inventory_transactions (product_id, quantity) VALUES (1001, -1);
-- 计算当前实际库存
SELECT
initial_inventory + COALESCE(SUM(quantity), 0) AS current_inventory
FROM
products p
LEFT JOIN
inventory_transactions t ON p.id = t.product_id
WHERE
p.id = 1001;优点:
- 完全避免行锁竞争,插入操作可高度并行
- 保留完整操作历史,便于审计和问题排查
- 系统扩展性好,适合分布式架构
缺点:
- 库存控制精确度难以保证,易出现超卖问题
- 实时库存查询需要聚合计算,性能较低
- 历史数据累积导致表体积快速增长
适用场景: 适合对实时库存精确度要求不高,但需要完整操作日志的业务场景,如虚拟商品销售、内容付费下载等。
改造MySQL:双十一实战级解决方案
在面对超大规模电商促销活动的极限挑战下,传统方案往往力不从心。以下介绍一种深度优化MySQL内核的企业级解决方案,该方案已在多家头部互联网公司的双十一等大促活动中得到验证。
技术核心与实现原理
这种方案的核心思想是针对热点行数据的UPDATE操作进行专项优化。通过在MySQL执行层实现热点行自动检测和并发控制,系统能够主动识别高频访问的数据行,并自动将对同一热点行的大量并发更新请求在执行层进行有序排队处理。
与传统的行锁排队机制不同,该方案在事务层之前就完成了请求的排队整合,避免了大量事务进入执行阶段后的自旋等待和锁资源争抢,显著降低了系统资源消耗。
实现机制详解
当开启热点更新自动检测功能后,MySQL服务器会维护一个热点行记录表,通过采样分析识别出短时间内被频繁更新的数据行。一旦某行数据被判定为热点,后续针对该行的更新请求将被引导至专门的排队处理通道,而非直接进入标准的执行路径。
这种排队处理机制相比传统的行锁排队有以下显著优势:
- 无需事务自旋等待,减少CPU资源消耗
- 避免频繁的锁资源申请与释放操作
- 请求处理更为有序,减少死锁风险
- 系统可预测性更强,性能更加稳定
用户配置与使用便利性
这种优化方案的一大优势是对应用代码几乎零侵入,开发人员只需开启热点检测功能,无需修改现有业务逻辑。典型配置如下:
-- 开启热点更新检测(以MySQL为例)
SET GLOBAL hotspot_detection = ON;
SET GLOBAL hotspot_threshold = 100; -- 每秒更新请求阈值云服务实现案例
随着云数据库服务的普及,多家云厂商已将这类高级特性集成到其MySQL服务中:
腾讯云数据库MySQL热点更新: 腾讯云基于TXSQL内核实现了热点更新功能,能够自动识别热点数据并进行特殊处理,测试表明在高并发场景下可提升TPS至少30%以上。详细配置可参考官方文档:云数据库 MySQL 热点更新_腾讯云
阿里云数据库Inventory Hint: 阿里云RDS MySQL提供了Inventory Hint功能,专门针对库存扣减等热点更新场景进行了优化,使用特定SQL hint可激活该功能。详情可参考:调用Inventory Hint提高吞吐能力 - 云数据库 RDS - 阿里云
批量更新方案实战详解
请求合并批量更新是一种无需修改数据库内核,通过应用层优化即可实现的高效方案。下面详细介绍其架构设计与实现细节。
基本架构设计
核心思想: 将实时处理的并发操作转为分时段的批量处理,通过"写入分离"模式降低主数据表的写入压力。
系统架构:
- 前端请求接入层:接收并验证用户请求
- 临时数据存储层:记录待处理的操作请求
- 批量处理执行层:定期将临时数据合并更新到主表
- 结果查询反馈层:为用户提供操作结果和状态查询
数据流转过程: 用户操作 → 请求验证 → 写入临时表 → 返回受理结果 → 定时任务批量处理 → 更新主表 → 清理临时数据
具体实现步骤
收集和汇总操作请求
首先需要设计一个用于存储待处理请求的临时表:
CREATE TABLE pending_operations (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
user_id INT NOT NULL COMMENT '用户ID',
operation_type VARCHAR(20) NOT NULL COMMENT '操作类型',
target_id INT NOT NULL COMMENT '目标对象ID',
value_change INT NOT NULL COMMENT '数值变更',
status TINYINT DEFAULT 0 COMMENT '处理状态:0未处理,1已处理,-1处理失败',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
processed_at TIMESTAMP NULL COMMENT '处理时间',
INDEX idx_status_created (status, created_at),
INDEX idx_target (operation_type, target_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;当用户发起操作请求时,系统验证请求有效性后,将操作信息写入临时表:
-- 以积分增加操作为例
INSERT INTO pending_operations
(user_id, operation_type, target_id, value_change)
VALUES
(123, 'POINTS_ADD', 123, 10);此时可以立即向用户返回操作已受理的响应,提升用户体验。
定期更新主数据表
通过调度系统(如Quartz、XXL-Job等)设置定时任务,定期执行批量更新操作:
-- 批量更新用户积分
BEGIN;
-- 1. 标记待处理的记录
UPDATE pending_operations
SET status = 2 -- 标记为处理中
WHERE status = 0 -- 仅处理未处理的记录
AND operation_type = 'POINTS_ADD'
AND created_at <= NOW() - INTERVAL 2 MINUTE; -- 留出缓冲时间,避免处理过新的记录
-- 2. 批量更新用户积分
UPDATE users u
JOIN (
SELECT target_id, SUM(value_change) as total_change
FROM pending_operations
WHERE status = 2
AND operation_type = 'POINTS_ADD'
GROUP BY target_id
) po ON u.user_id = po.target_id
SET u.points = u.points + po.total_change;
-- 3. 标记已处理的记录
UPDATE pending_operations
SET status = 1, -- 标记为已处理
processed_at = NOW()
WHERE status = 2
AND operation_type = 'POINTS_ADD';
COMMIT;异常处理与补偿机制
为保证数据一致性,需要实现完善的异常处理与补偿机制:
-- 查找长时间未处理成功的记录
SELECT * FROM pending_operations
WHERE status IN (0, 2) -- 未处理或处理中
AND created_at <= NOW() - INTERVAL 30 MINUTE;
-- 补偿处理
-- 根据业务逻辑重新执行或标记为失败
UPDATE pending_operations
SET status = -1, -- 标记为处理失败
processed_at = NOW()
WHERE id IN (...); -- 需要补偿处理的记录ID性能优化建议
合理设置批处理间隔:根据业务特性和系统负载,设置最佳的批处理时间间隔,通常在30秒至5分钟之间
分批次处理大量数据:对于积累的大量待处理记录,采用分页处理,避免单次事务过大
索引优化:为临时表的查询条件和关联字段建立合适的索引
监控机制:实时监控待处理队列长度,当积压超过阈值时触发告警
定期归档:对已处理的历史数据进行定期归档,避免表数据量过大影响性能
实际应用效果
在我们的生产环境中,采用批量更新方案处理用户积分变更,将原本每秒数千次的数据库写入操作降低到每分钟一次批量更新,数据库写入压力降低了99%,系统稳定性得到显著提升。特别是在营销活动高峰期,当单日积分变更操作超过千万次时,该方案的优势更为明显。
方案选择指南
针对不同的业务场景和技术条件,如何选择合适的热点数据更新方案?以下是一份实用的决策参考框架:
基于性能需求的选择
| 并发量级别 | 推荐方案 | 说明 |
|---|---|---|
| 极高(10万+TPS) | MySQL改造方案 | 适合大型电商秒杀场景 |
| 高(1万-10万TPS) | 库存拆分 + 请求合并 | 综合考虑性能与实现成本 |
| 中(1千-1万TPS) | 请求合并方案 | 简单高效,适合大多数业务 |
| 低(1千TPS以下) | 常规优化 | 合理设计索引与事务即可 |
基于实现难度的选择
对于技术资源有限的团队,推荐按以下顺序考虑:
- 请求合并方案:实现简单,效果明显,适合大多数场景
- 库存拆分方案:概念清晰,易于理解和实现
- Updates转Insert方案:需要较好的数据管理和统计能力
- 改造MySQL方案:技术门槛高,建议采用云服务现成解决方案
基于业务特性的选择
| 业务特点 | 推荐方案 | 原因 |
|---|---|---|
| 实时性要求极高 | MySQL改造方案 | 保证实时性的同时提升并发 |
| 可接受轻微延迟 | 请求合并方案 | 显著提升系统吞吐量 |
| 需要完整操作日志 | Updates转Insert方案 | 保留所有操作记录 |
| 库存精确控制不严格 | 库存拆分方案 | 简单高效 |
基于成本考量的选择
| 预算条件 | 推荐方案 | 说明 |
|---|---|---|
| 充足 | 云服务MySQL热点更新 | 直接使用现成云服务 |
| 中等 | 请求合并 + 定时任务 | 开发成本适中,效果良好 |
| 有限 | 库存拆分 | 实现简单,基本无额外基础设施要求 |
总结与展望
MySQL热点数据更新问题是高并发系统设计中的关键挑战之一。通过本文介绍的多种解决方案,从不同角度为这一问题提供了系统性的解决思路。
主要方案回顾
- 库存拆分:通过降低锁粒度提升并发能力
- 请求合并:将实时更新转为批量处理,减轻数据库压力
- Updates转Insert:规避锁竞争,提供完整操作历史
- 改造MySQL:从数据库内核层面解决高并发更新问题