源自: AINLPer(每日干货分享!!)
编辑: ShuYini
校稿: ShuYini
时间: 2025-4-2
引言
紧跟技术发展趋势,快速了解大模型最新动态。今天继续总结最近一周的研究动态,本片文章共计梳理了8篇有关大模型(LLMs)的最新研究进展,其中主要包括:Meta最新Llama4、DeepSeek最新训练方法、强化学习Dr.GRPO、大模型Agent应用、最新MoE架构等热门研究及咨询。
Meta | 开源Llama 4
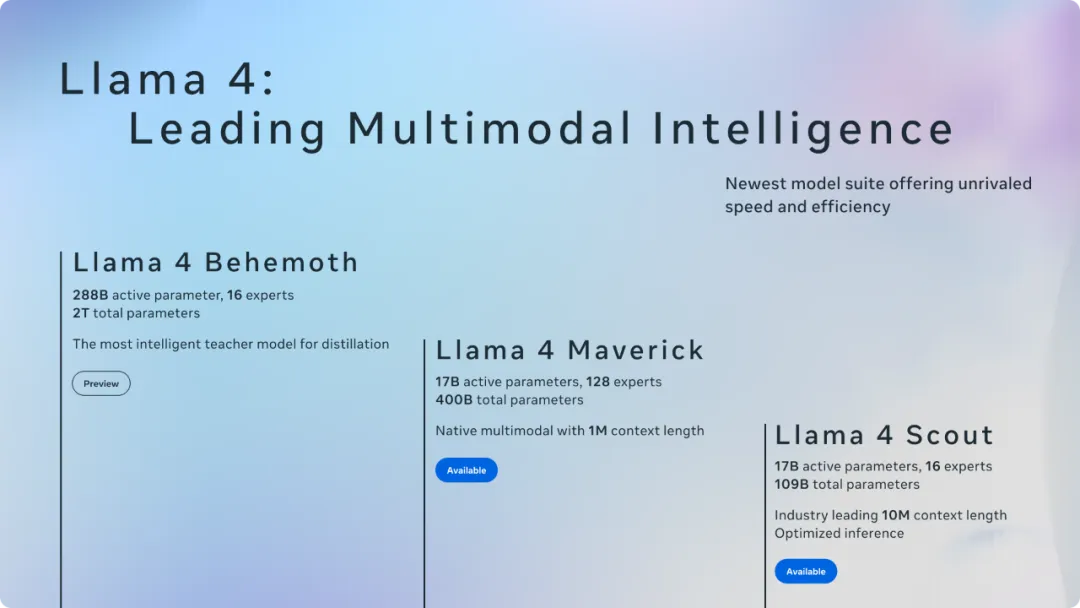
Meta发布Llama4系列模型。该系列包括 Llama 4 Scout、Llama 4 Maverick 和 Llama 4 Behemoth。所有这些模型都经过了大量未标注的文本、图像和视频数据的训练,以使它们具备广泛的视觉理解能力。
Llama 4 Scout 拥有 170 亿激活参数、16 个专家和 1090 亿总参数,是目前全球同类中最佳的多模态模型,支持长达 1000 万 token 的上下文窗口,采用无位置嵌入的交错注意力层(iRoPE 架构)以增强长上下文泛化能力,在编码、推理、长上下文和图像基准测试中表现优异。
Llama 4 Maverick 拥有 170 亿激活参数、128 个专家和 4000 亿总参数,是同类中性能最强的多模态模型,采用交替的密集层和混合专家(MoE)层来提高推理效率。在 MoE 层中,使用了128 个路由专家和一个共享专家。其 ELO 得分在 LMArena 上达到 1417,总排名第二,超越了 DeepSeek,在困难提示词、编程、数学和创意写作等任务中表现突出。
Llama 4 Behemoth 是目前 Meta 最强大的模型之一,拥有 2880 亿激活参数、16 个专家和近 2 万亿总参数,采用混合专家(MoE)架构和 FP8 精度训练,数据混合总量超过 30 万亿 token,支持多模态输入,正在训练中,未来将释放更多内容。
DeepSeek | SPCT训练方法

连接:https://arxiv.org/abs/2504.02495
强化学习(RL)在大规模大型语言模型(LLM)后训练中被广泛应用。研究表明,合适的训练方法可以提升模型的推理时扩展性。然而,获取准确的奖励信号是强化学习的一大挑战,尤其是在复杂领域中。
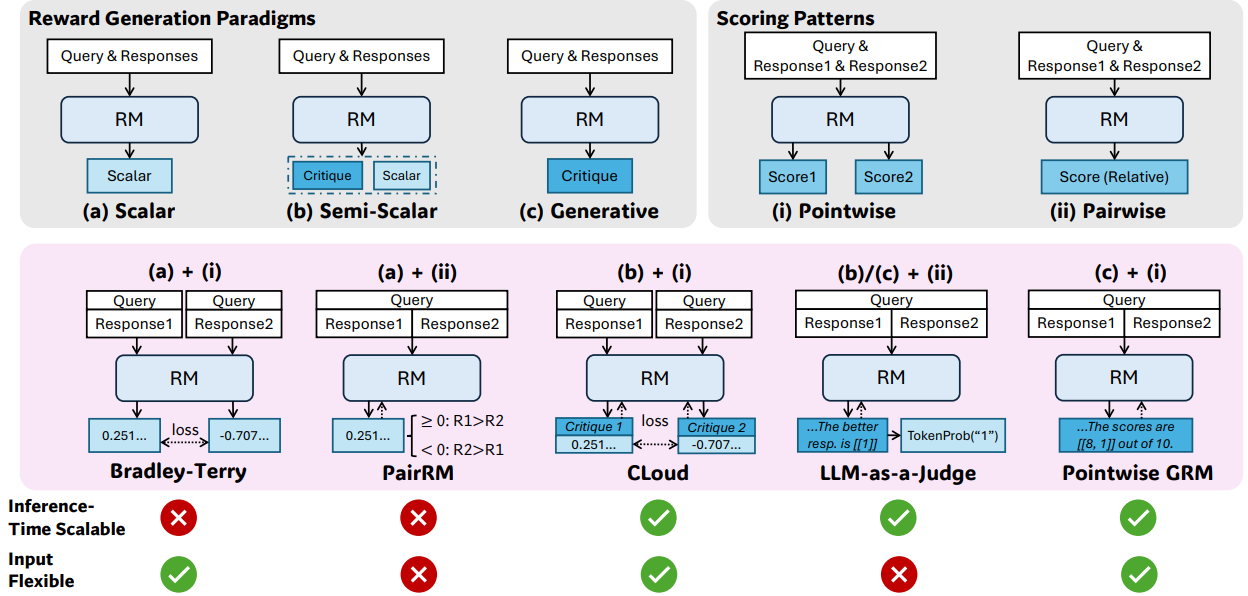
本文作者研究了如何通过增加推理计算资源来提升奖励建模(RM)的扩展性,并提出了一种新的训练方法——SPCT。该方法通过在线强化学习优化生成式奖励建模(GRM),使其能够自适应生成原则并准确生成批评,从而开发出DeepSeek-GRM模型。此外,作者还通过并行采样和元奖励模型进一步提升了推理时的扩展性。实验结果表明,SPCT显著提高了GRM的质量和扩展性,在多个基准测试中表现优于现有方法,且没有明显偏差。尽管DeepSeek-GRM在某些任务中仍有待改进,但作者认为未来的研究可以解决这些问题。
UNC |符号MoE架构

连接:https://arxiv.org/pdf/2503.05641
将现有预训练专家LLMs组合是解决大规模多样化任务的一种方法,但任务级选择专家过于粗粒度。
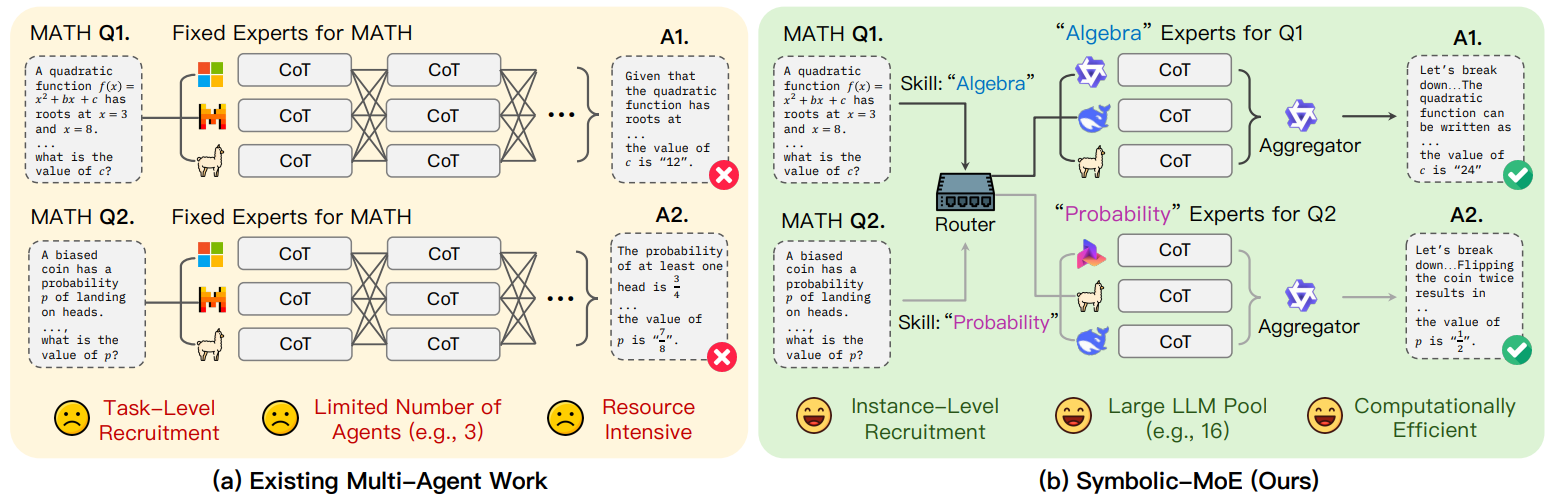
本文作者提出了符号混合专家(Symbolic-MOE)框架,通过强调技能(如数学中的代数、生物医学推理中的分子生物学等)进行细粒度选择,基于专家优势动态选择与任务最相关的专家LLMs集合,各专家生成推理结果后由聚合器整合成高质量响应。为降低计算开销,采用批量推理策略,按分配专家对实例分组,实现单GPU集成16模型,时间成本与4 GPU多代理基线相当。在多个基准测试中,Symbolic-MOE性能优于强LLMs及多代理方法,平均提升8.15%,且无需昂贵多轮讨论,计算量更少。

HKUST |YuE模型:长音乐生成
本文作者针对长篇音乐生成中的歌词到歌曲难题,基于LLaMA2架构提出了YuE模型。该模型可扩展至万亿级token,生成长达5分钟的音乐,保持歌词对齐、音乐结构连贯和吸引人的旋律。
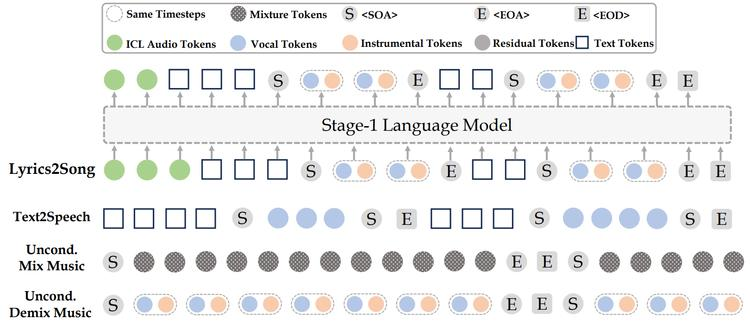
通过轨道解耦的下一个token预测、结构化渐进式条件和多任务多阶段预训练实现。还重新设计了音乐生成的上下文学习技术,支持风格转换和双向生成。经评估,YuE在音乐性和人声灵活性上可匹敌甚至超越一些专有系统,其学习到的表示在音乐理解任务上表现优异。
Sea | 强化学习:Dr.GRPO
连接:https://arxiv.org/pdf/2503.20783
DeepSeek-R1-Zero证明了强化学习(RL)可直接提升大型语言模型(LLMs)的推理能力,无需监督微调。本文作者对 R1-Zero 类训练的两大核心组件——基础模型和RL进行了批判性分析,研究发现,DeepSeek-V3-Base 基础模型已表现出“顿悟时刻”,而 Qwen2.5 基础模型即使没有提示模板也具备强大推理能力,暗示了预训练可能存在偏差。

此外,本文作者发现GRPO存在优化偏差,会导致训练时响应长度增加,尤其是错误输出。为此,作者引入无偏优化方法Dr.GRPO,在保持推理性能的同时提升token效率。基于这些见解,提出极简 R1-Zero 方案,使用 7B 基础模型在 AIME 2024 上达到 43.3% 准确率,创下新纪录。
Tuebingen| 升级版LoRA:DeLoRA
连接:https://arxiv.org/pdf/2503.18225
随着大规模预训练模型的广泛应用,参数高效微调(PEFT)方法因能快速适应下游任务且计算成本低而受关注。但常见微调方法如LoRA在超参数选择或扩展训练方案方面表现的鲁棒性存在一定的局限性。
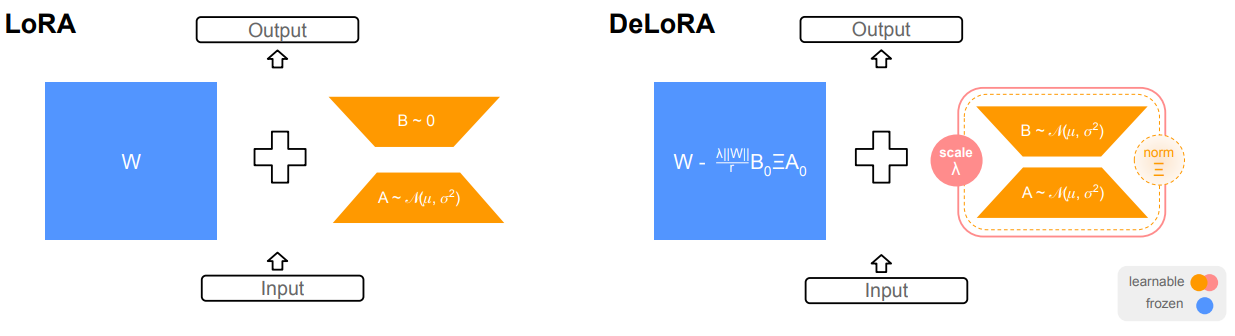
为此,本文作者提出了解耦低秩适配(DeLoRA)方法,通过归一化和缩放可学习低秩矩阵,限制变换距离,有效解耦角度学习与适配强度,增强鲁棒性且不损失性能。在主题驱动的图像生成、自然语言理解和指令微调等任务评估中,DeLoRA匹配或超越了其他PEFT方法性能,且鲁棒性更强。
清华| 目标检测分割:YOLOE
连接:https://arxiv.org/pdf/2503.07465
目标检测与分割在计算机视觉应用中广泛使用,但传统模型如YOLO系列主要依赖预定义类别,在开放场景中应用受限。
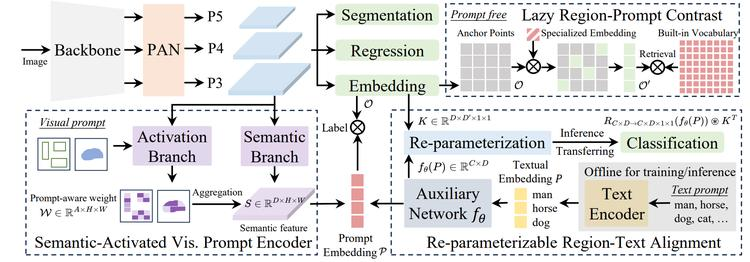
为此,本文作者提出YOLOE,将检测与分割整合于单一高效模型,涵盖多种开放提示机制,实现任意目标实时识别。
针对文本提示,提出可重参数化区域文本对齐(RepRTA)策略,通过轻量辅助网络优化预训练文本嵌入,强化视觉文本对齐且无推理和迁移开销;
对于视觉提示,呈现语义激活视觉提示编码器(SAVPE),采用解耦语义与激活分支,在极小复杂度下提升视觉嵌入与精度;
在无提示场景下,引入懒惰区域提示对比(LRPC)策略,借助内置大词汇量与专用嵌入识别所有目标,避免依赖昂贵语言模型。
大量实验表明YOLOE零样本性能卓越、迁移性强,推理效率高且训练成本低。
JHU|AgentRxiv框架,助力科学研究
连接:https://arxiv.org/pdf/2503.18102
科学发现往往是众多科学家共同协作的成果,但现有智能体工作流自主研究时相互孤立。
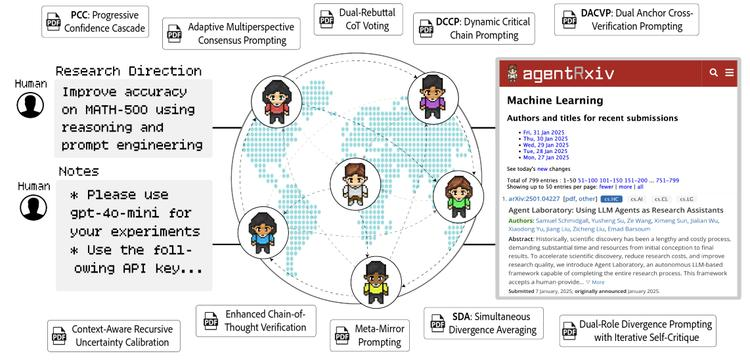
本文作者提出AgentRxiv框架,让LLM智能体实验室能从共享预印服务器上传、检索报告,实现协作、共享见解、迭代构建研究。实验表明,能访问先前研究的智能体相比孤立智能体性能提升更明显(在MATH - 500上相对基线提升11.4%),且该策略在其他领域基准测试中平均提升3.3%。多个实验室通过AgentRxiv共享研究成果,朝着共同目标更快进步,整体准确率更高(在MATH - 500上相对基线提升13.7%),表明自主智能体或许能与人类共同设计未来AI系统,加速科学发现。
推荐阅读
[1] 2025年的风口!| 万字长文让你了解大模型Agent
[2]Transformer | 一文了解:缩放、批量、多头、掩码、交叉注意力机制(Attention)
[3] 大模型Agent的 “USB”接口!| 一文详细了解MCP(模型上下文协议)
[4] 盘点一下!大模型Agent的花式玩法,涉及娱乐、金融、新闻、软件等各个行业
[5] 一文了解大模型Function Calling
[6] 万字长文!最全面的大模型Attention介绍,含DeepSeek MLA,含大量图示!
[7]一文带你详细了解:大模型MoE架构(含DeepSeek MoE详解)
[8] 颠覆大模型归一化!Meta | 提出动态Tanh:DyT,无归一化的 Transformer 性能更强