源自: AINLPer(每日干货分享!!)
编辑: ShuYini
校稿: ShuYini
时间: 2025-3-19
引言
紧跟技术发展趋势,快速了解大模型最新动态。今天继续总结最近一周的研究动态,本片文章共计梳理了10篇有关大模型(LLMs)的最新研究进展,其中主要包括:多尺度注意力(Attention)、强化学习算DAPO算法、大模型多Agent系统、人形机器人、调研报告生成、多模型推理模型、长CoT推理模型、RAG系统能力提升应等热门研究。
伯克利 | 多尺度注意力:Atlas

https://arxiv.org/pdf/2503.12355
高效建模大规模图像是机器学习的长期挑战。本文作者基于多尺度表示和双向跨尺度通信两大关键思想,提出了多尺度注意力(MSA)。基于此,作者设计了新型神经网络架构Atlas,在高分辨率ImageNet 100变体中显著改善长上下文图像建模的计算-性能权衡。

实验结果表明,1024px分辨率下,Atlas-B准确率达91.04%,与ConvNext-B相当但速度快4.3倍,且相较于FasterViT、LongViT等在速度和准确率上均有优势,与MambaVision-S相比在不同分辨率下准确率提升明显且运行时间相近。
字节 | DAPO算法,助力RL

https://arxiv.org/pdf/2503.14476
推理扩展赋予了LLMs前所未有的推理能力,强化学习是引发复杂推理的核心技术。然而,当前先进推理LLMs的关键技术细节被隐藏,社区难以复现其强化学习训练成果。

为此,本文作者提出了解耦剪辑和动态采样策略优化 (DAPO) 算法,开源了一个使用Qwen2.5-32B基础模型在AIME 2024上达到50分的先进大规模强化学习系统。与以往隐藏训练细节的作品不同,作者介绍了算法成功的四大关键技巧,并开源了基于verl框架构建的训练代码以及精心整理的数据集,增强了可复现性,助力未来大规模LLM强化学习研究。
港理工 | 视频语言Agent

https://arxiv.org/pdf/2503.13444
本文提出了一个新颖的视频-语言 Agent :VideoMind,旨在实现对时序视频理解。通过识别视频时间推理的关键能力并开发基于角色的工作流程,包括规划者、定位器、验证者和回答者。作者还提出了链式LoRA策略,通过轻量级LoRA适配器实现无缝角色切换,平衡了效率和灵活性。
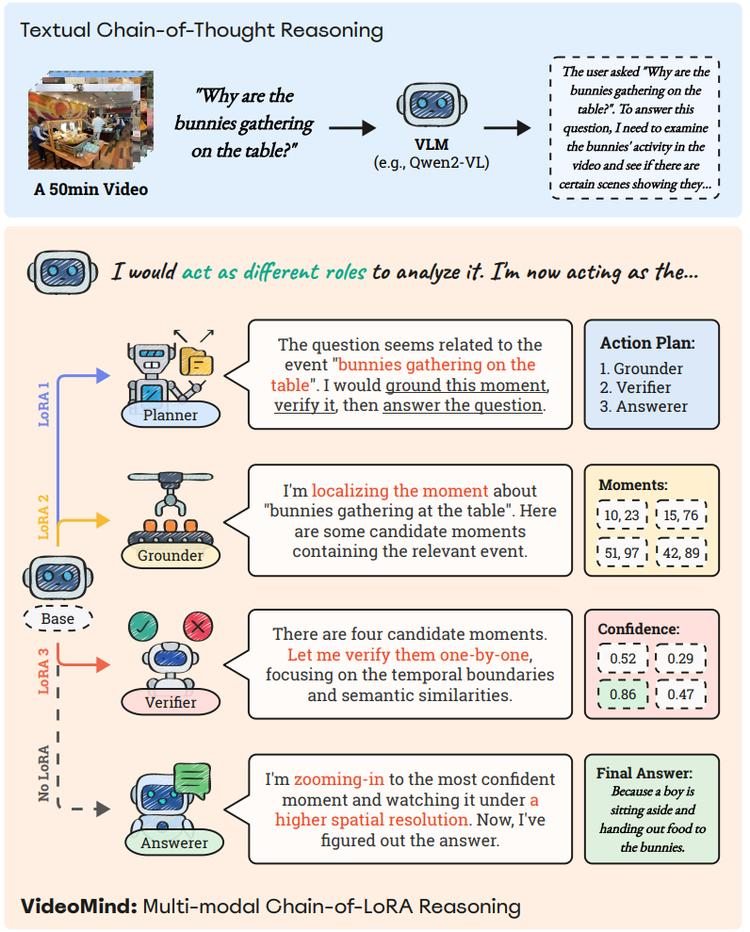
在14个公共基准测试中,VideoMind在多种视频理解任务上取得了最先进的性能,包括3个基于视频的问题回答、6个视频时间定位和5个一般视频问题回答,突出了其在视频代理和长视频推理方面的有效性。
NUS|MovieAgent,自动化电影生成
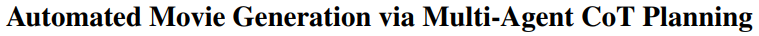
https://arxiv.org/pdf/2503.07314
本文作者提出了MovieAgent系统,旨在自动化长视频生成流程。
MovieAgent能够根据剧本和角色库生成多场景、多镜头的长视频,并保持叙事连贯性、角色一致性、字幕同步和稳定音频。其引入的层次化CoT推理过程自动构建场景、相机设置和电影摄影,显著减少人力投入。通过模拟导演、编剧、故事板艺术家和场地经理等角色,MovieAgent简化了生产流程,并在脚本忠实度、角色一致性和叙事连贯性方面取得了新进展。
北大 | 人形机器人框架Being-0

https://arxiv.org/pdf/2503.12533
本文作者介绍了Being-0框架,旨在构建能在现实世界中执行复杂任务的人形机器人。该框架包含三个关键部分:负责高级认知任务的Foundation Model(FM),提供稳定运动和灵巧操控的模块化技能库,以及连接FM和低级技能的视觉语言模型(VLM)。
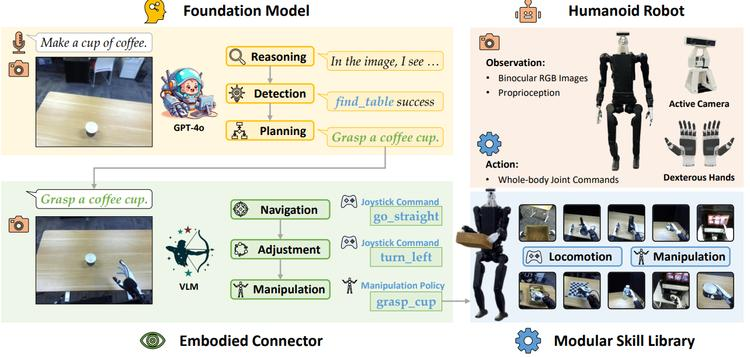
VLM增强了FM的具身能力,将基于语言的计划转化为可执行的技能命令,并动态协调运动和操控以提高任务成功率。所有组件(除FM外)均可部署在低成本的机载计算设备上,使Being-0能在全尺寸人形机器人上实现高效、实时的性能。
上海AI-Lab | 调研论文生成

https://arxiv.org/pdf/2503.04629
本文作者介绍了SURVEYFORGE,一个自动化生成调研论文的工具,旨在提高效率并缩小与人类撰写调研论文的质量差距。SURVEYFORGE通过分析人类撰写的大纲逻辑结构和引用相关领域文章生成大纲,利用高质量论文自动生成和优化文章内容。
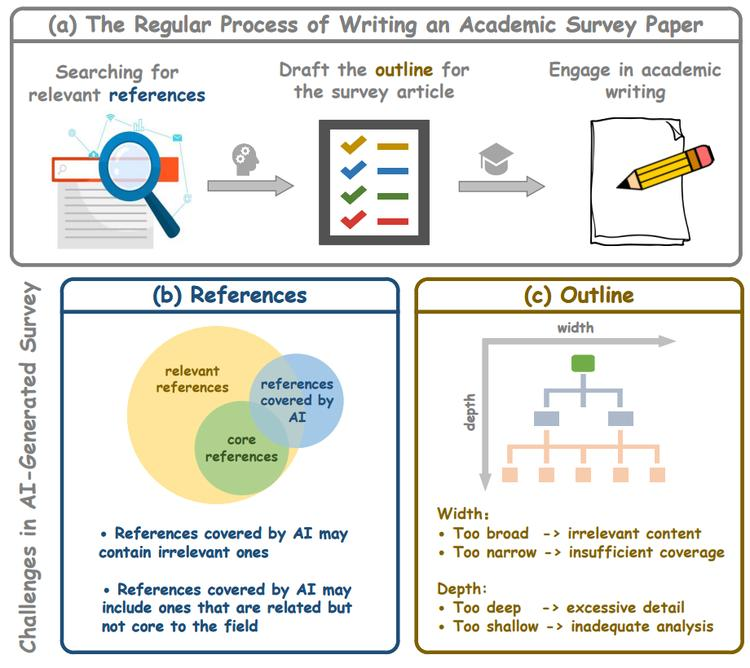
此外,本文作者构建了SurveyBench,一个包含100篇人类撰写的调研论文的基准,用以多维度评估AI生成的调研论文。实验显示SURVEYFORGE在生成调研论文方面优于AutoSurvey等先前工作。
人大 | MoC框架助力RAG系统

https://arxiv.org/pdf/2503.09600
本文作者提出了一种新的双重评估方法,包括边界清晰度和块粘性,以量化文本块的质量。基于此评估,本文作者指出传统和语义块处理复杂上下文的局限性,并强调了将大型语言模型(LLMs)整合到块处理过程中的必要性。
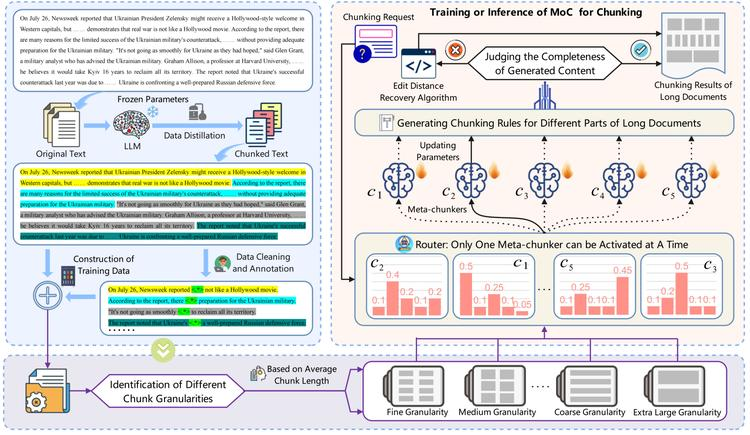
为解决LLMs在块处理中的效率与精度之间的权衡,本文作者设计文本块混合学习框架:MoC,通过三阶段处理机制指导生成结构化的块正则表达式列表,用于从原始文本中提取块。实验表明,新提出的评估指标和MoC框架有效解决了块任务的挑战,提高了检索增强生成系统的性能。
360 | 从头训练长链推理模型

https://arxiv.org/pdf/2503.10460
本文作者介绍了Light-R1系列模型,通过两阶段SFT和半策略DPO训练,从无长链推理能力的模型开始,训练出Light-R1-32B模型,其数学性能优于DeepSeek-R1-Distill-Qwen-32B。尽管仅在数学数据上训练,但Light-R1-32B在其他领域也展现出强泛化能力。
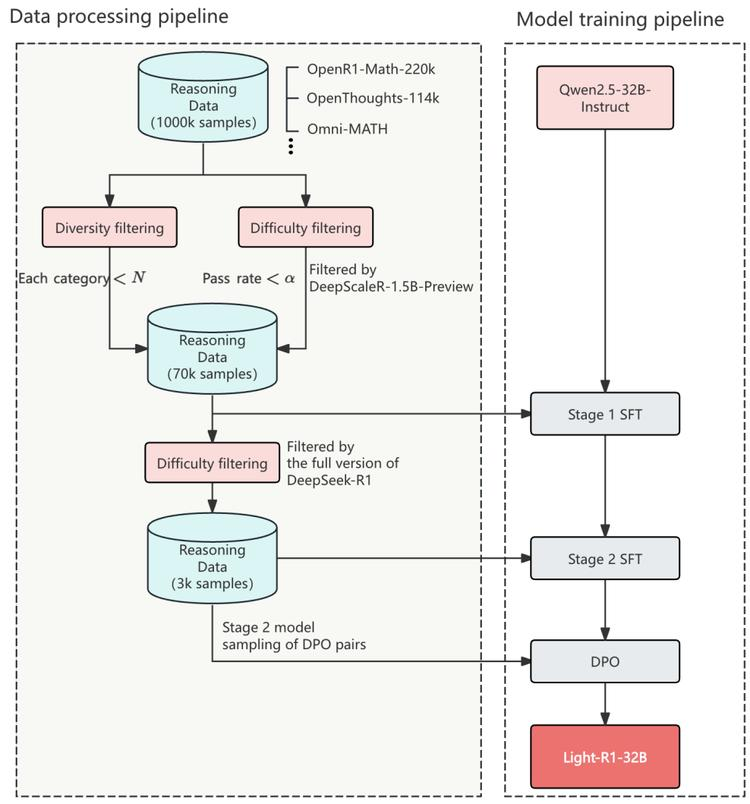
后续工作中,作者强调了为第二阶段SFT构建的3k数据集对提升其他模型的重要性,通过微调DeepSeek-R1-Distilled模型,获得了7B和14B的新SOTA模型,而32B模型Light-R1-32B-DS与QwQ-32B和DeepSeek-R1表现相当。此外,作者还通过应用强化学习(特别是GRPO)进一步改善了长链推理模型的推理性能,最终训练出的Light-R1-14B-DS模型在数学领域达到SOTA性能,超越了许多32B模型和DeepSeek-R1Distill-Llama-70B。
浙大|多模态推理模型:R1-Onevision

https://arxiv.org/pdf/2503.10615
本文作者介绍了R1-Onevision,一个多模态推理模型,旨在连接视觉感知和深度推理。提出了一种跨模态推理流程,将图像转化为形式化文本表示,实现精确的语言推理。
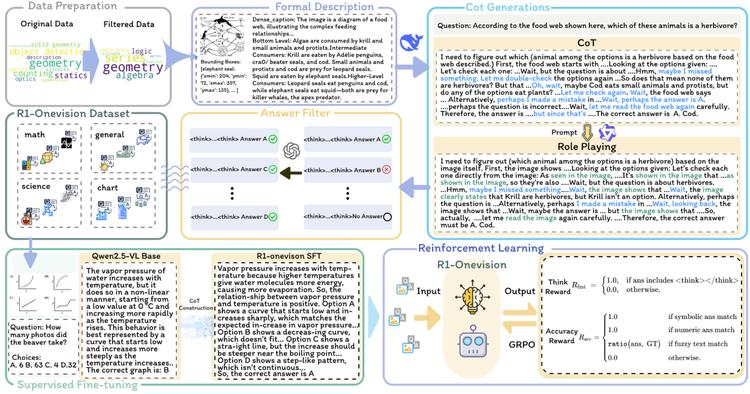
基于此流程,构建了R1-Onevision数据集,提供多领域的详细、分步的多模态推理标注。通过监督微调和强化学习进一步开发模型,培养高级推理和鲁棒泛化能力。实验结果表明,R1-Onevision在多个挑战性的多模态推理基准测试中表现优异,超越了GPT-4o和Qwen2.5-VL等模型。
推荐阅读
[1] 盘点一下!大模型Agent的花式玩法,涉及娱乐、金融、新闻、软件等各个行业
[2] 一文了解大模型Function Calling
[3] 2025年的风口!| 万字长文让你了解大模型Agent
[4] 万字长文!最全面的大模型Attention介绍,含DeepSeek MLA,含大量图示!
[5]一文带你详细了解:大模型MoE架构(含DeepSeek MoE详解)
[6] 颠覆大模型归一化!Meta | 提出动态Tanh:DyT,无归一化的 Transformer 性能更强