Abstract
在大型视觉语言模型(LVLMs)中,图像作为携带丰富信息的输入源。正如"一图胜千言"这一成语所喻,当前LVLMs中表示单幅图像可能需要数百甚至数千个标记(tokens)。这种情况导致了显著的计算成本,且随着输入图像分辨率的提升呈二次方增长,从而严重影响了效率。以往的方法尝试在LVLMs的早期阶段之前或内部减少图像标记的数量,但这些策略不可避免地会导致关键图像信息的丢失。为应对这一挑战,我们通过实证研究发现:在浅层网络中,所有视觉标记对LVLMs都是必要的;而随着网络深度增加,标记冗余度逐步提升。基于此,我们提出了PyramidDrop——一种视觉冗余减少策略,能够在几乎不损失性能的前提下提升LVLMs的推理和训练效率。具体而言,我们将LVLM划分为多个阶段,在每个阶段结束时按预设比例丢弃部分图像标记。该丢弃机制基于轻量级相似性计算,时间开销可忽略不计。大量实验表明,在LLaVA-NeXT等主流LVLMs上,PyramidDrop可实现40%以上的训练时间减少和55%的推理FLOPs加速,同时保持相当的多模态性能。此外,PyramidDrop还可作为即插即用策略自由加速推理,相比同类方法具有更优的性能和更低的推理成本。该项目已开源至https://github.com/Cooperx521/PyramidDrop,旨在为社区发展提供关键资源。
Introduction
1. 研究背景与挑战
-
视觉标记的高成本问题:
大型视觉语言模型(LVLMs)在处理高分辨率图像时,需要生成数百甚至数千个视觉标记(tokens),导致计算成本随分辨率呈二次方增长,严重影响训练和推理效率。
例如,图像标记数量与分辨率平方成正比,导致Transformer的计算复杂度急剧上升。 -
传统方法的局限性:
现有方法通过提前压缩图像标记或在浅层网络丢弃部分标记来降低计算成本,但这些策略会不可避免地损失关键信息,导致模型性能下降。
2. 关键发现
- 层间冗余性分析:
通过实验发现,LVLMs在浅层网络需要依赖所有视觉标记以全局理解图像,而随着网络深度增加,标记冗余度逐渐提升。例如,在浅层(如第2层)丢弃10%的标记会显著影响性能,但在深层(如第24层)即使保留10%的标记,模型表现仍稳定。
注意力可视化进一步表明,浅层关注全局信息,深层仅聚焦与指令相关的局部区域。
Related Work
2.1 Token Reduction(令牌缩减技术)
-
LLM领域的文本令牌缩减:
- 目标:减少长文本生成时的计算开销和KV缓存。
- 代表性方法:
- StreamLLM[47]:保留注意力“锚点”和最新令牌以压缩KV缓存。
- FastGen[15]:根据注意力头特性动态管理KV缓存。
- H2O[55]:基于累积注意力分数选择性剪枝KV对。
- ScissorHands[34]:保留历史窗口中具有稳定注意力模式的令牌。
- 局限性:针对文本令牌设计,无法直接迁移到视觉令牌场景。
-
视觉领域的令牌缩减:
- 早期ViT研究:
- Token Merging[3]:合并相似视觉令牌以加速ViT推理。
- PUMER[4]、SpViT[21]:通过剪枝或重组令牌减少冗余。
- LVLM领域的尝试:
- FastV[9]:在LVLM的第二层丢弃视觉令牌,但导致浅层信息丢失(如图像全局理解受损)。
- 局限性:现有方法未考虑LVLMs的层级冗余特性,压缩策略单一。
- 早期ViT研究:
2.2 Large Vision-Language Models(大型视觉语言模型)
-
模型发展脉络:
- 基础架构:基于LLaMA、Vicuna等开源LLM,结合视觉编码器(如CLIP)构建多模态模型(如LLaVA[31]、InstructBLIP[12])。
- 高分辨率扩展:
- LLaVA-NeXT[30]、Qwen-VL[2]:通过分块处理支持更高分辨率(如2880令牌),但计算成本激增。
- DocOwl[20]、Pali-X[10]:面向文档理解优化,需密集视觉特征。
- 挑战:图像分辨率提升导致令牌数量二次增长,训练/推理效率低下。
-
效率瓶颈:
- 计算复杂度:Transformer的注意力机制复杂度与序列长度平方相关(如2880令牌导致FLOPs剧增)。
- 现有方案不足:直接压缩令牌(如FastV)或投影降维(如BLIP-2的Q-Former[25])牺牲模型性能。
3. Method
3.1. Study of Visual Token Redundancy in LVLMs
作者提出核心问题:
“所有视觉标记在LVLMs的所有层中都是必要的吗?”
通过实验验证层间冗余性,为PyramidDrop的分阶段策略提供依据。
2. 实验设计
-
模型与基准:
采用LLaVA-v1.5-7B模型(32层),在TextVQA基准上评估标记删除的影响。TextVQA包含高分辨率图像文本,对标记压缩敏感,适合评估冗余性。 -
方法:
在不同层(第2、8、16、24层)删除不同比例的视觉标记,基于文本标记对图像标记的注意力值排序,保留高注意力值的标记。
3. 关键发现
-
浅层敏感性:
第2层删除标记对性能影响显著。例如,删除10%的标记即可导致性能下降(图1左),表明浅层需要依赖所有标记以全局理解图像。 -
深层冗余性:
随着层数加深,标记冗余性逐渐增加:- 第16层保留10%的标记仍能维持性能。
- 第24层的性能几乎与标记保留比例无关,说明模型已提取关键信息,剩余标记冗余。
-
注意力可视化:
浅层注意力均匀分布于全局图像,深层则聚焦与指令相关的局部区域(图1右),进一步验证冗余性随层数增加的趋势。
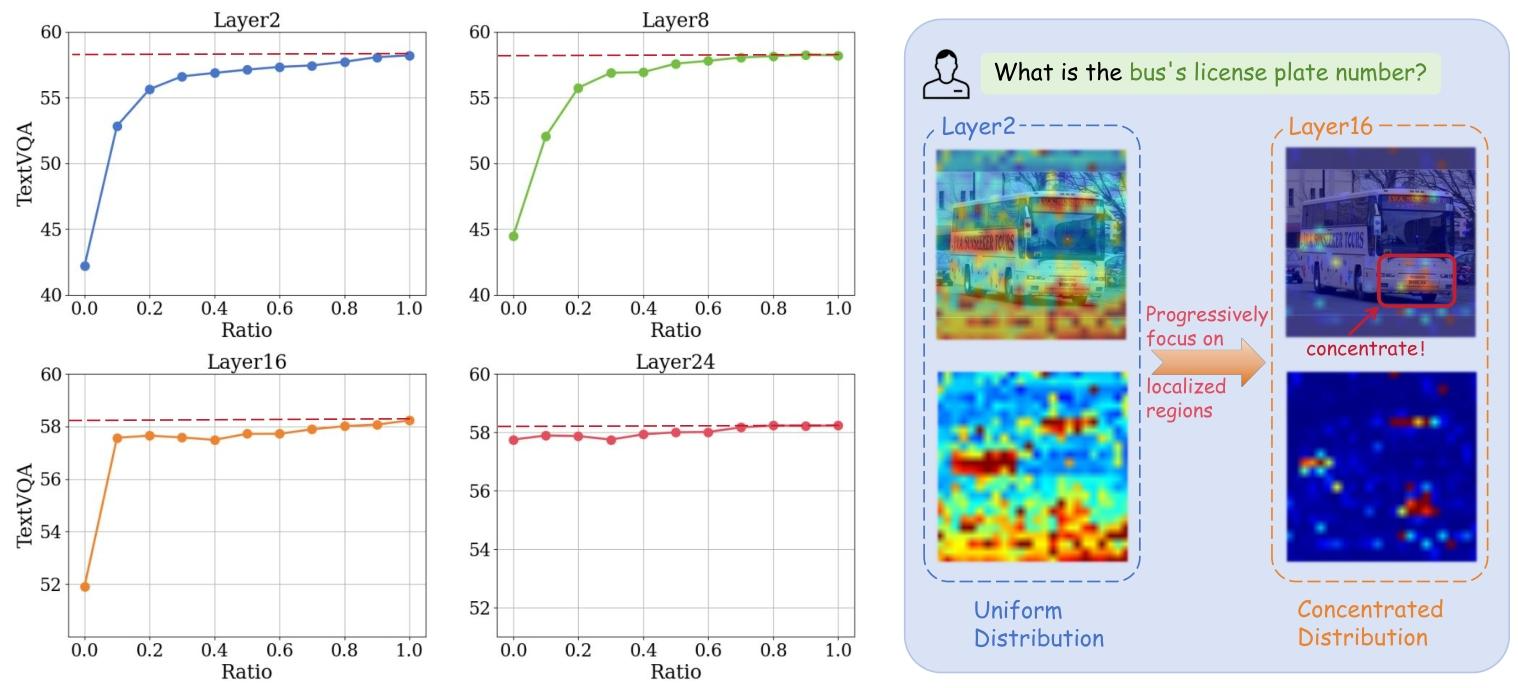
图1. 视觉冗余在不同网络层的观察结果。左图:LLaVA-1.5模型在不同层保留不同比例图像标记时的TextVQA任务性能。保留的图像标记为文本标记关注度最高的部分。右图:浅层和深层网络层的注意力图可视化。
3.2. PyramidDrop
1. 设计动机
-
层间冗余差异:
基于3.1节的研究发现,LVLMs浅层需要所有视觉标记,而深层冗余性逐渐增加。传统方法(如固定比率压缩)会导致浅层信息损失或深层冗余保留,无法充分利用层间特性。 -
目标:
通过分阶段动态丢弃标记,在浅层保留关键信息,深层逐步消除冗余,实现效率与性能的平衡。
2. 方法框架
2.1 阶段划分与标记丢弃
-
阶段分割:
将LVLM的语言模型(LLM)划分为多个阶段(例如4个阶段),每个阶段结束时按预定义比例(λ)丢弃部分图像标记。标记数量随阶段指数级减少,最终在深层接近零。 -
公式描述:
设初始图像标记数为 V 0 V_0 V0,阶段数为 S S S,则第 s s s阶段的标记数为:
V s = V 0 ⋅ λ s − 1 ( s = 1 , 2 , … , S ) V_s = V_0 \cdot \lambda^{s-1} \quad (s=1,2,\dots,S) Vs=V0⋅λs−1(s=1,2,…,S)
2.2 标记重要性评估
-
轻量级注意力计算:
基于文本标记对图像标记的关注程度排序,保留高重要性的标记。具体步骤为:- 在每个阶段末尾,提取文本指令的最后一个标记( t j I t_j^I tjI)的查询状态( q j t I q_j^{t_I} qjtI)和图像标记的键状态( k j v k_j^v kjv)。
- 计算相似度矩阵 q j t I × ( k j v ) T q_j^{t_I} \times (k_j^v)^T qjtI×(kjv)T,按分数保留前 λ ⋅ V s \lambda \cdot V_s λ⋅Vs个标记。
-
效率优化:
计算复杂度为 O ( n ) O(n) O(n),且仅在阶段末尾执行,时间开销可忽略。同时兼容FlashAttention技术,避免全注意力计算。
3. 数学公式与模型结构
3.1 LVLM预处理公式
-
定义LVLM为 M = ( L , V , P ) M = (L, V, P) M=(L,V,P),其中:
- L L L:语言模型(含Tokenizer c 0 c_0 c0和J层Transformer解码器 F F F)。
- V V V:视觉编码器。
- P P P:视觉-语言投影层。
-
输入图像-文本对 ( V , T ) (V, T) (V,T),生成图像标记 v 0 = P ( V ( V ) ) v_0 = P(V(V)) v0=P(V(V))和文本标记 t 0 = L 0 ( T ) t_0 = L_0(T) t0=L0(T)。
3.2 前向传播与阶段处理
-
每层前向传播公式为:
v j , t j = F j ( v j − 1 , t j − 1 ) v_j, t_j = \mathcal{F}_j(v_{j-1}, t_{j-1}) vj,tj=Fj(vj−1,tj−1) -
阶段末尾丢弃标记后,剩余标记作为下一阶段输入。
4. 效率分析
- 计算开销:
PyramidDrop引入的额外计算主要来自相似度矩阵计算,但复杂度仅为线性( O ( n ) O(n) O(n)),且阶段数 S S S通常较小(如4),总开销可忽略。 - 计算成本节省:
基于FlashAttention的线性复杂度假设,总计算成本公式为:
1 − λ S S ⋅ ( 1 − λ ) ⋅ c ⋅ N ⋅ L \frac{1-\lambda^S}{S \cdot (1-\lambda)} \cdot c \cdot N \cdot L S⋅(1−λ)1−λS⋅c⋅N⋅L
例如,当 λ = 0.5 \lambda=0.5 λ=0.5且 S = 4 S=4 S=4时,理论上可节省53.2%的计算成本。

图2. PyramidDrop整体流程。我们将语言模型(LLM)的前向传播划分为多个阶段,并在每个阶段结束时按预定义比例丢弃部分图像标记。丢弃操作基于轻量级注意力计算,时间开销可忽略不计。根据这一准则,LLM能够精准筛选出与指令相关的重要图像标记。得益于高效的冗余消除策略,平均序列长度得以快速缩减。
4. Experiment
4.1. Set up
1. 模型选择
- LLaVA-1.5-Vicuna-7B:
广泛使用的开源LVLM骨干模型,通过CLIP编码器将576个图像特征映射为LLM输入。 - LLaVA-NeXT-Vicuna-7B:
LLaVA-1.5的高分辨率扩展版本,支持最多2880个图像标记,具备更强的高分辨率处理能力。
2. 基准测试
- 通用任务:
- MME Benchmark[14]:评估多模态大模型的感知与认知能力。
- MMBench & MMBench-CN[33]:中英文视觉推理与感知任务。
- SEED[22]:由GPT-4生成的图像/视频问答数据集(约19,000问题)。
- MM-Vet[51]:基于GPT-4的六维能力评估。
- VQA-v2[17]、VizWiz[18]:传统视觉问答任务。
- 高分辨率任务:
- DocVQA[39]、ChartQA[38]、InfographicVQA[40]、TextVQA[44]:包含文本、图表等细粒度信息的高分辨率图像任务。
- MMStar[7]:强视觉依赖、低数据泄露的复杂多模态任务。
3. 效率评估指标
- 训练效率:
报告实际训练所需的GPU小时数(基于8个NVIDIA A100 80GB GPU)。 - 推理效率:
采用FLOPs(浮点运算次数)评估图像标记部分的计算量,公式为:
FLOPs = ∑ s = 0 S − 1 K s ( 4 n s d 2 + 2 n s 2 d + 3 n s d m ) \text{FLOPs} = \sum_{s=0}^{S-1} K_s \left(4n_s d^2 + 2n_s^2 d + 3n_s d m\right) FLOPs=s=0∑S−1Ks(4nsd2+2ns2d+3nsdm)
其中, n s = λ s n n_s = \lambda^s n ns=λsn 表示各阶段的图像标记数, d d d 为隐藏层大小, m m m 为前馈网络中间层大小。
4. 实现细节
- 阶段划分:
将LLM的32层划分为4个阶段,每个阶段结束时按 λ = 0.5 \lambda=0.5 λ=0.5的比例丢弃图像标记。 - 训练配置:
- 基于开源项目Open-LLaVA-NeXT进行训练(因LLaVA-NeXT原始代码未开源)。
- 使用FlashAttn优化注意力计算,避免全注意力图输出。
4.2. Efficiency of PyramidDrop in Inference
1. 推理加速效果
-
即插即用策略:
PyramidDrop作为推理阶段的独立优化策略,在不影响模型性能的前提下显著减少计算成本。例如,在LLaVA-NeXT-7B模型上实现了55%的推理FLOPs加速,同时保持多模态性能。 -
与FastV的对比:
实验表明,PyramidDrop在多个基准测试中优于FastV(如MME、GQA、TextVQA等)。例如:- LLaVA-NeXT-7B:MME分数1533.0(FastV为1504.0),TextVQA提升0.5%,SEED-Bench(Image)提升0.7%。
- LLaVA-1.5-7B:FLOPs从3.82T降至1.78T,同时MME分数保持1467.3(FastV为1473.7)。
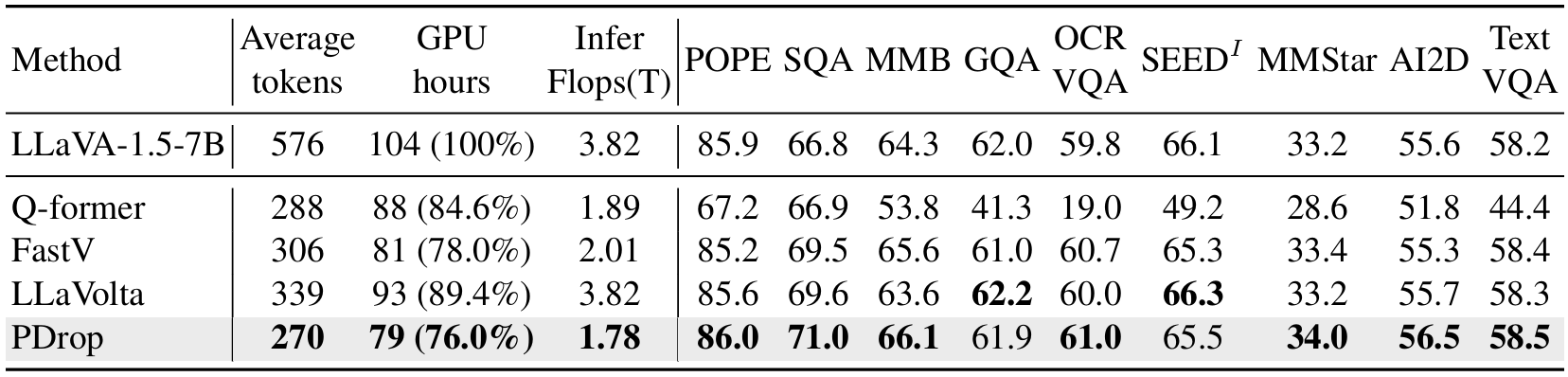
表5. PyramidDrop与其他高效训练策略的对比。此处的平均标记数指所有LLM层的平均图像标记数,而GPU小时代表模型训练所需时间。如表所示,我们的方法在几乎所有基准测试中均取得最佳性能,同时在训练和推理方面均为最具成本效益的策略。
2. 不同压缩比例下的性能
- 与其他方法的对比:
在保留192、128、64个图像标记时,PyramidDrop在MME、GQA、TextVQA等任务上均优于ToMe、FastV、SparseVLM等基线方法。例如:- 保留192标记时,PyramidDrop的MME分数为1797,高于SparseVLM的1721和FastV的1563。
- 即使压缩至64标记,PyramidDrop仍保持较高性能(MME分数1561,FastV为1505)。
3. 高分辨率任务表现
- 细粒度信息处理:
在高分辨率基准(如DocVQA、InfoVQA)中,PyramidDrop通过动态保留关键标记,避免了FastV因过早压缩导致的信息损失。例如:- LLaVA-NeXT-7B在DocVQA上的准确率为69.0%(FastV为67.2%),InfoVQA为31.7%(FastV为33.3%)。
4. 视频任务验证
- 视频LLM推理加速:
在Video-LLaVA模型上,PyramidDrop实现了27.8%的训练时间减少,并在TGIF、MSVD、MSRVTT等视频问答任务中保持性能。例如:- TGIF准确率46.6%(与原版47.0%相当),FLOPs显著降低。