Protocol Buffers(protobuf)是一种轻便高效的结构化数据存储格式,用于数据序列化和反序列化,具有语言无关、平台无关、可扩展性强等特点,能有效提高数据存储和传输的效率。
一.协议的设计
我们在介绍protobuf之前我们先来了解一下“协议”所谓协议就是规定了通信的双方比如客户端和服务器要遵循什么样的规则去收发数据
1.协议设计的基本概念
①.协议是两端约定的通信规范,确保通信的可靠性。
②.协议设计的注意事项包括解析效率、运行时限、可读性和兼容性。
③.协议设计的具体定义和应用场景。
2.协议设计的具体实现
①.消息边界的判断:通过特定符号或固定消息头加消息体结构。
②.版本区分:通过版本号字段区分不同版本的协议。
③.消息类型区分:通过command ID字段区分不同类型的消息。
二.序列化
1.序列化方法
①TLV编码(是一种将数据表示为标签(Tag)、长度(Length)和值(Value)三元组形式的编码方式)及其变体:比如protobuf
②文本流编码(文本流编码是将文本信息按照特定的规则转换为字节流的过程,):比如XML/JSON
③固定结构编码:基本原理是,协议规定了传输字段类型和字段含义
④内存dump:基本原理是,把内存中的数据直接输出,不做任何序列化的操作,反序列化就是直接还原内存
2.常见的序列化方法
主流序列化协议:xml,json,protobuf
XML:属于文本格式,使用标签来定义数据结构,标签嵌套形成层次关系,结构清晰,具有良好的可读性,人类可以直接查看和编辑。
JSON:同样是文本格式,基于键值对和数组的结构,语法简洁,易于阅读和编写
Protobuf:采用二进制编码格式,数据以二进制流的形式存储和传输,人类难以直接阅读和理解,需要借助特定工具和代码才能解析。
补充:::
文本:printf打印观察
二进制:printf打印后乱码

3.序列化结果数据对比


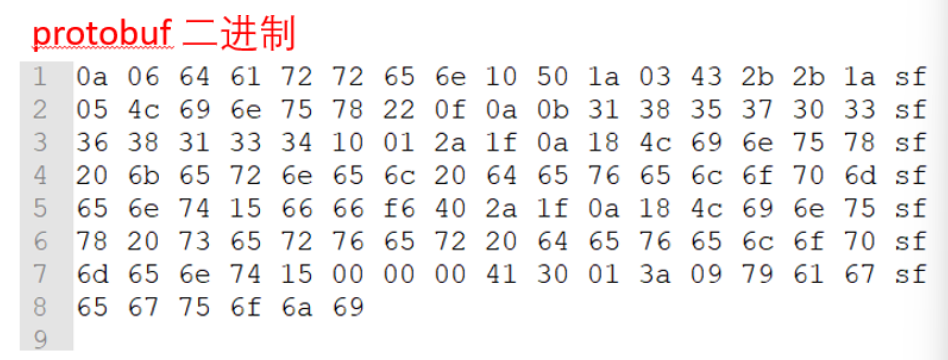 4.序列化和反序列化的速度对比
4.序列化和反序列化的速度对比
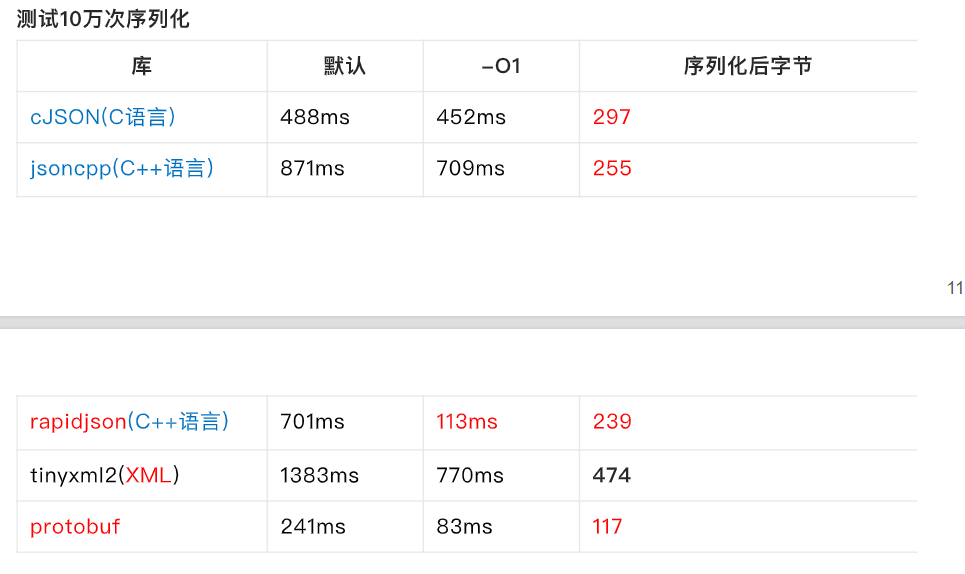
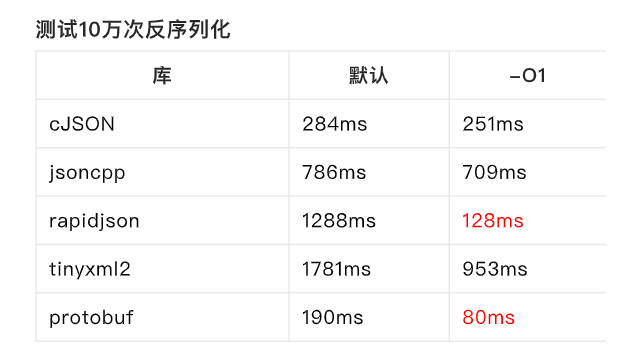
三.protobuf的使用
protobuf很适合做数据存储和RPC数据交换格式. 可用于通讯协议,数据存储等领域的语言无关,平台无关,可扩展的序列化的数据结构格式
1.protobuf 协议工作流程
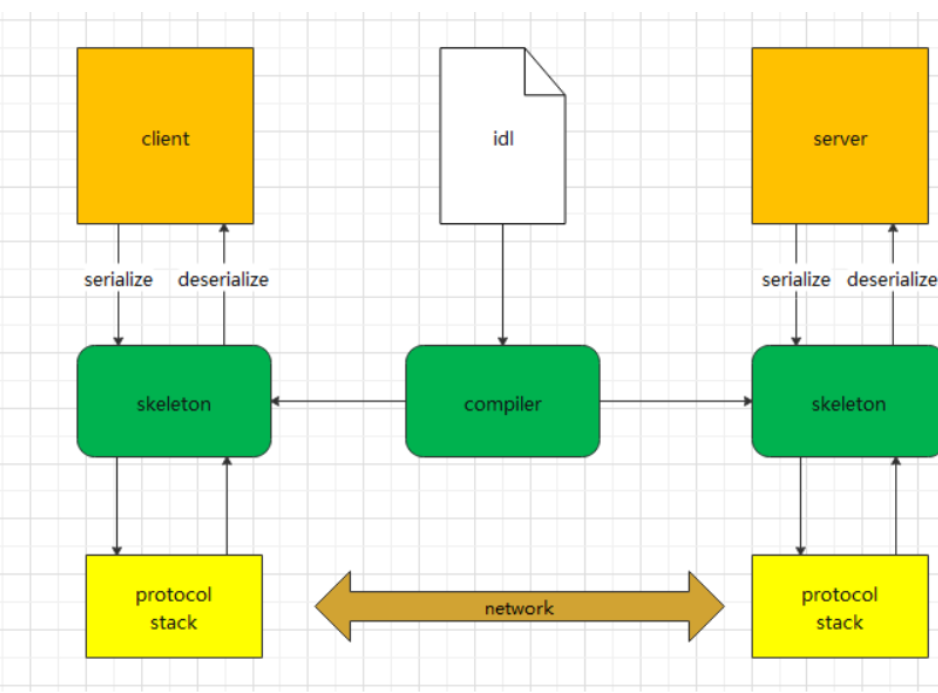
这是一个与远程过程调用(RPC)相关的架构示意图 ,涉及的关键组件及原理如下:
idl(接口定义语言):用于定义客户端和服务器之间交互的接口规范,独立于具体编程语言,清晰描述服务提供的方法、参数及返回值等,像 gRPC 使用的.proto 文件就是典型的 IDL 文件。
compiler(编译器):读取 idl 文件,依据其中定义生成特定编程语言的代码框架(骨架代码,即 skeleton )。比如 Protobuf 编译器 protoc,能将.proto 文件编译成 C++、Java、Python 等语言对应的代码。
skeleton(骨架):在客户端和服务器端生成的代码框架。客户端骨架负责将调用请求序列化(serialize),经网络发给服务器;服务器端骨架接收请求后反序列化(deserialize),调用实际服务逻辑,再将结果序列化返回给客户端,客户端反序列化得到最终结果。
protocol stack(协议栈):处理网络通信底层细节,包括数据的封装、传输、错误处理等,保障客户端和服务器间可靠的数据传输。
client 和 server:客户端发起服务请求,服务器接收请求并提供服务,二者借助上述组件完成基于网络(network)的交互通信。
2.protobuf的编码原理
①变长编码和固定长度编码的区别
②变长编码用什么方式区分变量边界,比如base128(一种基于 128 个字符的编码方式)
③base128 使用每个字节的最高位有效位作为标志位,而剩余的7位以二进制补码的形式存来存储数字值本身,当最高有效位为1时,代表其后还跟有字节,当最高有效位为0时,代表已经是该数字的最后一个字节了
④变长编码和固定编码有什么优缺点根据不同的场景
3.Varints 编码(变长类型才使用)
①举例子

在固长编码中 无论是 0x12345678 和 0x12 都是占用4个字节 我们想做到0
x12只占用1一个字节 从而获取更高的存储和传输效率(动态思想)
Varints 编码使用每个字节的最高有效位作为标志位, 而剩余的 7 位以二进制补码的形式来存储数值本身, 当最高有效位为 1 时, 代表其后还跟有字节, 当最高有效位为 0 时, 代表已经是该数字的最后的一个字节。
Protobuf 中, 使用的是 Base128 Varints 编码, 在这种方式中, 使用 7 bit (即7的2次方为128)来存储数字, 在 Protobuf 中, Base128 Varints 采用的是小端序, 即数字的低位存放在高地址。
举例来看,对于数字 1 我们假设 int 类型占 4 个字节, 以标准的整型存储, 其二进制表示应为

可见只有一个字节存储了有效值 我们浪费了前面三个字节 所以我们要可以采用varints编码以二进制形式存储为

因为其没有后续字节, 因此其最高有效位为 0, 其余的 7 位以补码形式存放 1
再比如数字 666, 其以标准的整型存储, 其二进制表示为
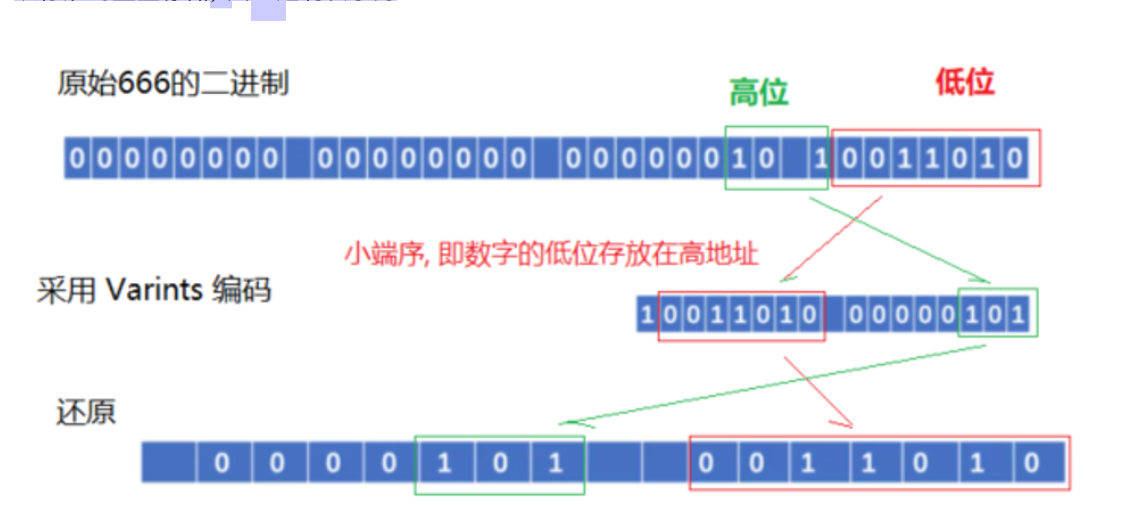
从上面的编码解码过程可以看出, 可变⻓整型编码对于不同大小的数字, 其所占用的存储空间是
不同的。
4.Zigzag 编码(针对负数的)
Zigzag 编码是为解决 Varint 等编码对负数编码效率低的问题而产生,专门用于对有符号整数进行高效编码,尤其是负数,我们在这里不多赘述了