Abstract
像GPT-4o这样的实时大型多模态模型(LMMs)的出现,引发了人们对高效LMMs的浓厚兴趣。LMM框架通常会将视觉输入编码为视觉令牌(连续表示),并将其与文本指令整合到大语言模型(LLMs)的上下文环境中。在这种情况下,大规模的参数和大量的上下文令牌(主要是视觉令牌)会导致巨大的计算开销。以往提高LMM效率的工作总是聚焦于用较小的模型替换LLM主干,却忽略了令牌数量这一关键问题。在本文中,我们推出了LLaVA-Mini,这是一种高效的大型多模态模型,仅需极少的视觉令牌。为了在保留视觉信息的同时实现视觉令牌的高压缩率,我们首先分析了LMMs对视觉令牌的理解方式,发现大多数视觉令牌仅在LLM主干的早期层中发挥关键作用,它们主要在这些层中将视觉信息融合到文本令牌中。基于这一发现,LLaVA-Mini引入了模态预融合技术,提前将视觉信息融合到文本令牌中,从而便于将输入到LLM主干的视觉令牌极度压缩为一个令牌。LLaVA-Mini是一个统一的大型多模态模型,能够高效地支持对图像、高分辨率图像和视频的理解。在11个基于图像和7个基于视频的基准测试中,实验表明LLaVA-Mini仅用1个视觉令牌(而非576个),性能就优于LLaVA-v1.5。效率分析显示,LLaVA-Mini可以将浮点运算次数(FLOPs)减少77%,在40毫秒内给出低延迟响应,并且能够在配备24GB内存的GPU硬件上处理超过10000帧的视频。
Introduction
1. 研究背景与趋势
- 多模态大模型(LMMs)的兴起:
- 以 GPT-4o 为代表的实时多模态模型成为研究热点,其核心是让大语言模型(LLMs)具备视觉理解能力,支持低延迟的多模态交互(如实时对话)。
- 主流架构(LLaVA 系列):
- 典型方法(如 LLaVA)通过视觉编码器(如 CLIP ViT)将图像编码为视觉标记(vision tokens),与文本指令共同输入 LLM 进行推理。例如,CLIP ViT-L 将单张图像编码为 24 × 24 = 576 24 \times 24 = 576 24×24=576 个视觉标记。
2. 现有问题与挑战
- 计算开销过大:
- 参数量大:LLM 的参数量级(如 7B/13B)导致计算负担。
- 视觉标记过多:单个图像的 576 个视觉标记显著增加 LLM 的上下文长度,尤其在高分辨率图像(需更多标记)和视频(多帧叠加)场景下,计算复杂度剧增。
- 效率瓶颈:视觉标记占 LLM 输入的大部分(如 90% 以上),导致推理延迟高、内存占用大,难以满足实时交互需求。
3. 现有方法的局限性
- 模型压缩:
- 缩小 LLM 规模(如用更小的 Vicuna-7B)会牺牲语言理解能力,导致性能下降。
- 标记压缩:
- 规则压缩:基于相似性的标记合并(如 Token Merging)或固定长度压缩(如 Q-Former)导致视觉信息丢失。
- 视频处理:固定帧采样或记忆池化(如 MovieChat)可能忽略关键帧或时序信息。
4. 研究动机与核心思路
- 关键发现:
- 通过分析 LLaVA 的注意力机制,发现视觉标记主要在 LLM 的 早期层 与文本融合,深层则依赖已融合的文本信息。这意味着大部分视觉标记在后期可被压缩。
- 解决思路:
- 模态预融合(Modality Pre-Fusion):在输入 LLM 前,提前将视觉信息融合到文本指令中,减少对视觉标记的依赖。
- 极简视觉标记:通过自适应压缩(如动态查询),将视觉标记从 576 个压缩至 1 个,同时保留关键信息。
Related Work
1. 高效 LMM 的两种路径
- 方向 1:缩小模型规模
- 方法:直接替换 LLM 为更小的模型(如 Vicuna-7B → TinyLLaVA),或量化技术(如 4-bit 量化)。
- 问题:模型能力下降,尤其在复杂视觉任务(如细粒度理解)中性能显著降低。
- 方向 2:减少视觉标记数量
- 图像领域:
- 规则压缩:基于相似性合并标记(如 Token Merging、PruMerge)。
- 固定压缩:通过 Q-Former(如 Qwen-VL)将标记压缩到固定长度(如 256)。
- 问题:直接丢弃或平均合并会丢失关键视觉信息(如空间细节)。
- 视频领域:
- 帧选择:固定采样频率(如 Video-ChatGPT 选 100 帧)或记忆池化(如 MovieChat)。
- 问题:忽略关键帧或时序信息,导致长视频理解能力不足。
- 图像领域:
2. 现有方法的局限性
- 信息损失与性能下降:
多数标记压缩方法仅关注视觉编码器输出,未考虑视觉标记与 LLM 内部交互机制。例如,TokenPacker 将标记压缩到 36 个后,VQA 准确率下降约 5%。 - 上下文长度限制:
视频场景下,每帧需数百标记,导致 LLM 上下文窗口迅速饱和(如 8 秒视频需 4608 标记),难以处理长视频(>10 分钟)。
3. 本文的改进方向
- 创新点:
不同于传统方法仅压缩视觉编码器输出,LLaVA-Mini 首次分析视觉标记在 LLM 内部的交互机制,发现早期层是视觉-文本融合的关键阶段。 - 技术路线:
- 提出 模态预融合模块,在输入 LLM 前完成视觉-文本信息融合。
- 结合 动态查询压缩,实现视觉标记的极简压缩(1 个/帧),避免信息丢失。
3 HOW DOES LLAVA UNDERSTAND VISION TOKENS?
3.1 LLAVA ARCHITECTURE
略
3.2 PRELIMINARY ANALYSES
1. 分析目标
探究视觉标记在 LLM 各层中的重要性差异,回答以下问题:
- 视觉标记在不同层中如何影响模型的视觉理解能力?
- 哪些层对视觉信息的融合最为关键?
2. 分析方法
- 注意力权重分析:
测量 LLM 各层中 文本指令、视觉标记 和 生成响应 之间的平均注意力权重分布。- 实验模型:LLaVA-v1.5(Vicuna-7B/13B)、LLaVA-v1.6(Mistral-7B)、LLaVA-NeXT。
- 注意力熵计算:
通过熵值衡量各层对视觉标记的关注集中程度(熵值高 → 关注均匀;熵值低 → 关注集中)。 - 消融实验:
逐步移除 LLM 不同层(如第 1-4 层、5-8 层等)的视觉标记,观察性能变化(测试集:GQA、MMBench)。
3. 关键发现
-
视觉标记的层重要性差异
- 早期层(如第 1-8 层):
- 视觉标记接收 80% 以上的注意力权重,文本指令通过跨模态注意力主动融合视觉信息。
- 高熵值:视觉标记的注意力分布均匀,所有标记均参与信息融合。
- 深层(如第 16 层后):
- 注意力转向文本指令和生成响应,视觉标记的注意力权重 下降至 20% 以下。
- 低熵值:仅少数视觉标记被关注(可能聚焦关键区域)。
- 早期层(如第 1-8 层):
-
消融实验验证
- 移除早期层视觉标记:导致视觉理解能力 完全丧失(如 GQA 准确率从 62.0% 降至随机水平)。
- 移除深层视觉标记:性能仅轻微下降(如 GQA 保持 58.3%),表明深层对视觉信息依赖度低。
4. 结论与启示
- 视觉-文本融合的关键阶段:
视觉信息主要在 LLM 的早期层与文本指令融合,深层则依赖已融合的文本特征生成响应。 - 压缩策略设计依据:
- 若能在早期层完成视觉-文本融合,后续层的视觉标记可被极简压缩(如 1 个标记)。
- 直接丢弃早期层视觉标记会导致信息丢失,需通过 模态预融合 提前完成关键信息提取。
4 LLAVA-MINI
4.1 ARCHITECTURE
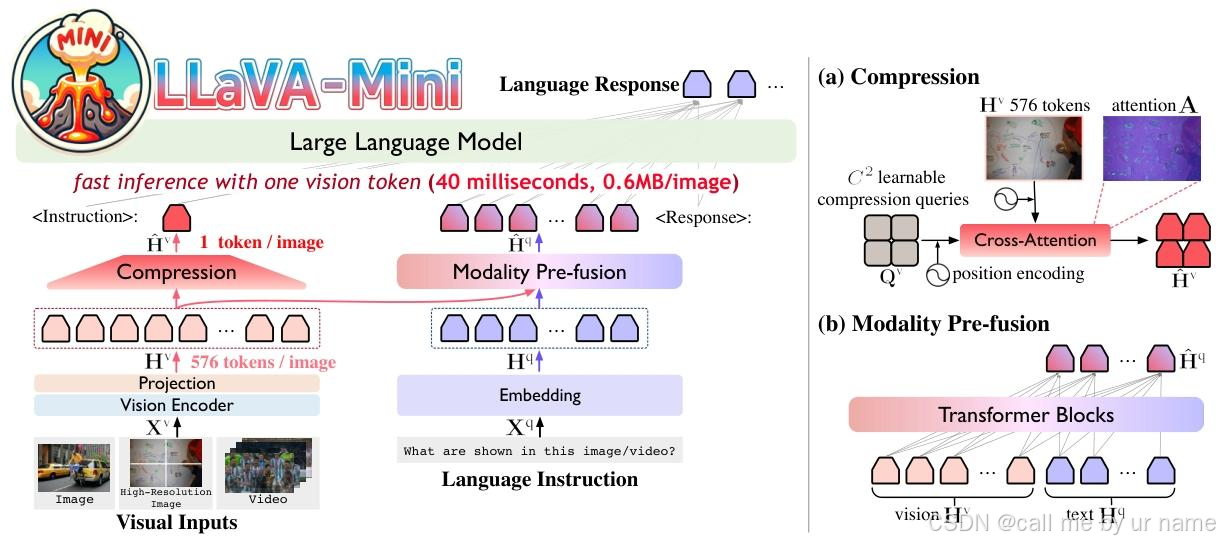
图6:LLaVA-Mini的架构。左图:LLaVA-Mini用一个视觉令牌表示每一幅图像。右图:所提出的基于查询的压缩和模态预融合的详细视图。
1. 整体架构流程
LLaVA-Mini 的架构分为四个主要模块(如图6所示):
- 视觉编码器(Vision Encoder):提取图像特征。
- 投影层(Projection Layer):将视觉特征映射到LLM的语义空间。
- 压缩模块(Compression Module):自适应压缩视觉标记数量。
- 模态预融合模块(Pre-Fusion Module):提前融合视觉与文本信息。
- LLM骨干(LLM Backbone):生成最终响应。
2. 核心模块功能
-
视觉编码与投影
- 视觉编码器:采用预训练的 CLIP ViT-L/336px,将图像分割为 N × N N \times N N×N 的块(如 24 × 24 = 576 24 \times 24 = 576 24×24=576 块),输出视觉特征 H v ∈ R N 2 × d h H^v \in \mathbb{R}^{N^2 \times d_h} Hv∈RN2×dh。
- 投影层:通过线性层将视觉特征 H v H^v Hv 映射到 LLM 的词嵌入空间,维度为 d h d_h dh(与文本标记对齐)。
-
视觉标记压缩
- 压缩查询(Compression Queries):引入 C × C C \times C C×C 个可学习的查询向量 Q v ∈ R C 2 × d h Q^v \in \mathbb{R}^{C^2 \times d_h} Qv∈RC2×dh(如 C = 1 C=1 C=1 时压缩为1个标记)。
- 压缩过程:通过交叉注意力机制,计算查询与视觉标记的相似度矩阵 A ∈ R C 2 × N 2 A \in \mathbb{R}^{C^2 \times N^2} A∈RC2×N2,生成压缩后的视觉标记 H ^ v = A ⋅ H v \hat{H}^v = A \cdot H^v H^v=A⋅Hv。
- 位置编码保留空间信息:在查询和视觉标记中加入 2D正弦位置编码,避免压缩丢失空间关系。
-
模态预融合模块
- 结构:包含 N fusion N_{\text{fusion}} Nfusion 个与 LLM 结构相同的 Transformer 块(如4层)。
- 输入:拼接原始视觉标记 H v H^v Hv 和文本指令嵌入 H q H^q Hq,总长度为 N 2 + l q N^2 + l_q N2+lq。
- 输出:仅保留文本部分的输出 H ^ q ∈ R l q × d h \hat{H}^q \in \mathbb{R}^{l_q \times d_h} H^q∈Rlq×dh,其中已融合视觉信息。
-
LLM骨干输入
- 最终输入:将压缩后的视觉标记 H ^ v \hat{H}^v H^v( C 2 C^2 C2 个)与预融合的文本标记 H ^ q \hat{H}^q H^q 拼接,总长度为 C 2 + l q C^2 + l_q C2+lq,输入 LLM 生成响应。
3. 高分辨率与视频扩展
-
高分辨率图像处理(如672×672)
- 分块策略:将图像水平/垂直切分为4个子图,分别输入视觉编码器,得到 4 × N 2 4 \times N^2 4×N2 个视觉标记。
- 压缩调整:增大 C C C(如 C = 8 C=8 C=8,压缩为64个标记),保留更多细节。
- 预融合输入:将子图与全局图的视觉标记共同输入预融合模块,增强局部与全局信息融合。
-
视频处理
- 逐帧压缩:对视频的每一帧独立压缩为 C 2 C^2 C2 个视觉标记(如 C = 1 C=1 C=1 时每帧1个标记)。
- 时序融合:将多帧的压缩标记按时间顺序拼接,总长度为 M × C 2 M \times C^2 M×C2( M M M 为帧数),文本标记通过池化聚合多帧信息。
4.2 HIGH-RESOLUTION IMAGE AND VIDEO MODELING
1. 高分辨率图像处理(High-Resolution Image Modeling)
-
问题背景:
传统视觉编码器(如 CLIP ViT-L)的分辨率有限(如 336 × 336 336 \times 336 336×336),高分辨率图像(如 672 × 672 672 \times 672 672×672)需编码更多视觉标记(如 24 × 24 × 4 = 2304 24 \times 24 \times 4 = 2304 24×24×4=2304 个),导致计算量剧增。 -
解决方案:
- 分块处理(Splitting Strategy):
- 将高分辨率图像 水平/垂直切分为4个子图(每块 336 × 336 336 \times 336 336×336),分别输入视觉编码器,得到 4 × 2 4 2 = 2304 4 \times 24^2 = 2304 4×242=2304 个视觉标记。
- 保留全局信息:额外将原始图像降采样至 336 × 336 336 \times 336 336×336,生成全局视觉标记(576 个)。
- 压缩增强:
- 增大压缩参数 C C C(如 C = 8 C=8 C=8 → 压缩为 8 × 8 = 64 8 \times 8 = 64 8×8=64 个标记),保留更多细节。
- 输入预融合模块:将4个子图标记(2304)和全局标记(576)与文本指令拼接,通过预融合模块生成融合后的文本表征。
- 效率优势:
- 计算量可控:尽管分块增加视觉标记数量,但压缩后输入 LLM 的标记数仅为 C 2 + l q C^2 + l_q C2+lq(如 64 + 256 = 320 64 + 256 = 320 64+256=320),显著低于传统方法(如 SPHINX-2k 需 2890 个标记)。
- 分块处理(Splitting Strategy):
2. 视频建模(Video Modeling)
-
问题背景:
视频包含多帧图像,传统方法(如 Video-LLaVA)受限于 LLM 的上下文窗口长度(如 4K tokens),只能采样少量帧(如 8 帧),导致长视频理解能力不足。 -
解决方案:
- 逐帧极简压缩:
- 每帧独立压缩为 C 2 C^2 C2 个视觉标记(默认 C = 1 C=1 C=1 → 每帧1个标记)。
- 时序拼接:M 帧视频压缩后生成 M × C 2 M \times C^2 M×C2 个视觉标记(如 100 帧视频 → 100 × 1 = 100 100 \times 1 = 100 100×1=100 个标记)。
- 文本指令融合:
- 每帧的文本指令通过预融合模块生成融合表征后,进行 时序池化(平均池化或最大池化),聚合多帧语义信息。
- 长视频支持:
- 单帧内存仅 0.6MB(传统方法约 200MB/帧),24GB GPU 可处理超 10,000 帧视频(约 3 小时,1fps 采样)。
- 逐帧极简压缩:
3. 关键技术创新
-
空间-时序解耦设计:
- 空间信息:通过分块和位置编码保留高分辨率图像的局部细节。
- 时序信息:通过逐帧压缩和池化操作捕捉长程依赖,避免传统固定帧采样的信息丢失。
-
动态可扩展性:
- 调整压缩参数 C C C 可平衡效率与性能(如 C = 1 C=1 C=1 用于实时交互, C = 8 C=8 C=8 用于精细分析)。
4. 与传统方法的对比优势
| 场景 | 传统方法(如 LLaVA-v1.5) | LLaVA-Mini |
|---|---|---|
| 高分辨率图像(672×672) | 直接编码为 576 标记,细节丢失 | 分块+压缩为 64 标记,保留局部/全局信息 |
| 长视频(10,000 帧) | 受限于上下文长度(最多处理约 100 帧) | 极简压缩(1标记/帧),支持万帧级处理 |
| 内存占用 | 单帧约 360MB | 单帧约 0.6MB |
4.3 TRAINING
LLaVA-Mini的训练过程与LLaVA相同,分为两个阶段。
- 阶段1:视觉-语言预训练:在这个阶段,尚未应用压缩模块和模态预融合模块(即 N 2 N^2 N2个视觉令牌保持不变)。LLaVA-Mini利用图像字幕数据学习对齐视觉和语言表征。训练仅聚焦于投影模块,而视觉编码器和大语言模型保持冻结状态。
- 阶段2:指令微调:在这个阶段,LLaVA-Mini使用指令数据进行训练,以基于极少的视觉令牌执行各种视觉任务。此时将压缩模块和模态预融合模块引入LLaVA-Mini,除了冻结的视觉编码器外,所有模块(即投影模块、压缩模块、模态预融合模块和大语言模型主干)都进行端到端的训练。
5 EXPERIMENTS
5.1 EXPERIMENTAL SETTING
1. 基准测试(Benchmarks)
实验涵盖 图像理解 和 视频理解 两大类任务,共 11 个图像基准 和 7 个视频基准:
- 图像任务:
- 通用问答:VQAv2、GQA、VisWiz(盲人视觉问答)、ScienceQA(科学问答)。
- 细粒度评估:POPE(目标存在性检测)、MME(多模态评估)、MMBench(综合能力测试)。
- 长文本生成:SEED(图像描述与推理)、LLaVA-Bench(复杂指令跟随)。
- 幻觉检测:MM-Vet(多模态幻觉评估)。
- 视频任务:
- 问答与推理:MSVD-QA、MSRVTT-QA、ActivityNet-QA。
- 生成评估:Correctness(准确性)、Detail(细节描述)、Contextual(上下文关联)、Temporal(时序理解)。
- 长视频理解:MLVU(多任务长视频测试)、EgoSchema(第一视角时序推理)。
2. 基线模型(Baselines)
- 图像模型对比:
- 传统多模态模型:BLIP-2、InstructBLIP、IDEFICS、Qwen-VL。
- 高效模型:MQT-LLaVA(量化压缩)、PruMerge(标记合并)、TokenPacker(标记打包)。
- 高性能模型:SPHINX、SPHINX-2k(高分辨率)、mPLUG-Owl2。
- 视频模型对比:
- 通用视频模型:Video-ChatGPT、Video-LLaMA、Video-LLaVA。
- 长视频模型:MovieChat(记忆池化)、LLaMA-VID(时序建模)、TimeChat(时序敏感模型)。
3. 模型配置
- 视觉编码器:CLIP ViT-L/336px(默认分辨率 336×336),高分辨率扩展使用 672×672。
- LLM 骨干:
- 基础版本:Vicuna-v1.5-7B(与 LLaVA-v1.5 一致)。
- 增强版本:LLaMA-3.1-8B-Instruct(更大参数量,用于探索性能上限)。
- 压缩参数:
- 标准图像: C = 1 C=1 C=1(1 个视觉标记)。
- 高分辨率图像: C = 8 C=8 C=8(64 个视觉标记)。
- 视频:每帧 C = 1 C=1 C=1,帧采样率 1fps。
4. 训练细节
- 数据:
- 预训练阶段:558K 图像-文本对(与 LLaVA-v1.5 相同)。
- 指令微调:665K 图像指令数据 + 100K 视频指令数据(来自 Video-ChatGPT),部分开源数据扩充至 3M 样本。
- 硬件:8 块 NVIDIA A800 GPU(80GB 显存)。
- 优化器与超参:
- 学习率:预训练阶段 1e-5,微调阶段 2e-5。
- 批次大小:预训练 512,微调 256。
- 训练轮次:预训练 1 轮,微调 3 轮。
- 冻结参数:视觉编码器权重固定,其余模块(投影层、压缩模块、预融合模块、LLM)端到端训练。
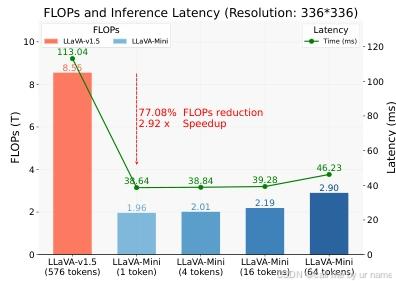
5. 效率评估指标
- 计算量:FLOPs(通过
calflops工具计算)。 - 延迟:A100 GPU 单样本推理时间(不含工程优化)。
- 内存占用:单帧/单视频的显存消耗(通过 PyTorch 显存分析工具测量)。
5.2 MAIN RESULTS
图像
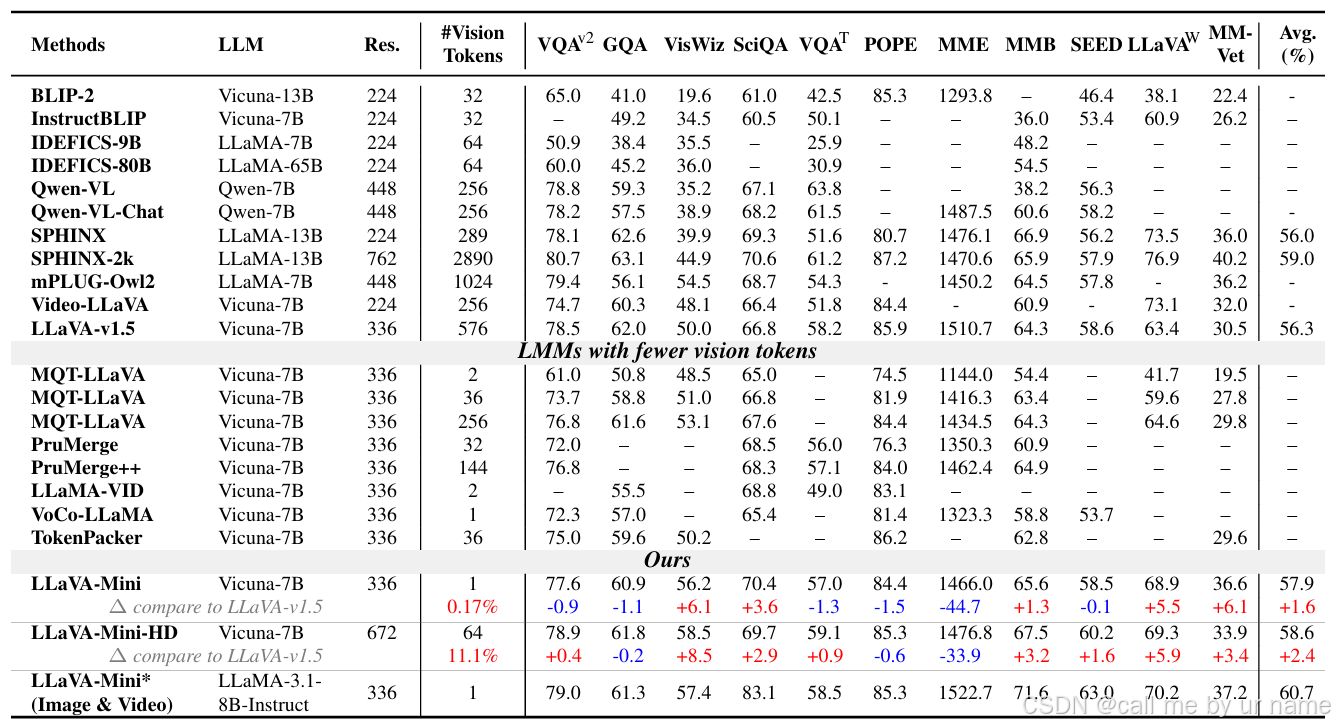
表1:11个基于图像的基准测试结果。“Res.”表示分辨率,“#Vision Tokens”表示输入到大语言模型(LLM)主干的视觉令牌数量。“*”表示涉及额外的训练数据。
视频
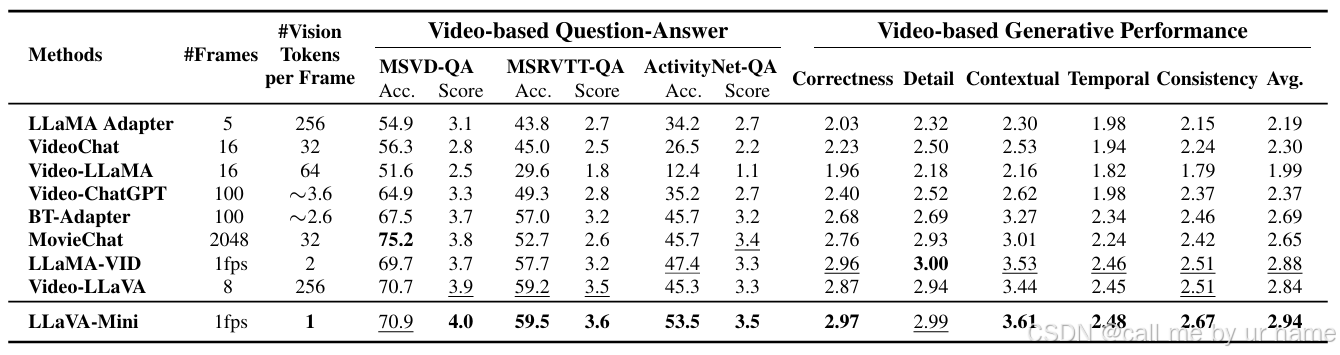
5.3 EFFICIENCY
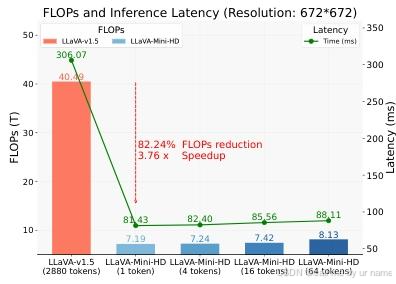
6 ANALYSES
6.1 模态预融合的优势(Superiority of Modality Pre-Fusion)
- 关键结论:
- 移除预融合模块后,模型性能显著下降(如 VQAv2 从 77.6% → 72.4%)。
- 预融合模块通过多层级交互,在压缩前完成视觉-文本信息对齐,避免早期层信息丢失。
- 实验支持:消融实验对比不同预融合层数( N fusion = 0 , 2 , 4 , 8 N_{\text{fusion}}=0,2,4,8 Nfusion=0,2,4,8),证明 4 层为最优配置。
6.2 压缩模块的有效性(Effect of Compression)
- 动态查询 vs 平均池化:
- 动态查询压缩在 VQAv2 上准确率 77.6%,显著高于平均池化的 76.1%(+1.5%)。
- 可视化分析:动态查询能自适应聚焦关键区域(如文字、小物体),而平均池化模糊细节。
- 位置编码的作用:
- 移除 2D 位置编码后,空间推理任务(GQA)准确率下降 4.3%,证明其保留空间关系的重要性。
6.3 不同视觉标记数量的影响(Performance with Various Vision Tokens)
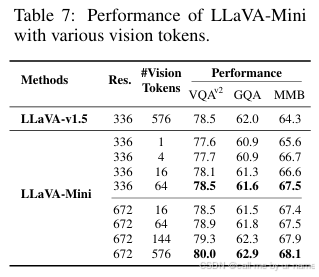
6.4 案例研究(Case Study)
-
图像理解案例:
- 任务:识别网站截图的商品价格。
- 结果:LLaVA-Mini 准确提取价格(“$299”),而 LLaVA-v1.5 因视觉标记过多导致注意力分散,误识别为“$199”。
-
视频理解案例:
- 输入:10 秒庆祝场景视频(10 帧,1fps)。
- LLaVA-Mini:正确描述“人群举旗欢呼”;Video-LLaVA(采样 8 帧)因漏掉关键帧,错误推断为“足球比赛”。
- 结论:极简压缩(1标记/帧)支持密集采样,避免信息丢失。
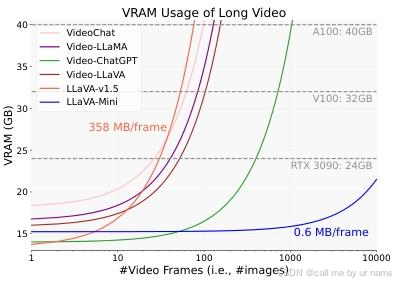
6.5 长视频理解的可扩展性(Long Video Scalability)
- 万帧视频处理:
- 硬件:NVIDIA RTX 3090(24GB 显存)。
- 结果:LLaVA-Mini 可处理 10,000 帧视频(约 3 小时),而传统方法(如 Video-ChatGPT)受限于显存,最多处理 100 帧。
- 内存对比:LLaVA-Mini 总显存占用 6GB(10,000×0.6MB),Video-LLaVA 需 200GB(100×200MB)。